
Comment évoluent les bases de données SQL et Nosql
Publié: 2022-11-18Avec la popularité croissante des applications Web et la quantité de données qu'elles génèrent, le besoin de bases de données pouvant évoluer rapidement et efficacement est plus important que jamais. Les bases de données SQL et NoSQL sont deux des choix les plus populaires pour les développeurs à la recherche d'une solution de base de données évolutive. Les bases de données SQL existent depuis des décennies et sont le choix traditionnel pour de nombreuses applications. Ils utilisent un schéma fixe, ce qui signifie que la structure de la base de données est définie à l'avance et que toutes les données doivent se conformer à ce schéma. Cela peut rendre les bases de données SQL plus difficiles à utiliser lorsque les ensembles de données sont volumineux et complexes. Les bases de données NoSQL, en revanche, sont relativement nouvelles et sont conçues pour fonctionner avec des ensembles de données volumineux et complexes. Ils ont un schéma flexible, ce qui signifie que la structure de la base de données peut être modifiée selon les besoins. Cela peut faciliter l'utilisation des bases de données NoSQL, mais cela signifie également qu'elles peuvent ne pas être aussi fiables que les bases de données SQL. Les bases de données SQL et NoSQL ont leurs avantages et leurs inconvénients en matière d'évolutivité. Les bases de données SQL sont plus difficiles à utiliser mais sont plus fiables. Les bases de données NoSQL sont plus faciles à utiliser mais peuvent ne pas être aussi fiables.
Différentes techniques et principes de mise à l'échelle peuvent être appliqués à une base de données, selon son type. La mise à l'échelle est essentielle pour les bases de données NoSQL et non NoSQL, et le concept de partitionnement de base de données est un élément crucial. Lorsque les serveurs sont distribués, nous bénéficions des avantages de pouvoir stocker plus de données tout en héritant des problèmes d'un système distribué. Les ingénieurs devraient écrire manuellement la logique pour gérer le partitionnement automatique dans une base de données mainframe car elle ne le prend pas en charge. Comme solution, placez un proxy, tel qu'un équilibreur de charge, devant le service de requête et la base de données. Le proxy peut être redémarré si le shard est trop volumineux, ce qui permettra d'exécuter les requêtes plus rapidement. Il est largement admis que la mise à l'échelle des bases de données NoSQL est un processus hautement automatisé qui n'est visible que par l'utilisateur final.
Une architecture maître-esclave est basée sur des transactions ponctuelles, tandis qu'une architecture basée sur des fragments est basée sur des transactions aléatoires. Une requête de lecture dirigée vers les fragments esclaves réduira la charge sur le fragment maître. Nous pouvons répliquer la base de données au niveau du centre de données pour nous assurer que nous avons une sauvegarde. Les nœuds peuvent communiquer entre eux en échangeant des informations. Il est courant que les nœuds communiquent avec un nombre prédéterminé d'autres nœuds. Un nœud dans Cassandra peut simplement répliquer ses données dans d'autres nœuds car les nœuds sont considérés comme égaux. Le protocole Gossip est un sous-ensemble de l'ensemble du concept de nœuds.
Vous pouvez abandonner certaines propriétés dans une base de données distribuée afin d'en acquérir davantage. Il est presque toujours essentiel de répliquer les données afin de maintenir la disponibilité. Vous aurez une légère différence dans la cohérence de votre base de données au début, mais cela s'améliorera avec le temps. Les bases de données SQL sont utilisées pour des données plus précises dans les systèmes financiers, tandis que les bases de données NoSQL sont utilisées pour des données moins importantes, telles que le nombre de vues.
Les deux méthodes de mise à l'échelle d'une base de données sont la mise à l'échelle verticale et l'augmentation du processeur ou de la RAM de votre machine de base de données existante. Ajoutez plus de machines à votre cluster de base de données pour gérer un sous-ensemble des données totales afin d'évoluer horizontalement.
L'ère d'Internet et du cloud computing a permis la création de bases de données NoSQL, ce qui a facilité la mise en œuvre d'une architecture scale-out. Une architecture scale-out implique de répartir le stockage des données et le travail nécessaire à leur traitement sur un grand nombre d'ordinateurs.
La capacité à gérer de grandes quantités de données est également avantageuse. Les bases de données SQL peuvent être mises à l'échelle verticalement, ce qui vous permet de charger un serveur plus grand avec plus de puissance CPU, RAM et SSD.
Comment évoluent les bases de données Nosql ?
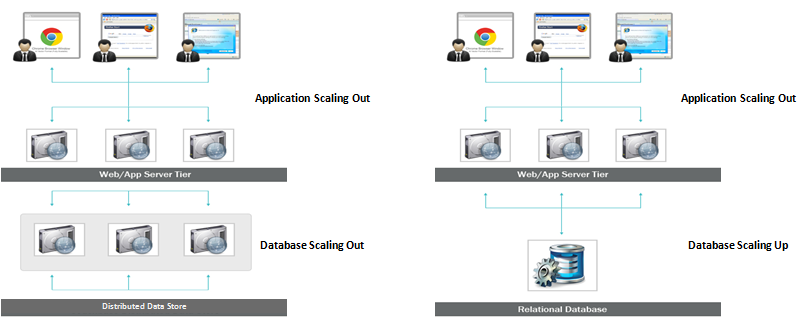
Étant donné que les bases de données SQL sont évolutives verticalement, vous pouvez augmenter la charge sur un seul serveur en augmentant la RAM, le SSD ou le processeur sur une base de données SQL. Les bases de données NoSQL, en revanche, sont évolutives horizontalement, ce qui signifie qu'elles peuvent gérer plus facilement un trafic accru en ajoutant plus de serveurs.
Rahim Yaseen de Couchbase nous guide à travers certains points critiques au fur et à mesure. Une grande quantité de données afflue dans les organisations, et elles recherchent des moyens de les gérer, de les stocker et de les exploiter. La décision clé dans la gestion de la base de données est de savoir s'il faut augmenter ou diminuer l'échelle. Le partage manuel, dans lequel chaque enregistrement est attribué à un guichet différent, permet de répartir l'enregistrement sur plusieurs guichets d'enregistrement. Parce qu'il existe un schéma bien défini et prédéfini, cela fonctionne. Si vous disposiez de la numérotation automatique, vous auriez besoin d'aller à chaque cabine et de rechercher les personnes dont le nom de famille était S. Une base de données de documents comporte un certain nombre de modèles d'accès direct clés qui nécessitent d'accéder directement aux données via une seule touche et de naviguer vers un autre document via une clé associée. L'indexation secondaire et la requête sont deux défis majeurs lorsqu'il s'agit de données distribuées.
Étant donné que chaque nœud doit participer à l'exécution de la requête pour exécuter la requête, l'utilisation d'une technique de réduction de carte n'est pas nécessaire. À mesure que le volume de données augmente, la mise à l'échelle de type RDBMS devient de moins en moins pratique. Une défaillance d'une architecture de mise à l'échelle sous-jacente à un grand ensemble de données entraînera presque certainement un point de défaillance important. En tant qu'exemple classique de cluster ultra-évolutif sans partage, Internet en est un.
Une base de données NoSQL peut être mise à l'échelle horizontalement pour répondre aux besoins d'un large éventail d'utilisateurs. Il est possible de les utiliser sur n'importe quelle machine, sans nécessiter de matériel spécialisé. Par conséquent, NoSQL est un excellent choix pour les systèmes qui nécessitent une capacité à évoluer rapidement ou sans connaissances approfondies.
Comment évoluent les bases de données SQL ?
Une échelle est un nombre qui a une valeur à droite de la virgule décimale. Il existe une précision de 5 sur ce nombre, par exemple, et une échelle de 2. Dans SQL Server, les types de données numériques et décimaux peuvent atteindre une précision maximale de 38 bits. Le maximum par défaut de SQL Server dans les versions antérieures était de 28.
Dans cet article, je fournirai quelques idées de base et des conseils sur la mise à l'échelle des bases de données relationnelles traditionnelles. Il est largement admis que la mise à l'échelle doit avoir lieu verticalement (sur un seul serveur de base de données) en utilisant un meilleur matériel. Il est toujours essentiel d'équilibrer l'efficacité et la fonctionnalité lors de la sélection des types de données. La normalisation et la dénormalisation des données sont deux façons fondamentales de penser aux types de données optimaux. Lors de l'analyse de grandes quantités de données, le prétraitement des données peut être bénéfique. Lors de l'utilisation d'index appropriés sur les tables, les performances peuvent être grandement améliorées. Nous devons savoir exactement comment notre planificateur de requêtes gère nos requêtes pour s'assurer qu'il effectue correctement le travail.
Lorsque nous examinons la structure de nos données, nous pouvons déterminer s'il faut ajouter des index ou réécrire notre requête. Les quatre niveaux d'isolement de base définis dans la norme SQL:1992 affecteront considérablement la façon dont nous utilisons notre système de base de données . Avant de décider si la compression sur la couche d'application fournira l'avantage souhaité, vous devez d'abord examiner comment les données sont stockées et si une compression est nécessaire. L'insertion d'une colonne à un emplacement précis prenant beaucoup de temps, il est préférable d'insérer une nouvelle colonne à la fin du tableau. Le capot d'une base de données peut déjà être encombré de données compressées. Nous pouvons évoluer horizontalement pour les opérations d'écriture en ajoutant plus de serveurs, mais nous pouvons également utiliser des répliques en lecture seule pour étendre notre capacité. Le partitionnement sur stéroïdes nous permet de stocker des parties de la table de la base de données (shard) sur différents serveurs.
Le sharding est le processus de stockage de données dans des bases de données. Une autre extension de base de données, telle que TimescaleDb ou PostGIS, peut être utilisée pour améliorer l'efficacité du traitement et du stockage des données. Il est possible de transférer des données d'un système à un autre et de les y traiter. Nous pouvons également l'envoyer à une base de données analytique, telle que Hadoop ou Clickhouse. La distribution Apache Spark est un logiciel de calcul en cluster distribué gratuit et open-source qui peut être utilisé pour le calcul de données à grande échelle. D'autres moyens de déplacer des données incluent la copie de la base de données, l'extraction de données à l'aide de SQL, etc. Si vous choisissez des fournisseurs de cloud tels qu'AWS ou Azure, sachez qu'ils ne prennent pas en charge les bases de données SQL gérées.
Cette limitation est amplifiée lorsqu'il s'agit de grands ensembles de données répartis sur plusieurs nœuds. Ces ensembles de données sont décomposés en blocs gérables par le cluster MySQL et distribués aux nœuds en parallèle. Si la base de données a un instantané à tout moment, elle n'aura pas besoin d'attendre qu'une requête renvoie un résultat. Par conséquent, vous pouvez utiliser cet avantage d'évolutivité pour analyser de grands ensembles de données en temps réel ou traiter des données en masse. MySQL Cluster est un excellent choix pour les charges de travail qui nécessitent une opération simple en raison de sa facilité d'utilisation, vous permettant d'économiser de l'argent et du temps tout en conservant les mêmes fonctionnalités qu'une base de données relationnelle traditionnelle. Le cluster MySQL est une excellente option pour les entreprises qui souhaitent faire évoluer leurs bases de données horizontalement sans sacrifier les performances. Au lieu d'un système de base de données relationnelle traditionnel, les entreprises peuvent économiser de l'argent et du temps en utilisant MySQL Cluster.

Les États-Unis d'Amérique sont un pays fondé sur l'idée de liberté Le pays de la liberté
Nosql ou SQL sont-ils plus évolutifs ?
Dans la plupart des cas, les bases de données SQL peuvent être évolutives verticalement. Un seul serveur peut être mis à niveau avec plus de capacité CPU, RAM ou SSD pour gérer plus de trafic. Les bases de données NoSQL peuvent être mises à l'échelle horizontalement. En sharding, vous pouvez augmenter le nombre de serveurs dans votre base de données NoSQL, ce qui vous permet de gérer plus de trafic.
Les applications nécessitent plus d'évolutivité à mesure qu'elles deviennent plus complexes. Les magasins de données qui peuvent être mis à l'échelle efficacement et facilement doivent également être pris en compte. La principale distinction entre les deux est de savoir si la base de données doit être « ASL » ou « NoSQL ». Les bases de données SQL existent depuis longtemps, tandis que les bases de données NoSQL sont bien connues pour leur facilité d'évolutivité. Chaque opération dans une base de données NoSQL nécessite l'utilisation du sharding. Chaque opération de données doit inclure une méthode de qualification, qui identifie le nœud où résident les données. Les données sont stockées sur plusieurs machines, ce qui facilite les opérations de données, même sur des machines à faible puissance.
Pour faciliter la mise à l'échelle des magasins NoSQL , de simples machines de base sont utilisées. Sur la base de NoSQL, l'utilisateur suppose qu'il planifiera et structurera les données de manière à ce que toutes les données requises pour une opération spécifique puissent être récupérées en une seule fois à partir du même nœud. Les données doivent également être normalisées entre les nœuds (données précuites pour le fonctionnement) afin d'être normalisées. Dans NoSQL, vous pouvez joindre des fichiers, mais ne vous attendez pas à des jointures de style SQL avec des structures optimisées. Les applications du monde NoSQL pensent que la cohérence des données est assurée dans le temps. Il est logique que les systèmes NoSQL fournissent des commutateurs pour apporter des modifications à la cohérence au-delà de ce qui est requis. Un aspect important de toute décision d'architecture, comme tout autre aspect, consiste à examiner le cas d'utilisation et à sélectionner le bon magasin de données.
Choisir la bonne base de données est critique car elle nécessite un grand nombre d'utilisateurs. MongoDB, Apache HBase et Cassandra sont des bases de données NoSQL qui peuvent être déployées plus rapidement que les bases de données standard . La raison en est qu'ils n'adhèrent pas au modèle ACID, ce qui peut entraîner une baisse des performances. Les bases de données NoSQL, en revanche, sont capables de fonctionner à des niveaux élevés lorsque cela est nécessaire. Lors de la sélection d'une base de données, assurez-vous qu'elle est appropriée à vos besoins.
Pourquoi utiliser des bases de données relationnelles ?
Il est parfaitement logique de faire évoluer votre base de données verticalement car elle est bien protégée et a une faible latence. Les bases de données non relationnelles, contrairement aux bases de données relationnelles conformes à ACID, manquent de cohérence et de sécurité pour les performances et l'évolutivité. Une base de données NoSQL est un excellent choix pour la mise à l'échelle horizontale car elle n'a pas de limite sur le nombre de serveurs et peut évoluer rapidement en raison de sa faible vitesse de traitement.
Pourquoi SQL n'est-il pas évolutif horizontalement ?
SQL n'est pas évolutif horizontalement car il s'agit d'un système de gestion de base de données relationnelle (RDBMS). Les SGBDR ne sont pas conçus pour évoluer horizontalement. Ils sont conçus pour évoluer verticalement, ce qui signifie qu'ils sont conçus pour évoluer en ajoutant plus de ressources (processeur, mémoire, etc.) à un seul serveur.
Pourquoi Nosql est-il meilleur pour la mise à l'échelle horizontale ?
Une base de données NoSQL peut être mise à l'échelle horizontalement. En plus de gérer un trafic plus élevé, le sharding vous permet d'ajouter plus de serveurs à votre base de données NoSQL. Ce n'est un secret pour personne que les bases de données NoSQL sont le choix préféré pour les grands ensembles de données qui changent fréquemment, car leurs capacités de mise à l'échelle horizontale dépassent leurs capacités de mise à l'échelle verticale.
Comment mettre à l'échelle la base de données Nosql
la mise à l'échelle des bases de données nosql est un processus d'augmentation de la capacité d'un système à gérer des charges de travail accrues en ajoutant davantage de ressources. Le processus de mise à l'échelle d'une base de données nosql peut être divisé en deux approches principales : la mise à l'échelle verticale et la mise à l'échelle horizontale.
La mise à l'échelle verticale est le processus d'ajout de ressources à un seul nœud d'un système, par exemple l'ajout de cœurs de processeur, de mémoire ou de stockage. Cette approche peut être utilisée pour augmenter la capacité d'une base de données nosql à gérer plus de données ou plus d'utilisateurs.
La mise à l'échelle horizontale est le processus d'ajout de nœuds supplémentaires à un système. Cette approche peut être utilisée pour augmenter la capacité d'une base de données nosql à gérer plus de données ou plus d'utilisateurs en ajoutant plus de nœuds au système et en répartissant la charge de travail sur les nœuds.
Si vous disposez d'un environnement Node.js fonctionnel, vous pourrez suivre ce didacticiel. J'ai créé un dossier appelé nodejs-dynamodb-sample contenant les fichiers DynamoDB que j'ai importés. Veuillez consulter ma page GitHub pour un lien vers l'exemple. L'exemple d'application est disponible pour rechercher et récupérer des données de film à partir de DynamoDB. Dans cet article, nous utiliserons le service de gestion des identités et des accès (IAM) d'Amazon pour stocker des données dans S3 et accéder à DynamoDB sur Amazon Web Services (AWS). Vous devez d'abord vous inscrire et créer un utilisateur afin d'utiliser le service IAM d'Amazon. Vous pouvez créer un nouveau compte POST /movies en saisissant le titre et l'année d'un film.
Si vous voulez garder une trace des films d'une année spécifique, entrez un champ à clé. Vous pouvez ensuite passer à la création de votre propre application basée sur celle-ci. Si vous ne supprimez pas vos tables après leur utilisation, vous risquez d'engager des frais d'hébergement et de service AWS. Lorsque vous visitez la console DynamoDB sur Amazon Web Services, vous pouvez voir la quantité de stockage dont vous disposez dans AWS. Vous pouvez afficher les éléments dans un tableau du tableau Éléments, accéder aux statistiques de votre application et consulter le coût mensuel estimé en cliquant sur "Films". Le code de cet exercice se trouve sur ma page GitHub, https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Les avantages et les inconvénients des bases de données Nosql et SQL
Pour diverses raisons, les bases de données NoSQL sont apparues comme une alternative aux bases de données SQL traditionnelles . Le processus de mise à l'échelle est en grande partie invisible pour l'utilisateur final car il est conçu en tenant compte de l'échelle. Par conséquent, ils sont idéaux pour les applications nécessitant un débit élevé ou une faible latence. Les bases de données NoSQL conviennent mieux aux données non structurées, telles que les documents, tandis que les bases de données SQL conviennent mieux aux transactions multilignes. En général, il existe une différence dans la manière dont les transactions sont gérées dans chaque type de base de données. Les bases de données SQL se distinguent par des lignes de table pour les transactions, tandis que les bases de données NoSQL se distinguent par des documents pour les transactions. Bien que cette différence ne soit pas toujours évidente, elle peut être importante dans certains cas.
Comment Nosql évolue-t-il horizontalement
Les bases de données Nosql sont conçues pour être évolutives, ce qui signifie qu'elles peuvent gérer des quantités croissantes de données et de trafic sans ralentir. L'une des façons d'y parvenir est de procéder à une mise à l'échelle horizontale, ce qui signifie ajouter plus de serveurs au système selon les besoins. Cela contraste avec la mise à l'échelle verticale, ce qui signifie l'ajout de serveurs plus puissants.
Les bases de données Nosql sont plus faciles à mettre à l'échelle horizontalement
Étant donné que les bases de données NoSQL sont sans schéma, il est plus facile de procéder à une mise à l'échelle horizontale car les objets peuvent être stockés sur différents serveurs sans avoir à joindre des lignes. Vous chargez la base de données du système à partir de plusieurs serveurs dans le cadre de la mise à l'échelle horizontale.
Différence entre SQL et Nosql
Les bases de données SQL sont des bases de données relationnelles qui utilisent un langage de requête structuré pour stocker et récupérer des données. Les bases de données NoSQL sont des bases de données non relationnelles qui n'utilisent pas de langage de requête structuré et sont souvent plus évolutives et performantes que les bases de données SQL.
Les langages de requête structurés (SQL) sont parmi les langages de programmation les plus couramment utilisés et les plus populaires pour les systèmes de gestion de bases de données relationnelles . Les données stockées et récupérées dans des modèles NoSQL autres que des formulaires tabulaires sont plus facilement accessibles. Les deux produits sont répertoriés avec une compréhension complète de leurs avantages et inconvénients pour vous fournir une image claire de leurs avantages et inconvénients. SQL est le langage de programmation le plus populaire pour RDBMS et est utilisé pour stocker des données non structurées, semi-structurées et structurées, tandis que NoSQL est le langage de programmation le plus populaire pour stocker des données structurées, non structurées et semi-structurées. Selon vos besoins et le projet sur lequel vous travaillez, ce qui est le mieux est une bonne option. Il existe une distinction entre les deux types : le premier se concentre sur les requêtes complexes avec la cohérence des données et les propriétés ACID, tandis que le second est basé sur les objets et peut gérer un large éventail de types de données.