
5 façons d'optimiser votre base de données NoSQL
Publié: 2023-01-12Les bases de données NoSQL deviennent de plus en plus populaires car elles sont considérées comme plus évolutives et flexibles que les bases de données relationnelles traditionnelles . Il existe plusieurs façons d'optimiser une base de données NoSQL, notamment : 1. Concevoir le schéma avec soin : ceci est important car un schéma bien conçu peut aider à améliorer les performances et rendre les données plus faciles à gérer. 2. Données d'indexation : cela peut aider à améliorer les performances des requêtes. 3. Utilisation de la mise en cache : la mise en cache peut contribuer à améliorer les performances en stockant en mémoire les données fréquemment consultées. 4. Partitionnement des données : cela peut aider à améliorer les performances et l'évolutivité en répartissant les données sur plusieurs serveurs. 5. Surveillance des performances : Ceci est important pour identifier les goulots d'étranglement et prendre des mesures correctives.
Jay Patel, un architecte eBay, a récemment publié un article sur la modélisation des données à l'aide du magasin de données Cassandra. Il explique comment ils ont conçu leur modèle de données à l'aide de Cassandra, comment ils ont utilisé les colonnes et les familles de colonnes et comment ils ont optimisé les résultats des requêtes à l'aide de l'optimisation des requêtes. L'une de mes idées préférées de leur approche est qu'elle peut être appliquée à n'importe quelle base de données NoSQL. Avant de pouvoir optimiser votre modèle de données, vous devez d'abord comprendre comment il sera accessible. Lorsque vous commencez à remarquer que vos requêtes prennent plus de temps, vous vous rendez compte que votre base de données relationnelle rencontre des problèmes de performances. Lorsque les données sont normalisées, elles sont moins susceptibles d'entraîner des jointures inutiles ou des requêtes n+1. Même si la dénormalisation est possible avec les magasins de données NoSQL, des coûts y sont associés.
Qu'est-ce que l'optimisation des requêtes dans Nosql ?
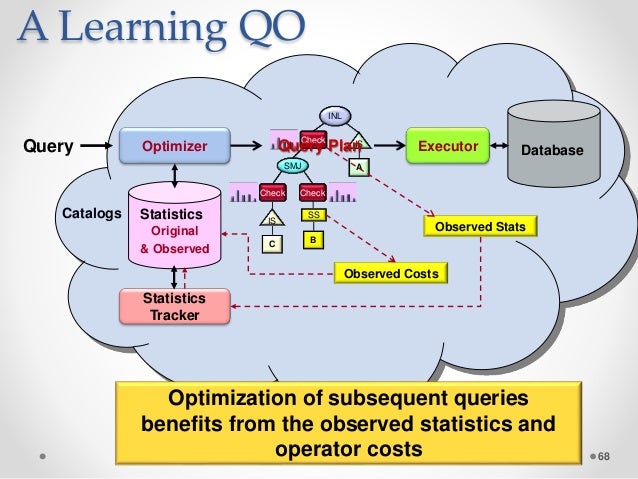
Le but de l'optimisation des requêtes est de trouver le plan le plus efficace. Lors de la mesure de l'efficacité, la latence et le débit sont utilisés. Une optimisation basée sur les coûts coûte le même prix que le coût de la mémoire, du processeur et de l'espace disque. Dans le monde NoSQL, la plupart des bases de données fournissent désormais une prise en charge du langage de requête de type SQL.
Une base de données MongoDB est une base de données NoSQL également connue sous le nom de base de données de documents. Cette base de données a été conçue de manière à être plus facile à développer que d'autres bases de données relationnelles. En utilisant expliquer (), nous pouvons voir comment notre requête fonctionne. Vous pouvez utiliser Explique pour créer un document qui inclut des plans de requête, des étapes de requête, etc. À la suite de cet article, nous pouvons mieux comprendre comment l'index peut modifier les étapes de numérisation d'une collection spécifique. Le but de cet article est de revenir sur les fondamentaux de l'optimisation. Les détails détaillés de l'optimisation de l'étape d'agrégation seront couverts dans les articles suivants. Les Noirs excellent dans les domaines de la technologie. Cette collection de ressources met en évidence certaines des choses que nous devrions savoir.
Qu'est-ce qui rend Nosql rapide ?
Les bases de données Nosql sont conçues pour être rapides et évolutives. Ils utilisent diverses techniques pour y parvenir, telles que la mise à l'échelle horizontale, le partitionnement et la dénormalisation.
La grande majorité des systèmes noSQL sont simplement des stockages persistants de clés ou de valeurs (comme Project Voldemort). Si vos requêtes sont du type qui vous obligent à rechercher une valeur de clé donnée, un système qui peut le faire aussi rapidement qu'un SGBDR le devrait. Les bases de données de documents (telles que CouchDB) sont également des systèmes nosql populaires. La dénormalisation est largement utilisée dans ces bases de données pour structurer la structure des données. En fait, je crois que les performances d'une application peuvent être mesurées par le nombre de pièces dont elle a besoin pour répondre à une seule exigence. Lorsque NoSQL est utilisé, les performances d'une base de données NoSQL comme djondb peuvent être dix fois plus rapides si vous n'avez besoin que d'une simple insertion. Le développeur pourra travailler plus efficacement car NoSQL lui permet de consommer moins de données.
L'objectif principal des BASES DE DONNÉES NoSQL (pas de frontières) est de maintenir un haut niveau d'évolutivité. Vous devez tenir compte des types de requêtes que vous effectuez, des colonnes que vous utilisez dans la table et de l'implémentation de votre serveur que vous utilisez. Si vous créez plus de nœuds à 1 000 000 tr/min stables pendant 2 ms et utilisez moins de code, vous obtiendrez un nœud plus rapide avec un taux et des performances stables plus élevés.
Qu'est-ce qui rend Nosql plus rapide que SQL ?
Cette méthode implique la collecte, la consolidation et la division de diverses entités de données. Par conséquent, une base de données NoSQL effectue les opérations de lecture et d'écriture plus rapidement qu'une base de données SQL.
Pourquoi les bases de données Nosql prennent le dessus
En plus d'une variété de facteurs, les bases de données NoSQL deviennent de plus en plus populaires. Ils sont simples à utiliser, capables de traiter de grandes quantités de données et peuvent être adaptés pour répondre aux exigences spécifiques de votre application. Ils présentent de nombreux avantages en plus d'être flexibles et personnalisables, ce qui est impossible à trouver dans d'autres types de bases de données.
Réglage des performances Nosql

Le réglage des performances Nosql consiste à s'assurer que votre base de données nosql fonctionne aussi efficacement que possible. Il y a quelques domaines clés sur lesquels se concentrer lors du réglage de votre base de données nosql : 1. Assurez-vous que votre base de données est correctement indexée. 2. Assurez-vous que vos requêtes sont optimisées. 3. Assurez-vous que vos données sont correctement normalisées. 4. Assurez-vous que votre base de données est correctement configurée. En vous concentrant sur ces domaines clés, vous pouvez vous assurer que votre base de données nosql fonctionne à des performances optimales.
Lorsque Mango est à une charge élevée, le script MangoNoSql effectue des écritures en arrière-plan. La fonction Batch Write Behind vous permet d'écrire dans les coulisses. Chaque tâche sera exécutée en parallèle des autres, mettant en évidence les valeurs ponctuelles d'un pool. Si vous avez remarqué des événements de perte de données NoSQL dans votre système, il est judicieux de modifier vos paramètres de performances. Lorsque vous appuyez sur le bouton Sauvegarder maintenant, une file d'attente de travaux sera créée pour sauvegarder le système maintenant. Toutes les valeurs de points prêtes à être écrites dans une liste de mémoire dans le cadre des modules NoSQL sont stockées dans mango. Après cela, il sélectionne jusqu'à "Batch write behind inserts per task" dans la liste et démarre un thread pour insérer les inserts.
Les avantages et les inconvénients de Nosql
Lors du développement de bases de données NoSQL, il est essentiel de les garder flexibles et rapides. Il a moins de surcharge car il a moins de contraintes que SQL. Le stockage Shallow NoSQL est flexible, ce qui lui permet d'être distribué sur une variété d'objets (documents ou paires clé-valeur). Une base de données NoSQL est largement considérée comme ayant un faible niveau de difficulté en termes de développement, de fonctionnalités et de performances. Il est simple à apprendre et est utilisé par les personnes qui préfèrent stocker des données non conformes aux modèles de base de données traditionnels .
Optimisation des performances Mongodb
MongoDB est un puissant système de base de données orienté document open source. Il dispose d'une fonction de recherche basée sur un index qui rend la récupération des données rapide et facile. Cependant, comme tout autre système de base de données, les performances de MongoDB peuvent être optimisées pour garantir un fonctionnement fluide et efficace. Il y a quelques choses de base qui peuvent être faites pour optimiser les performances de MongoDB. Tout d'abord, il est important de s'assurer que les bons index sont en place. Cela garantira que les données peuvent être récupérées rapidement et facilement. Deuxièmement, il est important de garder la base de données bien organisée. Cela aidera à réduire la taille des données et facilitera les requêtes. Enfin, il est important de surveiller régulièrement la base de données pour s'assurer qu'elle fonctionne correctement. En suivant ces conseils simples, il est possible de faire fonctionner MongoDB de manière fluide et efficace.

Guy Harrison explique comment utiliser le nouveau pipeline d'agrégation et d'agrégation de fenêtrage dans MongoDB 5.0 dans cet article de blog. Data Lake a été créé à la suite de l'explosion d'intérêt pour le Big Data et Hadoop. Le Data Lake, une alternative moderne et plus efficace à l'Enterprise Data Warehouse (EDW), a été développé. Le blog de cette semaine se concentre sur les index MongoDB B -tree et comment créer des index concaténés pour optimiser les recherches multi-clés. De plus, lorsque nous envisageons – ou utilisons – des indices, nous envisageons certains compromis.
Quelle est l'amélioration des performances dans Mongodb ?
Si vous connaissez vos modèles de requête MongoDB, vous pouvez améliorer vos performances MongoDB en : stockant les résultats de sous-requêtes fréquentes pour réduire la charge de lecture ; et détecter vos modèles de requête MongoDB. Assurez-vous que vous disposez régulièrement d'index sur chaque champ que vous interrogez. Si vous remarquez des requêtes lentes, vous pouvez utiliser vos journaux pour les identifier.
Mongodb a-t-il besoin de beaucoup de RAM ?
MongoDB nécessite 1 Go de RAM pour s'exécuter sur un seul actif. Si le système doit commencer à échanger de la mémoire sur le disque, cela aura un impact important sur les performances et doit être évité.
Mongodb a-t-il un optimiseur de requête ?
Lorsqu'un index est disponible dans MongoDB, l'optimiseur de requête détermine quel plan de requête est le plus efficace et le met en cache. Le nombre « d'unités de travail » (travaux) effectuées par le plan d'exécution de requête est utilisé pour déterminer le plan de requête le plus efficace lorsque le planificateur de requête examine les plans candidats.
Outil d'optimisation des requêtes Mongodb
Mongodb fournit un outil d'optimisation des requêtes qui permet aux utilisateurs d'améliorer les performances de leurs requêtes. Cet outil permet de visualiser le plan d'exécution de la requête et d'optimiser la requête en fonction des résultats. L'outil permet également aux utilisateurs de visualiser le plan d'exécution de la requête dans une variété de formats, y compris JSON, BSON et CSV.
MongoDB fournit des statistiques d'exécution des requêtes dans le cadre d'un système d'inspection. Ces informations peuvent être utilisées par un développeur pour optimiser une requête. L'onglet Expliquer le plan, par exemple, permet aux utilisateurs d'illustrer graphiquement les statistiques du plan. En plus de queryPlanner, executionStats et allExecutionPlans, les modes de verbosité peuvent être utilisés pour expliquer. Les index uniques, partiels, clairsemés (n'indexez pas les documents sans le champ d'index), masqués (ne voient pas les résultats du planificateur de requêtes) et multiclés sont tous pris en charge par MongoDB. Au lieu d'utiliser des clés de préfixes d'index ou des ordres de tri variables, un index composé est utilisé pour les index. MongoDB optimise les performances des requêtes en utilisant deux index ou préfixes distincts lors de la connexion de deux index ou de leurs préfixes.
Le pipeline de Mongod contient une étape qui correspond à un champ non indexé. C'est une solution simple de réécrire l'étape de matching pour utiliser un champ déjà existant et indexé. L'optimiseur recherche les unités de travail qui doivent être exécutées lors de l'exécution de chaque plan candidat. Lors de l'exécution d'applications à lecture intensive, la taille des jeux de réplicas doit être augmentée et le partitionnement effectué. L'état et la durée de la réplication doivent être surveillés. True : mettez à jour tous les documents correspondants aussi efficacement que possible lors de l'utilisation de multi. Examinez les métriques de verrouillage dans un ordre spécifique.
Un temps de verrouillage long peut indiquer que la structure de la requête ou l'architecture du système ne fonctionne pas correctement. Le traitement par lots améliore l'efficacité des ressources. Les événements dans Kafka, par exemple, peuvent être consommés par lots plutôt que par morceaux. Il est impossible d'indexer une requête sur une collection fragmentée si l'index ne contient pas la clé de la collection. En utilisant $planCacheStats, vous pouvez mieux comprendre les informations de cache dans l'étape d'agrégation. Cela signifie également que le cache du plan n'aura qu'une limite de taille de 0,5 Go, qui est la même limite de taille que la version précédente.
Magasins de données Nosql
Au lieu de stocker les données dans des tables, les bases de données NoSQL stockent les données dans des documents. En conséquence, nous les qualifions de « non seulement SQL », et ils peuvent donc être classés comme modèles de données flexibles en utilisant une variété de méthodes différentes. Les bases de données NoSQL sont divisées en quatre types : les bases de données de documents purs, les magasins clé-valeur, les bases de données à colonnes larges et les bases de données de graphes.
Le magasin de données Redis est un magasin de paires clé-valeur en mémoire open source développé par IBM. Il peut être utilisé pour stocker des données de session pour un accès plus rapide, en plus de la mise en cache, de la mise en file d'attente et de la mise en file d'attente, et il est moins coûteux que les bases de données traditionnelles . Une base de données NoSQL est fréquemment utilisée en complément plutôt qu'en remplacement d'une base de données relationnelle. Un type de persistance sous-jacent a un ensemble de caractéristiques différent de celui qui est stocké dans une base de données relationnelle. PyMongo, qui est construit à l'aide de code Python, vous permet d'interagir avec une ou plusieurs instances MongoDB à l'aide d'une interface commune. L'ORM Python construit autour de PyMongoEngine est spécialement conçu pour MongoDB. L'objectif de Graph Databases est de fournir une vue d'ensemble complète des magasins de données NoSQL et de les comparer à d'autres types de magasins de données. Ce qui suit est une brève description de NoSQL et de ses utilisations, ainsi qu'une description du théorème de cohérence, de disponibilité et de tolérance de partition (CAP). les données de session peuvent être stockées en mémoire plus rapidement que dans une base de données traditionnelle avec stockage persistant.
Les bases de données NoSQL bénéficient des caractéristiques suivantes : mise à l'échelle facile, haute disponibilité et faible latence d'accès aux données. Les applications de base de données sont conçues pour traiter plus de types de données que les bases de données traditionnelles. Il simplifie le stockage des données avec un modèle simplifié, permettant un traitement plus rapide et plus efficace. De plus, ils conviennent à l'analyse de données à grande échelle. Les bases de données NoSQL présentent un certain nombre d'avantages par rapport aux bases de données conventionnelles . Les avantages de les avoir sont qu'ils peuvent évoluer, fournir des niveaux élevés de disponibilité et fournir de faibles niveaux de latence pour l'accès aux données.
Pourquoi les bases de données Nosql prennent le dessus
Il existe de nombreux avantages à utiliser les bases de données NoSQL par rapport aux bases de données relationnelles traditionnelles, et elles deviennent de plus en plus populaires. La conception ObjectStore, qui permet une utilisation plus efficace des techniques de programmation orientée objet, en est l'une des principales raisons. Les bases de données NoSQL, en plus de leur évolutivité, offrent également une variété d'autres avantages. Les données peuvent être traitées facilement car elles sont volumineuses et peuvent être traitées en peu de temps. Pour toute entreprise à la recherche d'une base de données documentaire fiable et évolutive , MongoDB est un excellent choix. De plus, son utilisation est gratuite et constitue un choix populaire pour les entreprises de toutes tailles.
Index de texte Mongodb
Les index de texte de MongoDB prennent en charge le traitement de texte spécifique à la langue, y compris la tokenisation, la radicalisation et les mots vides spécifiques à la langue. Ils peuvent être utilisés avec n'importe quel champ contenant du texte basé sur la langue.
Créer des index de texte dans MongoDB est aussi simple que d'utiliser la méthode createIndex(). La fonction principale d'un index de texte est d'identifier tout élément dans une chaîne ou un tableau d'éléments dans un texte. Les index composés contiennent à la fois des clés d'index croissant et décroissant en plus de la clé d'index de texte. Dans ce cas, recherchons dans la collection Studentspost en créant un index de texte dans le champ de titre. MongoDB résume les résultats de chaque champ d'index du document en multipliant son poids par son nombre total de correspondances. Le poids par défaut d'un champ d'index est un, vous pouvez donc le modifier à l'aide de la méthode createIndex(). Vous pouvez créer plusieurs index de texte à l'aide du spécificateur générique ($**).