
Spark est-il pour Nosql
Publié: 2023-02-05Spark est un outil puissant pour travailler avec des données, en particulier des ensembles de données volumineux. Il est conçu pour être rapide et efficace et prend en charge une variété de formats de données, y compris les bases de données NoSQL . Les bases de données NoSQL sont de plus en plus populaires, car elles sont bien adaptées au traitement de grandes quantités de données. Spark peut vous aider à interroger et à manipuler efficacement les données NoSQL.
Pour travailler efficacement, il est essentiel de gérer les bases de données de votre application à l'aide d'Apache Spark et de NoSQL ( Apache Cassandra et MongoDB). L'objectif de ce blog est de fournir des conseils pour développer des applications Apache Spark à l'aide de backends NoSQL. C'est un parc à thème et TCP/IP sPark propose des manèges à CassandraLand et MongoLand. Lorsque nous avons tenté d'interroger les données du DOE, notre application Spark a commencé à sortir de son axe. La leçon ici est que lorsque vous interrogez Cassandra, les séquences de touches sont importantes. CassandraLand propose également les montagnes russes Partitioner, qui sont l'une de ses attractions les plus populaires. Pendant que les clients apprécient leur tour de montagnes russes, les opérateurs de manège peuvent suivre qui l'a monté chaque jour en conservant leurs informations.
Dans la première leçon, nous verrons comment gérer les connexions MongoDB. Lorsque vous avez besoin de mettre à jour des informations sur un parc, telles que le nouveau statut d'adhésion au parc du ministère de l'Énergie, vous pouvez utiliser les index mongo . MongoDB et Spark doivent être utilisés pour s'assurer que votre connexion est correctement gérée, ainsi que des index dans des cas spécifiques.
Apache Spark est un système de traitement distribué populaire qui est open source et conçu pour être utilisé dans des charges de travail de données volumineuses. Cette fonctionnalité, en plus de la mise en cache en mémoire et de l'exécution optimisée des requêtes, permet des requêtes analytiques rapides sur de grandes quantités de données.
Avec presque le même code, il est plus efficace et polyvalent, ce qui lui permet de traiter simultanément des données par lots et en temps réel. En conséquence, les anciens outils Big Data deviennent de plus en plus obsolètes en raison de l'absence de cette fonctionnalité.
Quel type de base de données est Spark ?
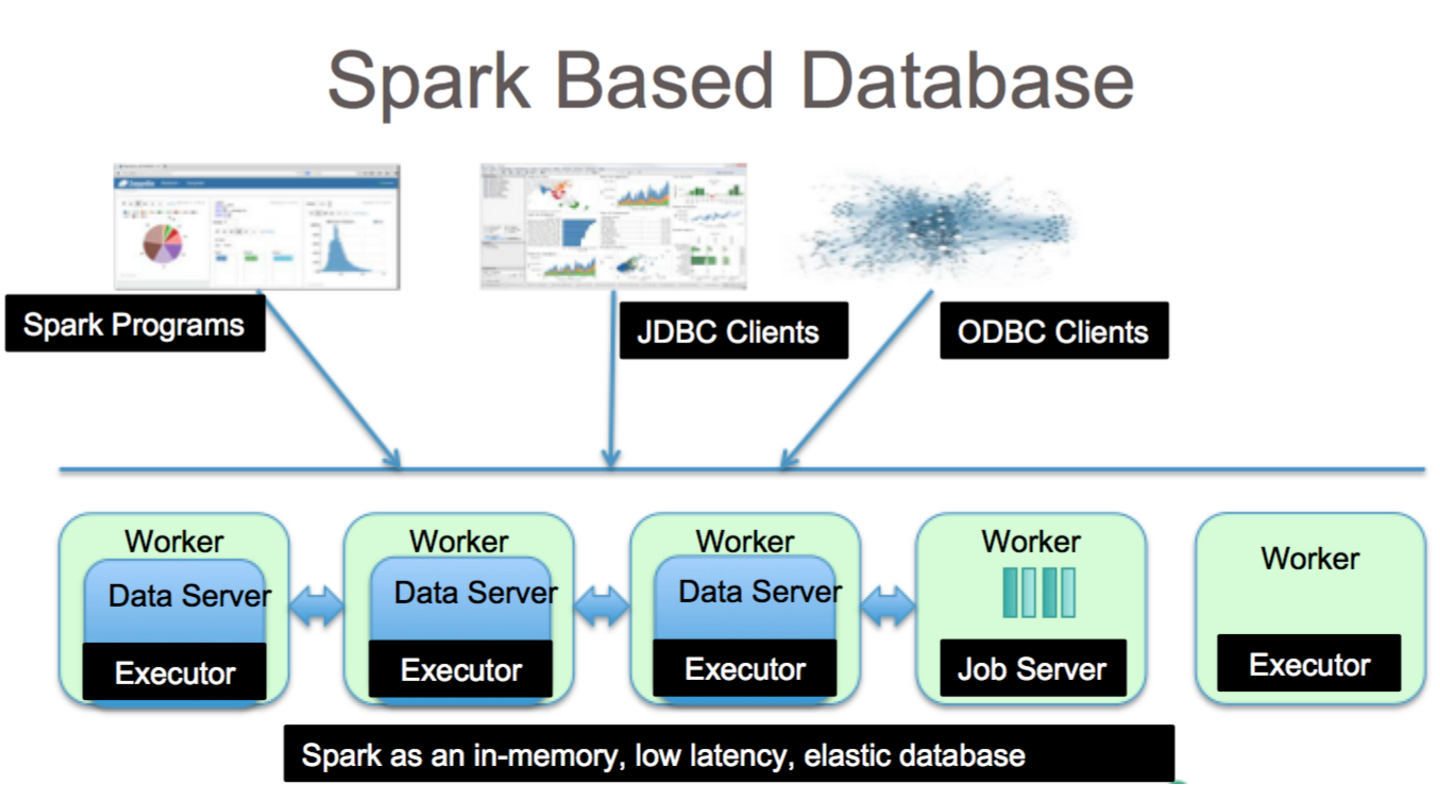
Apache Spark est une infrastructure de traitement de données qui peut gérer des données provenant de divers référentiels de données, notamment (HDFS), des bases de données NoSQL et des bases de données relationnelles.
Bien qu'il y ait eu de nombreux cycles de battage médiatique pour les bases de données relationnelles, elles continueront d'être populaires, quelles que soient les dernières avancées et l'essor des bases de données NoSQL. Au fil du temps, il est devenu de plus en plus difficile de stocker des données dans des bases de données relationnelles. Dans cet article, nous examinerons certaines des avancées significatives dans l'exploitation de la puissance de la base de données relationnelle à l'échelle mondiale. Lors de sa première sortie, l'interface entre Spark et Big Data Analysis était minimale. De nombreuses personnes ont écrit beaucoup de code pour exécuter ce programme, qui était puissant mais relativement lent. Les utilisateurs pourront facilement combiner ces deux modèles dans la base de données Spark SQL . Il accepte également un large éventail de formats de données provenant de diverses sources.
Le projet open source Apache Spark est le plus actif, avec des centaines de contributeurs qui y contribuent. En plus d'être un projet open source gratuit, Spark SQL a commencé à gagner en popularité dans les industries grand public. En plus de Spark SQL, environ les deux tiers des clients Databricks Cloud (le service hébergé exécutant Spark) utilisent d'autres langages de programmation. Après la conclusion de notre première étude de cas, nous montrerons comment appliquer les databricks au cas dans cette étude de cas pratique. Un Spark DataFrame est un ensemble de lignes (types de lignes) qui sont distribuées avec le même schéma. Chaque colonne de l'ensemble de données est étiquetée avec un nom. L'API de DataFrame permet aux développeurs d'intégrer du code procédural et relationnel.

Spark peut également gérer des fonctions avancées telles que les UDF. Une table dans une base de données relationnelle est analogue à un dataframe dans une base de données dataframe, mais il y a plus d'optimisations impliquées. Ils peuvent être manipulés de la même manière que les collections distribuées natives (RDD) de Spark. En général, la requête Spark SQL est plus rapide que la requête Shark et est plus compétitive avec Impulsa. Dans la requête 3a, où la sélectivité des requêtes rend l'une des tables très petite, il existe une différence significative entre Impala et Impala.
C'est un outil fantastique pour l'analyse de données avec Spark SQL. La syntaxe HiveQL, Hive SerDes et HiveDFs sont accessibles via la syntaxe HiveQL, ainsi que Hive SerDes et HiveDFs. Les metastores Hive , les SerDes et les UDF ont déjà été implémentés. Bien que Spark soit une base de données, c'est aussi une base de données NoSQL. Par conséquent, lorsque vous créez une table gérée dans Spark, vous pourrez utiliser divers outils compatibles SQL pour stocker vos données. Les expressions SQL peuvent être utilisées pour accéder aux tables dans Spark en se connectant à JDBC via des connecteurs de jdbc.org. Par conséquent, vous pouvez également utiliser des outils tiers tels que Tableau, Talend et Power BI. La possibilité d'utiliser Spark est idéale pour l'analyse des données, et c'est un outil utile pour un large éventail d'industries.
Spark Sql : le meilleur des deux mondes
Il comble le fossé entre les deux modèles mentionnés précédemment, les modèles procéduraux et relationnels, en incluant deux composants principaux. Par conséquent, vous pouvez exécuter des opérations relationnelles à grande échelle sur des sources de données externes et les collections distribuées intégrées de Spark à l'aide d'une API DataFrame.
Qu'est-ce que l'étincelle dans la base de données ? Il s'agit d'un framework open source qui utilise l'apprentissage automatique, le traitement interactif des requêtes et les charges de travail en temps réel. Cette société ne dispose pas de son propre système de stockage ; il utilise plutôt des analyses sur d'autres systèmes de stockage tels que HDFS, Amazon Redshift, Amazon S3, Couchbase et autres, en plus du sien. En matière de traitement de données structurées, Spark SQL n'est pas qu'une base de données ; c'est aussi un module. La grande majorité est écrite sur des DataFrames, qui sont les abstractions de programmation qui fonctionnent conjointement avec les requêtes SQL.
Quel est le type de SQL sql pour "sparksql" ? Hive SQL prend en charge la syntaxe HiveQL, ainsi que Hive SerDes et UDF, vous permettant d'accéder aux entrepôts Hive qui ont été créés précédemment. L'utilisation de métastores Hive, SerDes et UDF existants dans Spark SQL n'est pas difficile.
Mongodb peut-il exécuter Spark ?
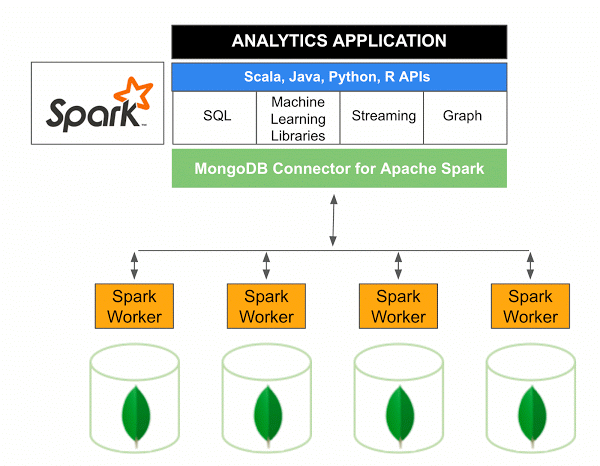
La version 10.0 du connecteur MongoDB pour Apache Spark inclut la prise en charge de Spark Structured Streaming via la nouvelle API Spark Data Sources V2 ainsi que la mise en œuvre de la nouvelle API Spark Data Sources V2.
Le connecteur MongoDB pour Spark est un projet open source qui vous permet d'écrire des données à partir de MongoDB et de les lire à partir de MongoDB à l'aide de Scala. Grâce aux méthodes utilitaires des connecteurs, les interactions entre Spark et MongoDB sont simplifiées, ce qui en fait une combinaison puissante pour créer des applications analytiques sophistiquées. Grâce à ses fonctionnalités de réplication et de partitionnement intégrées, Spark peut être implémenté dans une variété de charges de travail qui utilisent des bases de données MongoDB .
Spark : le moyen rapide de créer des applications riches en données
Avec l'aide de Spark, un outil puissant, vous pouvez rapidement développer des applications plus fonctionnelles. En incorporant MongoDB, les développeurs peuvent accélérer le processus de développement en utilisant une technologie de base de données unique. De plus, Spark est natif du cloud et inclut la prise en charge des magasins de données NoSQL , ce qui le rend idéal pour les applications gourmandes en données.