
Los pros y los contras de las bases de datos en columnas
Publicado: 2022-11-19Las bases de datos NoSQL son una excelente opción para muchas aplicaciones modernas, pero hay algunas cosas clave a considerar antes de hacer el cambio. Un factor importante es si necesita una base de datos relacional o no. Si lo hace, es posible que una base de datos en columnas no sea la elección correcta. Las bases de datos en columnas son adecuadas para aplicaciones que necesitan analizar grandes cantidades de datos rápidamente. También son una buena opción para aplicaciones que no necesitan el modelo relacional completo y pueden funcionar con un modelo de datos más simple. Sin embargo, las bases de datos en columnas tienen algunos inconvenientes. Pueden ser más difíciles de usar que las bases de datos relacionales y es posible que no admitan todas las funciones que necesita. Antes de decidir si una base de datos en columnas es adecuada para su aplicación, asegúrese de comprender los pros y los contras.
Una base de datos en columnas organiza y almacena datos por columnas en lugar de filas. Utilizan funciones y operaciones agregadas para optimizar las columnas de datos. Las columnas de la base de datos son escalables y se comprimen bien en comparación con otros tipos de bases de datos. En una base de datos en columnas, cada fila de datos está separada en varias columnas por un número de columnas. Las bases de datos en columnas son adecuadas para el procesamiento de big data, inteligencia comercial (BI) y análisis. Las operaciones de fila tienen un tiempo mucho más lento que las operaciones de columna. Los registros de IoT solo pueden contener una pequeña cantidad de elementos de datos a medida que llegan nuevos registros en un flujo constante. Big data tiene el potencial de transformar la forma en que funcionan los sistemas de bases de datos operativas.
Los dos tipos de bases de datos de bases de datos, filas y columnas, pueden cargar datos y realizar consultas utilizando lenguajes de consulta de bases de datos tradicionales como SQL. En muchos casos, las bases de datos, como las bases de datos de filas y columnas, pueden servir como motor para la extracción, transformación, carga y creación de herramientas de datos comunes.
Una base de datos en columnas, un tipo de sistema de administración de bases de datos (DBMS), es aquella que almacena datos en columnas en lugar de filas. Para acelerar la devolución de una consulta, las columnas en una base de datos en columnas se pueden escribir y leer de manera eficiente desde y en el disco duro.
Hoy veremos cómo funcionan las columnas en una base de datos columnar y las compararemos con una base de datos orientada a filas más tradicional (p. ej., MySQL). Repasaremos qué es una base de datos en columnas en este artículo, así como sus ventajas y desventajas.
¿Cuáles son algunos ejemplos de una base de datos NoSQL? Microsoft SQL Server es un sistema de gestión de bases de datos relacionales creado por Microsoft.
¿Mongodb es una base de datos columnar?
Mongodb no es una base de datos en columnas.
Se está volviendo más popular porque proporciona un rendimiento de consulta mejorado en consultas analíticas. Los datos en las bases de datos en columnas se almacenan de manera más eficiente que en los almacenes de datos basados en bases de datos porque los datos se almacenan en columnas. Las consultas analíticas realizadas en bases de datos en columnas tienen una mayor ventaja de rendimiento. En comparación con el almacenamiento orientado a filas, el almacenamiento en columnas es mucho más eficiente en términos de espacio de almacenamiento y rendimiento de consultas. Debido a que los datos se almacenan en forma de columnas, los datos se pueden leer y escribir más fácilmente.
¿Cuáles son las bases de datos Nosql?
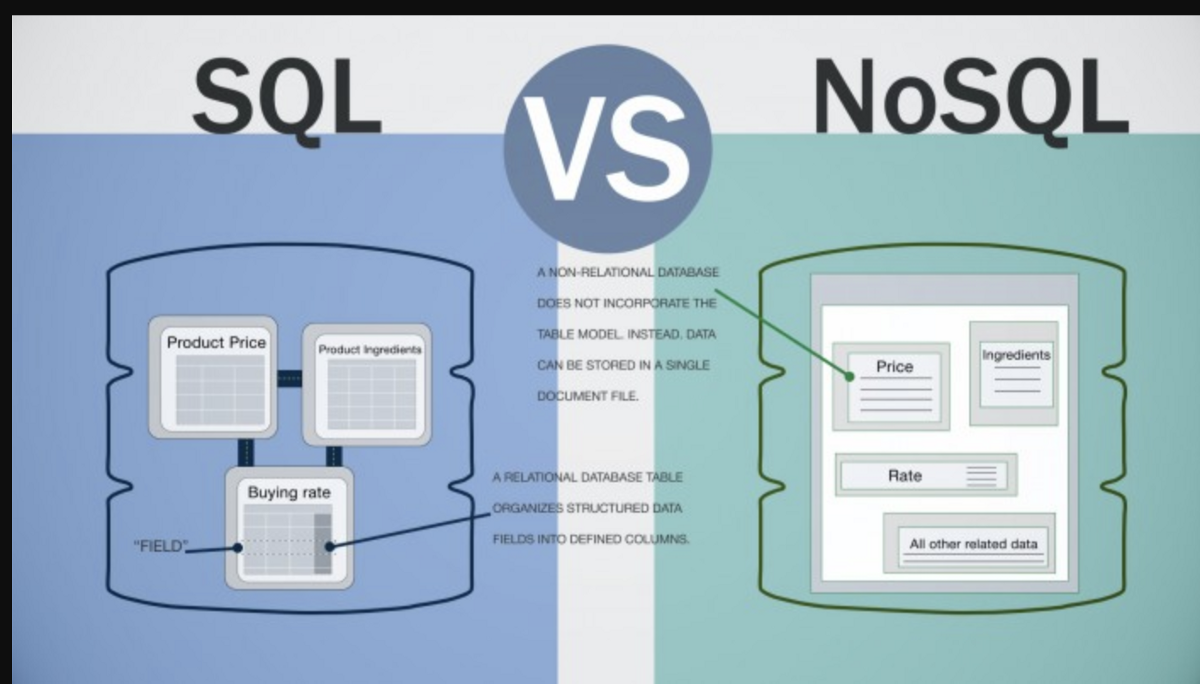
Las bases de datos NoSQL son bases de datos que no utilizan el modelo de base de datos relacional tradicional. En su lugar, utilizan una variedad de modelos diferentes, incluidos documentos, gráficos, valores clave y columnas. Las bases de datos NoSQL a menudo son más adecuadas para manejar grandes cantidades de datos que no son adecuados para el modelo relacional.
Un sistema NoSQL es un tipo de base de datos que no se basa en SQL. El modelo de datos utilizado por el equipo de modelado de datos difiere del modelo tradicional de tabla de filas y columnas utilizado en los sistemas de administración de bases de datos relacionales. Las bases de datos NoSQL, además de ser bastante diferentes entre sí, también son bastante diferentes entre sí. Las bases de datos de documentos normalmente se implementan con una arquitectura de escalamiento horizontal para los tipos de documentos más comunes. Las plataformas de comercio electrónico, las plataformas comerciales y el desarrollo de aplicaciones móviles son ejemplos de cómo estas plataformas pueden beneficiar a una empresa. El objetivo principal de comparar MongoDB y Postgres es proporcionar una comparación detallada de las principales bases de datos NoSQL. La capacidad de una base de datos en columnas para agregar el valor de una sola columna es ideal para analizar rápidamente una columna específica.
Debido a que la forma en que se escriben los datos dificulta que sean consistentes, deben basarse en una variedad de fuentes. Las bases de datos de gráficos están optimizadas para capturar y buscar conexiones entre elementos de datos para capturarlos y buscarlos. La sobrecarga asociada con UNIR varias tablas en SQL se elimina con el uso de estos métodos.
MongoDB normalmente almacena documentos en una colección conocida como colección. Es la colección de documentos que están vinculados entre sí por algún aspecto. Los datos de las colecciones suelen ser utilizados por varias aplicaciones para almacenar datos.
Los datos de MongoDB se almacenan en un árbol B, lo que significa que están organizados como cubo o nivel. Un depósito es una colección de datos a la que un navegador accede con frecuencia. El nivel es más grande porque hay más cubos en él. Los datos en un árbol B se pueden clasificar en orden ascendente por clave.
Debido a que MongoDB es tan simple de escalar, es una plataforma fantástica para escalar. Si su clúster experimenta un aumento en la carga, es posible que deba agregar más servidores. Además, MongoDB se puede agrupar para proporcionar datos HA (alta disponibilidad).
Por qué las bases de datos Nosql están ganando popularidad
A pesar de que las bases de datos NoSQL se están volviendo más populares en muchos casos, siguen siendo una alternativa a las bases de datos relacionales. Los datos que no se pueden almacenar en una base de datos relacional, como gráficos grandes o datos que cambian regularmente, son particularmente atractivos para ellos.
Ejemplo de base de datos en columnas Nosql
Una base de datos en columnas es un sistema de administración de bases de datos (DBMS) que almacena datos en columnas en lugar de filas. Los sistemas orientados a columnas suelen ser más rápidos para las cargas de trabajo de análisis que los sistemas tradicionales orientados a filas.
Por ejemplo, una base de datos en columnas puede almacenar datos de empleados y cada columna contiene datos como la identificación del empleado, el nombre, el cargo, el salario, etc. Una base de datos orientada a filas almacenaría los mismos datos con cada fila que contiene la identificación, el nombre, el cargo, el salario, etc. de un empleado.
NoSQL es un avance importante en el campo de los datos relacionales porque elimina la necesidad de sistemas altamente especializados o que consumen mucho tiempo. Las bases de datos NoSQL de documentos, gráficos, columnas y valores de fila son los cuatro tipos principales. Los almacenes de documentos contienen esquemas de datos complejos y pares de claves asociativas. Las columnas de la base de datos organizan los datos en columnas y funcionan de la misma manera que lo hacen las bases de datos relacionales. Existe una escalabilidad de cuadrícula de horizontal a infinito disponible en las bases de datos de columnas . La compresión es un método de almacenamiento que está bien hecho y los almacenes de columnas proporcionan mucho espacio de almacenamiento. La velocidad a la que se ejecutan las consultas de agregación suele ser más rápida que la de una base de datos relacional.
Debido a la naturaleza horizontal del diseño de datos, las aplicaciones OLTP no se pueden usar junto con almacenes en columnas. Las tiendas de columnas , como solución, tienen el potencial de ser extremadamente poderosas, pero también tienen el potencial de ser extremadamente limitadas. Aunque las columnas ofrecen menos garantías de consistencia y aislamiento que las filas, cada fila debe reescribirse varias veces. Las bases de datos NoSQL son más vulnerables a los ataques en línea debido a la falta de funciones de seguridad nativas. Si la ciberseguridad es una alta prioridad para usted, debe usar un modelo relacional o definir su esquema.
Base de datos Nosql
Una base de datos NoSQL es una base de datos no relacional que no utiliza el modelo tradicional de base de datos relacional basado en tablas. Las bases de datos NoSQL se utilizan a menudo para big data y aplicaciones web en tiempo real.
Base de datos Las bases de datos NoSQL no almacenan datos en las bases de datos relacionales tradicionales . Los tipos de documento, los tipos de clave-valor, los tipos de columna ancha y los tipos de gráfico son los más comunes. El costo de almacenar datos se ha reducido drásticamente en los últimos años, lo que ha resultado en el desarrollo de bases de datos NoSQL. Pueden almacenar una gran cantidad de datos no estructurados, lo que permite a los desarrolladores seleccionar qué aspectos de los datos desean guardar. Las bases de datos de documentos, las bases de datos de valores clave, los almacenes de columnas anchas y las bases de datos de gráficos son ejemplos de bases de datos NoSQL. Debido a que no se requieren uniones, las consultas se realizan más rápido. Se pueden usar casos de uso intensivos en datos, como análisis financiero y lecturas de IoT de cajas de arena para gatos inteligentes, mientras que se pueden usar aplicaciones menos serias, como casos de uso divertidos y entretenidos, como envases de alimentos inteligentes.
En este tutorial, repasaremos cuándo y por qué debería considerar las bases de datos NoSQL. Además, veremos algunos de los conceptos erróneos más comunes sobre las bases de datos NoSQL. Según DB-Engines, MongoDB es la base de datos NoSQL más popular del mundo. En este tutorial, aprenderá cómo consultar una base de datos MongoDB sin instalar nada en su computadora. Los clústeres de bases de datos son un ejemplo de una base de datos MongoDB. Tan pronto como tenga un clúster, Atlas comenzará a almacenar datos. Tiene tres opciones para crear una base de datos en Atlas Data Explorer, MongoDB Shell o MongoDB Compass: manual o automatizada.
En este caso, se importará el conjunto de datos de muestra de Atlas. Existen numerosos beneficios para las bases de datos NoSQL además de sus modelos de datos flexibles, escala horizontal, consultas ultrarrápidas y facilidad de uso. El Explorador de datos se puede utilizar para insertar nuevos documentos, editar documentos existentes y eliminarlos. El marco de agregación es una herramienta extremadamente poderosa para analizar sus datos. El uso de gráficos para visualizar datos almacenados en Atlas y Atlas Data Lake es la forma más sencilla de hacerlo.
Una base de datos clave-valor es el tipo más simple de NoSQL, con múltiples tablas que contienen claves y valores. La clave solo se requiere para el acceso a los datos, lo que simplifica la lectura y la escritura. Sin embargo, este tipo de base de datos no es adecuado para grandes conjuntos de datos porque cada clave de la base de datos debe ser única.
Los datos se almacenan en tablas que contienen columnas, que almacenan las claves y los valores de las bases de datos basadas en columnas. Debido a su versatilidad, una base de datos basada en columnas puede almacenar datos durante un período de tiempo más prolongado que una base de datos sin columnas.
Las bases de datos de documentos, a diferencia de las bases de datos de columnas, almacenan datos en tablas con columnas que almacenan claves y valores. Las bases de datos basadas en documentos, por otro lado, almacenan datos en archivos, de forma similar a los correos electrónicos. Debido a que los documentos son fáciles de leer y comprender, los datos se pueden buscar y ver de manera sencilla.
Una base de datos basada en gráficos es similar a una base de datos basada en documentos en que los datos se almacenan en tablas que contienen columnas con claves y valores. Por el contrario, los gráficos, que son similares a las redes en términos de almacenamiento de datos, se almacenan en bases de datos basadas en gráficos. Los nodos de datos se pueden conectar y los patrones se pueden identificar con facilidad.
Tipos de bases de datos Nosql para cada necesidad
Las bases de datos de documentos como MongoDB son adecuadas para aplicaciones que necesitan almacenar información en un formato flexible y modular. En MongoDB, JSON, texto y BSON son compatibles. Esto lo convierte en una excelente opción para aplicaciones como blogs y wikis, que almacenan grandes cantidades de datos no estructurados.
Cassandra y otras bases de datos basadas en columnas son opciones excelentes para aplicaciones que necesitan almacenar grandes cantidades de datos en formato de columnas. Los formatos de datos como el propio formato binario de Avro y Cassandra se pueden usar además del almacenamiento basado en texto dentro de HBase. Debido a que tiene la capacidad de almacenar datos que no caben en una base de datos relacional, es ideal para aplicaciones que requieren una gran cantidad de datos.
DynamoDB y otras bases de datos de valores clave se adaptan bien a las aplicaciones que normalmente almacenan cantidades de datos pequeñas o medianas. DynamoDB, por ejemplo, admite formatos de datos binarios y JSON. Esto lo convierte en una excelente opción para aplicaciones que almacenan datos que son demasiado pequeños para una tabla relacional y a los que se accede con frecuencia pero que no requieren un formato específico, así como para aplicaciones que necesitan almacenar datos a los que se accede con frecuencia pero que no requieren un formato específico. formato.
Es muy adecuado para aplicaciones que requieren la integración de elementos de datos que se almacenan en bases de datos de gráficos, como Neo4j. Por ejemplo, los formatos de datos como JSON, Atom y Graph se pueden usar en bases de datos de gráficos. Es ideal para aplicaciones que necesitan almacenar datos que son demasiado complejos para almacenarlos en una base de datos relacional o que almacenan datos a los que se accede con frecuencia pero que no requieren almacenarse en un formato específico.

Base de datos columnar de código abierto
Una base de datos columnar es un tipo de base de datos que almacena datos en columnas en lugar de filas. Este tipo de base de datos se usa a menudo para aplicaciones de análisis y almacenamiento de datos porque puede proporcionar un mejor rendimiento y escalabilidad que una base de datos tradicional basada en filas.
Hay varias bases de datos en columnas de código abierto disponibles, como Apache Cassandra, Apache HBase y Apache Drill. Cada una de estas bases de datos tiene sus propias fortalezas y debilidades, por lo que es importante elegir la adecuada para sus necesidades específicas.
Estas bases de datos son ideales para un flujo de trabajo de análisis eficiente porque son rápidas y escalables al mismo tiempo. En lugar de almacenar datos en filas, las columnas se utilizan en la base de datos de columnas. El uso de almacenamiento basado en columnas mejora el rendimiento de las consultas de la base de datos al reducir significativamente la cantidad de intentos de E/S. Se ha utilizado para impulsar Amazon Redshift y Snowflake, así como otros almacenes relacionales. Para mejorar el rendimiento de las bases de datos en columnas, se utilizan clústeres de hardware de bajo costo para escalarlas. En las bases de datos tradicionales , las filas se dividen en varias secciones de datos. Los elementos más relevantes de una base de datos en columnas son accesibles en segundos.
Incluso si la base de datos es grande, esto aumenta la velocidad de consulta. El costo de procesar y almacenar la mayor cantidad de datos también está aumentando. Parquet y ORC son dos de los formatos más utilizados para columnas en bases de datos. El parquet se usa para presentar columnas planas de datos de una manera más efectiva. ORC es un formato de archivo que se diseñó especialmente para las cargas de trabajo de Hadoop y se optimizó para lecturas de transmisión de gran tamaño. Hevo Data, un canal de datos sin código, le permite integrar datos de varias bases de datos con más de 100 fuentes y cargarlos en su herramienta de BI preferida. Apache Druid es una base de datos de análisis en tiempo real basada en software de código abierto que puede ejecutar consultas OLAP en grandes conjuntos de datos a un ritmo mucho más rápido.
El motor de almacenamiento de datos distribuidos de código abierto Apache Kudu se utiliza para ejecutar procesos analíticos rápidos en cantidades masivas de información. El modelo de almacenamiento de MonetDB se basa en la fragmentación vertical y su arquitectura de ejecución de consultas se basa en computadoras modernas. El motor de informes analíticos de ClickHouse permite la generación de informes en tiempo real. BigQuery es el resultado del motor de consultas distribuidas de Google, conocido como Dremel. La arquitectura sin servidor de Dremel puede procesar terabytes de datos en segundos utilizando computación distribuida. La compresión, la proyección justo a tiempo y la partición horizontal y vertical son algunos de los beneficios del almacenamiento basado en columnas. Los datos se pueden almacenar en filas en una base de datos en columnas, que es una base de datos orientada a filas.
Escalan utilizando clústeres con tecnología de bajo costo para aumentar el rendimiento. Las bases de datos en columnas se pueden usar para una variedad de propósitos en el procesamiento de big data, inteligencia comercial (BI) y análisis. Los dispositivos de Internet de las cosas (IoT) almacenan una gran cantidad de datos en sus centros de datos.
Las tres bases de datos de almacenamiento de datos orientadas a columnas más populares
Apache Cassandra es un conocido sistema de almacenamiento de datos en una variedad de bases de datos orientadas a columnas. Cassandra es un proyecto de código abierto del lado del servidor que puede manejar cantidades masivas de datos en muchos servidores básicos. DynamoDB, por otro lado, emplea un modelo de base de datos NoSQL y puede almacenar cualquier tipo de datos. MariaDB conserva el modelo relacional y SQL al tiempo que permite una generación de consultas analíticas más rápida y sencilla, lo que la convierte en una opción popular para muchas bases de datos en columnas.
Mejor base de datos columnar
No hay una respuesta definitiva a esta pregunta, ya que depende de las preferencias y necesidades individuales. Sin embargo, algunas de las bases de datos en columnas más populares incluyen Amazon Redshift, Google BigQuery y Microsoft SQL Server. Todas estas bases de datos son altamente escalables y ofrecen un rendimiento excelente para las cargas de trabajo de análisis y almacenamiento de datos.
Los datos en una base de datos columnar se almacenan en columnas en lugar de filas. En comparación con las bases de datos de filas tradicionales, las bases de datos en columnas brindan una variedad de ventajas, que incluyen velocidad y eficiencia. Sadas Engine es el sistema de gestión de bases de datos en columnas más potente y flexible disponible tanto en las instalaciones como en la nube. ClickHouse es un sistema de administración de bases de datos de código abierto que es fácil de usar. Amazon Redshift, el almacén de datos en la nube más rápido del mundo, continúa creciendo en velocidad. ClickHouse utiliza todo el hardware disponible en todo su potencial para procesar cada consulta lo más rápido posible. El motor de búsqueda y análisis de Rockset potencia las pantallas de tableros en vivo y las aplicaciones en tiempo real.
Vertica es la base de datos analítica avanzada más rápida y escalable del mercado. El lenguaje ANSI SQL es ideal para el análisis de petabytes porque puede manejar datos a velocidades ultrarrápidas y al mismo tiempo elimina la sobrecarga operativa. Análisis bajo demanda a escala con un costo de propiedad de tres años entre un 26 % y un 34 % más bajo que las alternativas de almacenamiento de datos en la nube. Puede encriptar sus datos a pedido y en casa con claves de encriptación administradas por la empresa o puede configurarlo en encriptación a voluntad. Greenplum Database es una plataforma de datos paralelos masivos de código abierto que proporciona capacidades de análisis, aprendizaje automático e inteligencia artificial. La herramienta proporciona análisis de datos en tiempo real en volúmenes de datos a escala de petabytes a la velocidad del rayo. Con su diseño central, Druid combina ideas de almacenes de datos, bases de datos de series temporales y sistemas de búsqueda para crear una base de datos de análisis de alto rendimiento en tiempo real.
Apache 2 es el código fuente de este proyecto. MariaDB Platform, una base de datos empresarial de código abierto, es la base de esta solución. Esta plataforma puede admitir una amplia gama de cargas de trabajo transaccionales, analíticas e híbridas. MariaDB se puede implementar en hardware básico o en una nube pública, según el tipo de hardware utilizado. Estudiantes, profesores, investigadores, empresarios, pequeñas empresas y corporaciones multinacionales de todo el mundo pueden unirse a la comunidad de MonetDB. Proporcionamos una base de datos como servicio para CrateDB, que está completamente administrada. El almacenamiento de tablas facilita la ampliación de sus datos al eliminar la necesidad de fragmentación manual.
Se replican tres veces los datos almacenados de una región mediante el almacenamiento con redundancia geográfica. Es sencillo portar aplicaciones heredadas o crear otras nuevas con el modelo de datos simple de Kudu. Parquet permite que los esquemas de compresión se especifiquen por columna y está preparado para el futuro, por lo que se pueden agregar nuevos esquemas de compresión cuando sea necesario. Hypertable, como su nombre lo indica, está diseñado para resolver el problema de escalabilidad en sus propios términos. Está diseñado para admitir cargas de trabajo OLAP basadas en DBMS InfiniDB columnar . El rendimiento de QikkDB en big data y operaciones poligonales complejas no tiene paralelo. La base de datos qikkDB está construida con las siguientes características: Es una base de datos columnar de serie temporal histórica multiplataforma de alto rendimiento con un motor de cómputo en memoria.
Q, un procesador de transmisión y lenguaje de programación, está diseñado para permitirle expresarse en tiempo real. El índice ordenado, el índice de mapa de bits y el índice invertido son las tres tecnologías de indexación que se pueden conectar. Apache versión 2.0 tiene licencia para este proyecto.
Las bases de datos orientadas a columnas son el futuro
Un gran número de bases de datos se han diseñado en torno a columnas en los últimos años. Debido a que estas bases de datos almacenan datos en filas y columnas, son fáciles de usar y administrar. Hay varias bases de datos orientadas a columnas disponibles, incluidas MariaDB, CrateDB, ClickHouse, Greenplum Database, Apache Hbase, Apache Kudu, Apache Parquet, Hypertable y MonetDB. Los datos de documentos, gráficos y columnas se pueden generar en DynamoDB utilizando un modelo de base de datos NoSQL. MongoDB, la empresa detrás de la base de datos del almacén de documentos, anunció el lanzamiento de la indexación del almacén de columnas, que permite a los desarrolladores crear consultas analíticas en sus aplicaciones.
Ejemplo de base de datos en columnas
Una base de datos columnar es un tipo de base de datos que almacena datos en columnas en lugar de filas. Este tipo de base de datos se usa a menudo para aplicaciones de análisis y almacenamiento de datos porque puede proporcionar un mejor rendimiento y escalabilidad que una base de datos tradicional basada en filas. Un ejemplo de una base de datos en columnas es Apache HBase.
Las operaciones de la base de datos se diferencian de las de otras bases de datos en que las columnas suelen distribuir la información en filas. La capacidad de analizar grandes conjuntos de datos es especialmente atractiva para las bases de datos en columnas. Los almacenes de documentos que utilizan bases de datos NoSQL han ganado popularidad en los últimos años. Las bases de datos de gráficos también se están volviendo cada vez más populares a medida que más personas las usan porque pueden mapear datos altamente interconectados con mucha precisión. Durante mucho tiempo, se han utilizado sistemas de gestión de bases de datos en columnas. A pesar de que todavía hay algunas implementaciones disponibles, hay varios sistemas que se han desarrollado. El acceso a las aplicaciones transaccionales suele ser diferente del acceso a otras aplicaciones. Esta tarea se realizaría mucho más lentamente en una base de datos en columnas que en una base de datos convencional .
Por qué las bases de datos orientadas a columnas son cada vez más populares
Las bases de datos orientadas a columnas como Cassandra, MariaDB y CrateDB están ganando popularidad como soluciones de almacenamiento de datos para aplicaciones que manejan grandes cantidades de datos. Dado que los datos se pueden almacenar en una base de datos con varias filas de la misma tabla (familia de columnas), es más fácil almacenar datos y mejorar el rendimiento.
Están disponibles varias bases de datos orientadas a columnas, como MariaDB, CrateDB, ClickHouse, Greenplum Database, Apache Hbase, Apache Kudu y Apache Parquet. Todas estas bases de datos son de código abierto y se han utilizado con éxito en una variedad de aplicaciones.