
La base de datos Oracle NoSQL
Publicado: 2022-12-17Oracle NoSQL Database es una base de datos clave-valor distribuida. Está diseñado para proporcionar una gestión de datos escalable y de alto rendimiento manteniendo una interfaz sencilla. Oracle NoSQL Database se basa en Oracle Berkeley DB Java Edition, que proporciona un motor de base de datos integrable de alto rendimiento. Oracle NoSQL Database está disponible como una imagen de máquina virtual descargable o como un servicio en la nube.
In-Memory emplea una arquitectura única de formato dual que permite que las tablas se representen simultáneamente en la memoria. Debido a que el nuevo formato de columna es un formato puro en memoria y no requiere almacenamiento en disco, no hay costos de almacenamiento adicionales ni problemas de sincronización de almacenamiento. La capacidad de las bases de datos en memoria para manejar consultas a la asombrosa velocidad de miles de millones de filas por segundo en un núcleo de CPU es asombrosa. La mayoría de estos índices analíticos se pueden eliminar con In-Memory mediante el uso del formato de columna In-Memory, que reduce la cantidad de datos que deben recuperarse y, al mismo tiempo, proporciona un rendimiento comparable al de tener un índice en cada columna. La eliminación de los índices analíticos acelera las operaciones de OLTP porque ya no es necesario mantener los índices en cada transacción. Solo las tablas y particiones con privilegios de memoria se pueden insertar en la memoria de los usuarios.
El sistema de gestión de base de datos NoSQL en memoria, como MongoDB y Redis, almacena todos los datos en la memoria principal y los actualiza en el disco de forma indefinida. Para garantizar la persistencia, cada solicitud de modificación se guarda en un registro binario. Debido a que el registro es solo para agregar, rara vez es un problema escribirlo con prisa.
¿Oracle Database está en memoria?

Sí, Oracle Database está en memoria. La función de almacenamiento de columnas en la memoria de Oracle permite almacenar y acceder a los datos en la memoria, lo que proporciona un aumento significativo del rendimiento para las cargas de trabajo analíticas. Cuando se combina con la tecnología Real Application Clusters (RAC) de Oracle, Oracle Database puede proporcionar un nivel aún mayor de escalabilidad y disponibilidad.
Database In-Memory es un conjunto de funciones que mejora el análisis en tiempo real y las cargas de trabajo mixtas al proporcionar mejoras significativas en el rendimiento. El almacén de columnas (almacén de columnas IM) se agregó a Oracle Database 12c versión 1 (12.1.0.2) como componente de Oracle Database 12c versión 1 (12.1.0.2). En las bases de datos relacionales tradicionales, los datos se pueden almacenar en formato de filas o columnas. La selección de columnas en una base de datos de columnas corresponde a la selección de filas en una base de datos de filas. La base de datos en memoria incluye un almacén de columnas en la base de datos, optimizaciones de consultas avanzadas y soluciones de acceso. El almacén de columnas de IM guarda copias de todas las columnas, tablas, particiones, etc. en un formato de columnas comprimido diseñado para un escaneo rápido. Mediante el uso de procesamiento paralelo, los almacenes de datos y las bases de datos de uso mixto pueden manejar órdenes de magnitud más rápido.
Como resultado del llenado, los datos basados en filas en el disco se transforman en datos en columnas en el almacén de columnas de IM. Como ejemplo, si desea dividir una tabla o vista en particiones particionadas, todas o una parte de las particiones se pueden configurar para la población. La expresión en memoria (expresión IM) en DBMS_INMEMORY_ADMIN.IME_CAPTURE_EXPRESSIONS permite la identificación y selección de expresiones activas. Cuando se reinicia una instancia de la base de datos, el método de inicio rápido en memoria de la base de datos (IM FastStart) ahorra tiempo al reducir la cantidad de datos que deben completarse en el almacén de columnas de IM. El formato en columnas es ideal para escanear datos debido a su alto rendimiento. Puede utilizar el análisis de datos en tiempo real para explorar nuevas posibilidades e iteraciones. Es posible escanear datos en su formato comprimido sin descomprimirlos primero en Oracle Database.
Un predicado de cláusula WHERE se usa contra datos comprimidos en la base de datos cuando las columnas se comprimen usando algoritmos que permiten comprimir columnas automáticamente. Bloom filtra las uniones avanzadas convirtiendo predicados en tablas de dimensiones pequeñas en filtros de dimensiones grandes. Cuando los datos se almacenan en el almacén de columnas IM, es más fácil organizar y realizar consultas complejas. La creación de estructuras de acceso es un paso fundamental para mejorar el rendimiento de las consultas analíticas. El enfoque más común es crear índices analíticos, vistas materializadas y cubos OLAP. Se debe insertar una fila en una tabla, lo que requiere modificar todos los índices. Las bases de datos de Oracle se almacenan en el formato de almacenamiento en disco de Oracle, que es idéntico al formato de columnas.
Es totalmente compatible con RMAN, Oracle Data Guard y Oracle ASM. No requiere el uso de una herramienta de migración de datos administrada por el usuario. Si utiliza funciones analíticas de Oracle o un código PL/SQL personalizado, tendrá acceso a una gama más amplia de consultas analíticas. Las únicas tareas requeridas son dimensionar el almacén de columnas IM y especificar valores de objeto para la población. En la siguiente tabla, encontrará una lista de las tareas de configuración más básicas de IM Column Store. Puede descargar In-Memory Advisor para PL/SQL y usarlo para analizar la carga de trabajo de procesamiento analítico de su base de datos. El procesamiento analítico difiere de otras actividades de la base de datos en función de la cardinalidad del plan, el uso de consultas paralelas y otros factores.
El In-Memory Advisor no está incluido en los paquetes PL/SQL almacenados en el sistema. Primero debe obtener el paquete de Oracle Support. Las estimaciones del asesor indican mejoras en el rendimiento del procesamiento analítico en función de los siguientes factores. Se pueden eliminar los tiempos de espera para la E/S del usuario, las transferencias de clúster y los eventos de bloqueo de caché de búfer. Dependiendo del tipo de compresión, los costos de compresión incurren en heurística.
¿Qué hay en la memoria en la base de datos?
Una base de datos en memoria, a diferencia de una base de datos basada en disco o SSD, está diseñada para almacenar datos en la memoria principalmente con fines de almacenamiento de datos. Los almacenes de datos creados en la memoria utilizan un método de bajo costo para eliminar la necesidad de acceder a los discos para reducir los tiempos de respuesta.
Ventajas de las bases de datos en memoria
Las bases de datos en memoria se han vuelto más populares en los últimos años porque brindan muchas ventajas sobre las bases de datos tradicionales. La primera ventaja de ellos es que pueden almacenar todo tipo de datos en el mismo sistema, lo que los hace ideales para aplicaciones que necesitan almacenar grandes cantidades de datos no estructurados. Además de la velocidad y eficiencia de las bases de datos en memoria, los usuarios pueden acceder a los datos más rápidamente. Además, las pequeñas empresas y los consumidores pueden utilizar las bases de datos en memoria porque son fáciles de usar y fáciles de administrar.
¿Oracle tiene una base de datos Nosql?
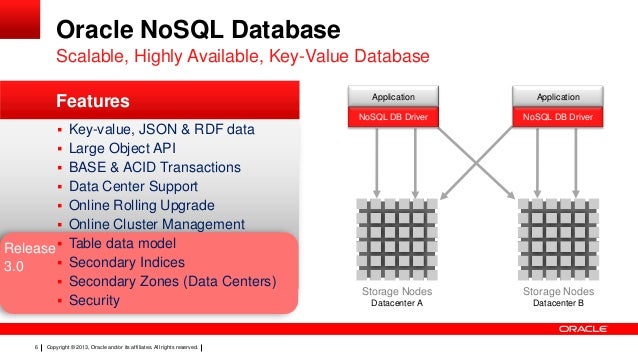
Sí, Oracle tiene una base de datos nosql llamada Berkeley DB. Berkeley DB es una base de datos de código abierto, escalable y de alto rendimiento.
¿Dónde se almacenan los datos Nosql?
En lugar de almacenar datos en una base de datos relacional, las bases de datos NoSQL almacenan datos en documentos. Dicho de otra manera, los dividimos en SQL y una variedad de modelos de datos flexibles para clasificarlos. Una base de datos NoSQL puede ser una base de datos de documentos puros, una base de datos de almacenamiento de clave-valor, una base de datos de columna ancha o una base de datos de gráficos.
Uno de los usos más comunes de las bases de datos NoSQL es el almacenamiento rápido de grandes cantidades de datos no relacionados. NoSQL es un tipo de base de datos que no comparte datos relacionales. Durante la década de 1970, las bases de datos relacionales ganaron popularidad como estándar para el almacenamiento de datos. Según Ben Finkel, un entrenador de CBT, NoSQL se preocupa por la velocidad y la flexibilidad sobre la consistencia y la eficiencia. A pesar de su velocidad y eficiencia, las bases de datos creadas con tecnología relacional no son tan simples como parecen. La base de datos NoSQL no requiere el diseño o la planificación de las estructuras de datos. Esto permite a los desarrolladores crear, crear prototipos e implementar aplicaciones mucho más rápidamente.
Funcionan de manera similar al desarrollo de software ágil, que también es popular. Las bases de datos NoSQL pueden almacenar una variedad de tipos de datos, lo que las hace fáciles de configurar. Las bases de datos NoSQL requieren más poder de cómputo para ejecutarse que las bases de datos relacionales. Raspberry Pi tiene la capacidad de ejecutar pequeñas bases de datos NoSQL , pero los servidores web serán significativamente más exigentes. Los gráficos, a diferencia de los pares o documentos clave:valor, son abstractos. Los nodos y los bordes son los dos componentes de los gráficos. Los nodos pueden contener información sobre un objeto (persona, lugar, cosa, idea, etc.). La relación entre un nodo y sus aristas se explica por aristas. El modelo de datos de columna ancha es similar a las filas y columnas de una base de datos relacional.
Varios factores contribuyen a la creciente popularidad de las bases de datos NoSQL. Las bases de datos relacionales tradicionales son ineficientes, consumen mucho tiempo y son propensas a la corrupción de datos, mientras que las bases de datos basadas en microservicios funcionan mejor. Por una buena razón, JSON es el formato preferido para las bases de datos NoSQL. En pocas palabras, los documentos JSON son más compactos y legibles que otros tipos de documentos. JSON es un formato de representación de datos creado en JavaScript.
JSON es más legible y compacto que el formato de texto estándar.
Las bases de datos NoSQL son más eficientes que las bases de datos relacionales tradicionales en términos de velocidad y rendimiento.
Hacen que sea más fácil de usar.
Son más resistentes a la corrupción de datos que otros animales.

Los diversos tipos de bases de datos Nosql
Las bases de datos NoSQL, como MongoDB, son populares debido a su simplicidad en el almacenamiento de datos, que es mucho más fácil de comprender que los tipos de modelos de datos utilizados en las bases de datos SQL. Los desarrolladores suelen tener acceso directo a la estructura de una base de datos NoSQL.
Una base de datos NoSQL es una base de datos no tabular que almacena datos de una manera diferente a una base de datos relacional (también conocida como SQL). Los diversos tipos de bases de datos NoSQL se basan en sus modelos de datos. Los principales tipos de documentos son gráficos, tablas y declaraciones de clave-valor.
¿Cómo instalo Nosql para almacenar datos en forma estructurada?
Los datos pueden estar estructurados, semiestructurados o no estructurados en una base de datos NoSQL, lo que permite acceder a ellos a través de varios mecanismos. La principal ventaja de su software es que es semiestructurado (JSON, XML, pero no se conocen todos los campos), lo que conduce a datos no estructurados.
¿Cómo se pueden almacenar los datos en una base de datos no relacional?
Debido a que una base de datos no relacional no usa el esquema tabular de la mayoría de las bases de datos tradicionales, no hay filas ni columnas. Las bases de datos no relacionales, por otro lado, utilizan un modelo de almacenamiento optimizado para el tipo de datos que deben almacenarse.
¿Qué es la base de datos Oracle Nosql?
Una base de datos Oracle NoSQL es un almacén de clave-valor distribuido y escalable diseñado para proporcionar alto rendimiento, escalabilidad horizontal y fácil disponibilidad. Oracle NoSQL Database es una base de datos compatible con NoSQL que proporciona almacenamiento de datos de pares clave-valor. Oracle NoSQL Database se ejecuta en un grupo de servidores básicos y proporciona una API de Java simple para acceder a la base de datos.
El SDK de Oracle NoSQL para Spring Data incluye un módulo de implementación de Spring Data. Esta función se puede utilizar para conectarse a un clúster de base de datos Oracle NoQL o al servicio en la nube Oracle NoQL. Agregue la dependencia de maven al XML de su proyecto para usar con el SDK. Para tener acceso a esta información, se debe utilizar lo siguiente. Nosql.spring es un cliente de Oracle. Usando un método NosqlDbConfig para configurar una base de datos. Defina una clase de entidad de la siguiente manera.
Se recomienda crear un repositorio para la extensión Nosql . La clase de aplicación debe escribirse. Al agregar archivos de dependencia a org.springframework.boot:spring-boot, puede comenzar con Spring Framework.
Ejemplo en memoria de Oracle
Un ejemplo de Oracle en memoria sería una empresa que utiliza una base de datos de Oracle para almacenar y procesar sus datos en memoria. Esto permitiría un procesamiento y una recuperación de datos más rápidos, además de reducir la necesidad de almacenamiento en disco.
Sin cambios en la base de código, los tipos de consulta, como las operaciones de agrupar por (consultas analíticas), han mejorado entre 4 y 27 veces. Una consulta de análisis en línea que requería 11 segundos para completarse tomó 399 milisegundos para completarse usando OIM. Es una buena idea mantener las particiones consultadas con más frecuencia en la memoria para tablas particionadas grandes. Cuando una tabla tiene columnas muy anchas, se recomienda excluir las columnas que se consultan con poca frecuencia. Debido a que cada columna no es un componente en memoria de una consulta, Oracle establece la memoria caché del búfer en 0. La relación de compresión aumenta para que se requiera menos procesamiento para procesarla, lo que ahorra espacio. Cuanto más específica sea la consulta, mayor será el impulso de velocidad proporcionado por OIM. Una consulta que devolvió 75 filas de una tabla de 20 m de filas que ejecutaba Oracle In-Memory tomó 69 veces más de lo que habría tomado con DBMS estándar . Como resultado, puede proporcionar mejoras de rendimiento hasta 67 veces más rápidas (en consultas muy selectivas).
Por qué el área Pl/sql merece más memoria
Para PL/SQL y sus objetos asociados, los procedimientos PL/SQL y los objetos globales se almacenan en la memoria del área PL/SQL. Todos estos objetos tienen funciones definidas por el usuario, están vinculados a un paquete PL/SQL y tienen privilegios de objeto. También es posible la ejecución en paralelo de la base de datos Oracle utilizando la memoria del área PL/SQL.
La recomendación general de Oracle es destinar el 95% de la memoria total al área SGA y el 5% al área PL/SQL.
Oracle Nosql contra Cassandra
Existen algunas diferencias clave entre Oracle NoSQL y Cassandra. Por un lado, Cassandra es un proyecto de código abierto, mientras que Oracle NoSQL es un sistema propietario. Cassandra también es una base de datos orientada a columnas, mientras que Oracle NoSQL es una base de datos orientada a filas. Finalmente, Cassandra se enfoca en alta disponibilidad y escalabilidad horizontal, mientras que Oracle NoSQL se enfoca en la facilidad de uso y la gestión de datos jerárquicos.
Apache Cassandra es una base de datos NoSQL muy adecuada para cargas de trabajo de alto rendimiento, escalabilidad lineal, consistencia ajustable y baja latencia en diversas cargas de trabajo. En la mayoría de los casos, Apache Cassandra no será la mejor opción para su caso de uso porque carece de una semántica coherente entre su base de datos relacional y las bases de datos NoSQL con transacciones ACID. Si necesita redundancia de datos reducida y conformidad con ACID, debería considerar usar bases de datos SQL en lugar de Oracle. Los desarrolladores web o móviles no suelen utilizar HBase porque está diseñado para funcionar con casos de uso de lagos de datos fríos o históricos. Una aplicación de Cassandra, por otro lado, está más disponible y es capaz de manejar entornos altamente exigentes.
¿Cuál es la diferencia entre Cassandra y Oracle?
Oracle Database Management System (ODMS) es un sistema de gestión de bases de datos relacionales (RDBMS) que está disponible en dos formatos: S.NO.ORACLE CASSANDRA1. Fue desarrollado por Oracle Corporation en 1980 y creado por Apache Software Foundation en 2008; 2. Fue escrito Se puede acceder al software de código abierto ejecutando siete filas más.
¿Oracle es una base de datos Nosql?
Oracle NoSQL Database Cloud Service facilita a los desarrolladores la creación de aplicaciones utilizando modelos de bases de datos de valores clave, columnas y documentos al ofrecer tiempos de respuesta predecibles en milisegundos, replicación de datos para alta disponibilidad y aplicaciones basadas en documentos.
¿Cassandra y Nosql son iguales?
Cassandra es un sistema de administración de bases de datos de tiendas de columna ancha , gratuito y de código abierto, distribuido, que se basa en el proyecto Cassandra de código abierto.
¿Netflix usa Cassandra?
Cassandra en Amazon Web Services sirve como un componente de infraestructura clave del servicio de transmisión global de Netflix.
Base de datos Oracle Nosql frente a Mongodb
Hay muchas diferencias entre Oracle NoSQL Database y MongoDB. Primero, MongoDB es una base de datos orientada a documentos, mientras que Oracle NoSQL Database es un almacén de clave-valor. Esto significa que MongoDB almacena datos en documentos similares a JSON, mientras que Oracle NoSQL Database almacena datos en pares clave-valor. En segundo lugar, MongoDB admite índices secundarios, mientras que Oracle NoSQL Database no lo hace. En tercer lugar, MongoDB tiene un lenguaje de consulta más completo que Oracle NoSQL Database. En cuarto lugar, MongoDB admite la fragmentación automática, mientras que Oracle NoSQL Database no lo hace. Finalmente, MongoDB es de código abierto, mientras que Oracle NoSQL Database no lo es.
MongoDB es fácil de configurar y brinda una flexibilidad increíble en términos de flexibilidad de diseño. Si sus formatos de datos no son consistentes, una base de datos NoSQL como Oracle NoSQL Database es una buena opción. Si necesita menos redundancia de datos y conformidad con ACID, usar una base de datos SQL puede ser la mejor opción para usted. Debido a que las bases de datos NoSQL, como MongoDB, carecen de interfaces gráficas, normalmente no están diseñadas para usarse junto con bases de datos tradicionales. Para mejorar la usabilidad, debe instalar aplicaciones de terceros que le permitan ver visualmente los esquemas y documentos almacenados. Si no sabe cómo utilizar MongoDB un DBA o un administrador del sistema, es una buena idea ir con un proveedor de alojamiento de MongoDB de terceros.
Diferencias clave entre Mongodb y Oracle
Hay varias diferencias significativas entre MongoDB y Oracle que deben tenerse en cuenta al decidir qué software comprar. La plataforma MongoDB es bien conocida por su capacidad para manejar grandes cantidades de datos, mientras que Oracle se usa más comúnmente para crear aplicaciones empresariales. Además, MongoDB incluye funciones avanzadas para buscar en cualquier campo o rango de consultas, mientras que las capacidades de Oracle son menos limitadas. Oracle escala verticalmente porque se basa en fragmentación, mientras que MongoDB escala horizontalmente porque se basa en fragmentación. Además, MongoDB se basa en una arquitectura de sistema distribuido en lugar de un diseño monolítico de un solo nodo, lo que lo diferencia de Oracle en términos de arquitectura.