
Conception d'une base de données pour les données de géolocalisation : considérations clés
Publié: 2022-12-29Les données de géolocalisation sont un type de données qui inclut des informations sur l'emplacement géographique d'un objet spécifique. Afin de stocker et de gérer efficacement les données de géolocalisation, il est important de comprendre comment structurer une base de données pour ce type de données. Il y a quelques considérations clés à garder à l'esprit lors de la conception d'une base de données pour les données de géolocalisation. La première considération est le niveau de granularité auquel les données seront stockées. Par exemple, les données seront-elles stockées au niveau du pays, de l'état ou de la ville ? Le niveau de granularité aura un impact sur la taille globale de la base de données et la complexité des requêtes pouvant être exécutées sur les données. La deuxième considération est le format dans lequel les données seront stockées. Il existe différentes options pour stocker les données de géolocalisation, notamment les paires latitude/longitude, GeoJSON et KML. Chaque option a ses propres avantages et inconvénients, il est donc important de choisir le format le mieux adapté aux besoins spécifiques de l'application. Enfin, il est important de considérer la stratégie d'indexation qui sera utilisée pour les données. L'indexation est importante pour des raisons de performances, mais elle peut également avoir un impact sur la structure globale de la base de données. Pour les données de géolocalisation, une stratégie d'indexation courante consiste à utiliser un index quadtree. En gardant ces considérations à l'esprit, il est possible de concevoir efficacement une base de données pour stocker des données de géolocalisation.
Un certain nombre d'entreprises technologiques grand public expérimentent des bases de données NoSQL dans les domaines des services basés sur la localisation. Un langage de requête structuré, tel que SQL, et une base de données relationnelle, telle que MySQL, fonctionnent de manière opposée. Il n'y a pas de caractéristiques communes aux bases de données NoSQL, et beaucoup d'entre elles ne nécessitent pas de schémas de table fixes ni d'opérations de jointure. MongoDB (open source), BigTable (propriétaire de Google) et Google Earth (disponible via Google Earth) ne sont que quelques-unes des bases de données NoSQL capables de gérer des données spatiales. Cassandra (une base de données NoSQL développée par Facebook) et CouchDB (une base de données NoSQL développée par Facebook) sont également des plates-formes logicielles open source. Amazon SimpleDB, un service Web, peut être utilisé. Le framework NoSQL n'est pas simplement un conteneur de magasins de données ; c'est une collection d'entre eux.
Un grand nombre de développeurs utilisent les technologies NoSQL pour résoudre les problèmes spatiaux, plutôt que de s'appuyer sur une base de données. Au lieu de cela, ils utiliseront un service local ou hébergé. Attendez-vous à plus d'options pour les bases de données, pas moins. Ceci est un merci à Paul Ramsey et à ses étudiants du Geog897g de Penn State pour leur contribution.
Comment les bases de données Nosql sont-elles structurées ?
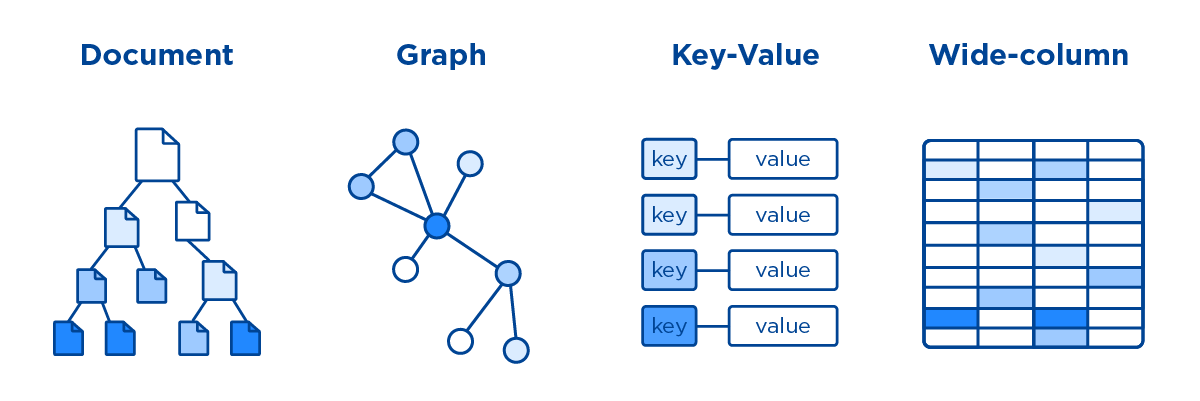
Les bases de données SQL (également appelées bases de données NoSQL) stockent les données différemment des bases de données traditionnelles en raison de leur nature non tabulaire. Une base de données NoSQL est composée de plusieurs types en fonction de son modèle de données. Les types de documents incluent les diagrammes, les graphiques et les colonnes larges, ainsi que les types clé-valeur.
Contrairement aux bases de données relationnelles traditionnelles , les bases de données NoSQL stockent les données dans un format qui leur est propre. Les types de document, de clé-valeur, de colonne large et de graphique sont les plus courants. Le coût de stockage des données a chuté de manière spectaculaire au cours de la dernière décennie, permettant aux bases de données NoSQL d'émerger. Les développeurs peuvent stocker de grandes quantités de données non structurées car ils peuvent utiliser ces systèmes à diverses fins. Les bases de données de documents, les bases de données clé-valeur, les magasins à colonnes larges et les bases de données de graphes sont tous des exemples de bases de données NoSQL. Lorsque la jointure n'est pas requise, les temps de requête s'améliorent. La variété des cas d'utilisation des solutions IoT va des plus critiques (comme les données financières) aux plus ludiques et absurdes (comme le stockage des lectures IoT d'un bac à litière intelligent pour chat).
Dans ce didacticiel, vous apprendrez à choisir et à utiliser une base de données NoSQL. De plus, nous examinerons en profondeur certaines idées fausses courantes sur les bases de données NoSQL. Selon DB-Engines, MongoDB est la base de données non relationnelle la plus populaire de la planète. Le but de ce tutoriel est de vous apprendre à interroger une base de données MongoDB sans rien installer sur votre ordinateur. Un cluster MongoDB est un emplacement où vous stockez vos bases de données. La capacité de stockage d'Atlas peut être augmentée une fois qu'il a été configuré pour un cluster. L'Atlas Data Explorer, le MongoDB Shell ou le MongoDB Compass sont toutes des méthodes possibles pour créer une base de données manuellement.
Les exemples de données d'Atlas seront importés dans ce script en conséquence. Les bases de données NoSQL présentent divers avantages pour les développeurs, notamment la possibilité de modéliser et de dimensionner les données en parallèle, d'interroger rapidement les données et d'utiliser des requêtes ultra-rapides. L'explorateur de données est le moyen le plus pratique d'insérer de nouveaux documents, de modifier des documents existants et de supprimer des documents. Vous pouvez analyser vos données à l'aide du cadre d'agrégation, qui est l'un des outils les plus puissants disponibles. Le graphique est l'un des moyens les plus simples de visualiser des données dans Atlas et Atlas Data Lake.
En raison de la flexibilité des bases de données NoSQL, elles peuvent gérer des données non structurées et semi-structurées. Cela permet un développement plus rapide et plus itératif car il n'est pas nécessaire de reconstruire les données dans la base de données. Les bases de données NoSQL peuvent également évoluer pour gérer de grandes quantités de données, car elles sont évolutives. Enfin, la structure de données des bases de données NoSQL leur permet de gérer les données d'une manière complètement nouvelle, qui leur est propre. Les bases de données NoSQL sont idéales pour les ensembles de données à grande échelle car elles peuvent être modifiées pour répondre à des exigences uniques.
Quel type de base de données Nosql est utilisé pour suivre les relations entre entités ?
Il n'y a pas de réponse définitive à cette question car cela dépend des besoins spécifiques de l'application. Cependant, certaines des bases de données nosql les plus populaires utilisées pour le suivi des relations entre entités incluent MongoDB, Couchbase et Cassandra.
Tout système qui fonctionne avec des bases de données SQL alternatives est appelé NoSQL. Contrairement aux tables de lignes et de colonnes traditionnelles utilisées dans les systèmes de gestion de bases de données relationnelles, les modèles de données utilisés dans cette application sont constitués de différentes structures. Les bases de données NoSQL sont assez différentes les unes des autres. Les bases de données documentaires avec une architecture scale-out sont couramment utilisées pour implémenter les bases de données documentaires les plus largement adoptées. Les plateformes de commerce électronique, les plateformes de trading et le développement d'applications mobiles ne sont que quelques exemples de cas d'utilisation. Nous examinons MongoDB et PostgreSQL en détail, en les comparant les uns aux autres. Ces données peuvent être recueillies en quelques secondes à l'aide d'une base de données en colonnes.
Ils sont incapables d'écrire des données de manière cohérente en raison de leur méthode d'écriture des données. Les bases de données de graphes sont optimisées pour capturer et rechercher des connexions entre les éléments de données dans le cadre de leurs capacités de recherche et de capture. Plusieurs tables peuvent être jointes en SQL plus efficacement en utilisant ces méthodes.
Quel type de base de données Nosql est le mieux adapté pour stocker des données avec des relations complexes ?
Une base de données documentaire est une base de données sans schéma, permettant de définir un schéma sans avoir à le suivre au préalable. Nous pouvons stocker des données complexes dans des formats de documents tels que XML et JSON en utilisant ce système.
Quel type de base de données Nosql utilise des arêtes et des relations dans sa structure ?
Une structure de graphe orienté est utilisée pour représenter les données dans une base de données NoSQL Graph Base. Un graphe est composé de nœuds et d'arêtes. Un graphique est une représentation d'un ensemble d'objets auxquels certaines paires d'objets sont liées par un certain type de lien.
Nosql Géospatial
Les données géospatiales sont des données qui incluent une composante géographique, telle que la latitude et la longitude. Les bases de données Nosql sont bien adaptées au stockage et à l'interrogation de données géospatiales. De nombreuses bases de données nosql ont une prise en charge intégrée des types de données et des opérations géospatiales .
Les données spatiales (fichiers, bases de données, services Web) sont un type de données qui stockent des informations géographiques et peuvent être utilisées dans des applications de géolocalisation. Les données d'une couche spatiale peuvent être utilisées pour représenter une couche graphique sur une carte, mais elles peuvent également être utilisées pour analyser des caractéristiques géographiques et des emplacements. Il s'agissait d'un type spécial de système de gestion de base de données qui ne prenait en charge que les objets spatiaux et était principalement utilisé par les analystes spatiaux. Nous nous référons aux données spatiales comme des points, des lignes et des zones d'informations cartographiques car elles sont conçues pour les stocker et les gérer. En général, les professionnels du graphisme utilisaient le logiciel de cartographie de bureau d'ESRI pour créer des cartes (statiques). En plus d'importer les données, les développeurs Web pourraient les interroger avec une couche d'application de cartographie Web sensible à l'emplacement en utilisant une base de données spatiale. Lors de l'accès aux données spatiales, il est plus courant que les développeurs créent une carte, que ce soit en ligne, dans une application mobile ou sur un ordinateur de bureau.
Lorsque vous commencez à utiliser des données spatiales comme un simple objet avec des coordonnées, vous remarquerez à quel point cela fonctionne bien avec les bases de données NoSQL. L'utilisation de l'informatique basée sur les clusters permet aux données spatiales de croître au fil du temps, avec des ressources de requête facilement disponibles. Ces applications facilitent la dissimulation de requêtes spatiales plus complexes couramment utilisées en coulisses. Il est courant que les bases de données spatiales calculent simplement un rectangle autour de chacune des entités d'un jeu de données et l'utilisent comme un index approximatif pour l'interroger. Ils utilisent le MBR pour déterminer la proximité des entités, afin de pouvoir ignorer les entités trop éloignées pour être importantes. Les demandes de documents à l'aide d'un logiciel NoSQL basé sur N1QL/SQL, tel que Couchbase, peuvent être effectuées. A l'aide des objets géospatiaux, les applications en aval peuvent y être directement connectées.
L'objectif de ce blog est de démontrer comment le langage de programmation R, ainsi que le package de mappage Leaflet, peuvent facilement demander des données et en tirer des résultats. La vraie bataille se déroule à l'extérieur avec des requêtes. Les applications SIG complètes et les bases de données spatiales sont également capables de générer de grandes quantités de données. La spécification comprend de nombreux types et fonctions différents pour les éléments spatiaux. Une autre forme populaire de jointure spatiale est la connexion de points, en particulier le regroupement de points en polygones. L'aspect le plus difficile est la conception d'un système basé sur la géométrie computationnelle, ce qui implique la création de nouvelles fonctionnalités. L'importance de la gestion des ressources ne peut être surestimée, car il est difficile de le faire.

Quelle est la relation entre Nosql et les données spatiales ?
Étant donné que NoSQL est conçu pour gérer des charges de travail volumineuses, s'appuyer sur lui pour les applications SIG ajoute toujours une couche supplémentaire de luxe en raison de sa nature informatique distribuée. Lorsque des clusters sont utilisés, les données spatiales augmentent au fil du temps et les ressources de requête peuvent être facilement étendues.
Les avantages de l'utilisation d'un index géospatial
Vous devez créer un index aspatial dans MongoDB afin d'utiliser des données spatiales dans MongoDB. Cet index vous permet d'interroger plus efficacement une collection de formes et de points spatiaux en l'utilisant comme index de requête spatiale. Un index géospatial, qui utilise une variété de critères tels que la latitude et la longitude, peut être utilisé pour localiser tous les lieux dans un document. Quels sont les avantages d'utiliser un index de mappage ? Un index cartographique peut accélérer le processus de localisation des objets dans les documents car il peut utiliser un index géographique pour les localiser. L'exemple suivant serait un endroit pour trouver tous les restaurants de votre ville. Parce qu'un index géospatial est basé sur la latitude et la longitude, il est simple de trouver des documents qui correspondent à vos critères. De même, l'utilisation d'un index géospatial peut vous aider à localiser des objets qui ne sont pas nécessairement situés dans la même zone. Vous voudrez peut-être rechercher tous les documents avec latitude et longitude qui se trouvent dans une zone géographique spécifique. Il est simple de trouver tous les documents dont vous avez besoin qui ont la latitude et la longitude en fonction de vos critères à l'aide d'un index géospatial. Comment créer un index géospatial ? Pour créer un index géospatial, vous devez d'abord créer une collection de données qui contient les données que vous souhaitez indexer. Un index spatial, suivi de la collection, est requis. Enfin, vous devez générer une requête qui utilise l'index géospatial pour localiser les objets. Quels sont les éléments clés à garder à l'esprit lorsque vous travaillez avec psy GIS ? Les pointeurs suivants doivent être suivis lorsque vous travaillez avec des données spatiales. Lors de la recherche d'objets dans un document, il est toujours préférable d'utiliser un index géospatial. Lorsque vous faites du SIG, assurez-vous que vos documents sont dans le bon format. Lors de l'interrogation d'objets, des coordonnées de référence doivent toujours être fournies. Ce n'est jamais une bonne idée de supposer qu'un document contient des informations géographiques. Avant d'utiliser l'index, il est toujours judicieux de revoir le format des données.
Stockage de données géospatiales
Le stockage de données géospatiales fait référence au processus de stockage de données numériques associées à un emplacement physique. Ce type de données peut être utilisé pour créer des cartes et d'autres visualisations qui aident les gens à comprendre le monde qui les entoure. Il existe différentes manières de stocker des données géospatiales, notamment à l'aide de bases de données, de fichiers et de services Web.
Les données géospatiales open source, telles que l'Internet des objets (IoT), les informations géographiques volontaires (VGI) et les données géospatiales ouvertes, gagnent toutes en popularité. Le processus d'importation de la base de données PostgreSQL/PostGIS est simplifié avec HOGS, un utilitaire de ligne de commande. Il a été développé dans le but de démontrer les performances d'une disposition de stockage traditionnelle et d'un magasin de documents NoSQL. Bien que la promesse de vitesse de NoSQL puisse sembler attrayante, il existe également des inconvénients. Par conséquent, afin de comprendre si nous pouvons vraiment abandonner les principes des systèmes de gestion de bases de données relationnelles (RDBMS), nous devons d'abord considérer cela. HOGS est un utilitaire de ligne de commande open source qui utilise la bibliothèque open source GDAL/OGR pour automatiser l'importation de données géospatiales hétérogènes vers des bases de données a/postGIS. Les magasins de documents, les bases de données de graphes, les bases de données orientées objet et les magasins clé-valeur sont tous des exemples de magasins de données NoSQL.
Les magasins de documents stockent les données sous forme de documents plutôt que de tables dans une base de données relationnelle, car ils n'ont pas de schéma explicite. En raison de leur facilité d'utilisation, ils sont fréquemment utilisés conjointement avec des ensembles de données open source. La norme GeoJSON, qui est utilisée à la fois par MongoDB et CouchDB, est utilisée pour fournir des capacités spatiales. Amirien et al. étudiez les modèles orientés document 19 % plus rapidement que les modèles relationnels pour les grandes données spatiales polygonales. Amirian et ses collègues ont testé trois stratégies de stockage différentes pour les « mégadonnées géospatiales » à l'aide de Microsoft SQL Server 2012, avec la contribution des utilisateurs. La mise en page du document XML (magasin de documents NoSQL) a fourni les meilleures performances et évolutivité lors de leur configuration.
Plusieurs des résultats de leurs recherches montrent que les modèles basés sur des documents doivent être pris en compte dans un large éventail de scénarios de flux de travail. L'utilisation de MongoDB pour interroger des points et des données composées offre trois fois les performances de PostGIS à six fois la vitesse. Malgré cela, PostgIS surpasse MongoDB de plus de 3 fois dans les requêtes de rayon lorsque le rayon de la requête augmente. Malgré cela, les auteurs reconnaissent que les bases de données NoSQL manquent de fonctionnalités similaires aux SGBDR, mais déclarent que cela changera à l'avenir. Python a été choisi comme langage pour implémenter le système HOGS en raison de sa disponibilité multiplateforme et de son intégration avec des bibliothèques open source telles que GDAL/OGR et GEOS, ainsi que de son intégration multiplateforme. La base de données est stockée de deux manières différentes : stockage des fonctionnalités et des jeux de données. Une table d'entités comporte des lignes pour chaque attribut, une colonne de géométrie et une colonne d'ID d'entité ; chaque ligne contient une entité avec un jeu de données.
Une colonne contient l'identifiant. Les colonnes Géométrie et ID sont des colonnes distinctes qui, en plus du tableau, sont organisées en colonnes. La principale distinction est que tous les attributs sont stockés dans une seule colonne de type jsonb. HOGS peut être utilisé pour prendre en charge la gestion des versions des ensembles de données en utilisant des numéros de version incrémentiels et des horodatages associés. HOGS utilise à la fois un NoSQL et une disposition de stockage traditionnelle basée sur des tables. Pendant la phase d'importation, les fichiers de chaque ensemble de données sont lus et analysés avant d'être écrits dans une base de données à l'aide d'une instruction COPY. Étant donné que chaque fichier d'une importation est son propre fichier, cette phase peut être exécutée simultanément avec d'autres fichiers. La vitesse d'importation, la vitesse de requête et la taille de la base de données ont toutes été mesurées pour chaque disposition de stockage de données.
L'autorité norvégienne de cartographie, connue sous le nom de N50, a fourni un ensemble de données ouvert pour chaque référence. Un ensemble de données à l'échelle 1/50 000 du continent norvégien contient huit sous-ensembles de données (collections d'entités) avec plusieurs couches topologiques. Après extraction des données dans l'ensemble de données complet, il y a 3415 fichiers d'une taille totale de 7,9 Go. La méthode d'importation basée sur une table est 44 % plus rapide que la méthode d'importation jsonb. L'importation de la mise en page de table prend environ une heure et 19 minutes, tandis que la mise en page jstrelb prend environ trois heures. Nous avons obtenu 840 géométries de requête à partir des journaux de requête de ce système en utilisant la vitesse d'importation de la mise en page de table. Ces polygones couvrent le continent norvégien dans une plage de 1 à 100 mètres.
Toutes les métriques montrent que la mise en page basée sur des tables fonctionne mieux que la mise en page NoSQL de style jsonb. En raison de la manière dont les attributs sont stockés et du nombre de tables utilisées, cela peut poser problème. PostgreSQL/PostGIS est utilisé par les deux bases de données, et les deux bases de données utilisent des types de géométrie PostGIS. La principale différence entre les requêtes de données et les fichiers jsonb est la taille de la table ; la table commune dans les fichiers jsonb est plus grande que la table commune dans les requêtes de données. De nombreux jeux de données peuvent être divisés en jeux de données distincts en fonction des types d'entités qu'ils incluent. Par rapport à une disposition de table combinée de magasin de documents NoSQL, nous avons découvert qu'une disposition traditionnelle à une table par jeu de données surpasse une disposition de table combinée de magasin de documents NoSQL pour des ensembles de données homogènes. HOGS peut être automatisé et n'introduit aucune complexité supplémentaire en tirant parti de GDAL/OGR dans un système GDAL/OGR.
Une table unique de divers ensembles de données avec un mélange hétérogène d'entités semble plus facile à utiliser, mais ce type de mise en page ne fonctionne pas avec d'autres packages SIG. L'étape suivante consiste à établir une configuration de référence plus approfondie, qui comprend un ensemble plus large d'ensembles de données. Il n'est pas recommandé d'utiliser le type de données jsonb dans Postgres pour stocker des ensembles de données homogènes dans le contexte des métadonnées pour les données géosynchrones . Si les exigences d'espace de stockage pour une seule instance de base de données ne dépassent pas celles d'une autre instance de base de données, l'instruction est maintenue en place. Les technologies RDBMS traditionnelles peuvent être utilisées pour stocker et interroger efficacement de grandes quantités de données géospatiales. Le manuel de MongoDB 2018. Le type de données JSONB dans PostgresQL accélère les opérations, selon Del Alba.
Pensez-vous que Nosql peut gérer les données d'utilisation et d'occupation des sols ? Nat Ecodyn. Ce livre a été publié de 11:438 à 4426. Vous pouvez publier cet article tant que vous suivez la licence Creative Commons (https://creativecommons.org/licenses/by/ 4.0/) sur le support de votre choix. Selon l'auteur, il n'y a pas d'intérêts concurrents. Malgré le fait que les cartes publiées et les affiliations institutionnelles contiennent des revendications juridictionnelles, Springer Nature reste neutre.
Les nombreuses utilisations du SIG
Les systèmes d'information géographique (SIG) peuvent être utilisés à diverses fins, notamment la cartographie des scènes de crime, la recherche sur le changement climatique et la gestion des terres. Il existe plusieurs types de logiciels SIG disponibles, chacun étant plus adapté à une tâche spécifique. ESRI, MapInfo et TopoGIS sont des exemples de progiciels SIG populaires.