
Bases de données NoSQL : grande table
Publié: 2023-01-04Les bases de données NoSQL deviennent de plus en plus populaires en raison de leur flexibilité, de leur évolutivité et de leurs performances. Une base de données NoSQL ne nécessite pas de schéma prédéfini et peut stocker des données dans n'importe quel format. Cela le rend idéal pour les applications qui doivent stocker de grandes quantités de données en constante évolution. Big table est un type de base de données NoSQL conçu pour stocker de grandes quantités de données. Big table est utilisé par de nombreuses grandes organisations, telles que Google, Facebook et Amazon. La grande table est hautement évolutive et peut gérer des milliards de lignes et des millions de colonnes. Big table est également très rapide et peut fournir un accès en temps réel aux données.
Google a publié une série de mises à jour généralement disponibles pour son service de base de données Cloud Bigtable . Grâce aux nouvelles mises à jour, jusqu'à cinq fois plus d'espace de stockage est désormais disponible par nœud. Google a également ajouté des fonctionnalités de mise à l'échelle automatique améliorées qui permettent à un cluster de bases de données d'augmenter ou de réduire automatiquement en fonction de ses besoins. Une nouvelle métrique d'utilisation du processeur et un routage de groupe de clusters permettent une plus grande visibilité sur la façon dont les ressources d'une application sont utilisées. En raison de la séparation du calcul et du stockage, chaque type de ressource peut être mis à l'échelle de manière indépendante dans Bigtable. Les utilisateurs peuvent désormais gérer facilement les déploiements à haute disponibilité et améliorer la gestion de la charge de travail grâce aux nouvelles fonctionnalités.
NoSQL est un choix populaire pour stocker de grandes quantités de données. Ce type de base de données devient de plus en plus populaire parmi les entreprises Web aujourd'hui. Les partisans des solutions NoSQL affirment qu'elles offrent une évolutivité plus simple et des performances accrues que les bases de données traditionnelles.
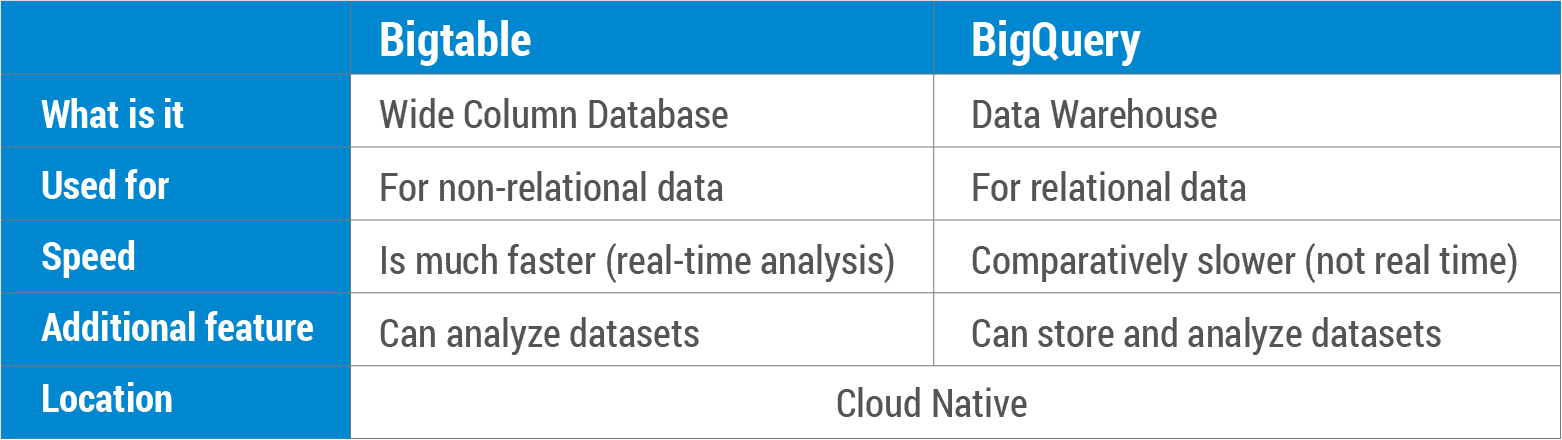
Bigtable est un type de service de base de données NoSQL qui peut être utilisé à la fois par les développeurs et les administrateurs de base de données. BigQuery est un hybride, car il utilise des dialectes SQL et est basé sur la technologie de traitement de données de Google, Dremel.
Est-ce que Bigtable SQL ou Nosql ?
Il n'y a pas de réponse définitive à cette question car cela dépend de la façon dont vous définissez chaque terme. Cependant, si nous prenons une définition large de SQL comme toute base de données qui utilise un langage de requête structuré, et NoSQL comme toute base de données qui n'utilise pas de langage de requête structuré, alors Bigtable serait considérée comme une base de données NoSQL.
Qu'est-ce qu'une comparaison entre Bigtable et BigQuery ? Bigtable est une base de données NoSQL qui vous permet de stocker des données de manière sécurisée et évolutive. BigQuery est un entrepôt de données relationnel qui stocke d'énormes quantités de données dans une base de données SQL. Bigtable a été intégré aux produits de Google tels que Analytics, Finance, Recherche personnalisée, Earth et Writely pour leurs opérations quotidiennes. Bigtable, une base de données NoSQL de données mutables , fonctionne bien avec les scénarios OLTP. BigQuery est un entrepôt de données SQL relationnel qui peut être utilisé pour les applications OLAP. Bigtable et BigQuery sont natifs du cloud, avec des accords de niveau de service de pointe. De plus, ils offrent une sauvegarde automatique (avec réplication) ainsi qu'une évolutivité infinie, un partitionnement automatique et une récupération automatique en cas de panne (avec réplication).
BigQuery, plutôt qu'une base de données NoSQL, ne le fait pas.
Quel type de base de données Nosql est Bigtable ?
Cloud Bigtable est une base de données NoSQL qui peut être utilisée pour analyser des données et exécuter des opérations. C'est une alternative à HBase, qui est un système de base de données en colonnes utilisant HDFS. Les applications avec une bande passante inférieure à 10 Mo conviennent à Cloud Bigtable, qui peut prendre en charge un haut niveau de débit et d'évolutivité.
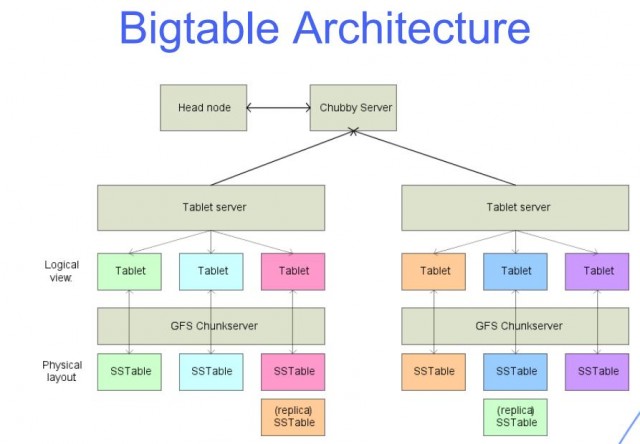
Les bases de données Big Table, comme on les appelle, sont un sous-ensemble des bases de données NoSQL. Bigtable, une application de Google, est similaire à Kleenex. Les bases de données Bigtable sont la norme du secteur en matière d'imitation et d'inspiration. Bien que l'article concerne principalement Bigtable, il examine également d'autres bases de données NoSQL. Bigtable a été conçu principalement pour un usage interne par Google, sans accès extérieur. Bigtable a été présenté à Google en 2004 et a depuis été utilisé par plus de 60 applications Google. Une implémentation Bigtable nécessite un serveur maître pour suivre les tablettes sur un cluster d'autres serveurs.
L'Apache Software Foundation a contribué à un certain nombre d'excellentes initiatives techniques, notamment dans le domaine des bases de données. Accumulo et HBase utilisent les mêmes principes de conception que Google Bigtable, mais dans un format disponible dans le commerce. Actuellement, Apache HBase exécute le système de messagerie de Facebook et est étroitement intégré à Hadoop, ce qui lui permet de traiter de grands ensembles de données. La base de données Hypertable est basée sur Bigtable, qui est une simple base de données tabulaire. Hypertable fonctionne de la même manière que Hadoop et HFS. Baidu, l'un des plus grands moteurs de recherche de Chine, est l'un des principaux sponsors d'Hypertable. Les clients incluent des sites d'enchères en ligne tels qu'eBay, Groupon et Rediff.com, ainsi que des détaillants hors ligne tels que Lowe's et TJ Maxx.
Hadoop est une plate-forme logicielle open source qui permet aux utilisateurs de stocker et de traiter efficacement d'énormes quantités de données. Cela active les bases de données NoSQL, ce qui peut réduire la quantité de données requises pour le stockage sur des serveurs uniques. Une base de données NoSQL, en revanche, ne nécessite pas de schéma fixe car elle est axée sur l'évolutivité. Pour cette raison, ils constituent un excellent choix pour stocker des quantités massives de données de manière distribuée.
À quel type de magasin de données Nosql appartient Bigtable ?
L'une des rares fonctionnalités disponibles sur le marché générique. À son niveau le plus élémentaire, Bigtable est une base de données NoSQL qui couvre un large éventail de colonnes.
'est-ce que la base de données en colonnes Bigtable ?
Les magasins à colonnes larges tels que Bigtable et Apache Cassandra ne sont pas des colonnes au sens traditionnel du terme car ils n'utilisent pas du tout de structures de données en colonnes aux deux niveaux.
Bigtable est-il une base de données non relationnelle ?
Il n'y a pas de réponse définitive à cette question car cela dépend de la façon dont vous définissez une "base de données non relationnelle". Bigtable est un magasin de données orienté colonne, que certaines personnes considèrent comme un type de base de données NoSQL. Cependant, il prend en charge les transactions et l'indexation, qui sont généralement associées aux bases de données relationnelles. Donc, cela dépend vraiment de la façon dont vous définissez une base de données non relationnelle.
L'instruction CREATE EXTERNAL TABLE peut être utilisée pour créer une table dans BigQuery en spécifiant une table à partir de laquelle extraire les données. L'option uri peut être utilisée pour spécifier une table à partir de laquelle extraire des données. Le schéma de table inclut le nom de la table, le type de table, les noms de colonne et les types de données, ainsi que le schéma de table de l'option bigtable_options.
Si vous utilisez MySQL, l'outil d'importation BigQuery peut être utilisé pour importer automatiquement les données d'une table MySQL dans BigQuery. Un nom de table et une famille de colonnes sont saisis dans l'outil, qui importe les données dans une table BigQuery.
Lorsque vous utilisez la console Google Cloud, vous devez saisir manuellement le nom de la table et les paramètres de qualification de la famille de colonnes. L'importation de données à partir de diverses sources est possible sur la plate-forme Google Cloud, notamment MySQL, PostgreSQL, MongoDB et Redis.
Principales caractéristiques de Bigtable
Quelles sont les fonctionnalités de Bigtable ?
La vitesse de lecture et d'écriture de Bigtable, son évolutivité massive et sa capacité à gérer de grandes quantités de données ne sont que quelques-unes de ses nombreuses fonctionnalités. De plus, comme Bigtable est une base de données NoSQL, les requêtes SQL ne sont pas prises en charge. Cela élimine le besoin d'effectuer des opérations SQL dans des bases de données distinctes.
Bigtable est-il une base de données ?
Bigtable n'est pas une base de données relationnelle. Il s'agit d'un système de stockage distribué pour la gestion de données structurées conçu pour évoluer à une très grande taille : des pétaoctets de données sur des milliers de serveurs de base. Google utilise Bigtable pour alimenter nombre de ses services à grande échelle, tels que Google Analytics et Google Maps.
Cloud BigTable fournit un ensemble unique de fonctionnalités, lui permettant d'évoluer jusqu'à plus de 100 000 colonnes et des milliards de lignes. Il prend en charge le stockage d'environ pétaoctets et téraoctets de données. Par rapport à BigTable, il a une latence très faible, mais il a également le potentiel de stocker une grande quantité de données. BigTable peut stocker des données structurées dans des colonnes, ce qui lui permet de gérer les services Web et les données de recherche Internet de l'entreprise. Des algorithmes de compression sont également utilisés pour augmenter la capacité du système. BigTable dispose de serveurs back-end percutants qui offrent de meilleurs avantages que l'installation HBase autogérée incluse avec BigTable. Les lignes de la BigTable partagent la même bordure, elles sont donc également appelées blocs.
Ces appareils, appelés « tablettes », vous aident à gérer votre charge de travail de requête. Le système de fichiers basé sur le cloud de Google, Colossus, est utilisé pour stocker toutes les tablettes. Toutes les opérations d'écriture dans BigTable sont stockées dans le journal partagé de Colossus, tout comme les fichiers SSTable. Les sept fonctionnalités clés de BigTable sont essentielles au succès d'une entreprise. BigTable a le potentiel de personnaliser, d'accélérer et d'automatiser votre vie de différentes manières. les lignes et les colonnes sont les deux dimensions des données dans BigTable. Chaque ligne contient un identificateur ou un index unique accessible à l'aide de la clé de ligne unique.
Chacune des colonnes d'une famille possède une colonne de qualification. L'utilisation d'unités de qualification de colonne, telles que les clés de ligne, facilite l'identification des colonnes. En ce qui concerne les bases de données, BigTable est connue comme une base de données clairsemée. Chacune des versions d'horodatage de BigTable est représentée par une cellule, qui est l'une des dimensions de la structure de carte 3D. Cette puissante base de données, qui peut être personnalisée et sensible à la vitesse, peut être utilisée pour alimenter des sites Web et des applications mobiles. Si vous repensez au passé, vous pouvez déterminer quelles interactions ont donné les meilleurs résultats. Cela vous aidera à mettre en œuvre davantage d'analyses de données et conduira à un meilleur service client.
Google Cloud Bigtable, une base de données NoSQL open source, est intégrée au cloud de Google. Le fait qu'il soit compatible avec tant d'écosystèmes Big Data et Hadoop existants signifie qu'il peut être utilisé pour des données non structurées ou des données nécessitant une faible latence.
Bigtable : un excellent choix pour les applications gourmandes en données
Bigtable, un service de base de données NoSQL, est utilisé pour les charges de travail analytiques et opérationnelles volumineuses. En conséquence, c'est un excellent choix pour les applications gourmandes en données et en temps réel. De plus, comme il est orienté colonne, il est idéal pour stocker des données en trois dimensions.
Bigtable contre Mongodb
Il existe quelques différences essentielles entre Bigtable et MongoDB. Premièrement, Bigtable est une base de données orientée colonnes, tandis que MongoDB est une base de données orientée documents. Cela signifie que dans Bigtable, les données sont stockées dans des colonnes, tandis que dans MongoDB, les données sont stockées dans des documents. Deuxièmement, Bigtable ne prend pas en charge les index secondaires, contrairement à MongoDB. Cela signifie que si vous souhaitez interroger des données dans Bigtable, vous devez connaître la colonne spécifique que vous souhaitez interroger. Dans MongoDB, vous pouvez interroger n'importe quel champ d'un document. Enfin, Bigtable est conçu pour évoluer horizontalement, tandis que MongoDB est conçu pour évoluer verticalement. Cela signifie que dans Bigtable, vous pouvez ajouter plus de machines à votre cluster pour augmenter la capacité, tandis que dans MongoDB, vous pouvez ajouter plus de RAM et de CPU à votre serveur pour augmenter la capacité.
Cloud Bigtable de Google : pas seulement pour le Big Data
Bigtable est toujours un composant de l'infrastructure de Google, ayant été créé en 2007. Bien que Cloud Bigtable soit idéal pour stocker de grandes quantités de données avec une faible latence, il n'est pas idéal pour les données qui ne nécessitent pas d'accès fréquent. Cloud Bigtable, par exemple, ne conviendrait pas à un lac de données.
Base de données Bigtable
Une base de données bigtable est une base de données qui utilise une structure de données bigtable . Une bigtable est un système de stockage distribué pour les données structurées qui est conçu pour évoluer jusqu'à une très grande taille.
Une grande table est une table qui comporte de nombreuses lignes et colonnes et qui est généralement peu peuplée. Bigtable est idéal pour les grands ensembles de données en raison de sa faible latence et de sa haute densité. Cette source de données est idéale pour les opérations MapReduce car elle prend en charge un débit de lecture-écriture élevé à faible latence et est idéale pour les grands ensembles de données. Les données d'une table Bigtable sont divisées en blocs de lignes contiguës, chacune étant appelée une tablette, afin de réduire la charge des requêtes. Le format SSTable est utilisé pour stocker les tablettes Google dans Colossus, le système de fichiers de l'entreprise. Chaque tablette est liée à un nœud spécifique dans l'instance Bigtable, également appelé nœud. L'ajout de nœuds à un cluster peut augmenter la capacité du cluster à gérer plusieurs demandes simultanées.
Chaque ligne contient une combinaison de la famille de colonnes, de l'identifiant de colonne et de l'horodatage, essentiellement un tableau d'entrées de clés/valeurs. La grande majorité du temps, Bigtable convertit toutes les données en chaînes d'octets brutes. Étant donné que Bigtable stocke les mutations de manière séquentielle et ne les compacte qu'une fois tous les quelques mois, les mutations occupent plus d'espace de stockage lorsqu'elles sont remplacées par une ligne. Bigtable compresse les données à l'aide d'un algorithme intelligent et utilise une technologie de compression. Les délétions étant un type de mutation spécialisé, elles nécessitent un espace de stockage supplémentaire à court terme. Les méthodes de stockage propriétaires de Google lui permettent de résister à l'épreuve du temps pour les données au-delà de la plage de réplication HDFS standard à trois voies. Les utilisateurs peuvent accéder à vos tables Bigtable à l'aide des rôles qui leur sont attribués par votre projet Google Cloud et Identity and Access Management (IAM). La majorité des données Google Cloud sont chiffrées au repos à l'aide des mêmes systèmes de gestion de clés renforcées que nous utilisons pour nos données chiffrées. Une sauvegarde peut être utilisée pour enregistrer une copie du schéma et des données de la table, ainsi que pour restaurer ultérieurement la sauvegarde dans une nouvelle table.
La Bigtable est un système de stockage distribué bien conçu, capable de stocker jusqu'à des pétaoctets de données. Parce qu'il est simple à utiliser, c'est un excellent choix pour le stockage de données à grande échelle .

La puissance du cloud Bigtable
La base de données Cloud Bigtable peut contenir des dizaines de milliers de lignes et de colonnes et est accessible depuis n'importe où dans le monde. En conséquence, il est bien adapté au stockage de données à grande échelle. Cloud Bigtable est désormais disponible sur Google Cloud depuis le 6 mai 2015. Cela a permis de diffuser plus de 10 EXAoctets de données et de traiter plus de 5 milliards de requêtes par seconde depuis lors. En conséquence, Cloud Bigtable est toujours utilisé et constitue un outil précieux pour le stockage de données.
Bigtable contre Cassandre
Chaque nœud est choisi pour les opérations de lecture et d'écriture en utilisant sa propre méthode. Dans Cassandra, une clé de partition est identifiée, alors que dans Bigtable, une clé de ligne est utilisée. La politique d'équilibrage de charge de Cassandra est d'abord inspectée par le client.
Des systèmes de bases de données tels que Bigtable et Cassandra sont distribués. Ils créent des magasins de valeurs-clés multidimensionnels capables de traiter des dizaines de milliers de requêtes par seconde (RPS). L'objectif de ce document est d'expliquer les différences et les similitudes entre les deux systèmes de base de données. Bigtable contient de nombreuses fonctionnalités principales décrites dans Bigtable. L'article décrit un système de stockage distribué pour des données structurées. Lorsque Bigtable identifie l'attribution de plage comme requise pour un ensemble de données, les plages de données d'un nœud de traitement sont simples à modifier, car la couche de stockage est séparée de la couche de traitement. De plus, Bigtable permet la réplication asynchrone entre des clusters distribués géographiquement dans des topologies jusqu'à quatre.
La tolérance aux pannes est fournie par Cassandra, qui est corrélée au niveau de cohérence. À l'aide d'une stratégie de topologie de réplication de données configurable, vous pouvez définir la réplication géographique. Dans la plupart des topologies de centres de données multiples, QUORUM (ou LOCAL_QUORUM) est le paramètre par défaut. La majorité des réponses d'un nœud de réplique au nœud coordinateur est requise pour que ce paramètre de niveau soit considéré comme réussi. Les répliques de données dans Cassandra peuvent être améliorées en termes de tolérance aux pannes en utilisant des configurations de centre de données et de rack. La topologie détermine les nœuds nécessaires pour garantir la cohérence lors des opérations de lecture et d'écriture. L'instance Bigtable peut avoir un ou plusieurs clusters, ou elle peut avoir une collection de jusqu'à quatre clusters répliqués.
Bigtable et Cassandra fonctionnent tous deux comme des magasins à colonnes larges NoSQL. La clé de ligne détermine l'ordre dans lequel le tri global des données d'une table s'affiche dans Bigtable. Dans Bigtable, les nœuds sont utilisés pour équilibrer la responsabilité des plages de clés, communément appelées tablettes. Le service Bigtable n'applique pas les types de données de colonne envoyés par le client. La famille de colonnes Bigtable sélectionne les colonnes d'une table qui doivent être stockées et récupérées de l'une à l'autre. Chaque table doit avoir au moins une famille de colonnes, mais les tables en ont souvent plus (le nombre maximum de colonnes qu'une table peut avoir est de 100). Une clé de ligne se trouve dans une cellule et un nom de colonne se trouve dans l'autre.
Cassandra et Bigtable utilisent des méthodes différentes pour choisir le nœud de traitement pour les opérations de lecture et d'écriture. Dans Cassandra, la clé de partition est distinguée, alors que dans Bigtable, la clé de ligne est utilisée. En créant une stratégie multicluster, une stratégie d'équilibrage de charge qui tient compte des centres de données offre les avantages du basculement. Les deux bases de données ont été optimisées pour une écriture rapide, et elles utilisent un processus similaire pour le faire. Les deux bases de données stockent les données dans des fichiers SSTable, qui sont des fichiers immuables. Dans Cassandra, plusieurs répliques doivent être contactées avant que le coordinateur n'informe le client que l'écriture est terminée. Étant donné que chaque clé de ligne dans Bigtable n'est attribuée qu'à un seul nœud, une réponse de ce nœud est requise pour confirmer qu'une écriture a réussi.
À la suite de la fusion SSTable, les deux bases de données peuvent exclure des cellules. Lors du retour de données à Cassandra, la clause WHERE dans une requête CQL limite le nombre de lignes. Seul le nœud en charge de la plage de clés doit être consulté lors de l'utilisation de Bigtable. Les résultats de lecture d'un nœud peuvent être limités de diverses manières. Lors d'une phase de compactage, Bigtable et Cassandra stockent les données dans des SSTables, qui sont régulièrement fusionnées. Bigtable ne limite pas le nombre de versions d'horodatage pour chaque cellule, mais d'autres tailles de ligne peuvent le faire. La réplication fournie par Colossus garantit une grande pérennité des données.
L'interface de ligne de commande de Bigtable, ainsi que ses bibliothèques clientes pour une variété de langages de programmation courants, complètent les capacités de Cassandra. Chaque nœud de Bigtable doit servir une série de SSTables contenant des données stockées sur ces tables. Vous n'avez plus besoin de calculer les instances dupliquées de stockage dans Bigtable comme vous le feriez dans Cassandra pour déterminer la taille du cluster. Les instances Bigtable stockent généralement les données sur des disques SSD ou des disques durs (HDD). Contrairement à Cassandra, qui repose sur la théorie selon laquelle il n'y a pas de perte de densité de stockage pour atteindre la tolérance aux pannes, la charge de travail ne perd pas de densité. Il est simple d'augmenter ou de réduire une instance Bigtable selon les besoins pour répondre aux exigences de la charge de travail tout en minimisant les efforts et les temps d'arrêt. Une instance ne peut avoir que quatre clusters, mais ils peuvent être regroupés dans n'importe quelle région cloud prise en charge sur la planète.
Pour créer une métrique pour chaque nœud QPS, Google recommande d'utiliser les performances de Bigtable avec des données et des requêtes représentatives. Bigtable inclut des composants gérés pour les fonctions d'administration courantes de Cassandra. Une table qui fait partie du cluster est créée en tant que copie restaurable de la table dans une sauvegarde bigtable. Le prix d'une sauvegarde est inférieur à celui de Cloud Storage ou ne consomme pas de ressources de nœud. Une autre option consiste à utiliser une exportation de données gérées vers Cloud Storage pour sauvegarder Bigtable. Bigtable gère facilement les tâches de maintenance internes courantes de Cassandra, telles que les correctifs du système d'exploitation, la récupération des nœuds, la réparation des nœuds, la surveillance du compactage du stockage et la rotation des certificats SSL. Les tableaux de bord sont prédéfinis pour suivre les métriques de débit et d'utilisation au niveau de l'instance, du cluster et de la table sur la page de la console Bigtable Google Cloud. Vous pouvez utiliser le tableau de bord de surveillance pour effectuer un réglage avancé des performances.
SQL est utilisé dans Bigtable, tout comme l'accès par clé de ligne aux données d'une base de données NoSQL. Les nœuds sont répartis sur le réseau et les commérages sont utilisés pour maintenir la cohérence du réseau. Avec ce système, la capacité de stockage des données est augmentée et la disponibilité est maintenue sans un seul point de défaillance.
Bigtable, en revanche, est plus évolutif et offre un meilleur niveau de disponibilité que Cassandra. Bigtable est également plus convivial que les autres langages de programmation, ce qui en fait un excellent choix pour les ensembles de données disposant de moins de ressources.
Google utilise-t-il toujours Bigtable ?
Google Analytics, l'indexation Web, MapReduce et de nombreuses autres applications Google, telles que Google Maps, Google Books, My Search History, Google Earth, Blogger.com, l'hébergement Google Code, l'utilisent pour générer et modifier les données stockées dans Bigtable, Google Maps , Google Livres, Ma recherche
Google utilise-t-il Cassandre ?
La topologie DataStax Astra Cassandra as a Service a été déployée sur Google Cloud à l'aide du système d'exploitation TensorFlow, ainsi que du système d'exploitation Apache Cassandra dans trois zones Google Cloud.
Bigtable est-il identique à Hbase ?
Un horodatage Bigtable est stocké en microsecondes, tandis qu'un horodatage HBase est stocké en millisecondes. Cette distinction peut être utile lors de l'utilisation de la bibliothèque cliente HBase pour Bigtable et de l'examen des horodatages inversés.
À quoi sert Bigtable ?
La base de données Bigtable NoSQL est une base de données à larges colonnes idéale pour une utilisation dans une base de données NoSQL. Le système est optimisé pour fournir une faible latence, un grand nombre de lectures et d'écritures et des performances élevées à grande échelle. L'utilisation de cas de table est généralement limitée à une échelle ou à un débit spécifique qui nécessite une latence élevée, comme l'Internet des objets (IoT), AdTech, FinTech, etc.
Bigtable contre BigQuery
Il existe quelques différences essentielles entre bigtable et bigquery. Bigtable est conçu pour être une base de données évolutive orientée colonnes, tandis que bigquery est conçu pour être une base de données relationnelle évolutive. Bigtable n'est pas compatible avec SQL, contrairement à bigquery. Bigtable n'est pas aussi largement utilisé que bigquery, mais il présente certains avantages par rapport à bigquery, comme la possibilité de s'adapter à un plus grand nombre de colonnes et de lignes.
Google a fait des progrès significatifs dans le stockage en nuage de données massives au fil des ans. Bigtable est un service de base de données NoSQL entièrement géré à l'échelle du pétaoctet, basé sur l'administration de base de données orientée objet (OOPA). BigQuery est construit à l'aide de Bigtable et de Google Cloud Platform, ainsi que du système de base de données Dremel de Google. Il existe trois différences majeures entre BigQuery et Bigtable. Une solution Big Data as a Service (BaaS) est une solution fournie par Google Cloud BigQuery. BigQuery est utilisé par des produits Google tels que Analytics, Finance, Recherche personnalisée, Earth, Orkut et Writely. Lorsque le traitement de données ultra-rapide de BigQuery est utilisé, 35 milliards de lignes peuvent être traitées en quelques secondes.
Une base de données NoSQL est un acronyme pour un service de base de données ; en d'autres termes, ce n'est pas une base de données relationnelle. Les colonnes de clé peuvent être de taille multiple et les barres de clé peuvent défiler horizontalement. Les éléments de données individuels avec une plus grande capacité de stockage de 10 mégaoctets peuvent nuire aux performances. Si vous avez besoin d'une solution de stockage complète pour des objets non structurés (par exemple, des fichiers vidéo), le stockage dans le cloud est probablement une meilleure option. C'est un excellent choix pour les requêtes nécessitant une analyse de table ou pour consulter une grande base de données en une seule fois. Il est impossible qu'un objet importé change au cours de sa durée de vie dans BigQuery, et ses données sont toujours immuables. Les tables d'une bigtable stockent des données évolutives qui ont été triées dans des cartes de clés/valeurs triées par clé, ligne et horodatage.
Avec Integrate.io, vous pouvez automatiser un processus ETL et d'intégration de données pour relier vos sources de données et vos entrepôts de données cloud. La plate-forme d'intégration comprend plus de 100 intégrations prédéfinies, y compris BigQuery, et une interface glisser-déposer qui facilite plus que jamais la gestion de vos processus d'intégration. Contactez notre équipe d'experts en données pour discuter de votre situation ou pour commencer un pilote de 14 jours de la plateforme Integrate.
Google BigQuery arrive en tête en termes de fonctionnalités, malgré le fait que MySQL soit encore largement utilisé. Cela est particulièrement vrai pour les fonctionnalités couramment utilisées dans les applications métier, telles que l'importation et l'exportation de données, l'analyse de données et la fédération de données. MySQL, en revanche, n'a que 28 fonctionnalités, ce qui signifie qu'il peut ne pas être en mesure de répondre aux besoins de nombreuses entreprises. Google BigQuery est basé sur le cloud, ce qui lui permet d'être accessible depuis n'importe quel endroit avec une connexion Internet. MySQL, en revanche, fonctionne sur une architecture client-serveur et n'est pas disponible dans le cloud.
Quelle est la différence entre BigQuery et Bigtable ?
Bigtable est une base de données NoSQL à larges colonnes optimisée pour les lectures et écritures intensives. Contrairement à BigQuery, qui est un entrepôt de données d'entreprise pour de grandes quantités de données relationnelles, Oracle Data Warehouse sert de service de déduplication.
BigQuery est-il basé sur Bigtable ?
Bigtable, un service de requête basé sur le cloud développé en collaboration avec Google et Microsoft, et le système Dremel de Google pour les requêtes ad hoc ont rapidement suivi, respectivement.
Quand dois-je utiliser Bigtable ?
Bigtable est idéal pour les applications nécessitant un débit et une évolutivité élevés lors de la gestion des données clé/valeur, avec un maximum de 10 Mo de données par valeur. Les points forts de Bigtable résident dans les opérations MapReduce par lots, le traitement/l'analyse des flux et l'apprentissage automatique.
Service de base de données Nosql évolutif
Un service de base de données nosql évolutif est un type de base de données qui peut gérer des données à grande échelle. Il s'agit d'un service Web qui peut être utilisé pour stocker et gérer de grandes quantités de données. Ce type de base de données est conçu pour être évolutif afin de pouvoir gérer des données à grande échelle.
Ce didacticiel suppose que vous disposez d'un environnement Node.js opérationnel. J'ai créé un dossier appelé nodejs-dynamodb-sample dans lequel décompresser les fichiers DynamoDB. La page GitHub du projet est https://www.gofundme.com/adamfowleruk/nodesurvey.html. L'exemple d'application utilise DynamoDB pour rechercher et récupérer des données de film. Pour stocker des données sur S3, nous utiliserons le service de gestion des identités et des accès (IAM) d'Amazon, et pour accéder à DynamoDB sur AWS, nous utiliserons le service DynamoDB d'Amazon. Pour utiliser le service iADM d'Amazon, vous devez d'abord vous inscrire et créer un utilisateur. Un titre de film et une année peuvent être ajoutés à la section POST/films de votre recherche.
Faites une liste de films d'une année donnée en entrant dans le champ de saisie. Vous pouvez maintenant créer votre propre application en suivant cet exemple de base. Si vous avez l'intention de réutiliser vos tables, vous devez les supprimer une fois que vous avez fini de les utiliser, ce qui entraînera des frais d'hébergement et de service AWS. Sur AWS, accédez à la console DynamoDB et entrez la quantité de stockage que vous avez utilisée. Vous pouvez afficher les éléments dans un tableau en cliquant sur "Films", consulter les mesures que vous voyez dans votre application et consulter les coûts mensuels estimés en cliquant sur l'onglet Capacité. Sur ma page GitHub, j'inclus un échantillon du code dans cet exercice : https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Base de données Google Cloud Bigtable
Google Cloud Bigtable est un service de base de données NoSQL rapide, entièrement géré et à l'échelle du pétaoctet, idéal pour les charges de travail analytiques et opérationnelles volumineuses.
Le magasin de données de Google est mieux adapté aux applications nécessitant des réponses rapides aux demandes des utilisateurs.
Dans la base de données Bigtable de Google, il n'y a pas de base de données relationnelle. Les requêtes SQL, les jointures et les transactions multilignes ne sont pas prises en charge. Par conséquent, si vous recherchez un support de base de données standard, vous ne pouvez pas vous y attendre. Bigtable, en revanche, ne fournit pas une grande quantité de données ou d'analyses. La nature optimisée de Bigtable est due en partie à ses capacités d'analyse et de traitement des données hautes performances. Le magasin de données, quant à lui, est conçu pour permettre aux données transactionnelles de grande valeur d'être servies aux applications. Par conséquent, Datastore est mieux adapté aux applications qui nécessitent des réponses rapides aux demandes des utilisateurs.