
Bases de données NoSQL : une alternative aux bases de données relationnelles traditionnelles
Publié: 2023-01-13Les bases de données NoSQL deviennent de plus en plus populaires comme alternative aux bases de données relationnelles traditionnelles. Une base de données NoSQL ne nécessite pas de schéma fixe et est facile à mettre à l'échelle. Une file d'attente est un type de magasin de données NoSQL. Une file d'attente est une structure de données qui stocke les données selon le principe du premier entré, premier sorti (FIFO). Une file d'attente est souvent utilisée pour stocker des données qui doivent être traitées dans un ordre séquentiel, comme une liste de tâches à accomplir. Une file d'attente est un type de magasin de données NoSQL car elle ne nécessite pas de schéma fixe. Une file d'attente peut être facilement mise à l'échelle à mesure que le nombre de tâches augmente.
Si je vais utiliser MongoDB ou RavenDB comme file d'attente de messages, que vais-je préférer ? L'objet message peut être envoyé à un service Web via le client, puis récupéré par le service Web. Le service qui effectue le travail peut alors sélectionner un type de message en fonction de tout critère pouvant survenir. Je peux créer des index basés sur les scénarios afin d'accélérer les choses. Si vous ne construisez qu'une file d'attente, vous ne devriez envisager NoSQL que pour cela. Cela aura très probablement un impact plus important sur les performances, la fiabilité et l'efficacité si vous prenez une décision sur l'implémentation que vous souhaitez utiliser.
Les bases de données NoSQL (également appelées SQL) stockent les données différemment des bases de données relationnelles en plus d'être non tabulaires. Une base de données NoSQL peut être de différents types en fonction de son modèle de données. Les types de documents, les types de valeurs-clés, les types de colonnes larges et les graphiques sont les plus couramment utilisés.
Datastore est une base de données NoSQL hautement évolutive qui prend en charge un large éventail d'applications. Par conséquent, Datastore gère automatiquement le partitionnement et la réplication, ce qui vous permet d'utiliser une base de données hautement disponible et durable qui évolue automatiquement pour gérer la charge de vos applications.
Qu'est-ce qu'un magasin de données Nosql ?
Il existe de nombreux types de magasins de données NoSQL, chacun avec ses propres forces et faiblesses. Les magasins de données NoSQL les plus populaires sont MongoDB, Cassandra et HBase.
Les bases de données NoSQL basées sur des documents stockent les données plus efficacement que les bases de données relationnelles. Ils sont conçus pour être adaptables, évolutifs et capables de répondre rapidement aux besoins de l'entreprise en matière de gestion des données. Les types de bases de données communément appelés NoSQL incluent les bases de données de documents purs, les magasins clé-valeur, les bases de données à colonnes larges et les bases de données de graphes. Les entreprises du Global 2000 adoptent rapidement les bases de données NoSQL pour alimenter les applications critiques. Cela est dû à cinq tendances qui présentent des défis techniques qui rendent la plupart des bases de données relationnelles difficiles à utiliser. La gestion des bases de données est un obstacle majeur au développement agile, car elles n'ont pas la capacité de prendre en charge le modèle de données fixe qui est essentiel au développement agile. Le modèle d'application définit le modèle de données dans NoSQL.
La modélisation des données en NoSQL n'est pas statique. Le format JSON est le format par défaut pour stocker des données dans une base de données orientée document. Cela élimine le besoin de cadres ORM et améliore le processus de développement. N1QL (prononcé nickel), un langage de requête puissant qui étend SQL à JSON, a été publié dans le cadre de Couchbase Server 4.0. De plus, il inclut la prise en charge des instructions SELECT / FROM / WHERE standard ainsi que l'agrégation (GROUP BY), le tri (SORT BY), les jointures (LEFT OUTER / INNER) et autres. En raison de leur architecture évolutive et de l'absence de point de défaillance unique, les bases de données distribuées NoSQL présentent des avantages opérationnels incontestables. La disponibilité devient un problème majeur car de plus en plus de clients interagissent avec les entreprises en ligne et via des applications mobiles.
Les bases de données NoSQL sont simples à installer, à configurer et à mettre à l'échelle. Avec leurs lectures, écritures et stockage distribués, ils ont été conçus pour simplifier la lecture, l'écriture et le stockage. Ils peuvent fonctionner à une large gamme d'échelles, y compris celles qui gèrent et surveillent des clusters de différentes tailles. Il n'est pas nécessaire de développer un logiciel pour répliquer entre les centres de données ; une base de données NoSQL distribuée inclut une réplication intégrée entre les centres de données. En outre, il permet aux applications d'effectuer leur propre basculement plutôt que d'attendre que la base de données détecte un problème et exécute un processus de récupération basé sur la base de données. Les bases de données NoSQL sont de plus en plus utilisées dans les applications Web, mobiles et IoT en raison de leur facilité d'utilisation et de leur facilité d'intégration.
Le stockage de table est une excellente solution pour les données qui ne sont pas stockées dans une base de données relationnelle. Le stockage de table vous permet de stocker des données dans un conteneur suffisamment flexible pour s'adapter à la croissance de votre application. Un système de stockage de table peut être utilisé pour stocker des données difficiles à stocker dans un modèle relationnel, telles que des données vidéo ou d'image.
Bases de données Nosql d'Azure : Documentdb, Graph et Keyvalue
Les trois types de bases de données NoSQL dans Azure sont Azure DocumentDB, Azure Graph et Azure KeyValue. Avec Azure DocumentDB, plus besoin de gérer les fichiers de données sur le serveur ni de les récupérer dans les archives ; il est sans serveur, clé-valeur et peut gérer jusqu'à un million de requêtes par seconde. Il s'agit d'une base de données graphique qui peut être utilisée pour interroger et gérer des données sur plusieurs niveaux dans une application. Azure Graph est une base de données de graphes qui peut être utilisée pour interroger et gérer des données sur plusieurs niveaux dans une application. Il vous permet d'organiser et de filtrer les données dans les listes triées et filtrées d'Azure KeyValue.
Une file d'attente est-elle une base de données ?
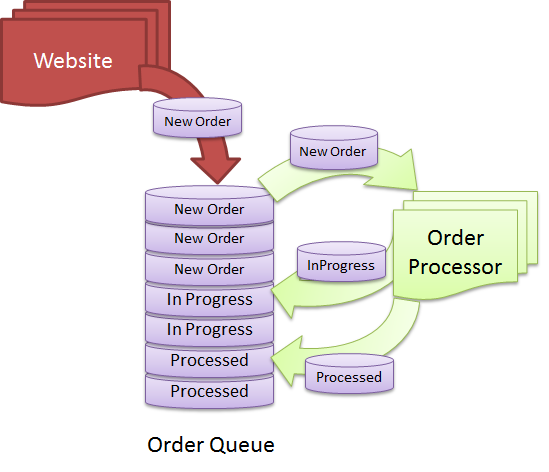
Il n'y a pas de réponse définitive à cette question car cela dépend de la façon dont vous définissez une base de données. De manière générale, une base de données est un ensemble de données organisées de manière spécifique afin qu'elles puissent être consultées et mises à jour au besoin. Une file d'attente est une structure de données qui vous permet de stocker et de récupérer des données dans un ordre spécifique. Ainsi, si vous considérez une file d'attente comme une collection de données, elle peut être considérée comme une base de données. Cependant, si vous ne considérez qu'une base de données comme une collection de données accessibles et mises à jour, une file d'attente ne sera pas considérée comme une base de données.
Quel est le bon moment pour utiliser une base de données pour un système basé sur une file d'attente ? Il est essentiel de maintenir une file d'attente ordonnée et organisée afin que toutes les demandes soient traitées le plus rapidement possible. Il existe une file d'attente de messages conçue pour gérer ce type de situation, ce qui simplifie le retrait ou la mise en file d' attente des messages . Imaginez que vous ayez des centaines de demandes de création de PDF dans votre base de données à tout moment. Il est souhaitable de pouvoir traiter plus de demandes par seconde sur une base continue. Il n'est pas nécessaire de connecter plus de travailleurs (processus qui gèrent les demandes) car vous pouvez faire évoluer votre solution. Pour recevoir la demande, le travailleur devra fournir une information supplémentaire.
Les files d'attente de messages n'exigent pas que l'utilisateur effectue des transactions pour s'assurer que les messages sont stockés et traités. Au lieu d'interroger manuellement les messages d'une base de données, les files d'attente de messages sont poussées en temps réel. Si vous manquez de puissance CPU en vous connectant à trop de connexions ou en effectuant d'autres tâches nécessitant beaucoup de CPU, vous pouvez utiliser plus de puissance CPU pour alimenter votre serveur de file d'attente de messages. Dans les cas où un grand nombre de messages asynchrones sont requis, une file d'attente de messages est fortement recommandée. Si un travailleur meurt pendant l'exécution d'une tâche, il doit être conservé dans la file d'attente jusqu'à ce que la demande soit résolue. Lorsqu'un message est reçu et traité, un agent renvoie un accusé de réception à la file d'attente des messages pour l'informer de la progression.
Une file d'attente est une structure de données qui peut stocker une collection d'éléments dans un ordre logique. Les éléments placés dans une file d'attente sont traités dès que possible après avoir été ajoutés à la file d'attente. Une file d'attente peut être utile lorsque vous souhaitez traiter des éléments dans un ordre spécifique. Une instruction SELECT est une méthode qui peut être utilisée pour modifier le contenu d'une file d'attente. Une instruction SELECT est une méthode qui vous permet de sélectionner des éléments dans une file d'attente et de les envoyer à un autre emplacement si vous le souhaitez. L'instruction SELECT est également utilisée pour envoyer des éléments d'un autre emplacement vers une file d' attente appropriée , ainsi que pour les insérer dans une file d'attente. Une instruction INSERT, UPDATE, DELETE ou TRUNCATE ne peut pas tenter de cibler une file d'attente. Si vous devez traiter des éléments dans un ordre spécifique, une file d'attente est utile ; cependant, vous ne devez pas modifier les éléments de la file d'attente.

L'importance des systèmes de file d'attente dans les systèmes de base de données
Une base de données avec des mécanismes de file d'attente est un excellent ajout à tout centre de données. Il est essentiel de disposer de fonctionnalités SGBD pour les systèmes de file d'attente, car elles peuvent être utilisées à diverses fins. En intégrant la fonctionnalité de file d'attente dans un système de base de données standard , d'autres applications peuvent y accéder plus facilement. Avec cette mise à jour, les systèmes de file d'attente sont plus puissants et polyvalents, et leur utilité et leur potentiel sont accrus.
Mongodb a-t-il une file d'attente ?
Une file d'attente est une collection de documents qui sont insérés dans une base de données MongoDB dans un ordre croissant basé sur les données de création du document ou un classement des documents basé sur une priorité donnée.
Si vous utilisez déjà MongoDB, vous pouvez utiliser cette méthode pour créer des files d'attente avec une belle API. Si vous avez un pilote MongoDB v3 ou une ancienne base de données, l'option mongodb- [email protected] est recommandée. Ce package est classé comme fonctionnalité complète et stable. Malgré son utilisation généralisée, il y a très peu de nouveaux développements en cours. S'il vous plaît laissez-nous savoir si vous avez des problèmes ou si vous l'utilisez de manière incorrecte. Chaque file d'attente que vous créez sera l'une des siennes. Une collection MongoDB peut être créée sous le nom de resizing-image-queue ou notify-owner-queue, qui peuvent toutes deux être utilisées.
Si vous ne recevez pas de message dans les 30 secondes suivant sa réception, il est replacé dans la file d'attente afin de pouvoir être récupéré. Interrogez votre file d'attente morte pour voir si des messages morts ont été trouvés. Lorsque nous renvoyons tous les messages de la file d'attente d'origine vers la file d'attente morte when.get(), la charge utile de la file d'attente morte est le message. Si un élément est supprimé de la file d'attente mais n'est pas acquitté, il sera déplacé vers cette file d'attente morte la prochaine fois qu'il tentera de quitter. Si un élément est supprimé de la file d'attente mais n'est pas acquitté, il sera déplacé vers cette file d'attente morte la prochaine fois qu'il tentera de quitter. La file d'attente peut toujours être visualisée en envoyant un ping à un message pour lui dire que vous êtes en vie et que vous traitez la demande. Le temps de visibilité que vous passez sur l'opération ping est également déterminé par la méthode // temps de visibilité (dans ce cas, cette file d'attente a vu%d messages%d messages%d comptes ; ); // queue.ping(msg.ack, (err, id) = Le nombre de messages qui ont été dans la file d'attente au cours des dernières 24 heures, ainsi que les messages actuels.
Nous pouvons calculer le nombre de nouveaux messages reçus mais pas encore activés. Il devrait être possible de get.total() si vous additionnez up.size() +.inFlight() +.done() mais cela ne sera qu'approximatif car les deux sont des opérations différentes qui sont utilisées pour calculer le total. Parfois, les saisons sont très différentes. Utilisez l'option setInterval pour nettoyer régulièrement votre système. Console.log('Les messages traités ont été supprimés de la file d'attente')*).
File d'attente Mongodb
Les files d'attente MongoDB (ou files d'attente de messages) fournissent un mécanisme pour stocker les messages de manière ordonnée, premier entré, premier sorti. Les messages peuvent être insérés dans la file d'attente à tout moment et seront traités dans l'ordre dans lequel ils sont reçus. Cela rend les files d'attente MongoDB idéales pour le traitement des tâches qui doivent être effectuées dans un ordre spécifique ou pour les tâches qui peuvent être traitées de manière asynchrone.
La mission de FloQast est de permettre aux équipes produit d'accélérer et d'automatiser le développement de produits innovants. Traditionnellement, AWS SQS a servi de service de file d'attente de messages . Cela a entraîné des problèmes en termes de maintien de la maniabilité et de la duplication. Au lieu de cela, nous avons choisi MongoDB comme file d'attente de messages. Dans AWS Lambda, vous pouvez facilement ajouter des messages à n'importe quelle file d'attente. Il élimine le besoin de mettre à niveau les services existants afin d'utiliser un Lambda distinct. Lorsqu'une file d'attente est accessible, le service utilise la méthode atomique findAndModify de MongoDB pour saisir le premier élément et appeler Lambda en fonction des instructions du développeur.
Qu'est-ce que Change Stream dans Mongodb ?
En temps réel, les développeurs d'applications peuvent voir les changements dans les données sans craindre de suivre leur oplog ou d'avoir à faire face à la complexité et aux risques des structures de données complexes. Un flux de modifications peut être utilisé par une application pour s'abonner à toutes les modifications de données sur n'importe quelle collection, base de données ou déploiement et y réagir immédiatement.
Utiliser des déclencheurs pour automatiser les opérations de base de données
En utilisant des mécanismes de déclenchement, vous pouvez automatiser les opérations de base de données et rendre votre système plus efficace. Lorsqu'un document est ajouté, mis à jour ou supprimé d'un cluster MongoDB Atlas lié, les déclencheurs peuvent gérer la logique côté serveur. Vous serez en mesure de maintenir le bon fonctionnement de votre système et d'automatiser les opérations de base de données en conséquence.
Base de données de documents Nosql
Une base de données NoSQL, également appelée base de données non relationnelle, est une base de données qui n'utilise pas la structure de base de données relationnelle traditionnelle basée sur des tables. Les bases de données NoSQL sont souvent utilisées pour le Big Data et les applications Web en temps réel.
Une base de données orientée document est un moyen moderne de stocker des données dans JSON plutôt que d'utiliser des colonnes et des lignes traditionnelles. Ces données semi-structurées peuvent être utilisées pour résoudre des problèmes difficiles qui nécessiteraient autrement un SGBDR. Les magasins de documents constituent une solution naturelle et flexible qui peut être utilisée par les développeurs qui souhaitent travailler plus rapidement avec des logiciels agiles. Vous pouvez effectuer des requêtes de différentes manières grâce au langage de requête expressif et aux capacités d'indexation polyvalentes. Une base de données relationnelle possède un ensemble de garanties que vous connaissez bien lors de l'exécution de transactions ACID. Avoir des systèmes distribués vous permet de faire évoluer et de protéger vos données de manière plus efficace et adaptable. Chaque document est distribué sur plusieurs serveurs dans une unité indépendante, ce qui réduit le besoin de localisation des données.
Les bases de données documentaires sont intuitives et simples à utiliser, avec des vitesses de données plus rapides que les bases de données relationnelles. La qualité des données sera moindre et les tableaux seront rigides. Étant donné que la mise à l'échelle native ne peut pas être effectuée, vous devez payer pour des systèmes de mise à l'échelle coûteux si vous souhaitez partitionner votre base de données relationnelle traditionnelle. Il est possible de choisir parmi une large gamme de types de documents dans les bases de données orientées documents ; cependant, les champs trouvés dans chaque magasin peuvent être facultatifs. Chaque document a la même structure, mais ses champs diffèrent. Chaque document a son propre ID unique qui peut être utilisé pour ajouter, modifier, supprimer et interroger des informations. Les encodages de documents sont généralement considérés comme le processus de conversion de données (ou d'informations) encapsulées dans un format standard.
Une structure de base de données orientée document est moins rigide et donc moins sujette aux incohérences. Lorsque vous interrogez des informations directement à partir du document plutôt qu'à partir des colonnes de la base de données, les données sont stockées plus directement dans le document. Les données peuvent être ajoutées au magasin de documents avec un champ unique qui contient des champs d'informations pertinents pour les données.