
InfluxDB : une base de données de séries chronologiques
Publié: 2022-11-18InfluxDB est une base de données de séries chronologiques écrite en Go et développée par InfluxData. Il est conçu pour être évolutif, en mettant l'accent sur des performances d'écriture élevées et une interrogation rapide. Il est également open source, avec une version communautaire et une version entreprise. InfluxDB est souvent utilisé en conjonction avec Grafana, un outil de visualisation de données open source. InfluxDB est un choix populaire pour les données de séries chronologiques, en raison de ses performances d'écriture élevées et de ses requêtes rapides. Il est également open source, ce qui le rend attractif pour de nombreux développeurs.
Afin d'effectuer une comparaison, nous avons utilisé de vrais avis d'utilisateurs PeerSpot pour comparer InfluxDB à Oracle NoSQL . Dans cet article, nous comparerons les fonctionnalités, la tarification, le service et l'assistance, la facilité de déploiement et le retour sur investissement des bases de données NoSQL pour déterminer celle qui convient le mieux à votre entreprise. Depuis 2012, nos recherches ont été utilisées par 648 701 professionnels. InfluxDB, qui est une offre basée sur le cloud, possède la meilleure fonctionnalité, à savoir sa base de données chronologique, ses requêtes rapides en masse et ses opérations de fenêtre. Il y a quelques problèmes avec l'API en bloc pour InfluxDB, qui est incompatible avec les données à haute cardinalité. Utilisez notre moteur de recommandation gratuit pour déterminer quelle base de données NoSQL répondra le mieux à vos besoins. InluxDB est un logiciel open source gratuit qui permet aux développeurs et aux entreprises de gérer des données de séries chronologiques.
InfluxDB vous permet de surveiller et d'analyser l'Internet des objets (IoT), les applications, les systèmes, les conteneurs et l'infrastructure. Un examinateur a cité l'agrégation de données et l'intégration avec Grafana comme les caractéristiques les plus importantes. La base de données Oracle NoSQL est destinée à être un système de base de données très volumineux et hautement disponible. Des opérations complètes de création, lecture, mise à jour et suppression (CRUD), ainsi qu'une variété de garanties de durabilité et de cohérence, sont disponibles. Avec quatre avis, InfluxDB se classe au cinquième rang sur le marché des bases de données NoSQL, derrière Oracle No SQL, qui se classe septième avec un. En tant que base de données la plus recommandée, elle possède une interface très simple et est légère et puissante.
InfluxDB n'est pas une base de données relationnelle car elle n'inclut aucune clé primaire ou étrangère, aucune jointure de mesures, etc. les balises comme solution : les balises sont utilisées comme solution de contournement en théorie, mais elles ne conviennent que pour les données à faible cardinalité. Vous aurez besoin d'une grande quantité de mémoire si vous avez de nombreux enregistrements avec une étiquette d'identification unique.
La base de données influxDB est similaire à une base de données SQL, mais il existe plusieurs différences. Cette base de données est spécialement conçue pour gérer les données de séries chronologiques. Bien que les bases de données relationnelles puissent gérer des données de séries chronologiques, elles ne sont pas optimisées pour les charges de travail de séries chronologiques courantes.
InfluxDB Cloud est une plate-forme de données de séries chronologiques élastique entièrement gérée qui permet aux utilisateurs de démarrer rapidement et d'évoluer rapidement pour répondre à leurs besoins.
Une base de données de séries chronologiques (TSDB) créée par InfluxData est une base de données open source. Les données de séries chronologiques, telles que les opérations, les métriques d'application, les données de capteurs de l'Internet des objets et les analyses en temps réel, peuvent être stockées et récupérées à l'aide de cette bibliothèque dans Go.
Graphql est-il un Sql ou un Nosql ?
Dans GraphQL, nous utilisons un système de type pour renvoyer efficacement les données dans les requêtes dynamiques, qui sont un langage de requête basé sur le type. SQL (langage de requête structuré) est une norme plus ancienne et plus largement utilisée pour la conception, la mise en œuvre et la gestion des structures de données dans les bases de données tabulaires et hiérarchiques. Si vous souhaitez utiliser une base de données NoSQL pour votre API, optez pour GraphQL.
Les bases de données Type Mismatch et GraphQL ont été créées par Cochrane et Herman Camarena. Un système de type peut être introduit en utilisant GraphQL plutôt qu'un système NoSQL car nous pouvons toujours profiter des avantages de NoSQL. La structure des documents dans une collection GraphQL varie légèrement d'un document à l'autre, à quelques exceptions près. Grâce aux API GraphQL, un développeur peut choisir les types de données qu'il souhaite qui correspondent approximativement aux types de backends. Pour réaliser le plein potentiel de GraphQL, le problème des incompatibilités de type doit être résolu. En tant que langage, il présente de nombreux avantages, ce qui rend le problème d'inadéquation moins grave. En utilisant des outils tels que JSON2SDL de StepZen, vous pourrez encore plus automatiser le travail.
Graphql est indépendant des sources de données
Il n'est indépendant d'aucune source de données pour laquelle des modifications sont stockées ou récupérées. Les données peuvent être consultées et manipulées à l'aide de fonctions arbitraires appelées résolveurs.
Influx Sql ou Nosql est-il?
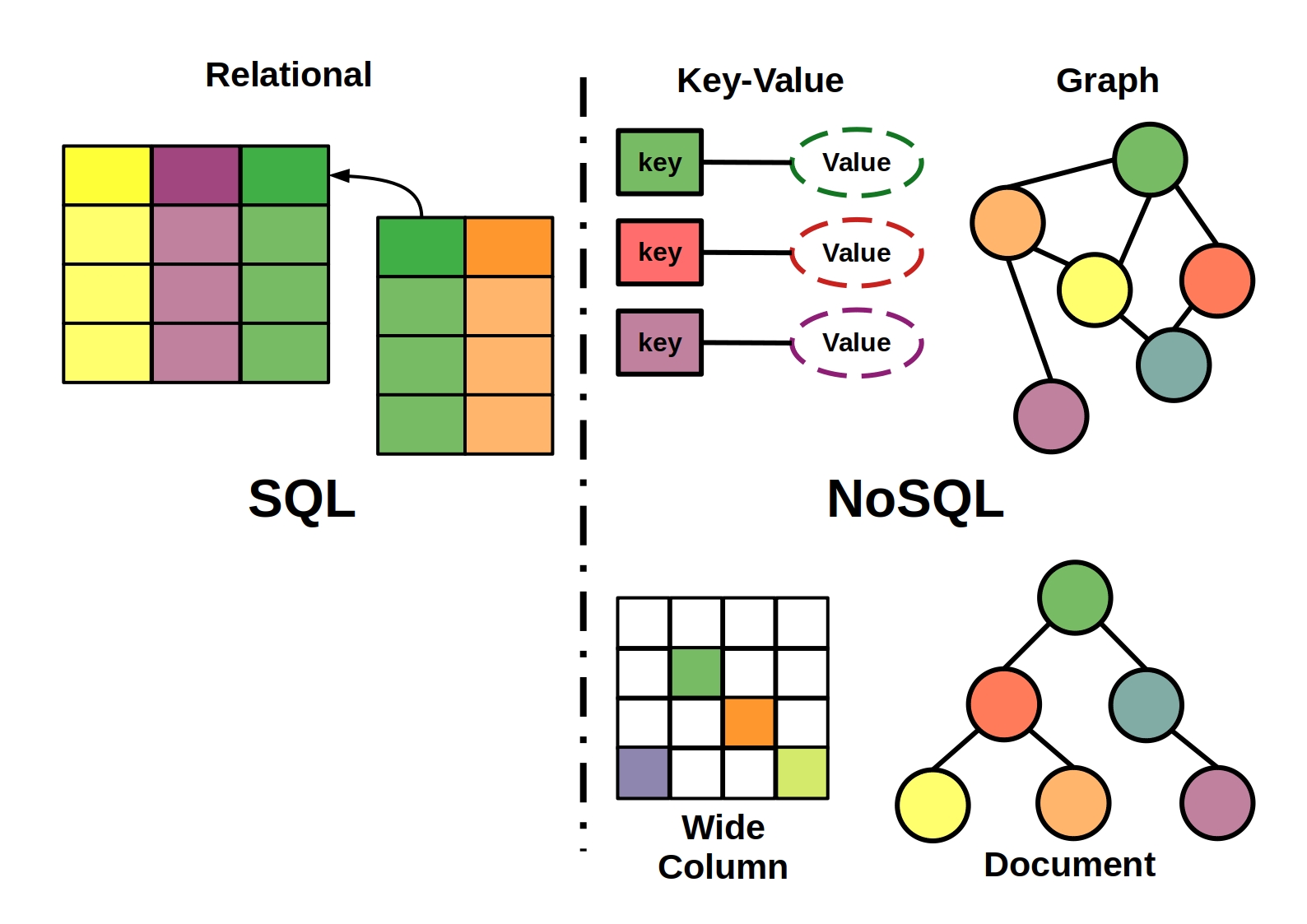
InfluxDB est une base de données relationnelle développée par InfluxData. est une base de données open source gratuite qui combine big data , NoSQL et évolutivité. Il a une haute disponibilité, une vitesse d'écriture élevée et est disponible sur demande. InfluxDB, une base de données NoSQL, stocke un ensemble de points de données au fil du temps en fonction d'une série de points de données chronologiques.
Son but est d'être utilisé pour les données de séries chronologiques. Chaque série de données a un horodatage qui identifie un point unique en son sein. Dans une table de base de données, la clé primaire est toujours définie par le système dans ce cas, tout comme dans les bases de données SQL. Dans la plupart des cas, l'ajout d'un nouveau champ à une mesure peut se faire simplement en écrivant un point pour celui-ci. Des descriptions plus détaillées des termes influxDB mentionnés dans cette section sont disponibles dans notre glossaire des termes. Lorsque vous utilisez InfluxDB 1.8 avec Flux, vous pouvez acquérir une compréhension de base de sa syntaxe et de ses concepts. InfluxQL, un langage de requête de type SQL, est utilisé pour interagir avec influxDB.
L'environnement SQL a été conçu pour que ceux qui viennent d'autres environnements soient à l'aise avec. Le programme ne prend pas en charge les opérations avancées telles que UNION, JOIN ou HAVING. L'horodatage actuel du serveur peut être utilisé avec l'heure relative et now() pour calculer l'heure relative. Cette requête génère une liste de données foodships. Une base de données CR-ud n'est pas une base de données CRUD complète, mais plutôt une base de données qui ressemble plus à afluxDB. Il est conçu pour donner la priorité à la génération et à la lecture des données plutôt qu'à la mise à jour et à la destruction des données.
InfluxDB et MySQL sont deux des bases de données de séries chronologiques les plus utilisées. Les deux outils open source sont simples à utiliser et peuvent être personnalisés. InfluxDB est un excellent choix pour l'analyse de données de séries chronologiques car il est plus simple que tout autre. InfluxDB offre un certain nombre d'avantages par rapport à MySQL. MySQL est plus économe en mémoire et plus rapide à développer qu'InfluxDB. La deuxième raison pour laquelle InfluxDB est un meilleur outil que MySQL est qu'il est plus stable. De plus, InfluxDB offre une meilleure prise en charge de l'analyse des séries chronologiques que MySQL. Pour l'analyse de séries chronologiques, InfluxDB est un bon choix car il est simple à utiliser, économe en mémoire et fiable. Un certain nombre d'entreprises, dont Cisco, Power Home Remodeling, AT&T et Windstream Communications, utilisent déjà InfluxDB.
Les avantages et les inconvénients des bases de données Nosql et SQL
Les bases de données SQL offrent un meilleur traitement des transactions multilignes que les bases de données NoSQL pour les données non structurées telles que les documents et JSON. Les bases de données SQL sont également utilisées dans les systèmes hérités qui ont été écrits dans un format relationnel. Les données d'InfluxDB sont stockées dans un groupe de fragments. Les données sont stockées dans un groupe de partitions et stockées avec des horodatages qui sont définis dans l'historique comme la durée de la partition et sont organisés par politique de rétention (RP). De plus, en fonction du RP, la durée du groupe de fragments peut être ajustée. Vous pouvez modifier la durée du groupe de partitions en accédant à Gestion de la stratégie de rétention. InfluxDB présente de nombreuses différences en termes de structure et de fonctionnement par rapport aux bases de données SQL. Le but d'InfluxDB est de stocker des données historiques. Les données de séries chronologiques peuvent être stockées dans des bases de données relationnelles, mais ces bases de données ne sont pas optimisées pour les charges de travail de séries chronologiques de routine. Le client InfluxDBQL permet les requêtes SQL des données de la base de données.

Quel type de base de données est Influxdb ?
InfluxDB est une base de données de séries chronologiques open source sans dépendances externes. Il est utile pour surveiller les métriques, les événements et analyser les analyses.
La base de données open source InflluxDB est écrite dans un format de série chronologique et est maintenue par InfluxData. Cette plate-forme, conçue pour stocker et récupérer des données de séries chronologiques, est utilisée pour surveiller et enregistrer des mesures et des analyses de performance. L'architecture de base de données d'InfluxDB se compose de deux bases de données : un index de séries chronologiques (TSI) pour les données de séries et un index inversé pour les métadonnées de mesure, de balises et de champs. InfluxDB, une base de données open source, stocke les données dans un format en colonnes. De plus, les colonnes du stockage de données peuvent prendre en charge les requêtes de séries chronologiques courantes telles que les analyses dans le temps. L'arbre de fusion structuré dans le temps (TSM) est la structure organisationnelle utilisée par InfluxDB. Un FileStore est également utilisé pour gérer l'accès aux fichiers de tous les fichiers TSM sur un ordinateur.
InfluxDB est une solution de stockage de données puissante, rapide et économique qui peut être utilisée pour l'analyse et la surveillance de séries chronologiques. Il utilise la livraison de données en colonnes dans laquelle toutes les données sont livrées en même temps, éliminant ainsi le besoin de lire des lignes entières afin d'extraire des valeurs de données spécifiques. Par conséquent, InfluxDB est un outil utile pour les données souvent volumineuses et denses, telles que les données de capteur et de système. InfluxDB, comme la plupart des bases de données, offre un débit élevé en lecture et en écriture ainsi qu'une fonctionnalité en colonnes grâce à son utilisation du partitionnement et de l'indexation. Il s'agit d'une fonctionnalité utile car les données des capteurs ou des journaux système, qui doivent être conservées et récupérées régulièrement, peuvent être stockées et récupérées. InfluxDB est une solution de stockage de données puissante et flexible qui convient parfaitement à l'analyse et à la surveillance des séries chronologiques. Le format comprend un tableau en colonnes qui fournit les données une colonne à la fois, des débits de lecture et d'écriture deux fois plus rapides et des capacités d'indexation qui permettent une recherche et une mise à l'échelle plus rapides. InfluxDB est un excellent choix pour un large éventail d'exigences de stockage, y compris les données de séries chronologiques volumineuses ainsi que celles nécessitant une solution de stockage de données rapide et efficace.
Influxdb contre Mongodb
Les résultats d'InfluxDB ont démontré qu'il était de loin supérieur à MongoDB en ce qui concerne l'ingestion de données et les performances de stockage sur disque. En termes d'ingestion de données, InfluxDB surpasse MongoDB par un facteur de quatre. InfluxDB, contrairement à MongoDB, offrait 20 fois la compression.
Après avoir passé plus de 4 ans à utiliser couchbase, nous sommes passés à MongoDB, et nous ne pouvions pas être plus heureux. Nous avons reçu une assistance d'entreprise, mais l'expérience a été terrible, malgré le fait que nous ayons été répertoriés comme partenaire Couchbase. Pour le faire fonctionner correctement, vous aurez besoin d'au moins six serveurs à leurs exigences minimales. Six serveurs seront nécessaires en production. Une instance Memcached plus petite est livrée avec l'instance Couchbase afin de gérer le cache en mémoire. Ce programme dispose de 8 Go de RAM et peut prendre en charge 5000 documents. Je ne suis pas facétieux ici. Sur une instance Couchbase, il y avait moins de 5 000 documents, moins de 20 index et plus de 8 Go de RAM.
La base de données InfluxDB est un très bon choix pour les données de séries chronologiques. En conséquence, c'est un excellent choix pour stocker des données sensibles car il permet au développeur un contrôle total sur la sécurité de ses données. De plus, le support communautaire d'InfluxDB est excellent, ce qui facilite le contact avec l'organisation si nécessaire.
Pourquoi Orientdb est la meilleure base de données de graphes
OrientDB, contrairement à MongoDB, offre un certain nombre d'avantages.
Parce qu'OrientDB est sans schéma, vous pouvez facilement modéliser votre modèle de données.
Parce qu'OrientDB est conforme à ACID, vos données seront cohérentes et durables.
Les performances d'OrientDB sont supérieures à MongoDB, ce qui en fait un excellent choix pour stocker des données de séries chronologiques.
OrientDB pourrait être la meilleure option pour vous si vous recherchez une base de données de graphes. Lorsque vous maîtriserez le True Graph Engine, vous n'aurez plus besoin de gérer d'autres types de données ni d'implémenter d'autres systèmes.
Influxdb Avantages
Il existe de nombreuses raisons d'aimer InfluxDB. En voici quelques-unes : – Tout d'abord, InfluxDB est incroyablement facile à installer et à faire fonctionner. En fait, vous pouvez avoir une instance opérationnelle en quelques minutes avec très peu de configuration. – Deuxièmement, InfluxDB a d'excellentes performances en écriture. Il peut facilement gérer des millions de points de données par seconde sans transpirer. – Troisièmement, InfluxDB dispose d'un modèle de données très flexible qui peut être facilement personnalisé pour répondre à vos besoins. – Quatrièmement, InfluxDB dispose d'un langage de requête riche qui prend en charge de nombreux types de requêtes différents. – Cinquièmement, InfluxDB s'intègre bien avec de nombreux types de sources de données et d'applications. Dans l'ensemble, InfluxDB est un excellent choix pour les données de séries chronologiques. Il est facile à utiliser, a d'excellentes performances et est très flexible.
InfluxDB est une base de données de séries chronologiques. Pour optimiser les performances de ce cas d'utilisation, il est essentiel de faire des compromis, principalement en termes de fonctionnalités. Les données avec des horodatages très récents constituent la grande majorité des écritures et sont ajoutées par ordre croissant. Les données en question sont rarement mises à jour et les mises à jour litigieuses sont rares. Il était difficile pour les concepteurs d'augmenter les performances en traitant des données éphémères et non consécutives. Une base de données avec un grand nombre de lectures et d'écritures doit être suffisamment grande pour le gérer.
La base de données de séries chronologiques la plus puissante est un service qui combine InfluxDB Cloud et une base de données de séries chronologiques. Cet outil gratuit est simple à utiliser, rapide, sans serveur et élastique, et il prend en charge des outils populaires tels que Docker et Prometheus. En raison de la popularité de l'open source InfluxDB, la société est devenue l'une des entreprises les plus prospères du secteur. L'année a vu une expansion spectaculaire de la portée d'InfluxData, avec plus de 450 000 instances actives d'InfluxDB fonctionnant dans le monde entier. Les data scientists et les ingénieurs qui ont besoin d'une puissante base de données de séries chronologiques, à la fois simple et rapide à déployer, sont des candidats idéaux pour InfluxDB Cloud.