
Hadoop HDFS et NoSQL : une combinaison puissante pour le Big Data
Publié: 2023-01-05Hadoop est un framework open source qui permet le traitement distribué de grands ensembles de données sur des clusters d'ordinateurs à l'aide d'un modèle de programmation simple. HDFS est le système de fichiers distribué Hadoop qui fournit un moyen évolutif et tolérant aux pannes de stocker des données. Les bases de données NoSQL sont une nouvelle classe de bases de données conçues pour fournir une alternative évolutive, flexible et performante aux bases de données relationnelles traditionnelles.
La principale distinction entre Hadoop et HDFS est que Hadoop est un framework open source pour le stockage, le traitement et l'analyse des données, tandis que HDFS est un système de fichiers qui permet aux utilisateurs d'accéder aux données Hadoop. Par conséquent, HDFS est un module Hadoop .
SQL et Hadoop peuvent tous deux gérer les données de différentes manières. Un framework Hadoop est utilisé pour assembler des composants logiciels, tandis qu'un framework SQL est utilisé pour assembler des bases de données. Pour le Big Data, il est essentiel de considérer les avantages et les inconvénients de chaque outil. La plate-forme Hadoop ne stocke les données qu'une seule fois, alors que Hadoop stocke un nombre beaucoup plus important d'ensembles de données.
Hadoop n'est pas une base de données, mais plutôt un logiciel qui permet un calcul parallèle massif. Cette technologie permet aux bases de données NoSQL (telles que HBase) de répartir les données sur des milliers de serveurs avec peu de dégradation des performances.
Hadoop ne stocke pas les données de la même manière que le stockage relationnel. Un serveur distribué est l'une des applications qui l'utilisent le plus. Bien qu'il s'agisse d'une base de données Hadoop , elle n'est pas considérée comme une base de données relationnelle car elle stocke des fichiers dans HDFS (système de fichiers distribué).
Quelle est la différence entre Nosql et Hdfs ?
C'est un système de fichiers, et il est également appelé système de fichiers. Il est déjà clair que cette application offre un certain nombre de fonctionnalités. Où obtenez-vous ce truc NOSQL? Nous pourrons traiter de grandes quantités de données en temps réel en l'utilisant car cela ne nous oblige pas à utiliser des bases de données relationnelles ou d'autres fonctionnalités.
Le gestionnaire de stockage HBase, qui s'exécute dans Hadoop, fournit des lectures et des écritures aléatoires à faible latence. Le système HBase utilise une fonctionnalité de partitionnement automatique dans laquelle les grandes tables sont distribuées dynamiquement. Chaque serveur de région est chargé de desservir un ensemble de régions, et il n'y a qu'un seul serveur de région capable de desservir une région (c'est-à-dire que HMaster et HRegion sont deux des principaux services fournis par HBase. Le composant HRegion de la table HBase est responsable de la gestion sous-ensembles des données de la table. Lorsqu'un serveur de région est lancé, il est affecté à chaque région. Par conséquent, le maître n'est pas impliqué dans les opérations de lecture et d'écriture.
Lorsqu'il s'agit de traiter des données non structurées et volumineuses, les bases de données NoSQL telles que MongoDB et Cassandra se démarquent des bases de données relationnelles traditionnelles. Les entreprises ayant de grandes charges de travail de données, telles que le Big Data, préfèrent utiliser ces outils pour traiter et analyser rapidement des quantités massives de données variées et non structurées. MongoDB stocke les données dans des collections, tandis que hadoop stocke les données dans un système de fichiers différent appelé HDFS. Il est avantageux d'avoir une architecture différente du fait de cette différence. Il est également beaucoup plus rapide d'interroger des données dans MongoDB que de rechercher dans des fichiers individuels. De plus, étant donné que mongodb est conçu pour les environnements à volume élevé, il est bien adapté pour gérer de gros volumes de données à un coût relativement faible. Il est recommandé aux entreprises qui ont besoin de solutions Big Data d'utiliser des bases de données NoSQL. Elles présentent de nombreux avantages par rapport aux bases de données traditionnelles en termes de vitesse de traitement et d'analyse, et elles sont bien adaptées à l'analyse et à la gestion de données à grande échelle.
Hadoop est-il une base de données Nosql ?
Hadoop n'est pas un système traditionnel de gestion de bases de données relationnelles. Il s'agit d'un système de fichiers distribué qui permet de stocker et de traiter de grands ensembles de données sur un cluster de serveurs de base. Hadoop est conçu pour passer de serveurs uniques à des milliers de machines, chacune offrant un calcul et un stockage locaux.
L'utilisation des données à une échelle super massive est en train d'être révolutionnée par les nouvelles technologies. L'infrastructure Big Data compte de nombreux acteurs, dont Hadoop, NoSQL et Spark. Les DBA et les ingénieurs/développeurs d'infrastructure travaillent maintenant pour eux pour gérer des systèmes complexes dans une nouvelle génération de DBA et d'ingénieurs d'infrastructure. Parce que Hadoop est un écosystème logiciel plutôt qu'une base de données, il permet le calcul de quantités massives de données à un rythme à la fois efficace et efficient. Les avantages qu'il offre pour les quantités massives de données qu'il traite ont changé la donne pour le traitement du Big Data. Une transaction de données importante, telle qu'une transaction qui prend 20 heures sur un système de base de données relationnelle centralisé, peut être effectuée en seulement trois minutes sur un cluster Hadoop.
Il existe plusieurs langages SQL parmi lesquels choisir. MongoDB, une base de données de documents purs, est un type de base de données NoSQL ; Cassandra, une base de données à larges colonnes, en est une autre ; et Neo4j, une base de données de graphes, en est une autre. Cette fonctionnalité a été créée par SQL-on- Hadoop . SQL-on-Hadoop est une nouvelle classe d'outils d'analyse qui combine des requêtes SQL établies avec des cadres de données Hadoop. SQL-on-Hadoop permet aux développeurs d'entreprise et aux analystes commerciaux de collaborer avec Hadoop sur des clusters informatiques de base en autorisant l'exécution de requêtes SQL familières. Les avantages de SQL sur hadoop. Les nombreux avantages de SQL-on-Hadoop, en plus de sa facilité d'utilisation, valent bien le temps et les ressources des développeurs et analystes de données d'entreprise. Pour commencer, ils peuvent travailler avec Hadoop sur des clusters informatiques de base, ce qui leur permettra de se lancer rapidement et facilement dans l'analyse du Big Data. SQL-on-Hadoop leur permet également d'exploiter des requêtes SQL familières, ce qui leur facilite l'apprentissage de l'analyse de données volumineuses. De plus, SQL-on-Hadoop fournit la fonctionnalité de mappage/réduction de Hadoop ainsi que les riches capacités d'analyse de données qu'il fournit.
Bases de données Nosql à la hausse
En conséquence, les bases de données NoSQL deviennent de plus en plus populaires en raison de leur évolutivité, de leurs performances en lecture/écriture et de la flexibilité des données. Il existe plusieurs bons exemples de bases de données NoSQL sur le marché, notamment DynamoDB, Riak et Redis.
Hive est une base de données NoSQL légère et modulaire avec d'excellentes mesures de performances. Il est écrit dans le langage de programmation Dart pur et est populaire parmi les développeurs en raison de sa simplicité.
Quelle est la différence entre Hadoop et la base de données ?

Alors que le SGBDR ne stocke ni ne traite les données, Hadoop stocke et traite plutôt les données comme un système de fichiers distribué. Un SGBDR, en revanche, est une base de données structurée qui stocke les données en lignes et en colonnes et peut être mise à jour avec SQL et présentée dans une variété de tables.
L'adoption de technologies et d'outils de mégadonnées s'est développée à un rythme rapide. Une distribution Hadoop open source s'exécute sur un système de fichiers distribué et permet l'échange et le traitement de grands ensembles de données. Un RDB est un système de gestion de base de données de base qui est utilisé dans sa forme la plus simple par tous les systèmes de gestion de base de données tels que Microsoft SQL Server, Oracle et MySQL. Bien qu'il soit classé comme une évolution, un SGBDR ressemble plus à n'importe quelle autre base de données standard qu'à une entreprise majeure. Ce n'est pas une base de données, mais plutôt un système de fichiers distribué qui peut héberger et traiter de grandes collections de fichiers de données. Bien que des systèmes comme Hadoop puissent offrir de meilleures performances, certains inconvénients sont rarement évoqués. Vous devez réfléchir à la manière de gérer votre cluster Hadoop, la sécurité, Presto ou toute autre interface que vous utilisez.
La majorité des systèmes de bases de données relationnelles, tels que SQL Server et Oracle, sont beaucoup plus faciles à utiliser. La plupart des organisations sont confrontées au problème majeur du manque de personnel qualifié capable d'exploiter efficacement Hadoop, ainsi qu'à un coût important des talents. Si vous avez 10 000 employés, vous aurez besoin de beaucoup de données pour les suivre tous. Ces informations peuvent être stockées de différentes manières avec Presto. Une partition de date peut être utilisée pour stocker la position d'une personne chaque jour. Le SGBDR, en revanche, peut être utilisé comme exemple de modèle de données. La seule façon d'utiliser cette méthode est si vous avez déjà accès aux données de la veille.
Quelle est la principale différence entre les bases de données relationnelles et le Big Data ?
La principale distinction entre les bases de données relationnelles et les mégadonnées est que les bases de données relationnelles sont optimisées pour stocker des données structurées, tandis que les mégadonnées sont optimisées pour stocker des données non structurées et semi-structurées. Une base de données relationnelle est modélisée d'après le modèle relationnel, tandis qu'une base de données Big Data est modélisée d'après le modèle distribué. Les données structurées peuvent être stockées et traitées dans des bases de données relationnelles de manière efficace. La table contient des données et permet l'accès et la récupération en langage de requête structuré (SQL). Les mégadonnées sont définies comme toutes les données non structurées ou semi-structurées.

Quelle est la différence entre Hadoop et Mongodb ?
Étant donné que MongoDB s'exécute en C, il est meilleur en termes de gestion de la mémoire que toute autre base de données. Hadoop est un ensemble de logiciels basés sur Java qui fournit un cadre pour le stockage, la récupération et le traitement des données. Hadoop optimise l'espace plus efficacement que MongoDB.
MongoDB était une base de données NoSQL (pas seulement SQL) créée en C. Hadoop est une plate-forme logicielle open source principalement composée de Java qui permet le traitement de grandes quantités de données. De plus, MongoDB Atlas inclut une recherche en texte intégral, des analyses avancées et un langage de requête intuitif. Hadoop est efficace pour stocker et traiter une grande quantité de données, mais il le fait par petits lots. Il existe une variété d'outils de traitement de données en temps réel intégrés disponibles dans MongoDB. Grâce à ses connecteurs pour des outils externes tels que Kafka et Spark, MongoDB simplifie l'ingestion et le traitement des données. Les avantages de Hadoop et MongoDB par rapport aux bases de données traditionnelles dans le domaine du big data sont nombreux. Hadoop, un système de fichiers distribué, peut être utilisé pour traiter d'énormes fichiers. MongoDB est la seule base de données capable de remplacer une base de données traditionnelle en termes de performances.
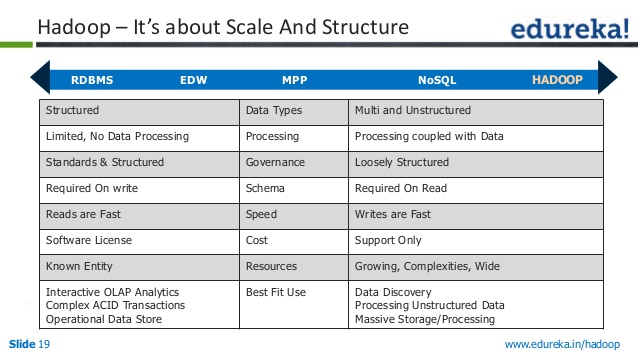
Rdbms contre Nosql contre Hadoop
Il existe trois principaux types de magasins de données : RDBMS, NoSQL et Hadoop. Ils ont chacun leurs propres forces et faiblesses, il est donc important de choisir celui qui convient à vos besoins.
RDBMS (Relational Database Management System) est le type de stockage de données le plus courant. Il est facile à utiliser et facile à mettre à l'échelle. Cependant, il n'est pas aussi flexible que NoSQL ou Hadoop, et sa maintenance peut être plus coûteuse.
NoSQL (Not Only SQL) est un nouveau type de magasin de données qui devient de plus en plus populaire. Il est plus flexible que RDBMS et peut être plus évolutif. Cependant, il n'est pas aussi facile à utiliser et peut être plus coûteux à entretenir.
Hadoop est un type de magasin de données conçu pour le Big Data. Il est très évolutif et peut gérer beaucoup de données. Cependant, il n'est pas aussi facile à utiliser que RDBMS ou NoSQL, et sa maintenance peut être plus coûteuse.
L'approche d'une entreprise en matière de stockage, de traitement et d'analyse des données peut être considérablement améliorée avec la plate-forme Apache Hadoop . Un lac de données peut exécuter plusieurs types de charges de travail analytiques sur le même matériel et logiciel, ainsi que gérer des volumes de données à grande échelle. Les analystes peuvent désormais interagir efficacement avec les données en déplacement à l'aide d'outils comme Apache Impala et Apache Spark. Hadoop, contrairement au système de gestion de base de données relationnelle (RDBMS), n'a pas les mêmes capacités qu'une base de données, mais est plutôt un système de fichiers distribué capable de traiter d'énormes quantités de données. La quantité de données qui peut être traitée facilement et efficacement est appelée volume de données. En d'autres termes, c'est le traitement du volume total de données sur une période de temps spécifique qui peut être optimisé. Il a la capacité de stocker et de traiter des données provenant d'un large éventail de sources et de les préparer pour l'analyse.
En petite quantité, le SGBDR ne pouvait gérer que des données structurées et semi-structurées. Hadoop est incapable de gérer des données provenant de diverses sources ou de toute structure structurée. Le temps de réponse, l'évolutivité et le coût sont quelques-uns des autres facteurs importants à prendre en compte.
Pourquoi Rdbms est toujours le système de gestion de base de données le plus populaire
Le système de gestion de base de données le plus utilisé dans le monde est le RDBMS. Il offre un large éventail de fonctionnalités, tout en étant extrêmement fiable. La base de données relationnelle est la mieux adaptée au stockage des données nécessaires à l'accès de plusieurs utilisateurs.
Les bases de données NoSQL gagnent en popularité en partie en raison de leurs avantages en termes de performances par rapport aux bases de données relationnelles. Ils vous permettent également de stocker de grandes quantités de données que vous n'avez pas besoin de partager avec plusieurs utilisateurs.
Hadoop Nosql
Sur un cluster matériel de base, Hadoop stocke le Big Data. Vous avez la possibilité de modifier toute fonction qui ne fonctionne pas ou répond à vos besoins si nécessaire. En revanche, un système de gestion de base de données NoSQL est un type de système de gestion de base de données utilisé pour stocker des données structurées, semi-structurées et non structurées.
Hdfs est-il une base de données
Le système de fichiers HDFS est un système de fichiers distribué qui s'exécute sur du matériel standard. Un seul cluster Apache Hadoop peut être configuré pour prendre en charge des centaines (voire des milliers) de nœuds à l'aide de cette fonctionnalité. Apache Hadoop, qui comprend également MapReduce et YARN, est composé de plusieurs composants majeurs.
Un accès hautes performances aux données est fourni par Hadoop Distributed File System (HDFS), qui est un composant du système d'exploitation Hadoop . Le nœud de nom principal d'un cluster est responsable du suivi de l'emplacement de stockage des données de fichier du cluster. Outre la gestion de l'accès aux fichiers, le nœud Nom gère l'accès aux fichiers tels que les lectures, les écritures, les créations, les suppressions, etc. Yahoo a introduit le système de fichiers distribués Hadoop dans le cadre de ses exigences en matière de placement d'annonces en ligne et de moteur de recherche. Le protocole HDFS expose un espace de noms de système de fichiers afin de stocker les données utilisateur. Les DataNodes peuvent communiquer entre eux pendant les opérations normales sur les fichiers car ils communiquent entre eux. Le système de fichiers distribués Hadoop (HDFS) est un composant de nombreux lacs de données open source. HDFS est utilisé par eBay, Facebook, LinkedIn et Twitter pour analyser de grandes quantités de données. En cas de défaillance d'un nœud ou d'un matériel, la réplication des données est nécessaire pour que HDFS fonctionne correctement.
Exemple de base de données Hadoop
Une base de données Hadoop est une base de données qui utilise le système de fichiers distribués Hadoop (HDFS) pour son stockage sous-jacent. Les bases de données Hadoop sont généralement utilisées pour stocker de grandes quantités de données qui sont trop volumineuses pour tenir sur un seul serveur.
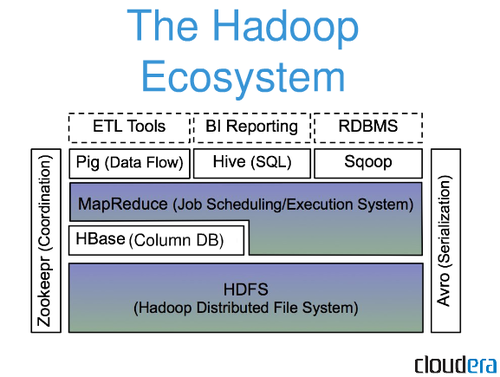
Framework open source pour le stockage et le traitement de grands ensembles de données de manière distribuée sur du matériel de base, Apache Hadoop est utilisé dans une variété d'applications. Il s'agit d'une version open source du paradigme Google qui a été utilisé dans leur article MapReduce de 2004. Nous passerons en revue certaines des questions les plus fréquemment posées par les débutants dans l'écosystème Big Data dans cet article. La plate-forme Apache Hadoop se concentre sur le traitement de données distribué plutôt que sur le stockage de base de données ou le stockage relationnel. Malgré la présence d'un composant de stockage appelé HDFS (Hadoop Distributed File System), qui stocke les fichiers utilisés pour le traitement, HDFS entre dans la catégorie des bases de données relationnelles. Hive, ainsi que HiveQL, peuvent être utilisés pour interroger le stockage HDFS de HDFS, qui est intégré à HDFS.
Qu'est-ce qu'un exemple de Hadoop ?
Hadoop peut être utilisé par les sociétés de services financiers pour évaluer les risques, créer des modèles d'investissement et créer des algorithmes de trading ; Hadoop a également été utilisé pour aider à la création et à la gestion de ces applications. Cette technologie est utilisée par les détaillants pour les aider à mieux comprendre et servir leurs clients en analysant des données structurées et non structurées.
Les nombreuses utilisations de Hadoop
Hadoop peut être utilisé pour gérer les données dans des applications de données volumineuses telles que l'analyse de données volumineuses, l'analyse de données en temps réel, la recherche scientifique et l'entreposage de données. En conséquence, il s'agit d'une plate-forme polyvalente et adaptable idéale pour un large éventail d'applications.
Spark est-il une base de données Nosql
Un NoSQL DataFrame, selon la documentation, est un format de source de données pour le Spark DataFrame. L'élagage des données et le filtrage (refoulement de prédicat) sont disponibles dans cette source de données, ce qui permet aux requêtes Spark de s'exécuter sur de plus petites quantités de données, et seules les données requises pour la tâche active sont chargées.
Il faut beaucoup d'efforts tactiques pour connecter une base de données Apache Spark et NoSQL (Apache Cassandra et MongoDB). Ce blog explique comment créer des applications Apache Spark sur des backends NoSQL. TCP/IP sPark est une destination de parc à thème populaire avec un grand nombre de manèges dans ses célèbres sections CassandraLand et MongoLand. Lorsque notre application Spark recherchait des données du DOE, elle tournait les roues et devenait frustrée. La leçon ici est que la séquence de clés de Cassandra est essentielle dans le processus de récupération des données. CassandraLand possède également des montagnes russes populaires appelées Partitioner. Les clients des manèges en montagnes russes sont encouragés à garder une trace de leur historique de manège afin que les opérateurs puissent suivre qui l'a monté chaque jour. Mongo Leçon 1 - Gérer correctement les connexions MongoDB Lors de la mise à jour de données, telles que le statut des nouveaux membres du parc du ministère de l'Énergie, les index Mongo peuvent être très utiles. Dans le cas de mises à jour spécifiques, MongoDB et Spark doivent assurer une bonne gestion et indexation des connexions.
Spark : l'avenir du Big Data
Apache Spark, un système de traitement distribué développé en collaboration avec Apache Software Foundation, est un système de traitement de données volumineuses basé sur Hadoop. Un framework open source qui peut être utilisé pour optimiser de grands ensembles de données et combler le fossé entre les modèles procéduraux et relationnels. De plus, Spark prend en charge MongoDB, ce qui lui permet d'être utilisé pour l'analyse en temps réel et l'apprentissage automatique.