
Comment stocker des données structurées dans une base de données NoSQL
Publié: 2022-11-17Les bases de données NoSQL sont souvent utilisées pour stocker des données non structurées , mais elles peuvent également être utilisées pour stocker des données structurées. Il existe plusieurs façons de stocker des données structurées dans une base de données NoSQL, et la méthode la plus appropriée dépendra des données spécifiques et du résultat souhaité. Une façon de stocker des données structurées dans une base de données NoSQL consiste à utiliser une approche orientée document. Cela signifie que les données sont stockées dans des documents, qui sont ensuite organisés en collections. Une autre façon de stocker des données structurées dans une base de données NoSQL consiste à utiliser une approche clé-valeur. Cela signifie que les données sont stockées dans un magasin clé-valeur, où chaque clé correspond à une valeur. Enfin, une approche orientée graphe peut également être utilisée pour stocker des données structurées dans une base de données NoSQL. Cela signifie que les données sont stockées dans un graphe, où les nœuds représentent les données et les arêtes représentent les relations entre les données.
Le terme « données non structurées » a un large éventail de connotations et est susceptible de signifier quelque chose de différent pour différentes personnes. RDBMS, comme il s'attend à ce que vous définissiez tout, s'attend à ce que vous le fassiez d'une manière initiale (en particulier, il serait difficile de gérer des données avec un nom et un type de colonne (comme celui-ci). Lors de la dernière visite d'un utilisateur un pays spécifique, vous aimeriez connaître la fréquence à laquelle ils l'ont visité. Dans une base de données No SQL, il est possible de modéliser la table de telle sorte que le nom de la cellule corresponde au nom de la table. BLOB peut être stocké en toute sécurité dans n'importe quel SGBDR, y compris la base de données Oracle et d'autres bases de données relationnelles . La valeur de la clé ne peut pas être spécifiée dans les cas de CLOB et BLOB. Parce qu'ils sont semi-structurés (JSON, XML, tous les champs ne sont pas connus), ils sont distingués par leur nature non structurée.
Les bases de données NoSQL sont fréquemment utilisées pour gérer des données semi-structurées. Les appareils IIoT génèrent des données structurées, non structurées et semi-structurées en temps réel. Il est simple de gérer et de traiter des données structurées lorsque la structure est définie par le vendeur.
Hadoop peut aider une entreprise à se structurer et à donner un sens aux modèles et aux tendances cachés dans de vastes quantités de données générées à partir de diverses sources, en particulier à l'ère des quantités massives de données. Il est évident que les capacités supérieures de Hadoop pour les données non structurées ne peuvent être surestimées, mais elles peuvent également être utilisées pour résoudre des problèmes complexes de données structurées.
Pour les entreprises qui traitent et analysent de grandes quantités de données variées et non structurées, telles que le Big Data, NoSQL est une meilleure option. Les bases de données NoSQL n'ont pas les mêmes contraintes que les bases de données relationnelles sur les données pouvant être stockées.
Mongodb peut-il stocker des données structurées ?

Oui, MongoDB peut stocker des données structurées. Pour ce faire, il utilise BSON (Binary JSON) pour stocker les données dans un format binaire. BSON est un sur-ensemble de JSON, et donc tout document JSON peut être stocké dans une base de données MongoDB .
MongoDB, par exemple, a gagné en popularité ces dernières années en raison de divers facteurs. Une application à grande échelle, dans laquelle les données ne peuvent pas être structurées et doivent être stockées de manière flexible, est bien adaptée au stockage en nuage. Étant donné que MongoDB est classé comme une base de données non structurée, il utilise une approche différente du stockage des données . Étant donné que JSON est un type de données qui peut être formaté de différentes manières, les fichiers texte et autres actifs non structurés sont conservés dans ce format. MongoDB est bien adapté pour gérer de gros volumes de données car il est conçu à cet effet. MongoDB peut facilement gérer de gros volumes de données car il est physiquement impossible de les gérer.
Quel type de données nosql stocke-t-il ?
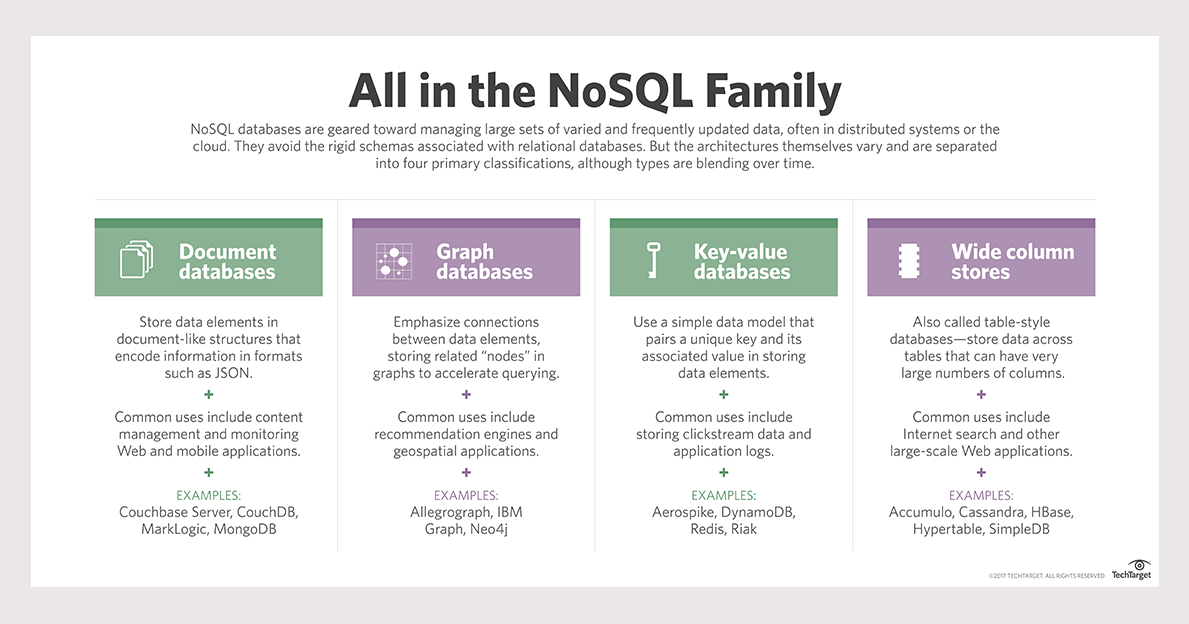
Les bases de données NoSQL sont utilisées pour stocker des données non structurées, ce qui signifie qu'elles ne s'intègrent pas parfaitement dans un format de table traditionnel. Cela peut inclure des éléments tels que des publications sur les réseaux sociaux, des commentaires, des images ou tout autre élément qui ne rentre pas dans une structure de base de données traditionnelle . Étant donné que les bases de données NoSQL sont plus flexibles, elles peuvent être un bon choix pour les applications qui nécessitent un accès rapide et facile à de grandes quantités de données.
Le terme "base de données non relationnelle" fait référence à une base de données qui n'a pas de structure fixe. Le magasin clé-valeur, les bases de données orientées colonnes, basées sur des documents, graphiques et graphiques sont les types de bases de données les plus courants. Dans le monde NoSQL, les bases de données clé-valeur font partie des types de bases de données les plus simples à utiliser. Les données sont stockées, rassemblées et supprimées à l'aide d'un simple ensemble de fonctions. Une base de données de magasin clé-valeur n'a pas de langage de requête pouvant être utilisé. Les types de données sont déterminés par les exigences des applications qui les traitent. Le cas d'utilisation le plus courant des bases de données clé-valeur consiste à enregistrer des sessions dans des applications qui nécessitent une connexion.
En plus du cas d'utilisation plus général, un panier d'achat permet aux sites Web de commerce électronique de stocker des données sur la session d'achat de chaque utilisateur. Lorsque les soldes de vacances et les promotions spéciales sont en cours, l'évolutivité des magasins de valeur-clé est utile. De plus, le système a une redondance intégrée afin qu'aucun article d'un panier ne soit jamais perdu. Les bases de données clé-valeur ont un objectif spécifique et incluent des fonctionnalités qui ajoutent de la valeur à certaines tout en imposant des limites à d'autres.
Le langage de programmation MongoDB est non seulement populaire, mais il est également extrêmement flexible. Par conséquent, vous pouvez augmenter le nombre de serveurs pour gérer la charge supplémentaire. En plus de cela, la fonctionnalité de réplication de MongoDB garantit que les données sont toujours à jour et à plusieurs endroits. Par conséquent, MongoDB est une option très attrayante pour les grandes organisations qui souhaitent conserver des données à la fois fiables et cohérentes.
Nosql est-il des données non structurées ou des données semi-structurées ?
Les bases de données non relationnelles sont utilisées pour stocker des données structurées et non structurées en NoSQL (plutôt que de simples langages de requête structurés). En raison de sa grande évolutivité et de sa facilité de recherche, NoSQL est idéal pour les données non structurées.

Les données peuvent être stockées dans une variété de formats, tels que des feuilles de calcul, du texte et de la vidéo, ou même des fichiers audio. Il s'agit d'un type de données qui est stocké dans le stockage et qui devrait avoir une structure prédéfinie avant d'être stocké. Un ensemble de données non structuré est un ensemble qui ne peut pas être stocké dans une base de données relationnelle car il manque un modèle de données prédéfini. Les données non structurées sont un terme qui fait référence à des données non structurées qui sont non structurées mais qui contiennent une certaine forme de métadonnées qui peuvent être utilisées pour trouver la structure des données ou la hiérarchie des données. Les ingénieurs et scientifiques en Machine Learning et en Intelligence Artificielle analysent ce type de données à l'aide de techniques telles que le Machine Learning et l'IA pour en extraire du sens (voire une structure de haut niveau). Il comprend des e-mails et d'autres documents dans un format similaire mais contient des métadonnées qui permettent aux utilisateurs d'accéder à des informations spécifiques à un niveau spécifique, quel que soit le format. Nous avons couvert quelques exemples concrets de chacun des différents types de données dans cet article, et nous avons également examiné comment elles sont utilisées dans les organisations modernes.
Les données structurées sont généralement stockées dans des bases de données (qui sont ensuite utilisées pour l'entreposage de données). Les données non structurées sont stockées dans des bases de données non relationnelles ou des lacs de données car il n'y a pas de schéma prédéfini qui doit être suivi pour que les données soient classées. Pour les données semi-structurées et hiérarchisées, MongoDB est une bonne option.
Les systèmes de base de données NoSQL ont gagné en popularité en raison de leur évolutivité et de leur flexibilité. Cette méthode de stockage des données est idéale pour les données non structurées et semi-structurées, en plus des données semi-structurées et non structurées. Parce qu'il est plus facile de travailler avec des données de manière plus agile, elles sont idéales pour le développement itératif.
Stockage de données non structurées
Un système de stockage de données non structurées est un système de fichiers qui n'impose aucune structure aux données qu'il stocke. Les données sont simplement stockées dans un fichier plat, sans structure imposée par le système de fichiers. Ce type de système de stockage est généralement utilisé pour stocker du texte ou des données binaires, telles que des images, qui n'ont pas besoin d'être organisées de manière particulière.
Cette catégorie comprend environ 80 % des données non structurées. Le volume, la variété et la vitesse des données non structurées rendent leur stockage difficile. Les systèmes de stockage traditionnellement conçus pour gérer de grandes quantités de données non structurées pourraient ne plus être en mesure de le faire à l'avenir. Par conséquent, votre infrastructure de stockage de données doit être capable de gérer un grand nombre de transactions et d'évoluer. Lors du développement d'un projet Big Data, il est essentiel que les entreprises planifient à l'avance le stockage des données non structurées. Il est essentiel de sélectionner une infrastructure de stockage agile, rentable, évolutive et adaptée à un large éventail de cas d'utilisation. Une base de données Nosql (Norelational) est un excellent moyen de stocker ces informations.
MongoDB Atlas ou d'autres bases de données cloud , telles que MongoDB as a Service (DaaS), sont d'excellentes options. Une base de données MongoDB stocke les données dans un format BSON (de type json) basé sur des documents. Les attributs d'un document varient en fonction de son type de données. Étant donné que les données sont sauvegardées et peuvent être répliquées, les magasins de documents sont hautement évolutifs et disponibles pour la conception. La plate-forme de base de données en tant que service MongoDB Atlas utilise les principales plates-formes cloud telles qu'AWS, Azure et Google Cloud pour stocker les bases de données. Avant de pouvoir accéder à un entrepôt de données, une étape d'extraction, de transformation et de chargement (ETL) doit être effectuée sur des données non structurées. Les entrepôts de données traitent et stockent des données provenant de diverses sources pour s'assurer qu'elles sont prêtes pour l'analyse. Les lacs de données stockent toutes les données dans leur format natif, qui est un mélange de données brutes et traitées.
En raison de sa simplicité, de sa légèreté et de sa facilité de traitement, JSON est idéal pour stocker des données non structurées. Il peut être facilement converti en une variété de formats, y compris HDFS, Cassandra et MongoDB, qui sont tous pris en charge par cette application. Du fait de l'absence de besoin de joindre les données, notre solution était simple à mettre en œuvre. En utilisant la fonction json_archive, nous pourrions créer des fichiers séparés pour chaque objet JSON. Une base de données relationnelle peut stocker des données non structurées de différentes manières. Pour commencer, les bases de données relationnelles sont le moyen le plus efficace de stocker et d'interroger de grandes quantités de données non structurées. Ils permettent une compression très efficace de grandes quantités de données et, dans de nombreux cas, des langages de requête, une sémantique et d'autres mécanismes qui servent des types de données spécifiques sont inclus. Deuxièmement, la structure de la base de données relationnelle facilite l'interrogation des données. Chaque enregistrement est stocké en tant qu'objet JSON unique dans une base de données relationnelle, et toutes ses données sont stockées en un seul. Que vous recherchiez un enregistrement spécifique ou un ensemble complet d'enregistrements, vous serez en mesure de trouver les informations dont vous avez besoin. Le troisième avantage d'une base de données relationnelle est qu'elle est capable de gérer de grandes quantités de données. En plus de pouvoir stocker des dizaines de millions d'enregistrements, ils sont capables de gérer des requêtes complexes.
Données non structurées : quoi, où et comment les stocker
Bien que les données non structurées puissent être stockées dans n'importe quel format, elles sont généralement stockées dans un format texte ou non texte. Les données non structurées, en général, nécessitent une plus grande capacité de stockage car elles ne rentrent pas dans une structure prédéfinie. Le stockage dans le cloud offre la sécurité et la possibilité d'accéder aux données depuis n'importe quel emplacement, ce qui en fait une excellente option pour les données non structurées. L'utilisation du stockage de fichiers est un bon moyen de stocker de grandes quantités de données afin de les organiser. Ce logiciel est basé sur le stockage basé sur le chemin, ce qui signifie que les dossiers et répertoires sont utilisés pour stocker les données. Il est essentiel de savoir où les données résident dans un système de stockage de fichiers si elles doivent être trouvées.