
Bigtable de Google : le magasin de données orienté colonne le plus largement utilisé
Publié: 2022-12-19Bigtable est un magasin de données orienté colonne créé par Google. Il est conçu pour traiter de grandes quantités de données avec un haut degré de flexibilité. Bigtable est utilisé par Google depuis plus d'une décennie et constitue la base de bon nombre de ses services, notamment Gmail, Google Maps et YouTube. Bien que Bigtable ne soit pas le premier magasin de données orienté colonne, il est certainement le plus utilisé et le plus connu.
Dans cet article, nous examinerons le modèle de stockage NoSQL tridimensionnel développé par Bigtable. Pour vérifier qu'il est correctement structuré, nous allons d'abord regarder comment il est implémenté sur le plan théorique puis utiliser pour cela le client Node.js. Le modèle de stockage dans Bigtable diffère de la façon dont vous pourriez le trouver dans une base de données similaire. Plusieurs cellules dans une combinaison ligne/colonne peuvent être triées par un horodatage par cellule. Au lieu d'enregistrer les cellules dans un ordre arbitraire, chaque cellule a la valeur et un horodatage pour garantir que les cellules sont enregistrées dans un ordre ordonné. Pour cet exemple, nous utiliserons Node.js et du JavaScript simple pour créer Google Cloud Bigtable. Dans cet article, nous verrons comment créer une nouvelle instance Bigtable à l'aide du code.
Nous commençons par créer un environnement propre, en lisant et en écrivant dessus, puis en le détruisant. Lors de l'exécution de code à l'aide du client Node.js Bigtable, le client Node.js Bigtable peut provoquer une erreur d'autorisation refusée et générer un lien pour activer l'API Cloud Bigtable Admin. Vous devez également créer un compte de service distinct sur votre projet GCP pour gérer le rôle d'administrateur Bigtable. Pour créer une table Bigtable, nous devons d'abord créer une instance de la base de données et un cluster de tables. Définissez simplement un ID de table et une famille de colonnes dans le client Node.js pour ce faire, et vous êtes prêt à partir. Des lignes simples peuvent être créées à l'aide de Bigtable dans une base de données. La seule façon d'interroger des données consiste à utiliser la clé de ligne pour interroger une ligne spécifique ou un groupe de lignes.
Bien que les temps d'ingestion n'aient aucune incidence sur l'ordre dans lequel les versions sont stockées, ils ont un effet sur la manière dont elles sont stockées. Il n'est pas nécessaire de fournir la clé de ligne entière ; un simple préfixe suffit. Lorsque vous devez interroger plusieurs lignes à partir de Bigtable, je vous conseille toujours d'utiliser le streaming. Lors de l'utilisation du streaming, Bigtable n'a pas besoin de mettre en mémoire tampon les données sur le serveur avant d'envoyer des lignes, ce qui améliore les performances. Les filtres peuvent être utilisés pour limiter les versions de cellule, en renvoyant uniquement les colonnes avec des noms de famille spécifiques ou des colonnes avec des critères de qualification spécifiques. Ceci est particulièrement utile si vous avez de nombreuses versions à conserver, mais que seule la plus récente est requise à des fins spécifiques. Les filtres sont principalement utilisés pour réduire la quantité de données interrogées et envoyées afin d'améliorer les performances des requêtes.
En d'autres termes, Cloud Bigtable est une base de données NoSQL conçue pour les charges de travail d'analyse et d'exploitation. Ce système de base de données est un hybride multiplateforme qui utilise Hadoop plutôt que HBase, qui utilise une base de données en colonnes. Une grande table cloud peut être utilisée pour alimenter des applications avec un débit et une évolutivité élevés, avec une capacité inférieure à 10 Mo.
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable et Microsoft Azure CosmosDB sont des exemples de magasins à colonnes larges.
Les tables ne sont pas les mêmes que les bases de données relationnelles en termes de stockage clé/valeur. Les transactions ne peuvent être effectuées qu'une seule fois et les jointures ne sont pas prises en charge.
Google Bigtable est-il une base de données Nosql ?
Google Bigtable est une base de données NoSQL conçue pour stocker et gérer de grandes quantités de données. Bigtable est une base de données orientée colonnes, ce qui signifie que les données sont organisées en colonnes au lieu de lignes. Cela le rend bien adapté au stockage de données qui changent constamment, telles que les journaux Web ou les données des médias sociaux. Bigtable est également hautement évolutif, ce qui signifie qu'il peut facilement gérer de grandes quantités de données.
Cette base de données NoSQL peut stocker un large éventail de types de données et est extrêmement stable. Il gère également à la fois le partitionnement et la réplication, garantissant que la base de données est hautement disponible et fiable. De nombreuses applications Google l'utilisent, notamment Google Analytics, l'indexation Web, MapReduce et Google Maps, Google Livres, Mon historique de recherche, Google Earth, Blogger.com, Google Code Hosting et Google For les applications qui nécessitent une base de données capable de gérer un grand nombre d'éléments de données, Datastore est un excellent choix.
Dans quelles commandes les données sont-elles stockées dans Bigtable ?
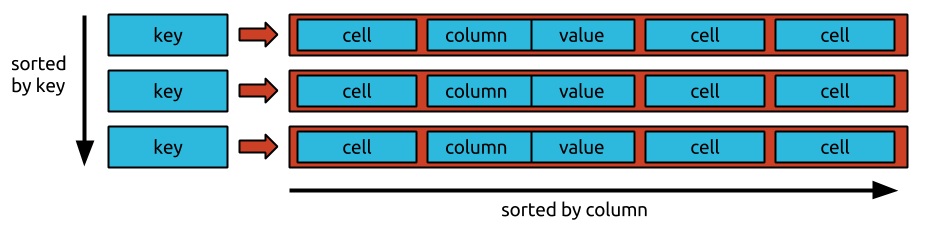
Il n'y a pas d'ordre spécifique dans lequel les données sont stockées dans bigtable. Les données sont stockées dans un ordre aléatoire, ce qui rend difficile l'accès à des données spécifiques.
Bigtable de Google : pas seulement pour stocker des données
Les données ne peuvent pas être placées dans un ordre spécifique dans l'igtable. Étant donné que Bigtable est une base de données orientée lignes, toutes les données d'une ligne sont organisées en colonnes, suivies d'une colonne. Comme les données sont stockées dans l'ordre chronologique inverse, il est simple et rapide de demander la valeur la plus récente, mais il est difficile et long de demander la plus ancienne.
Vos données sont conservées sur Colossus, le système de fichiers interne et durable de Google, qui est hébergé dans les centres de données de Google, suite à l'utilisation de Colossus par Bigtable. L'utilisation de Bigtable est gratuite et vous n'avez pas besoin d'utiliser un cluster HDFS ou tout autre système de fichiers.
Une requête vers une source de données externe peut être effectuée sans créer de table permanente avec la commande combine : Un fichier de définition de table avec une requête. Il existe une définition de schéma en ligne ainsi qu'une requête. Un fichier de définition de schéma JSON avec une requête.
Bigtable contre Datastore
Il existe quelques différences essentielles entre Bigtable et Datastore. Tout d'abord, Bigtable est un magasin de données orienté colonne, tandis que Datastore est orienté ligne. Cela signifie que dans Bigtable, les données sont organisées en colonnes, tandis que dans Datastore, elles sont organisées en lignes. Deuxièmement, Bigtable n'a pas de concept de transactions, contrairement à Datastore. Cela signifie que dans Bigtable, vous ne pouvez pas annuler les modifications à un état antérieur, alors que dans Datastore, vous le pouvez. Enfin, Bigtable est conçu pour un débit élevé et une faible latence, tandis que Datastore est conçu pour une disponibilité et une évolutivité élevées.
Quel magasin de données cloud peut être utilisé pour créer des bases de données cloud Google ? Étant donné que Bigtable prend en charge des charges de travail volumineuses avec des charges de travail back-end complexes, il est destiné aux grandes organisations et entreprises. Contrairement à SQL, qui utilise le langage de requête GQL plus restrictif, les magasins de données effectuent des transactions ACID sur des sous-ensembles de données appelés groupes d'entités (bien que le langage de requête GQL soit beaucoup plus ouvert). Google Cloud Datastore et Google Cloud Bigtable sont deux services distincts dotés de plusieurs fonctionnalités distinctes. En outre, les informations contenues dans l'image ci-dessous peuvent vous aider à sélectionner le fournisseur de services approprié pour vous. Les réponses ci-dessus, ainsi que ce qui est discuté dans le manuel Coursea Google Cloud Platform Big Data and Machine Learning Fundamentals, me serviront de guide pour cet article.
Quelle est la différence entre Bigtable et Datastore ?
Quelle est la différence entre datastore et base de données ? La grande table et le magasin de données sont tous deux conçus respectivement pour le traitement et l'analyse de données à grand volume, tandis que le magasin de données est conçu pour les données transactionnelles de grande valeur. Le Datastore est également connu sous le nom de base de données NoSQL car il n'adhère pas au standard SQL traditionnel, ce qui lui permet de conserver les données de manière plus flexible et évolutive. Quel type de magasin de données est Google Bigtable ? Le modèle de stockage Bigtable stocke les données dans des tables extrêmement évolutives qui sont triées par cartes de clés et de valeurs. Un tableau est composé de lignes, chacune décrivant une seule entité, et de colonnes, chacune avec sa propre valeur. Le magasin de données est-il obsolète ? Étant donné que l'API Cloud Datastore v1beta3 a été publiée, elle n'est plus disponible. Néanmoins, le produit Cloud Datastore est entièrement fonctionnel et pris en charge.
Base de données Bigtable
Une Bigtable est un système de stockage distribué pour la gestion de données structurées conçu pour évoluer à une très grande taille : des pétaoctets de données sur des milliers de serveurs de base. Bigtable est une base de données orientée colonnes, ce qui signifie que les données sont stockées par colonne plutôt que par ligne.
Le tableau est une structure clairsemée et densément peuplée avec des lignes et des colonnes pouvant atteindre des milliards de lignes. Une grande table est un excellent choix pour stocker de grandes quantités de données avec une faible latence. Parce qu'il prend en charge un débit de lecture et d'écriture élevé à faible latence, il s'agit d'une source de données appropriée pour les opérations MapReduce. Lors de l'utilisation d'une table Bigtable, celle-ci est partitionnée en blocs de lignes contiguës appelées tablettes afin de faciliter les requêtes. Dans un système de fichiers appelé Colossus, utilisé par Google, les tablettes sont stockées au format SSTable. Un nœud Bigtable est un sous-ensemble de chaque tablette, qui fait partie de l'instance Bigtable. L'ajout de nœuds à un cluster peut augmenter le nombre de requêtes simultanées qu'il peut gérer.

Une ligne contient un ensemble d'entrées de clé ou de valeur, qui sont une combinaison de la famille de colonnes, de l'horodatage de la colonne et de la clé. Bigtable traite toutes les données de la même manière : comme des chaînes d'octets brutes. Étant donné que Bigtable stocke les mutations de manière séquentielle et les compacte régulièrement, le nombre de mutations pouvant être stockées à un moment donné nécessite davantage d'espace de stockage. Bigtable compresse vos données à l'aide d'un algorithme sophistiqué automatisé. Comme les délétions sont en fait de nouveaux types de mutations, elles nécessitent plus d'espace de stockage à court terme. Les méthodes de stockage propriétaires de Google lui permettent d'atteindre une durabilité des données supérieure à celle obtenue par la réplication triple HDFS standard. En plus de gérer l'accès aux tables Bigtable, vous pouvez gérer l'accès à d'autres services Google Cloud en attribuant des rôles aux utilisateurs dans la section Identity and Access Management (IAM) de votre projet Google Cloud. Selon la politique de chiffrement par défaut de Google Cloud, toutes les données dans le cloud sont chiffrées au repos à l'aide des mêmes systèmes de gestion de clés renforcées que nous utilisons pour nos données chiffrées. À l'aide d'une sauvegarde, vous pouvez enregistrer une copie du schéma et des données d'une table, puis restaurer ultérieurement cette copie des données dans une nouvelle table.
Bigtable contre Cassandre
Cassandra et Bigtable utilisent des méthodes différentes pour déterminer quel nœud de traitement doit effectuer les opérations de lecture et d'écriture. Dans Cassandra, la clé de partition est appelée clé, tandis que dans Bigtable, la clé de ligne est appelée clé. La politique d'équilibrage de charge pour Cassandra doit être examinée par le client dans le cadre du processus.
Une base de données distribuée est une base de données partagée par plusieurs personnes. Cette société intègre des magasins de valeurs-clés multidimensionnels dans son système, ce qui lui permet de traiter des dizaines de milliers de requêtes par seconde (RPS). L'objectif de ce document est de comparer et de mettre en contraste les deux systèmes de base de données. Les principales fonctionnalités de Bigtable incluent : Un article sur le système de stockage distribué pour les données structurées a été créé. Si Bigtable détermine qu'un rééquilibrage de plage est nécessaire pour un ensemble de données, il est simple pour un nœud de traitement de modifier les plages de données, car la couche de stockage est distincte de la couche de traitement. Bigtable peut également être utilisé pour prendre en charge la réplication asynchrone sur des clusters répartis géographiquement jusqu'à quatre clusters dans des topologies. La tolérance aux pannes de Cassandra est liée à son niveau de cohérence réglable.
En configurant une stratégie de topologie de réplication de données, vous pouvez définir la réplication géographique. En général, un paramètre QUORUM (ou LOCAL_QUORUM dans certains centres de données) est utilisé. Pour être considérée comme réussie, le paramètre de niveau de cohérence d'une opération doit être atteint avec une majorité de nœuds de réplique répondant au nœud coordinateur. En utilisant des configurations de centre de données et de rack, les répliques de Cassandra sont capables de résister à plus de stress par rapport aux répliques traditionnelles. Lors des opérations de lecture et d'écriture, la topologie détermine les nœuds nécessaires pour garantir la cohérence. Une instance Bigtable peut contenir un seul cluster ou un groupe de jusqu'à quatre instances dupliquées de grande taille. Bigtable et Cassandra sont des magasins de données NoSQL qui sont des magasins à colonnes larges.
La clé de ligne de Bigtable est utilisée pour trier les données globales d'une table par ordre. Les nœuds de Bigtable équilibrent automatiquement la responsabilité nodale des plages de clés, également appelées tablettes, dans le cadre de la fonctionnalité Nodes de Bigtable. Le service Bigtable d'un client n'applique pas les types de données de colonne qu'il envoie. Dans Bigtable, chaque colonne d'une table se voit attribuer un nom de famille. Bien que les tables aient souvent plusieurs familles de colonnes (le nombre maximum de colonnes par table est de 100), chaque table nécessite au moins une famille de colonnes. Une intersection de clé de ligne est composée de deux cellules (une famille de colonnes combinée à un qualificatif de colonne). Dans Cassandra et Bigtable, il existe une méthode pour sélectionner le nœud de traitement pour les opérations de lecture et d'écriture.
Dans Cassandra, la clé de partition est identifiée, alors que dans Bigtable, la clé de ligne est utilisée. Une stratégie d'équilibrage de charge qui tient compte des centres de données, telle qu'une stratégie multicluster, offre la possibilité d'un basculement. Les deux bases de données utilisent une méthode similaire pour terminer une écriture et ont été optimisées pour la vitesse. Les données sont stockées dans les deux bases de données via des fichiers SSTable qui sont immuables. Dans Cassandra, le coordinateur doit informer le client que l'écriture est terminée avant que plusieurs répliques ne répondent. Une écriture réussie dans Bigtable ne peut être confirmée que par une réponse d'un nœud, car chaque clé de ligne n'est attribuée qu'à un seul nœud. Les cellules de l'une ou l'autre base de données peuvent ne pas être incluses dans la SSTable fusionnée.
En raison de la clause WHERE dans une requête CQL, il est impossible de renvoyer plus d'une ligne dans Cassandra. Seul le nœud en charge de la plage de clés doit obligatoirement être consulté dans Bigtable. Au nœud de traitement, il est possible de limiter la quantité de données pouvant être lues. Lors d'une phase de compactage, les SSTables sont régulièrement fusionnées, et les données stockées dans Bigtable et Cassandra y sont stockées. Aucune règle ne régit le nombre de versions d'horodatage pour chaque cellule, mais il peut y avoir d'autres limites de taille de ligne. Les garanties de durabilité des données sont fournies par le système de réplication de Colossus. Bigtable, comme Cassandra, dispose d'une interface de ligne de commande et de bibliothèques clientes pour de nombreux langages de programmation courants.
Chaque nœud se voit attribuer une SSTable dans Bigtable, et les données qui y sont stockées sont servies par ce nœud. Lorsque vous dimensionnez un cluster Cassandra, vous n'avez pas besoin de tenir compte des répliques de stockage comme vous le faites avec Bigtable. Les disques SSD ou les disques durs (HDD) sont les types de stockage les plus couramment utilisés pour les instances Bigtable . Comme l'a démontré Cassandra, il n'y a pas de perte de densité de stockage pour atteindre la tolérance aux pannes. Il est possible de mettre à l'échelle une instance Bigtable pour répondre aux exigences de la charge de travail avec un minimum d'effort et un minimum de temps d'arrêt. Bien qu'il n'y ait que quatre clusters, chaque cluster peut être créé dans n'importe quelle région cloud prise en charge dans le monde. Google vous recommande de tester les performances de Bigtable avec des données et des requêtes représentatives afin de générer une métrique QPS par nœud.
Cassandra exécute un grand nombre de fonctions d'administration à l'aide de composants gérés Bigtable. Les sauvegardes de grande table créent des copies restaurables de la table, qui sont stockées en tant qu'objets dans le cluster. Les sauvegardes consomment moins de ressources de nœud et sont moins chères que le stockage dans le cloud. Une autre méthode de sauvegarde de Bigtable consiste à utiliser une exportation de données gérées vers Cloud Storage. Les tâches de maintenance internes telles que les correctifs du système d'exploitation, la récupération des nœuds, la réparation des nœuds, la surveillance du compactage du stockage et la rotation des certificats SSL sont toutes gérées de manière transparente par le service Bigtable. Des tableaux de bord sont disponibles pour surveiller les métriques de débit et d'utilisation au niveau des instances, des clusters et des tables sur la page de la console Bigtable Google Cloud . Vous pouvez utiliser le tableau de bord de surveillance pour effectuer un réglage avancé des performances.
Le document Bigtable décrit un système de stockage de données qui prend en charge une évolutivité massive. Chaque table dans les données est divisée en un certain nombre de partitions. Vous pouvez interroger la table à l'aide d'une clé de ligne ou d'une plage de clés de ligne. L'article Bigtable décrit également une méthode de distribution du travail de la table sur un cluster de nœuds. Apache Cassandra, une base de données open source, est basée sur certains des concepts de l'article Bigtable. Les centres de données utilisent une architecture de nœuds distribués, dans laquelle le stockage est partagé entre les serveurs qui servent les données. L'accès au système de stockage de données de Bigtable est fourni à l'aide de l'interface de ligne de commande cbt et des bibliothèques clientes. Bigtable inclut un certain nombre de langages de programmation en plus de Python, ce qui facilite l'intégration avec les applications.
Datastax Astra Cassandra de Google en tant que service : facile à déployer et à faire évoluer
DataStax Astra Cassandra en tant que service de Google est un excellent choix pour en savoir plus sur Cassandra. L'interface utilisateur de l'opérateur Kubernetes simplifie la configuration, la gestion et la mise à l'échelle de votre déploiement Cassandra.
Documentation Bigtable
La documentation Bigtable est une excellente ressource pour en savoir plus sur cet outil puissant. Il fournit une présentation des fonctionnalités et des capacités de Bigtable, ainsi que des informations détaillées sur son utilisation. La documentation est bien organisée et facile à suivre, ce qui en fait une ressource précieuse pour quiconque souhaite en savoir plus sur cet outil puissant.
Google Cloud Platform est responsable de l'hébergement de la base de données Bigtable de Google. Il est simple d'utiliser OpenTSDB 2.1 et versions ultérieures lorsqu'il est utilisé conjointement avec le backend de Google. Tout ce que vous avez à faire est de créer une instance Bigtable, de configurer vos tables TSDB à l'aide du shell Bigtable HBase et de démarrer les TSD. Les clients de Bigtable sont actuellement en version bêta et subissent diverses modifications.
La mise en page efficace des données de Bigtable
Bigtable est également bien adapté aux opérations MapReduce. En raison de sa disposition efficace des données, MapReduce peut gérer de gros volumes de données en peu de temps.