
MapReduce : un modèle de programmation pour les grands ensembles de données
Publié: 2023-01-08MapReduce est un modèle de programmation et une implémentation associée pour le traitement et la génération de grands ensembles de données avec un algorithme distribué parallèle sur un cluster.
Nous transformons notre façon de travailler avec des quantités massives de données grâce aux nouvelles technologies. Les entrepôts de données, tels que Hadoop, NoSQL et Spark, font partie des acteurs les plus importants dans le domaine. Les administrateurs de base de données et les ingénieurs/développeurs d'infrastructure font partie de la nouvelle génération de professionnels qui se spécialisent dans la gestion de systèmes avec un haut niveau de sophistication. Au lieu d'une base de données, Hadoop est un écosystème logiciel qui permet le calcul parallèle sous la forme de fichiers volumineux. Cette technologie a fourni des avantages significatifs en termes de prise en charge des besoins de traitement massifs du Big Data. Pour une transaction de données importante, le cluster Hadoop moyen ne prend que trois minutes pour traiter une transaction importante qui prendrait généralement 20 heures dans un système de base de données relationnelle centralisé.
Un cluster mapreduce est un cluster avec un algorithme parallèle et un modèle de programmation qui traite et génère de grands ensembles de données de la même manière qu'un cluster normal.
L'écosystème Apache Hadoop est conçu pour prendre en charge l'informatique distribuée et fournit un environnement fiable, évolutif et prêt à l'emploi. Le module MapReduce de ce projet est un modèle de programmation utilisé pour traiter d'énormes ensembles de données qui résident sur Hadoop (un système de fichiers distribué).
Ce module est un composant de l'écosystème open source Apache Hadoop et est utilisé pour interroger et sélectionner des données dans le système de fichiers distribués Hadoop (HDFS). Les données peuvent être sélectionnées pour une variété de requêtes à l'aide d'un algorithme MapReduce qui est disponible pour effectuer de telles sélections.
En utilisant MapReduce, il est possible d'exécuter de grandes tâches de traitement de données. Vous pouvez créer des programmes MapReduce dans n'importe quel langage de programmation, y compris C, Ruby, Java, Python et autres. Ces programmes peuvent être utilisés simultanément pour exécuter des programmes MapReduce, ce qui les rend très utiles dans l'analyse de données à grande échelle.
À quoi sert Mapreduce dans Mongodb ?
Les cartes dans MongoDB sont un modèle de programmation de traitement de données qui permet aux utilisateurs d'effectuer de grands ensembles de données et de générer des résultats agrégés à partir de ceux-ci. MapReduce est la méthode utilisée par MongoDB pour réduire les cartes. Cette fonction est divisée en deux composants : une fonction de mappage et une fonction de réduction.
En utilisant l' outil MapReduce de MongoDB, il est possible d'organiser et d'agréger de grands ensembles de données. Cette commande, dans MongoDB, utilise les deux entrées principales de MongoDB : la fonction map et la fonction reduce, afin de traiter une grande quantité de données. Pour définir des exemples, suivez les étapes ci-dessous. Nous allons définir la fonction map, la fonction reduce et les exemples.
MapReduce comparera les chaînes pour trier la sortie en utilisant la méthode de tri par défaut, que vous utilisiez ou non la méthode par défaut. Pour modifier la façon dont les données sont triées, vous devez d'abord créer un algorithme de tri, puis l'implémenter à l'aide de la classe mapper.
SpiderMonkey est un moteur JavaScript largement utilisé. C'est bon pour les applications à petite échelle, mais il a quelques limites. SpiderMonkey n'a pas d'algorithme de tri, par exemple. Par conséquent, si vous souhaitez utiliser Mapmapper pour trier les données, vous devez d'abord créer votre propre algorithme de tri et l'implémenter dans la classe Reduce.
Malgré sa popularité, SpiderMonkey n'utilise pas d'algorithme de tri. Il existe d'autres limitations à SpiderMonkey, mais celle-ci est notable. SpiderMonkey, par exemple, n'a pas un bon ramasse-miettes, donc si votre programme commence à ralentir, vous devrez peut-être prendre certaines mesures pour le rendre plus rapide.
Pourquoi utiliser une fonction Mapreduce ?
Une fonction MapReduce peut être utile dans diverses situations. Cette méthode peut être utilisée pour le traitement de données par lots dans certains cas. Il est également utile si vous avez besoin qu'une grande quantité de données soit gérée par une seule application ou un seul processus. Une fonction MapReduce peut également être utilisée pour traiter des données réparties sur plusieurs nœuds dans un système distribué. En utilisant la fonction MapReduce, les données des nœuds peuvent être combinées en une seule sortie. Une application MapReduce est généralement utilisée pour traiter de grandes quantités de données, même si elle peut être nécessaire pour gérer de très grandes quantités.
Pourquoi s'appelle-t-il Mapreduce ?
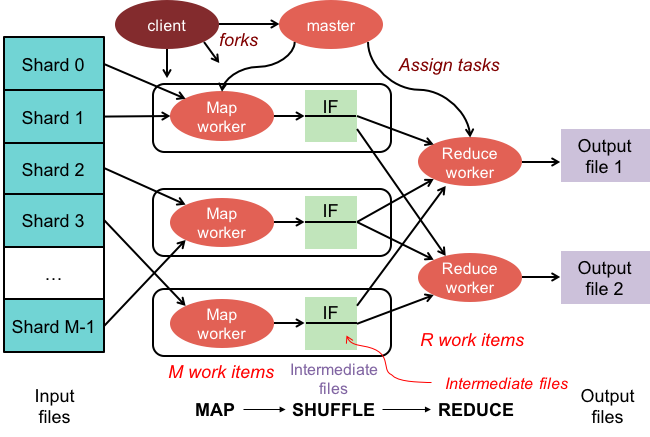
Il existe quelques théories sur la raison pour laquelle il s'appelle MapReduce. La première est qu'il s'agit d'un jeu de mots, puisque les algorithmes de réduction de carte impliquent de décomposer un problème en plus petits morceaux (cartographie), puis de résoudre ces morceaux et de les reconstituer (réduire). Une autre théorie est qu'il s'agit d'une référence à un article écrit par des employés de Google en 2004 intitulé "MapReduce : traitement simplifié des données sur les grands clusters". Dans l'article, les auteurs utilisent les termes « mapper » et « réduire » pour décrire les deux phases principales de leur modèle de traitement proposé.
Cependant, il est important de noter que le modèle MapReduce n'est utilisé que de manière limitée. Il n'est pas adapté aux grands ensembles de données et doit être parallélisé pour fonctionner correctement. Lorsqu'il s'agit de résoudre ces problèmes, Apache Spark dispose d'une puissante alternative à MapReduce. Le système informatique du cluster Spark est basé sur Hadoop et fonctionne comme une plate-forme informatique à usage général. Cet outil peut être utilisé pour accélérer les tâches d'analyse de données traditionnelles telles que l'exploration de données et l'apprentissage automatique, ainsi que des tâches de traitement de données plus complexes telles que l'entreposage de données et l'analyse de mégadonnées. Ce logiciel est construit à l'aide d'Erlang, un langage de programmation à la fois évolutif et tolérant aux pannes. Il peut gérer de grandes quantités de données et peut être exécuté sur plusieurs machines en même temps. De plus, Spark utilise le parallélisme, permettant à plusieurs nœuds d'effectuer la même tâche en même temps. Dans l'ensemble, il a le potentiel d'automatiser les tâches d'analyse de données à grande échelle et de les rendre plus évolutives. Si vous avez besoin de paralléliser votre traitement et de gérer de grands ensembles de données, c'est une excellente alternative à MapReduce.
Quelle est la différence entre mapreduce et agrégation ?
Lorsque vous travaillez avec le Big Data, mapreduce est une méthode importante pour extraire des données d'une grande quantité de données. MongoDB 2.2, à partir de maintenant, inclut le nouveau cadre d'agrégation. En termes de fonctionnalité, l'agrégation est similaire à mapreduce, mais sur le papier, elle semble être plus rapide.
Dans ce scénario, MongoDB Aggregation et MapReduce sont exécutés sur des conteneurs Docker dans une configuration fragmentée. Les performances du pipeline d'agrégation sont supérieures à celles de mapreduce, car elles permettent une navigation plus rapide et plus facile. Voici comment le problème fonctionne : tweet compte les pronoms suédois comme « den », « denne », « denna », « det », « han », « hon » et « hen » (sensible à la casse) dans un hashtag Twitter. Combien de pseudos Twitter un utilisateur possède-t-il ? Plus de 4 millions de tweets ont été envoyés. Dans cette expérience, nous allons d'abord créer une base de données MongoDB et activer le sharding. Les flux Twitter ont été importés dans la base de données et les requêtes utilisant MapReduce et Aggregation Pipeline ont été exécutées.
Mapreduce : l'outil ultime d'agrégation de données
Un programme mapReduce lit une liste de documents d'une collection et les traite à l'aide d'un ensemble de fonctions prédéfinies. L'opération mapReduce génère un flux de documents prêts à traiter qui seront traités à l'étape de réduction. Il est possible de combiner mapsreduce et agrégation dans une variété de situations. L'opérateur d'agrégation $group est un outil qui peut être utilisé pour regrouper des documents dans un seul champ. Lorsque plusieurs documents sont fusionnés à l'aide de l'opérateur d'agrégation $merge, un nouveau document peut être créé. L'opérateur d'agrégation $accumulator peut être utilisé pour représenter les résultats de plusieurs opérations de réduction de carte dans un seul document.
Mapreduce à Mongodb
Mongodb mapreduce est une technologie de traitement de données pour de grands ensembles de données. Il s'agit d'un outil puissant d'analyse des données et fournit un moyen de traiter et d'agréger les données de manière parallèle et distribuée. MapReduce a été largement utilisé pour l'analyse de données dans divers domaines, notamment l'analyse du trafic Web, l'analyse des journaux et l'analyse des réseaux sociaux.

Lorsque vous utilisez la commande mapReduce , vous pouvez exécuter des opérations d'agrégation map-reduce sur une collection. La fonction de carte peut convertir n'importe quel document en zéro ou en plusieurs autres. Dans les versions de MongoDB allant de 4.2 à antérieures, chaque émission ne peut contenir que la moitié de la taille maximale du document BSON. Le code JavaScript obsolète de type BSON utilisé dans MapReduce n'est plus pris en charge et le code ne peut plus être utilisé pour ses fonctions. MongoDB 4.4 n'inclut plus le code JavaScript obsolète de type BSON avec portée (BSON type 15). Le paramètre scope spécifie quelles variables sont autorisées à accéder par la fonction reduce. Pour réduire les entrées, MongoDB limite la taille du document BSON à la moitié de sa taille maximale.
Les documents volumineux renvoyés au serveur peuvent être renvoyés puis fusionnés dans des réductions ultérieures, ce qui pourrait enfreindre l'exigence. MongoDB 4.2 est la version la plus récente. Cette option peut être utilisée pour créer une nouvelle collection fragmentée ainsi que map-reduce pour créer une nouvelle collection avec le même nom de collection. La fonction finalize reçoit comme arguments une valeur clé et la valeur réduite de la fonction reduce. Il existe trois options pour configurer le paramètre out. Cette option, en plus de créer une nouvelle collection, ne fonctionne pas sur les membres secondaires des jeux de répliques. NonAtomic : l'option false ne peut être fournie que si la collection existe déjà pour transmettre la spécification explicite.
L'utilisation de la fonction de réduction à la fois sur le nouveau document et sur le document existant se produit si la clé du nouveau document est la même que celle du document existant. Une réduction de carte ne fonctionne pas lorsque collectionName est une collection existante non renforcée qui a été configurée. Dans ce cas, MongoDB est empêché de verrouiller sa base de données si nonAtomic est vrai. Seuls les membres secondaires des jeux de réplicas qui utilisent cette option peuvent être hors du jeu. Aucune fonction personnalisée n'est requise pour réécrire l'opération de réduction de carte. Le cust_id est utilisé pour calculer le champ de valeur du groupe $group stage par la méthode cust_id. L'étape $merge combine les résultats de l'étape $merge dans la collection de sortie à l'aide des opérateurs de pipeline d'agrégation disponibles.
Par exemple, l'étape $out peut être utilisée pour écrire la sortie de la collection agg_alternative_1. Chaque document d'entrée peut être traité avec la fonction map. Chaque article de la commande est associé à une nouvelle valeur d'objet contenant à la fois le nombre de 1 et la quantité d'articles dans la commande. Dans ReducedVal, le champ count représente la somme des champs count générés par les éléments du tableau. Si la fonction finalize modifie l'objet reduceVal pour inclure un champ calculé nommé avg, l'objet modifié est renvoyé à l'utilisateur. L'étape $unwind décompose le document en un document pour chaque élément du tableau à l'aide du champ de tableau items. L'étape $project remodèle le document de sortie afin de refléter la sortie de mapreduce en incluant deux champs -id et value.
Il écrase le document existant s'il n'y a pas de document existant avec la même clé que le nouveau résultat. Si vous spécifiez le paramètre out, mapReduce renvoie un document en tant que sortie au format suivant si vous souhaitez écrire les résultats dans une collection. Un tableau des documents résultants est renvoyé si la sortie est écrite en ligne. Chaque document contient deux champs : le nom du document source et le nom du document destinataire. Lorsque la valeur de la clé est entrée dans le champ -id, un champ de valeur est créé pour réduire ou finaliser les valeurs de la clé.
Qu'est-ce qu'Emit dans Mongodb ?
En tant que fonction de carte, la fonction de carte peut appeler des émissions (clé, valeur) à tout moment pour générer un document de sortie qui inclut la clé et la valeur. Une seule émission dans MongoDB 4.2 et versions antérieures ne peut contenir que la moitié de la taille maximale des fichiers BSON de MongoDB. À partir de la version 4.4 de MongoDB, la restriction est supprimée.
Pourquoi Mongodb est le meilleur choix pour des données flexibles et évolutives
En raison de son absence de schéma rigide, MongoDB est fréquemment associé à NoSQL. En raison de l'absence de schéma rigide, les données peuvent être stockées dans n'importe quel format convenant à l'application. La flexibilité de la base de données offre un avantage important lors de sa mise à l'échelle vers le haut ou vers le bas, car cela signifie que les données peuvent être stockées d'une manière adaptée aux besoins de l'application.
Un diagramme de données avec des diagrammes ER peut être utilisé pour visualiser les relations entre divers éléments de données. Le diagramme ER décrit une série de nœuds représentant une collection de données, et les connexions entre eux servent d'identifiant.
Les relations ne sont pas appliquées dans MongoDB car il ne s'agit pas d'une base de données relationnelle. Le diagramme ER décrit les relations qui existent au sein des données, et il aide également à les visualiser.
MongoDB est un excellent choix pour des données flexibles et évolutives. Sa flexibilité lui permet de stocker des données d'une manière logique pour une application, et son évolutivité lui permet de gérer rapidement et facilement de grands ensembles de données.
Exemple de réduction de carte Mongodb
Dans MongoDB, map-reduce est un paradigme de traitement de données permettant d'agréger les données des collections. Il est similaire à la carte et réduit les fonctions de la programmation fonctionnelle.
Les opérations de réduction de carte comportent deux phases :
1. La phase de mappage applique une fonction de mappage à chaque document de la collection. La fonction de mappage émet un ou plusieurs objets pour chaque document d'entrée.
2. La phase de réduction applique une fonction de réduction aux documents émis par la phase de carte. La fonction reduce agrège les objets et produit un seul objet en sortie.
Par exemple, considérons une collection d'articles. Nous pouvons utiliser map-reduce pour calculer le nombre de mots dans chaque article.
Tout d'abord, nous définissons une fonction de mappage qui émet une paire clé-valeur pour chaque document, où la clé est l'identifiant de l'article et la valeur est le nombre de mots dans l'article.
Ensuite, nous définissons une fonction de réduction qui additionne les valeurs de chaque clé.
Enfin, nous exécutons l'opération de réduction de carte sur la collection. Le résultat est un document qui contient les données agrégées.
En mongosh, il y a une base de données. La méthode mapReduce() est un wrapper autour de la commande mapReduce. Plusieurs exemples dans cette section, tels qu'une alternative de pipeline d'agrégation sans expression d'agrégation personnalisée, sont fournis. Les cartes peuvent être traduites avec des expressions personnalisées à l'aide d'exemples de traduction Map-Reduce to Aggregation Pipeline. L'opération de réduction de carte peut être modifiée sans avoir à définir de fonctions personnalisées à l'aide des opérateurs de pipeline d'agrégation disponibles. La fonction de carte peut être utilisée pour traiter chaque document dans l'entrée. Chaque article a sa propre valeur d'objet associée à une nouvelle valeur contenant le numéro 1, le numéro de quantité pour la commande et une liste d'articles.
Si la clé du document actuel est la même que la clé du nouveau document, l'opération écrase ce document. Vous pouvez réécrire l'opération de réduction de carte à l'aide d'opérateurs de pipeline d'agrégation plutôt que de définir des fonctions personnalisées. L'étape $unwind décompose le document par le champ de tableau d'éléments, ce qui donne un document pour chaque élément du tableau. Lorsque l'étape $project remodèle le document de sortie, la sortie map-reduce est mise en miroir. Une opération écrase un document existant qui a la même clé que le nouveau résultat.
Qu'est-ce que la fonction Mapper dans Hadoop ?
En tant que réducteur, vous devez combiner les données des mappeurs afin de générer une réponse unifiée. Réduire la sortie est produit lorsqu'un ensemble de sorties de carte est accepté comme entrée, chacune représentant un sous-ensemble du résultat généré.
Les mappeurs sont utilisés pour diviser les données en blocs gérables, puis attribuer chaque bloc à une tâche en fonction de sa taille. Les données d'entrée sont reçues par la fonction mappeur, où il y a des paramètres indiquant la tâche à effectuer.
Une série d'éléments correspond aux blocs de données qui ont été mappés par le mappeur en sortie. En conséquence, la sortie de carte est transmise au réducteur, qui la convertit en une sortie de réduction.
Les erreurs sont également gérées par la fonction mapper. Un mappeur renverra une sortie d'erreur dans ce cas, qui n'est pas une sortie de carte. Étant donné que le réducteur ne peut pas traiter ces données, le mappeur renverra un message d'erreur.
Écosystème Hadoop
L'écosystème Hadoop est une plate-forme de traitement et de stockage de données volumineuses. Il se compose d'un certain nombre de composants, dont chacun a un rôle spécifique à jouer dans le traitement et le stockage des données. Les composants les plus importants de l'écosystème sont le système de fichiers distribués Hadoop (HDFS), le framework MapReduce et la bibliothèque Hadoop Common .