
Bases de données NoSQL et données non uniformes
Publié: 2023-03-03Les données non uniformes dans NoSQL sont des données qui ne sont pas cohérentes avec le schéma de la base de données. Cela peut se produire lorsque les données ne sont pas bien formées, lorsqu'elles ne sont pas normalisées ou lorsqu'elles ne sont pas valides selon les règles de la base de données. Les données non uniformes dans NoSQL peuvent entraîner des problèmes de performances de la base de données et peuvent également entraîner une perte de données.
Qu'est-ce qu'une base de données Nosql non relationnelle ?
Une base de données non relationnelle est une base de données qui ne repose pas sur le schéma tabulaire trouvé dans une base de données standard. Les bases de données non relationnelles, quant à elles, utilisent un modèle de stockage adapté aux besoins spécifiques du type de données stockées.
Le logiciel de base de données conçu pour le cloud offre des avantages tels qu'une plus grande évolutivité, des performances et une flexibilité du modèle de données par rapport aux bases de données relationnelles traditionnelles . Les technologies de base de données telles que NoSQL ont été créées pour être extrêmement flexibles et simples à utiliser, ainsi que non spécifiques à l'approche basée sur les tables. Tous les types de données, structurées et non structurées, peuvent être facilement manipulés et ils peuvent être mis à l'échelle pour les stocker de manière rentable. Lorsqu'il s'agit de créer des systèmes qui personnalisent l'expérience client, les bases de données NoSQL sont le choix le plus populaire. L'une des principales différences entre une base de données NoSQL et une base de données relationnelle est son évolutivité. En plus des bases de données NoSQL, vous avez la possibilité de choisir celle qui répond le mieux à vos données et à vos objectifs. Une base de données de graphes est un magasin de données qui utilise une métaphore de graphe pour connecter les relations de données.
Les bases de données multi-modèles gagnent en popularité sur les marchés NoSQL et RDBMS. Les bases de données NoSQL sont conçues pour prendre en charge les systèmes décentralisés qui ciblent les applications cloud. Une base de données NoSQL, dans la plupart des cas, offre les avantages suivants par rapport aux autres systèmes de gestion de base de données : Elle ne nécessite pas de schéma prédéfini. Vous pouvez modifier les types et les champs de données à la volée. Lorsque des bases de données NoSQL sont utilisées, elles garantissent que les données sont toujours disponibles en en répliquant des copies sur plusieurs serveurs. Il est utilisé pour répliquer une base de données NoSQL de deux manières : primaire/secondaire et peer-to-peer. Les API de chaque modèle de données NoSQL, telles que les modèles clé-valeur, document, tabulaire et graphique, leur sont propres.
Les SGBDR sont conçus pour lire, écrire et distribuer des données, tandis que les bases de données NoSQL sont conçues pour lire, écrire et distribuer des données. MongoDB, par exemple, prend en charge les écritures et les lectures sur tous les nœuds d'un cluster NoSQL, comme Cassandra. De nombreux principes de NoSQL, tels que l'architecture de système distribué et SQL, sont désormais utilisés dans les bases de données newSQL.
Les bases de données NoSQL peuvent également être mises à l'échelle verticalement pour accueillir un plus grand nombre d'utilisateurs. Les mécanismes de réplication et de tolérance aux pannes sont deux moyens clés d'atteindre l'évolutivité. En conséquence, les données peuvent être stockées sur plusieurs serveurs afin de réduire les risques de panne.
Une base de données NoSQL est également disponible en forte demande. Ils ont un faible taux de défaillance et peuvent supporter des charges élevées. En raison de leur faible latence et de leur débit, ils constituent d'excellents choix pour les applications nécessitant un débit élevé.
Les avantages des bases de données non relationnelles
Quels sont les avantages de ne pas utiliser de systèmes de bases de données relationnelles ?
Il existe de nombreux avantages à utiliser une base de données non relationnelle plutôt qu'une base de données relationnelle. Une base de données non relationnelle est le meilleur choix pour le développement rapide d'applications. Il est plus pratique d'y stocker des données car ils sont souvent plus rapides à exécuter et ont une plus grande vitesse. Cependant, ils sont plus adaptables et rapides à travailler, de sorte qu'ils peuvent être gérés sans difficulté.
Qu'est-ce que le type de données dans Nosql ?
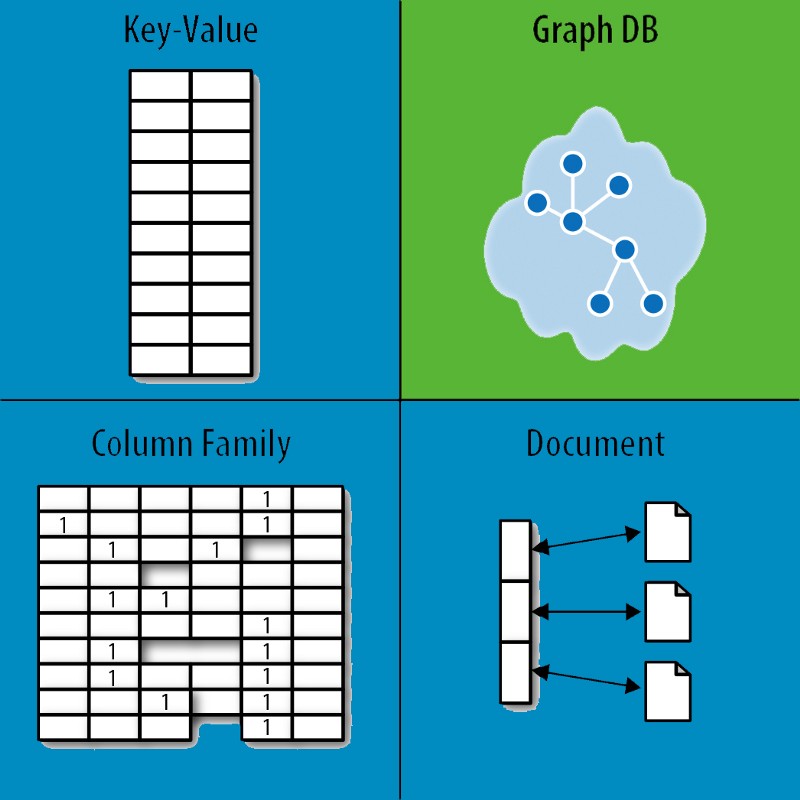
Un système NoSQL est défini comme toute alternative à la base de données SQL traditionnelle. Les bases de données SQL et les bases de données NoSQL sont des bases de données très différentes. Ils ont créé leur modèle de données d'une manière différente des modèles de table de lignes et de colonnes traditionnels utilisés dans les systèmes de gestion de bases de données relationnelles (RDBMS).
Une base de données NoSQL est composée de quatre types : les magasins clé-valeur, les magasins de documents, les bases de données orientées colonnes et les bases de données de graphes . Une base de données relationnelle ne peut pas résoudre un problème avec n'importe quel type de solution. OrientDB, par exemple, est une base de données qui combine des types NoSQL et multi-modèles. Il existe de nombreux types d'entités et options de liaison de tables pour une base de données relationnelle à grande échelle. Toutes les entités (personnes) sont représentées dans une ligne répartie sur plusieurs colonnes. Les colonnes sont stockées séparément dans une base de données de colonnes, ce qui facilite leur recherche lorsqu'il n'y a que quelques colonnes impliquées. L'index trace les lignes et les colonnes sur les données, tandis que la base de données de colonnes trace les lignes et les colonnes sur les données.
Un magasin clé-valeur, contrairement à une base de données NoSQL, est le moins complexe. Ils peuvent stocker des documents de tous les jours d'une manière qui les rend faciles à interroger et à calculer, et ils stockent les documents tels quels. La normalisation n'est pas importante pour les magasins de documents tant que les données sont correctement structurées. L'objectif des bases de données graphiques est de faciliter le suivi des relations entre les entités. Les bases de données de graphes sont composées de deux composants principaux : les données et la structure. L'entité dans son ensemble. Une arête est une propriété de deux entités représentées par des lignes. Les magasins de documents et les magasins de valeurs-clés adhèrent à BASE, tandis que les bases de données de graphes telles que Neo4j prétendent respecter ACID.
Stockage de données flexible avec Json
Étant donné que les documents JSON sont flexibles et simples à utiliser, ils constituent un type de données populaire dans les bases de données NoSQL. JSON est un type de stockage de données similaire à une feuille de calcul, sauf qu'il est stocké dans des lignes et des colonnes plutôt que dans des lignes et des colonnes. C'est idéal pour stocker des données semi-structurées, qui ne nécessitent pas de procédure d'organisation spécifique.
Nosql est-il des données non structurées ou des données semi-structurées ?
Une base de données NoSQL est généralement adaptée au traitement de données semi-structurées, de données entièrement non structurées, de documents, de graphiques ou de schémas dynamiques. Alors que les SGBDR traditionnels peuvent gérer des données hautement structurées, les bases de données NoSQL le font généralement à des niveaux semi- ou entièrement structurés.
Il existe de nombreux types de données différents, allant des feuilles de calcul aux fichiers texte et vidéo aux fichiers audio. Les données structurées sont un type de données qui a été prédéfini afin qu'elles puissent être stockées dans le stockage d'une manière spécifique. Comme elles ne contiennent pas de modèle de données prédéfini, les données non structurées ne sont pas stockées dans une base de données relationnelle. Le terme données non structurées fait référence à des données non structurées qui ne sont pas structurées, mais qui contiennent des métadonnées qui permettent aux utilisateurs d'identifier une structure partielle ou hiérarchique. Les scientifiques et ingénieurs qui utilisent le Machine Learning ou l'Intelligence Artificielle extraient du sens de ce type de données en utilisant des techniques à la fois efficaces et profondes. Un fichier de données semi-structuré comprend des e-mails et d'autres documents qui sont dans le même format mais contiennent des métadonnées qui permettent aux utilisateurs d'accéder aux informations à un niveau spécifique. Dans cet article, nous examinerons quelques exemples concrets pour chaque type de données et discuterons de leurs principales applications dans les organisations modernes.

Les données structurées sont généralement stockées dans une base de données et des entrepôts de données sont également inclus. Parce qu'il leur manque un schéma défini qui doit être suivi pour un attribut donné, les données non structurées sont stockées dans une base de données Data Lakes ou une base de données non relationnelle. Les bases de données NoSQL modernes, telles que MongoDB, sont utilisées pour stocker des données semi-structurées (avec structure ou hiérarchie) d'une manière ou d'une autre.
Ce type de base de données offre des avantages tels qu'un développement plus rapide et un modèle de données plus flexible, ce qui en fait un choix populaire. MongoDB, la solution NoSQL leader, est particulièrement efficace pour archiver des données non structurées. Par conséquent, son modèle de données de document stocke toutes les données associées dans un seul document, ce qui est beaucoup plus flexible qu'un modèle de base de données relationnelle rigide. Par conséquent, MongoDB est un excellent choix pour les données non structurées et semi-structurées.
Les nombreux avantages des données semi-structurées
Les données semi-structurées, comme leur nom l'indique, ne rentrent parfaitement dans aucune des catégories suivantes : structure, quantité ou composition. Les deux types de données peuvent être considérés comme mixtes et appariés. Les types de données semi-structurées pouvant être stockées sont JSON, XML et texte.
Bases de données Nosql
Une base de données NoSQL fournit un mécanisme de stockage et de récupération des données qui utilise des modèles de cohérence plus lâches que les bases de données relationnelles traditionnelles. Les bases de données NoSQL sont souvent plus évolutives et offrent de meilleures performances.
Contrairement aux bases de données traditionnelles , les bases de données NoSQL sont plus flexibles. Les bases de données NoSQL stockent les données dans la même structure de données que les autres types de bases de données, telles que les documents. Une base de données non relationnelle peut être utilisée pour gérer des ensembles de données volumineux et généralement non structurés en raison de son faible niveau de relationnalité. Les systèmes de base de données NoSQL ne nécessitent pas la connexion de tables. Les bases de données NoSQL vous permettent de stocker un large éventail de structures de données, ce qui les rend utiles dans l'analyse de données, les réseaux sociaux et les applications mobiles. Il y a plusieurs avantages à chaque type de base de données, mais NoSQL et les bases de données relationnelles sont utilisées en grand nombre par les entreprises. Les bases de données de documents contiennent des données sous forme de documents, qui sont synchronisés les uns avec les autres lorsqu'ils sont utilisés dans des applications.
Les bases de données documentaires sont fréquemment utilisées par les systèmes de gestion de contenu ainsi que par les profils d'utilisateurs. Les informations sont stockées dans des colonnes dans de grandes bases de données, ce qui permet aux utilisateurs d'accéder facilement à des colonnes spécifiques. Apache HBase et Apache Cassandra, par exemple, sont deux exemples de ce type de base de données. Une base de données de graphes gère et stocke un réseau de connexions entre des éléments de graphe. Étant donné que les données sont stockées en mémoire plutôt que sur le disque, elles sont accessibles plus rapidement qu'avec les bases de données traditionnelles sur disque. Il est avantageux d'avoir une application basée sur des microservices, car elle élimine le besoin d'un seul magasin de données partagé entre plusieurs applications. En conséquence, IBM peut fournir une large gamme de bases de données NoSQL et NoSQL pour un large éventail d'applications. IBM Data Management Platform for MongoDB Enterprise Advanced est un composant d'IBM Cloud Pak for Data Suite. Apache CouchDB, PouchDB et d'autres bibliothèques de développement Web et mobiles populaires sont tous pris en charge par le service, qui fait partie d'un écosystème open source.
Quelle est la meilleure façon de créer un schéma pour une base de données NoSQL ? Lors de la création d'un schéma pour une base de données NoSQL, la structure native de la base de données peut servir de point de départ. De plus, vous pouvez créer le schéma à l'aide d'un éditeur de schéma.
Bases de données Nosql : avantages et inconvénients
Les bases de données NoSQL sont parfois comparées aux bases de données SQL, qui sont plus couramment utilisées par les entreprises. Les bases de données NoSQL sont également utiles pour les applications qui stockent les données d'une manière différente de celle que SQL peut gérer.
Les bases de données de documents, par exemple, peuvent stocker des données aux formats JSON ou XML. Lors du stockage de données dans des magasins clé-valeur, deux paires clé-valeur doivent être présentes. Les données sont stockées dans des colonnes de largeur variable dans des magasins à colonnes larges, ce qui les rend idéales pour stocker des données qui ne sont pas bien définies ou qui nécessitent un accès rapide. Les données peuvent être stockées dans des bases de données de graphes afin de représenter les relations entre différentes entités en affichant des graphes.
Les bases de données SQL, en revanche, ne sont pas aussi puissantes que les bases de données NoSQL. De plus, les bases de données SQL sont nettement plus chères et ne peuvent gérer qu'un nombre limité de transactions. Par conséquent, les données non structurées, souvent difficiles à stocker dans une base de données relationnelle, sont plus susceptibles d'être traitées par ces systèmes.
Il existe cependant quelques limitations aux bases de données NoSQL. Les bases de données SQL sont clairement définies et bien mieux adaptées aux transactions multi-lignes, alors que ces bases de données peuvent ne pas être aussi bien adaptées. De plus, ils sont plus difficiles à apprendre que les bases de données SQL.
Magasins de données
Les magasins de données sont des référentiels de données accessibles par les ordinateurs. Ils peuvent être divisés en deux types principaux : les magasins de données actifs, qui sont utilisés pour stocker les données activement utilisées par les applications, et les magasins de données passifs, qui sont utilisés pour stocker les données qui ne sont pas activement utilisées par les applications. Les magasins de données peuvent être divisés en deux sous-types : les magasins de données relationnelles, qui stockent les données dans un format tabulaire, et les magasins de données non relationnelles, qui stockent les données dans un format non tabulaire.
Qu'entend-on par magasin de données ?
Un magasin de données est une connexion qui existe entre deux ou plusieurs magasins de données, que les données soient stockées dans une base de données ou dans un ou plusieurs fichiers. Le magasin de données, ou il peut s'agir de la source de données d'un processus, ou il peut s'agir de la source des résultats Staged Data d'un processus vers un magasin de données.
L'importance du stockage primaire
Il s'agit du stockage principal de l'ordinateur, qui stocke les données, les programmes et les instructions en cours d'utilisation. En raison du stockage principal de la carte mère, elle peut lire et écrire des données extrêmement rapidement. Un serveur est un ordinateur qui reçoit et stocke les données de plusieurs clients sur un réseau. Il est stocké sur un disque pour un accès à long terme aux fichiers. Le stockage peut être inclus en tant que composant d'un système de serveur ou il peut être séparé du serveur.
Modèles de base de données de graphes courants
Il existe trois modèles de base de données de graphes courants : le modèle de graphe de propriétés, le modèle de cadre de description des ressources et le modèle de triple magasin. Le modèle de graphe de propriétés est le modèle le plus populaire et est utilisé par de nombreuses bases de données de graphes, y compris Neo4j. Le modèle de cadre de description des ressources est un modèle standard pour stocker des données dans une base de données de graphes et est utilisé par des bases de données telles qu'AllegroGraph. Le modèle triple store est un modèle simple utilisé par de nombreuses bases de données de graphes, y compris Virtuoso.
Mongodb : une base de données de graphes ?
MongoDB est une base de données de graphes.