
Base de données NoSQL : Impala
Publié: 2023-03-03NoSQL est un terme utilisé pour décrire une base de données qui n'utilise pas la structure de base de données relationnelle traditionnelle. Au lieu de cela, les bases de données NoSQL sont souvent conçues pour fournir une solution plus simple et plus évolutive.
Impala est une base de données NoSQL conçue pour fournir une solution rapide et évolutive pour la gestion de grands ensembles de données. Impala est basé sur le modèle de données Google Bigtable et utilise un format de stockage en colonnes. Impala est disponible en tant que projet open source et est pris en charge par Cloudera.
Apache Impala est un moteur de requête SQL open source qui est installé sur un cluster Hadoop et effectue un traitement parallèle massif (MPP) pour les données stockées sur le système. Développé à l'origine en 2012, le projet open source est connu sous le nom de "Microsoft Formula 1".
La plate-forme Impala permet aux utilisateurs d'effectuer des requêtes SQL à faible latence sur les données Hadoop stockées dans HDFS et Apache HBase sans avoir à déplacer ou transformer les données.
Impala Sql est-il basé ?
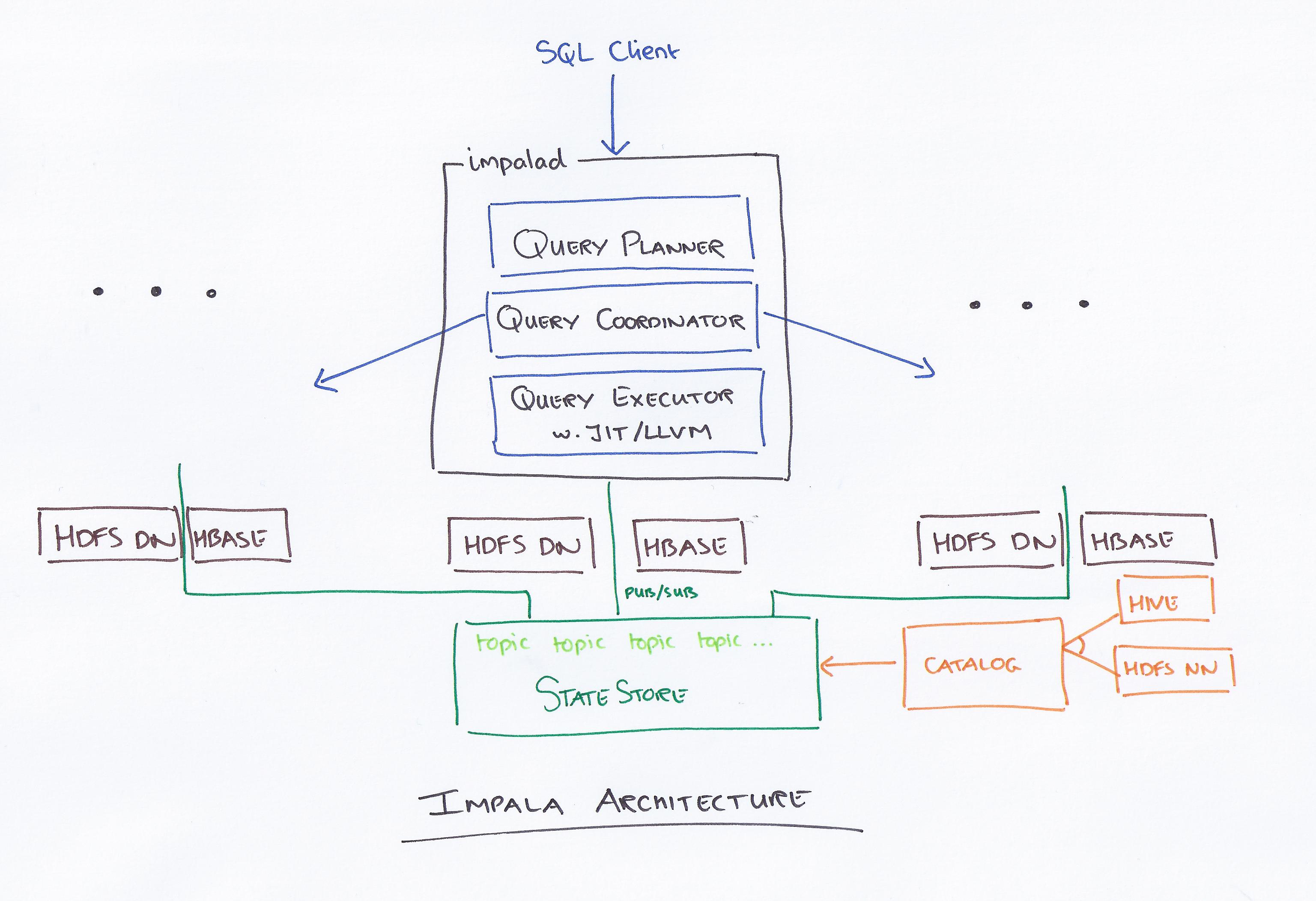
Impala est un moteur de requête basé sur SQL qui s'exécute sur Apache Hadoop. Il permet aux utilisateurs d'interroger les données stockées dans HDFS et HBase à l'aide de SQL. Impala offre des performances élevées et une faible latence par rapport aux autres moteurs de requête Hadoop tels que Hive et Pig.
La base de données analytique MPP d'Impala offre le temps d'analyse le plus rapide du secteur. Il est intégré à CDH et accessible via Cloudera Enterprise. Les bases de données MPP pour Apache Hadoop, comme Impala, utilisent HDFS pour fournir des informations plus rapides.
Impala est une base de données
C'est une base de données je crois.
Impala est-il un outil ETL ?
Impala n'est pas un outil ETL, c'est un moteur de requête SQL qui peut être utilisé pour effectuer des requêtes SQL après que les données ont été nettoyées via un processus.
À quoi sert Apache Impala ?
En utilisant des requêtes de type SQL, nous pouvons lire des données provenant de diverses sources à l'aide d'Impala. Apache Impala est plus performant que Hive et d'autres moteurs SQL lorsqu'il s'agit d'accéder aux données stockées dans le système de fichiers distribué Hadoop . Nous utilisons Impala pour stocker des données dans Hadoop HBase, HDFS et Amazon S3.
19 entreprises qui utilisent Apache Impala dans leurs piles technologiques
Apache Impala est un moteur de traitement de données populaire pour une variété de grandes entreprises. Selon les rapports, 19 entreprises technologiques, dont Stripe, Agoda et Expedia.com, utilisent Apache Impala. La plate-forme Impala est flexible et efficace, capable de gérer rapidement et efficacement de grands ensembles de données. La généralisation de cet outil démontre son utilité, et son utilité dans le traitement des données.
Quelles sont les différences entre Sql Hive et Impala ?
L'objectif de Hive est de gérer les requêtes de longue durée qui nécessitent plusieurs transformations et jointures. En raison de sa faible latence et de sa capacité à gérer des requêtes plus petites, le moteur de traitement des requêtes Impala est idéal pour l'informatique interactive. Spark prend en charge les requêtes à court et à long terme en plus des requêtes à court et à long terme.
Hive est mieux adapté aux travaux par lots de longue durée
L'objectif principal des outils n'est pas de traiter des lots. Hive est mieux adapté au travail par lots à long terme qu'Impulsa, qui peut gérer des ensembles de données plus petits.
Impala est-il une base de données
Un impala est une base de données qui stocke les données dans un format en colonnes. Il est conçu pour être évolutif et fournir des performances élevées pour les grands ensembles de données.
Dans la version initiale d'Impala, les types de données de colonne de base suivants sont pris en charge : STRING, VARCHAR, VARCHar2, INT et FLOAT plutôt que nombre, et aucun type BLOB n'est pris en charge. Impala SQL-92 inclut certaines améliorations des standards SQL, mais il ne les intègre pas toutes. Lorsque les données sont trop volumineuses pour être produites, manipulées et analysées sur un seul serveur, Impala fonctionne mieux que les autres entrepôts de données et est plus évolutif. Il n'est pas nécessaire de supprimer l'emplacement d'origine des fichiers de données lors du chargement d'Impala car il est léger. La première étape de l'apprentissage des tests de performances, de l'évolutivité et des configurations de cluster à plusieurs nœuds consiste généralement à collecter de grandes quantités de données. Cloudera Impala est optimisé pour le chargement de données et la lecture en bloc dans de grands ensembles de données, ce qui vous permet d'en faire plus avec moins. La taille de bloc de plusieurs mégaoctets de HDFS permet à Impala de traiter d'énormes quantités de données en parallèle sur plusieurs serveurs en réseau.
Au lieu de planifier des index normalisés et le temps et les efforts nécessaires pour les créer, vous le ferez dans Impala. Le moteur de requête d'Impala peut gérer de grandes quantités de données provenant d'entrepôts de données. Il analyse un cluster et répartit les tâches entre les nœuds afin de réduire la quantité de ressources consommées. Le partitionnement d'un entrepôt de données est un concept familier dans Impala. Le partitionnement réduit les E/S de disque et augmente l'évolutivité des requêtes dans Impala. Les fichiers de données sont nécessaires car vous ne pourrez accéder à aucune table intégrée dans Impala. INSERT est l'une des options disponibles.
Pour construire deux tables jouets, utilisez une déclaration de valeur. Si vous avez utilisé un logiciel orienté batch, vous pouvez l'essayer. Vous pouvez intégrer la technologie SQL-on-hadoop dans votre configuration Apache Hive. Les tables Hive dans Impala ne sont pas chargées ou converties de manière fastidieuse.
Impala : un puissant outil de gestion de données pour Hadoop
La syntaxe SQL est familière aux utilisateurs d'Impala, qui peuvent interroger les données stockées dans HDFS et Apache HBase. De cette façon, Hadoop et Impulsa peuvent être utilisés plutôt que les bases de données relationnelles traditionnelles . De plus, c'est un puissant outil de gestion de données grâce à ses fonctionnalités. De plus, ses capacités pour les grands ensembles de données sont impressionnantes et il peut les gérer avec une grande facilité.
Impala dans le Big Data
Impala est un moteur de requête SQL MPP open source qui s'exécute sur Apache Hadoop. Il fournit des requêtes SQL rapides et interactives sur les données stockées dans HDFS et HBase. Impala est conçu pour améliorer les performances d'Apache Hadoop en fournissant une interface SQL rapide et interactive pour les données stockées dans HDFS et HBase.
Impala, dirigé par Cloudera, est un nouveau système de requête. Hadoop a HDFS et HBase, il peut donc interroger le Big Data au niveau PB qui y est stocké. Cette technologie est basée sur la ruche et la mémoire pour le calcul, ainsi que sur la prise en compte de l'entrepôt de données, et elle fournit un traitement par lots en temps réel et un traitement simultané multiple. Un client envoie une demande de requête à un nœud au sein d'un réseau impalad, où un identifiant de requête est renvoyé pour les opérations client ultérieures. Au cours de la première étape du processus de création de l'analyseur, un plan d'exécution autonome (plan de machine unique, plan d'exécution distribué) est généré, et SQL sera également exécuté, comme les changements d'ordre de jointure, les poussées de prédicat, etc. Tous les nœuds conservent une copie des informations de métadonnées les plus récentes pour s'assurer que vous n'êtes pas exclu de la boucle. Avant d'utiliser Hadoop, Hive ou Impurbia, vous devez d'abord installer le logiciel de traitement de données nécessaire.

Le fichier de configuration d'Impala peut être modifié. Chaque nœud effectue un changement de configuration dans Impala. Tous les nœuds sont responsables de la connexion du package de pilotes MySQL à une base de données. Les nœuds modifient le chemin Java de Bigtop.
Une comparaison de la ruche et de l'impala
Il existe également quelques différences mineures, en plus de ces trois principales. Dans Hive, il existe un sous-ensemble de HiveQL, alors que dans Implicit, il existe un sous-ensemble de HiveQL. Hive et Impala sont utilisés respectivement pour l'entreposage de données et les requêtes interactives. Hive, contrairement à Impala, n'est pas destiné à l'informatique interactive.
Qu'est-ce qu'Impala dans Hadoop
Impala est un moteur de requête SQL open source pour les données stockées dans un cluster Hadoop. Il est conçu pour fournir des requêtes SQL rapides et interactives sur les données stockées dans HDFS, HBase ou toute autre source de données Hadoop .
Impala utilise une large gamme de composants Hadoop familiers . INSERT ne peut écrire que des données du type qu'Impala peut lire, tandis que SELECT peut lire des données du type qu'Impala peut lire. Lorsque vous utilisez un format de fichier Avro, RCFile ou SequenceFile, les données sont chargées dans Hive. Les statistiques de table et les statistiques de colonne peuvent être utilisées en plus des statistiques de table et de colonne. Toutes les instructions DDL et DML sont automatiquement mises à jour à l'aide du démon catalogd dans Impala 1.2 et supérieur si elles sont envoyées via le démon catalogd. La méthode INVALIDATE METADATA renvoie les métadonnées de toutes les tables du metastore auxquelles on a accédé. Les fichiers de données sont stockés dans des répertoires pour une nouvelle table et sont lus quel que soit le nom du fichier lors de l'exécution d'Impala.
Dans l'ensemble, Apache Hive fonctionne bien en tant que plate-forme d'entreposage de données, tandis qu'Impala est mieux adapté au traitement parallèle. Le Hive est tolérant aux pannes, alors que l'Impulsa ne l'est pas.
Apache Impala
Apache Impala est un moteur de requête SQL rapide et interactif pour Apache Hadoop. Il permet aux utilisateurs d'émettre des requêtes SQL à faible latence sur les données stockées dans HDFS et Apache HBase sans nécessiter de déplacement ou de transformation des données.
Le concept d'architecture d'Impala lui permet de gérer les requêtes interactives à l'aide de HDFS plus efficacement que tout autre moteur de requête. Hive est beaucoup plus lent en raison de ses opérations d'E/S de disque, mais Apache est beaucoup plus rapide car il s'agit d'un moteur complètement différent. Il n'y a pas de distinction entre Impulsa et Presto car Impulsa utilise une technologie beaucoup plus rapide et Presto utilise une architecture similaire. En ce qui concerne les limes Parquet, Impala est la plus performante. Déterminez les données que vous devez partitionner en fonction des requêtes de vos analystes. Avec Compute Stats Statistics, vos requêtes seront beaucoup plus faciles, surtout si elles impliquent plus d'une table (jointures). Nous avions un plantage du serveur de catalogue Impala quatre fois par semaine et nos requêtes prenaient beaucoup trop de temps.
De plus, la quantité de fichiers que nous créons affecte considérablement les performances de nos requêtes. En conséquence, nous avons commencé à gérer nos partitions et à les fusionner dans la taille de fichier optimale d'environ 256 Mo. Il est précisé que chaque partition n'a qu'un seul fichier (sauf si sa taille est > 256 Mo). Le type de colonne le plus approprié doit être choisi parmi tous les types de données pris en charge par Implicit. Pour limiter le nombre de requêtes simultanées ou la mémoire Y accessible par un utilisateur, utilisez le contrôle d'admission Impala. Si une requête dure plus de 30 minutes, elle est considérée comme morte.
Le meilleur moteur pour le Big Data : Impala
Le moteur Impala est un moteur de traitement de données Hadoop spécialement conçu pour les grands clusters. Il utilise beaucoup moins d'énergie et consomme beaucoup moins de ressources que le moteur MapReduce standard de Hadoop. Implicit utilise le système de fichiers distribué HDFS comme principal support de stockage de données, en s'appuyant sur la redondance de HDFS pour empêcher les pannes matérielles ou réseau sur une base nœud par nœud. Les fichiers de données qui représentent des données de table sont physiquement représentés par des formats de fichiers HDFS et des codecs de compression familiers.
Moteur de requête de traitement parallèle
Un moteur de requêtes à traitement parallèle est un type de moteur de base de données conçu pour traiter des requêtes en parallèle. Cela peut être fait en utilisant plusieurs processeurs, plusieurs cœurs ou plusieurs machines. Le traitement parallèle peut grandement améliorer les performances d'un moteur de requête, en particulier pour les requêtes complexes.
Un ordinateur multiprocesseur est utilisé pour transformer des requêtes complexes en plans d'exécution pouvant être exécutés simultanément, ce qui lui permet de traiter de grandes quantités de données à la fois. Une exécution efficace, telle qu'un bon temps de réponse aux requêtes ou un débit élevé des requêtes, est nécessaire pour des performances élevées. Il est accompli grâce à l'utilisation de techniques d'exécution parallèle efficaces et à l'optimisation des requêtes.
Traitement parallèle : l'avenir d'ETL ?
Une requête de haut niveau peut être transformée en un plan d'exécution qui peut être exécuté efficacement par un ordinateur multiprocesseur utilisant un traitement de requête parallèle. Le traitement parallèle utilise la technique de combinaison de données parallèles et distribuées, ainsi que les diverses techniques d'exécution fournies par le système de base de données parallèle . Le traitement parallèle des requêtes est implémenté dans ETL en divisant l'ensemble d'enregistrements de chaque table source affectée au transfert en morceaux de même taille, puis en effectuant le processus de transformation des données pour chaque table source dans un cycle, en sélectionnant les données consécutivement, morceau par morceau .