
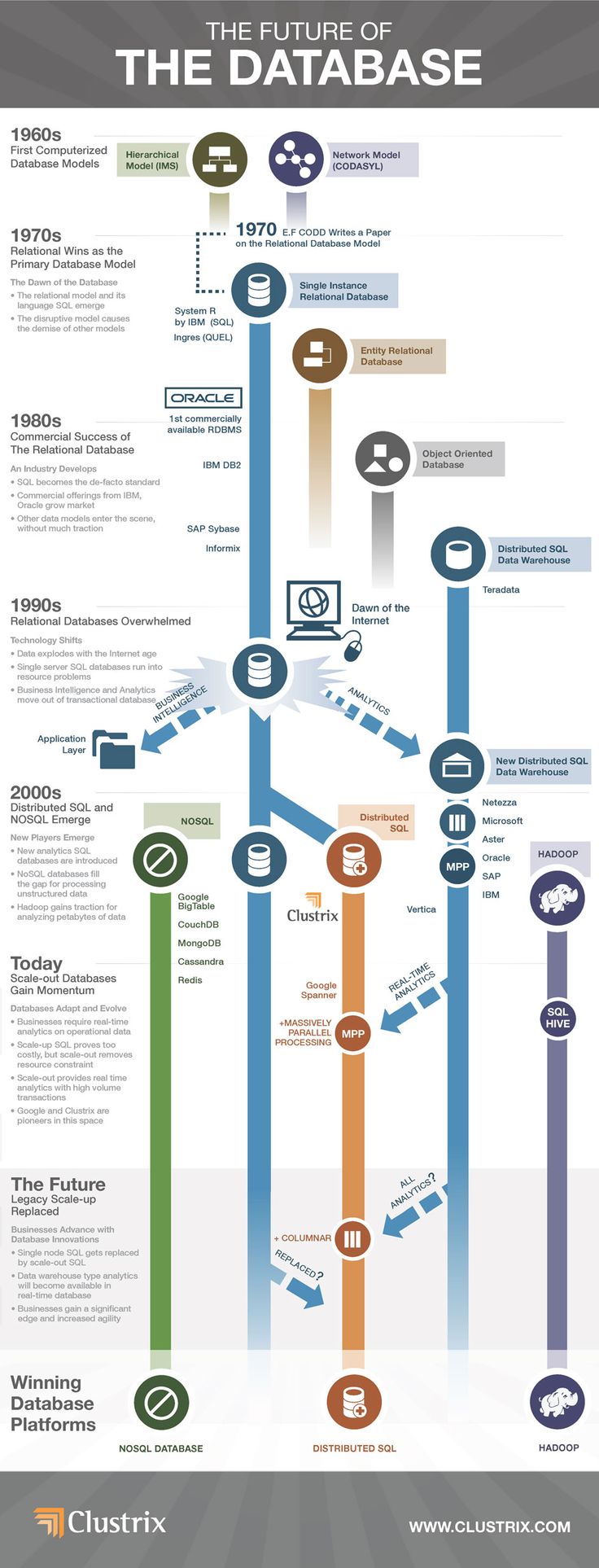
Por qué las bases de datos Nosql son mejores para Big Data
Publicado: 2022-11-19Las bases de datos Nosql son mejores para Big Data por varias razones. Están diseñados para ser escalables horizontalmente, lo que significa que pueden manejar más datos al agregar más servidores. También están diseñados para tener una alta disponibilidad, lo que significa que pueden seguir funcionando incluso si fallan algunos servidores. Y pueden manejar un alto rendimiento, lo que significa que pueden manejar muchas lecturas y escrituras.
El uso de bases de datos NoSQL fue popular entre empresas de Internet como Amazon, Google, LinkedIn y Facebook en respuesta a los inconvenientes de RDBMS. A medida que aumentan los requisitos de procesamiento de datos, NoSQL es una solución adaptable y basada en la nube para administrar datos no estructurados. Según Esprdo de Oliveira, Director de Desarrollo Comercial de FairCom, hay algunos problemas con NoSQL que una base de datos tradicional no puede manejar. Se utiliza para impulsar la tecnología de bases de datos en la nube, la Web, big data y los grandes usuarios. Las bases de datos NoSQL son un subconjunto de bases de datos que almacenan datos de diversas formas. Los tipos más populares son gráficos, pares clave-valor, columnas y documentos. Las empresas que dependen en gran medida de los datos, como Amazon, eBay, etc., requerían una base de datos como NoSQL o SQL que pudiera adaptarse mejor al modelo de datos cambiante, permitiéndoles administrar sus operaciones de manera más eficiente.
El almacenamiento y el procesamiento de datos en tiempo real pueden lograrse mediante bases de datos NoSQL, que son mucho más sofisticadas que las bases de datos relacionales. Debido a la creciente velocidad y variedad de datos, el panorama de las bases de datos está inundado con una mayor velocidad de datos, una variedad de datos en expansión y un volumen explosivo de datos, todo lo cual es requerido por las aplicaciones de Big Data. Las bases de datos NoSQL como HBase, Cassandra y Couchbase son El concepto de prioridades CAP (Coherencia-Disponibilidad-Tolerancia de partición) es un concepto de base de datos NoSQL.
El esquema de la base de datos es fijo en las bases de datos relacionales. No hay coherencia en las bases de datos NoSQL. No hay transacciones en las bases de datos NoSQL (solo admiten transacciones simples). En una base de datos relacional , se admiten transacciones (así como transacciones complejas con uniones).
Hay una razón por la que las bases de datos NoSQL han ganado popularidad en los últimos años: son fáciles de entender y no requieren modelos de datos complejos como las bases de datos SQL. Además, las bases de datos NoSQL frecuentemente permiten a los desarrolladores modificar directamente la estructura de datos.
Los desarrolladores pueden beneficiarse de las bases de datos NoSQL de varias maneras, incluidos resultados de consulta más rápidos, modelos de datos flexibles, escalado horizontal y un proceso de desarrollo optimizado. Las bases de datos de documentos, las bases de datos de valores clave, los almacenes de columnas anchas y las bases de datos de gráficos son solo algunos ejemplos de bases de datos NoSQL.
¿Nosql es bueno para grandes datos?
Es fundamental que las soluciones de almacenamiento para big data sean capaces de procesar y almacenar grandes cantidades de datos para poder procesarlos y analizarlos. Una base de datos NoSQL, también conocida como base de datos no relacional, está diseñada para manejar una gran cantidad de datos mientras se escala horizontalmente.
Como lo demostraron MongoDB, Apache Cassandra y HBase, las bases de datos NoSQL han experimentado un crecimiento sin precedentes a lo largo del tiempo. En comparación con el software de código abierto, NoSQL es una mejor opción para las empresas que requieren un procesamiento y análisis rápidos de grandes cantidades de datos diversos y no estructurados. Estas bases de datos tienen ventajas de alta capacidad de respuesta, escalabilidad y disponibilidad en comparación con los productos RDBMS tradicionales. Las organizaciones que desean almacenar y analizar cantidades masivas de archivos y conjuntos de datos estructurados, semiestructurados y no estructurados prefieren una base de datos NoSQL, especialmente en tiempo real. Se requerirán más servidores físicos a medida que crezcan los datos en el clúster. Las bases de datos NoSQL utilizan una arquitectura de escalado horizontal que las hace eficientes. Las bases de datos NoSQL tienen un costo por transacción más bajo que las bases de datos tradicionales debido a su naturaleza de código abierto. NoSQL y RDBMS, así como sus puntos fuertes, se pueden usar juntos para crear un sistema de gestión de datos eficiente.
¿Qué base de datos es mejor para grandes datos?
No hay una respuesta definitiva para esta pregunta, ya que depende de varios factores, como las necesidades específicas del usuario, el tipo de datos que se almacenan y el presupuesto. Sin embargo, algunas bases de datos ampliamente utilizadas para grandes conjuntos de datos incluyen Apache Hadoop, Apache Cassandra y MongoDB.
Por qué Nosql es mejor

Hay muchas razones por las que NoSQL se considera una mejor opción para la gestión de datos moderna. Primero, las bases de datos NoSQL son muy buenas para manejar datos a gran escala debido a sus capacidades de escalado horizontal. También se pueden integrar fácilmente con soluciones de big data. En segundo lugar, las bases de datos NoSQL ofrecen un modelo de datos mucho más rico que las bases de datos relacionales tradicionales , lo que las hace más adecuadas para manejar datos complejos. Finalmente, las bases de datos NoSQL generalmente son mucho más fáciles de usar y requieren menos mantenimiento que las bases de datos relacionales.
Los datos son un componente clave de todos los subcampos de la ciencia de datos. Es más probable que necesite almacenar datos en un sistema de administración de bases de datos (DBMS). Al interactuar y comunicarse con el DBMS, se requiere su idioma. SQL (lenguaje de consulta estructurado) es el lenguaje utilizado para interactuar con los DBMS. Otro término que ha surgido recientemente en el campo de las bases de datos es el de bases de datos NoSQL. Las bases de datos NoSQL, como las bases de datos no relacionales, no almacenan datos en tablas o registros. En cambio, la estructura de almacenamiento de datos está configurada para cumplir requisitos específicos.
Los cuatro tipos más comunes son bases de datos de gráficos, bases de datos orientadas a columnas, bases de datos orientadas a documentos y pares clave-valor. Las bases de datos orientadas a documentos, como MongoDB, son un ejemplo de una base de datos de Python. Cuando utilice una base de datos NoSQL, podrá crear una estructura de datos más fácilmente. Las bases de datos SQL, por otro lado, tienen una estructura más rígida y un tipo de datos más bajo. Si desea aprender SQL como principiante, comience con SQL y luego pase a NoSQL. Existen numerosas ventajas y desventajas para cada uno de estos programas, y debe considerar sus ventajas y desventajas en función de sus datos, aplicación y lo que hace que sea más fácil de desarrollar. No hay duda de que SQL es superior a NoSQL o la forma en que está escrito. Si escucha sus datos, tomará la mejor decisión para usted.
Sql vs Nosql para Big Data
SQL también funciona mejor cuando se trata de consultas complejas porque proporciona una mayor velocidad y recuperación. Sin embargo, si desea ampliar la estructura estándar de RDBMS o crear un esquema flexible, las bases de datos NoSQL son la mejor opción.

Es fundamental seleccionar una base de datos relacional (SQL) o una base de datos no relacional (Nosql) para aprovechar al máximo sus inversiones en bases de datos. Para tomar una decisión informada sobre el tipo de base de datos requerida para un proyecto, primero debe comprender las diferencias entre los dos. La elasticidad es un requisito fundamental para las bases de datos NoSQL, por lo que son más adecuadas para big data. Según el requisito, pueden ser pares clave-valor, bases de datos de gráficos basadas en documentos o almacenes de columnas anchas. Como resultado, cada documento puede tener su propia estructura distinta, lo que permite crear documentos sin tener una estructura definida. En términos de NoSQL, existen numerosas preguntas, particularmente en el contexto de big data y análisis de datos. Algunas bases de datos NoSQL requieren experiencia interna para configurarlas y administrarlas, mientras que otras dependen en gran medida del apoyo de la comunidad.
La regla general es que NoSQL no es más rápido que SQL, al igual que es más rápido para realizar operaciones de lectura o escritura en una sola entidad de datos. Debido a que las bases de datos NoSQL permiten grandes cantidades de datos, son ideales para Google, Yahoo y Amazon. Las bases de datos relacionales existentes no pudieron satisfacer la creciente demanda de procesamiento de datos. Una base de datos NoSQL tiene el potencial de crecer y volverse más poderosa según sea necesario. Este tipo de aplicación es ideal para aplicaciones sin definiciones de esquema específicas, como sistemas de administración de contenido, aplicaciones de big data y análisis en tiempo real.
¿Nosql es bueno para grandes conjuntos de datos?
Es su responsabilidad convertir los datos no estructurados y semiestructurados en un formato que puedan utilizar las herramientas analíticas. Estos requisitos distintivos han hecho que las bases de datos NoSQL (no relacionales) como MongoDB sean una opción poderosa para almacenar grandes cantidades de datos.
¿Sql es bueno para Big Data?
Los motores SQL-on-Hadoop basados en Hadoop se pueden usar para manejar grandes bases de datos. El mito de que los grandes datos son demasiado grandes para los sistemas SQL ahora está refutado y no es cierto en absoluto. Es, de hecho, un mito. SQL es un marco excelente para construir sistemas de big data.
¿En qué se diferencian las bases de datos Big Data y Nosql?
No hay una respuesta única a esta pregunta, ya que los dos términos pueden significar cosas diferentes para diferentes personas. Sin embargo, en general, las bases de datos big data y nosql se usan indistintamente para referirse a almacenes de datos que están diseñados para contener grandes cantidades de datos y que no se basan en el modelo de base de datos relacional tradicional.
La base de datos NoSQL , también conocida como código abierto, se basa en una base de datos de código abierto. Las categorías de las bases de datos NoSQL están determinadas por el modelo de datos de la base de datos. Cada uno de los modelos de datos se compone de un almacén de valores clave, un documento, una entrada de columna y un modelo de datos gráfico. Se puede acceder a una base de datos móvil en una variedad de dispositivos y ubicaciones. También hay una tendencia a realizar múltiples tareas en general. La flexibilidad de las bases de datos NoSQL, así como la falta de un esquema fijo, les permite ser más flexibles que las bases de datos tradicionales cuando se trata de abordar la variedad de características de datos por las que se conoce a Big Data. Debido a las propiedades ACID de las bases de datos, no tienen una alta disponibilidad debido a la falta de finalización total o completa de las transacciones.
Debido a que NoSQL es de código abierto, esto significa que es económicamente viable. Debido a todas estas ventajas y al auge de la industria, habrá un aumento en la cantidad de personas que pueden trabajar en bases de datos NoSQL. Craigslist es un sitio web de anuncios clasificados y anuncios de empleo que sirve a 570 ciudades en 50 países de todo el mundo. Coursera6, una plataforma educativa en línea fundada en 2001, brinda oportunidades educativas a universidades de todo el mundo. Ha crecido a 10 millones de estudiantes durante la última década, con el uso de NoSQL, bases de datos Cassandra y una base de datos tradicional.
Bases de datos Nosql: por qué están ganando popularidad
Las características de una base de datos NoSQL son las siguientes: Su diseño les permite manejar grandes cantidades de datos. Se les conoce como “escalas”. Los datos se pueden procesar en una variedad de formas usándolos. La cantidad de datos en estas bases de datos es mayor que en las bases de datos tradicionales.
Análisis de datos Nosql
Es fácil entender por qué NoSQL significa "No solo SQL". En este caso, los datos no se dividen en varias tablas porque permite que todo el conjunto de datos esté contenido en una sola estructura. Cuando trabaje con grandes cantidades de datos, el rendimiento de las consultas en una base de datos NoSQL no será un problema.
Nosql Vs Sql: ¿Cuál es la mejor base de datos para Big Data?
El análisis de big data requiere bases de datos NoSQL porque ofrecen beneficios superiores. Las bases de datos SQL, por otro lado, se han utilizado para el análisis de datos durante mucho tiempo. Debido a que la mayoría de las herramientas de BI, como Looker, no admiten la función de consulta para bases de datos NoSQL, esta no es una opción.
Si sus datos están muy estructurados y se requiere el cumplimiento de ACID, SQL es una gran opción para usted. Si bien NoSQL puede ser beneficioso para aquellos que no conocen sus requisitos de datos o que tienen datos no estructurados, también puede ser beneficioso para quienes los conocen. Una base de datos NoSQL no requiere esquemas predefinidos como lo hacen las bases de datos SQL.
Esta flexibilidad es necesaria para el buen funcionamiento de conjuntos de datos complejos y la facilitación de una toma de decisiones flexible. Además, MongoDB admite potentes funciones de consulta que le permiten analizar y recuperar grandes cantidades de datos rápidamente. Podemos realizar análisis de datos avanzados en muy poco tiempo con nuestras conexiones R.
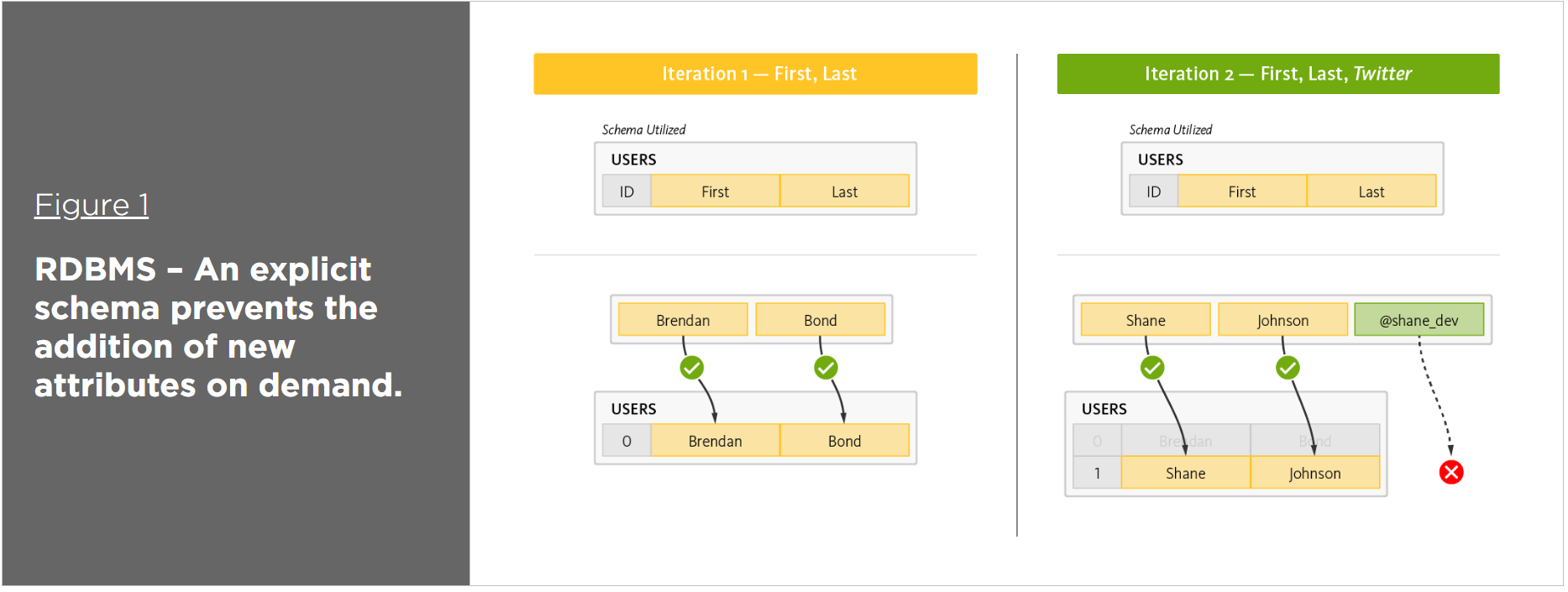
Por qué Rdbms no es adecuado para Big Data
No es posible eliminar normalizar. La fragmentación automática de datos es casi imposible en cualquier circunstancia (pesadilla). Un sistema de alta disponibilidad es difícil de implementar.
Todas y cada una de las herramientas internas de RDBMS (Relational Database Management System) explicarán su importancia en Big Data. ¿Por qué es tan difícil escalar? Hay varias razones para esto, pero la principal es que estamos insatisfechos. No podemos determinar la complejidad exacta de la consulta necesaria para extraer los resultados deseados de la base de datos. Si los datos son más grandes que el tamaño de la memoria de nuestro sistema, no podremos manejarlos. En big data, se debe fusionar una cantidad significativa de datos para generar una perspectiva. Los datos se almacenan en varias ubicaciones, por lo que las herramientas RDBMS son ineficientes e incapaces de manejar esta situación.
La capacidad de unirse es imposible debido a la fragmentación. Después de realizar un procedimiento de fragmentación, un solo marco de datos se puede dividir en varios nodos. Se considera que un servicio es de “alta disponibilidad” si está siempre disponible, y si no se cumplen algunas de sus características, su rendimiento se arreglará por sí solo. Hay una variedad de razones por las que la alta disponibilidad es extremadamente difícil de lograr, en las siguientes secciones.
Por qué Rdbmss no puede manejar Big Data
Big data no es compatible con RDBMS tradicional. Los sistemas son lentos e incapaces de lidiar con las fluctuaciones en los datos. Hadoop se puede usar para almacenar grandes cantidades de datos, pero no está diseñado específicamente para este propósito.