
Por qué las bases de datos Nosql son más fáciles de replicar
Publicado: 2022-12-26Las bases de datos Nosql son más fáciles de replicar porque no están limitadas por la estructura rígida de las bases de datos relacionales tradicionales. Esta flexibilidad permite escalar y duplicar fácilmente las bases de datos nosql en varios servidores. Además, las bases de datos nosql se pueden respaldar y restaurar fácilmente, lo que las hace ideales para aplicaciones con uso intensivo de datos.
La replicación de datos es esencial para mantener la base de datos y atender las consultas. Los niveles de RAID 3, 4, 5 o 10 se utilizan con frecuencia para mejorar la confiabilidad de los grandes sistemas de almacenamiento. Puedo mantener mi clúster activo si puedo volver a acceder a los datos en los discos fallidos antes de que ocurra la tercera falla. Un disco en un clúster R=3 contiene fragmentos de datos que se replican en otros discos en otras partes del clúster. Se realiza una reconstrucción entre 10 pares de sistemas copiando un disco por par de sistemas. Se necesitarían 100 servidores para reconstruir todo el conjunto de datos en un servidor fallido si tuviera diez discos. Todos los datos de la base de datos se pueden leer siempre que estemos en R1.
Una sola falla puede hacer que el clúster vaya a R0, donde no se pueden leer algunos datos. Consideremos una regla según la cual solo una réplica de un fragmento puede residir en un disco, servidor, PDU (fuente de alimentación) o conmutador de red. Si fallan fragmentos del disco o del servidor antes que R2, un clúster puede reducir la cantidad de tiempo dedicado a R2. Como resultado, es más probable que el clúster falle en el futuro, dando como resultado clústeres R1 y R0. Cuando las filas hacen que una base de datos falle, las tres réplicas del fragmento que contiene la fila pueden fallar al mismo tiempo.
Debido a que varios servidores pueden compartir los datos replicados , ningún servidor se sobrecargará con las consultas de los usuarios. Serás más eficiente. Si el servidor está menos congestionado con consultas, es posible que pueda proporcionar un mejor rendimiento para menos usuarios. La tienda tiene mucha demanda.
Un conjunto de réplicas es el equivalente de MongoDB a un grupo de procesos mongod que mantienen el mismo conjunto de datos. La capacidad de proporcionar altos niveles de redundancia y disponibilidad con réplicas es lo que las hace ideales para implementaciones de producción.
Las bases de datos NoSQL funcionan mejor que las bases de datos relacionales en términos de escalabilidad, escalabilidad y rendimiento. Además, sus modelos de datos son más flexibles y fáciles de usar que los modelos relacionales, lo que los convierte en una opción de desarrollo más rápida en comparación con otras plataformas.
Las bases de datos NoSQL procesan datos no estructurados mediante esquemas flexibles para permitir un almacenamiento y análisis eficientes de los datos que se distribuyen y utilizan para aplicaciones basadas en datos. Al reducir la consistencia de los datos y simplificar las restricciones de acceso a los datos de las bases de datos basadas en SQL, las bases de datos NoSQL permiten baja latencia, escalabilidad y alto rendimiento.
¿Soporta Nosql la replicación?
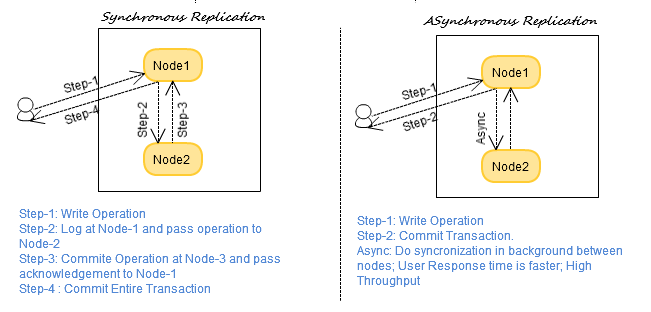
La replicación de datos NoSQL punto a punto se desarrolló como un medio para almacenar datos que se pasan entre copias de una base de datos. Este método solo se puede utilizar si todas las copias contienen el mismo formato de esquema y almacenan el mismo tipo de datos. Además, esta técnica de replicación de datos requiere el uso de una base de datos.
La plataforma CloverDX es un marco ideal para la integración de datos en la nube, en las instalaciones o en un entorno híbrido. Redis Enterprise es un almacén de estructura de datos que se puede utilizar como base de datos, caché o intermediario de mensajes en un almacén de estructura de datos en memoria. Net Cloud Platform es una plataforma informática en la nube de código abierto. El software de administración de bases de datos como GraphDB puede ayudar a las empresas a indexar datos. Los almacenes de datos en memoria y los entornos de caché se pueden administrar en la nube con Amazon ElastiCache, que es compatible con Redis y Memcached. Riak KV es una solución de base de datos NoSQL de código abierto que permite a las empresas administrar, replicar, recuperar y distribuir datos de múltiples fuentes. Actian Zen se ejecuta en una variedad de sistemas operativos, incluidos Windows, Linux, Android, iOS, macOS y máquinas virtuales, y es una base de datos integrada que se puede ejecutar en contenedores y contenedores. Un cifrado AES es capaz de hasta 128 bits de datos.
¿Qué es la replicación en la base de datos Nosql?
La replicación en una base de datos NoSQL se refiere al proceso de copiar datos de una base de datos primaria a una o más bases de datos secundarias. El propósito de la replicación es garantizar la disponibilidad de datos y mejorar el rendimiento mediante la distribución de datos entre varios servidores. Existen diferentes estrategias de replicación que se pueden usar en una base de datos NoSQL, como la replicación maestro-esclavo y la replicación punto a punto. En la replicación maestro-esclavo, la base de datos principal se denomina maestra y las bases de datos secundarias se denominan esclavas. El maestro escribe datos en los esclavos, que leen los datos del maestro. En la replicación punto a punto, cada base de datos es maestra y esclava, y los datos se replican entre las bases de datos en ambas direcciones. Las bases de datos NoSQL generalmente brindan alta disponibilidad mediante el uso de la replicación. Por ejemplo, si un servidor de base de datos deja de funcionar, todavía se puede acceder a los datos desde otro servidor.
La capacidad de replicar datos le permite aumentar la disponibilidad de los datos al replicarlos entre servidores. Se envía una operación de escritor al servidor primario (nodo) y se aplica a los datos en los servidores secundarios. Es necesario instalar MongoDB en tres o más nodos para que se replique en MongoDB. Establezca el nombre del puerto de su instancia mongod (para clientes remotos) y el nombre de su dirección IP (para clientes locales) con las opciones de línea de comandos –replSet y –bind_ip. Cuando ejecute la función rs.initiate() completa en el shell mongo, llamará al miembro 0 del conjunto de réplicas. Solo se puede ejecutar una copia del conjunto de réplicas a la vez, y solo se debe ejecutar la primera copia. Las herramientas a nivel del sistema pueden ayudarlo a obtener más información sobre la replicación y la fragmentación.
Es posible que las operaciones primarias de ejecución prolongada eviten las replicaciones. Debe considerar escribir una solicitud mayoritaria como un medio para garantizar que las operaciones grandes se repliquen correctamente. Puedes replicar un pastel de pizza en cada servidor, como lo harías por tu cuenta. Puede enviar porciones de pizza a varios conjuntos de réplicas mediante fragmentación. Como resultado, incluso las partes más delicadas de la pizza quedan accesibles. MongoDB Atlas también permite la implementación de réplicas distribuidas globalmente. Agiliza y automatiza sus conjuntos de réplicas, haciendo que el proceso sea mucho más sencillo para usted.
En la replicación de base de datos no transaccional, los datos de una base de datos principal se replican en una instancia de réplica, pero los cambios no se replican en el orden en que ocurren en la base de datos principal. Se utiliza una estrategia de replicación no transaccional para aumentar el rendimiento. Cuando se trata de replicar su base de datos, puede usar la replicación transaccional o la replicación no transaccional. Cuando se realizan cambios en la base de datos, se replica en tiempo real mediante la replicación transaccional. Esto asegura que la consistencia de los datos esté garantizada. Cuando existe una replicación no transaccional, los cambios realizados en la base de datos principal no se replican en el mismo orden que los realizados en la instancia de réplica. En este caso, la réplica se puede acelerar, pero puede que no sea tan consistente.
¿Por qué Nosql es más flexible?
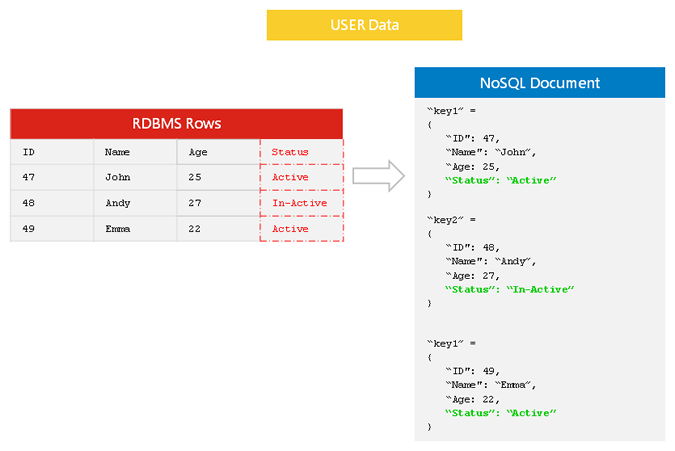
Hay muchas razones por las que las bases de datos NoSQL son más flexibles que sus equivalentes SQL. Por un lado, las bases de datos NoSQL no requieren un esquema fijo, lo que significa que pueden adaptarse más fácilmente a los cambios en sus datos. Además, las bases de datos NoSQL generalmente son más escalables que las bases de datos SQL, lo que significa que pueden manejar grandes cantidades de datos de manera más eficiente. Por último, las bases de datos NoSQL suelen tener un mejor rendimiento que las bases de datos SQL, lo que significa que pueden proporcionar un acceso más rápido a los datos.

La capacidad de controlar y manipular datos en una base de datos NoSQL se está volviendo más importante a medida que gana popularidad. Es ideal para aplicaciones que requieren manejar grandes cantidades de datos sin necesidad de seguir un esquema estricto.
¿Cuál puede ser la razón más común para usar una base de datos Nosql?

Las siguientes son razones por las que las bases de datos NoSQL pueden ser apropiadas para usted: para almacenar grandes colecciones de datos que es muy poco probable que estén estructurados. Una base de datos NoSQL puede admitir una amplia gama de tipos de datos y le permite cambiar los tipos de datos según sus necesidades.
Debido a que las bases de datos NoSQL pueden manejar aplicaciones de misión crítica, el mercado para ellas ha crecido. Una base de datos NoSQL almacena información de manera diferente a una base de datos relacional, que se almacena en una tabla fija. Para personalizar la experiencia de una aplicación, debe manejar una gran cantidad de datos y las preferencias del usuario deben cambiarse constantemente. No es posible manejar el volumen, la velocidad o la variedad de datos de sensores en una base de datos relacional. Una base de datos NoSQL puede procesar los datos de millones de dispositivos conectados al mismo tiempo. ¿Es necesario diseñar una base de datos NoSQL para cada aplicación web y móvil? Sin embargo, si su aplicación es similar a la de otros desarrolladores, se debe considerar NoSQL.
Las bases de datos NoSQL brindan más flexibilidad en sus esquemas debido a su capacidad para adaptarse a entornos de datos cambiantes. Debido al esquema predefinido, los datos de una base de datos relacional suelen estar estructurados de manera que son difíciles de manipular. Una base de datos NoSQL, por otro lado, brinda más flexibilidad en la forma en que se almacenan los datos, lo que permite que las aplicaciones se adapten rápidamente a la nueva información cuando sea necesario. Además, las bases de datos NoSQL no pueden admitir transacciones, lo que puede limitar el alcance de algunas aplicaciones. El problema se puede aliviar utilizando una base de datos relacional, que puede manejar transacciones complejas. Las bases de datos NoSQL, en general, brindan un esquema más flexible adecuado para entornos de datos cambiantes, mientras que las bases de datos relacionales brindan un esquema más tradicional que es más estable.
Réplica de lectura Nosql
Las bases de datos Nosql se utilizan a menudo como una forma de almacenar grandes cantidades de datos a los que es necesario acceder rápidamente. Una réplica de lectura nosql es una copia de una base de datos nosql que se utiliza para ayudar a mejorar el rendimiento al proporcionar una forma de leer rápidamente los datos de la base de datos.
Los datos se pueden administrar sin el uso de sintaxis o restricciones de formulario en las bases de datos NoSQL. Incluso si almacena sus datos en una base de datos no relacional, puede escalarlos fácilmente. Del mismo modo, la replicación de datos NoSQL es una característica robusta que le permite copiar y almacenar sin problemas sus datos estructurados, no estructurados y semiestructurados. Con Hevo, puede ahorrar dinero y tiempo replicando datos en minutos en lugar de horas. La velocidad, la simplicidad y la confiabilidad de Hevo la convierten en la plataforma de replicación de datos más simple, fácil y confiable. La robusta capa de transformación incorporada de Hevo le permite procesar y enriquecer datos granulares sin procesar sin escribir ningún código. Las bases de datos de documentos en NoSQL tienen una función similar a las bases de datos de valores clave porque están vinculadas a claves específicas a través de los propios documentos.
Varias filas pueden contener diferentes columnas en las bases de datos NoSQL de la familia de columnas, e incluso puede agregar columnas a cualquier fila en cualquier momento. Puede obtener todo lo que necesita para replicar datos con la plataforma automatizada sin código de Hevo Data. Un enfoque maestro-esclavo para replicar sus bases de datos NoSQL ofrece varias ventajas. Una técnica de replicación de datos NoSQL punto a punto tiene una serie de inconvenientes, además de las desventajas enumeradas anteriormente. Uno de los usos más comunes de las bases de datos No SQL es la verificación de identidad y la detección de fraudes. La plataforma No SQL proporciona a las empresas de comercio electrónico una forma sólida de almacenar datos de productos y marketing. No SQL Data Replication es una técnica popular y muy útil que las empresas utilizan para replicar datos. Antes de que pueda ejecutar consultas o realizar análisis de datos en sus datos sin procesar, primero debe exportarlos a un almacén de datos. Con Hevo Data, podrá automatizar sus procesos de transferencia de datos, lo que le permitirá concentrarse en otros aspectos de su negocio, como análisis, gestión de clientes, etc.
¿Qué hace que las bases de datos Nosql de clave-valor sean poderosas para las operaciones Crud básicas?
Hay muchas razones por las que las bases de datos NoSQL de clave-valor son poderosas para las operaciones CRUD básicas. Una de las razones es que las bases de datos de clave-valor son altamente escalables. Pueden manejar grandes cantidades de datos de manera muy eficiente. Otra razón es que las bases de datos de clave-valor son muy rápidas. Pueden recuperar datos rápida y fácilmente. Finalmente, las bases de datos de clave-valor son muy flexibles. Se pueden utilizar para una amplia variedad de tipos de datos y estructuras de datos.
Las bases de datos no relacionales (NoSQL) son aquellas que no tienen una estructura fija y, por lo tanto, no dependen de las relaciones a seguir. Las bases de datos de almacenamiento clave-valor, orientadas a columnas, basadas en documentos, gráficas y gráficas son los cuatro tipos principales de bases de datos. Como uno de los tipos menos complejos de bases de datos NoSQL, una base de datos clave-valor es una buena opción. Se puede utilizar para almacenar datos, recuperarlos y eliminarlos de una manera muy sencilla. Los lenguajes de consulta de base de datos utilizados en las bases de datos de almacenamiento de clave-valor no son compatibles con ellos. Los datos no son únicos y están determinados por los requisitos de la aplicación que los procesa. Se utiliza una base de datos clave-valor para registrar los inicios de sesión en las aplicaciones que los requieren.
Otra opción es un carrito de compras que almacena datos sobre compras individuales en línea, que es un caso de uso más especializado. Es ventajoso poder escalar las tiendas de valor clave durante las temporadas navideñas, así como durante las ventas y promociones especiales. Además, con su redundancia incorporada, evita que se pierdan artículos del carrito. Las bases de datos de valores clave son específicas para un propósito específico y tienen características que agregan valor a algunas pero imponen limitaciones a otras.
Consistencia en Nosql
Como resultado, las bases de datos NoSQL tienen cierta coherencia para que estén más disponibles. En lugar de proporcionar una gran consistencia, proporcionan una consistencia a largo plazo. En otras palabras, un almacén de datos que garantiza la integridad de un conjunto de datos puede fallar ocasionalmente al enviar los resultados de la ESCRITURA más reciente.
La implementación de un almacén de datos de documentos es mucho más difícil de solucionar que la implementación de un modelo relacional. De manera similar, refactorizar los datos de una tienda en vuelo es mucho más difícil que simplemente transformar los datos RDBMS en un nuevo formato. Los desarrolladores y arquitectos que no entiendan o tengan miedo de perder su trabajo si cometen un error no podrán participar en esta oportunidad. Al final, dividirán las transacciones atómicas en filas de transacciones, ignorando el hecho de que la replicación y la latencia son en realidad funciones y que los sistemas de terceros se incluyen en la mezcla. Eventualmente, todo el sistema se eliminará gradualmente y el departamento se subcontratará para que otra persona lo mantenga.