
Bases de données NoSQL : partitionnement et réplication
Publié: 2022-11-21Les bases de données NoSQL sont souvent utilisées pour le stockage de données à grande échelle en raison de leur capacité à évoluer horizontalement. Cela signifie qu'ils peuvent évoluer en ajoutant plus de nœuds au système, plutôt qu'en mettant à niveau le matériel d'un seul nœud. L'un des moyens d'atteindre cette évolutivité horizontale est le partage, qui est un processus de distribution des données sur plusieurs nœuds. La réplication est une autre façon dont les bases de données NoSQL peuvent évoluer, et elle implique la création de copies de données sur plusieurs nœuds.
Dans les bases de données SQL et NoSQL, le concept de partitionnement de base de données est essentiel pour la mise à l'échelle. La base de données est divisée en plusieurs morceaux (fragments) comme son nom l'indique.
Vous pouvez également utiliser la réplication de données NoSQL pour vous assurer de ne pas perdre de données lorsqu'un serveur tombe en panne en copiant et en stockant de manière transparente vos données structurées, non structurées et semi-structurées. Vous pouvez en savoir plus sur les bases de données NoSQL en visitant cette page.
Une base de données relationnelle peut être partitionnée à l'aide de la méthode Sharding, également appelée partition horizontale. Amazon Relational Database Service ( Amazon RDS ) est un service de base de données relationnelle géré qui simplifie son utilisation dans le cloud en fournissant une variété de fonctionnalités.
Une méthode de réplication copie les données de plusieurs serveurs et les place dans un emplacement où elles peuvent être trouvées. Lors de la réplication, des copies maître et esclave sont créées, les copies maître devenant des copies faisant autorité qui gèrent les données écrites et les copies esclaves devenant des copies asynchrones qui gèrent les données écrites.
Nosql utilise-t-il le partage ?
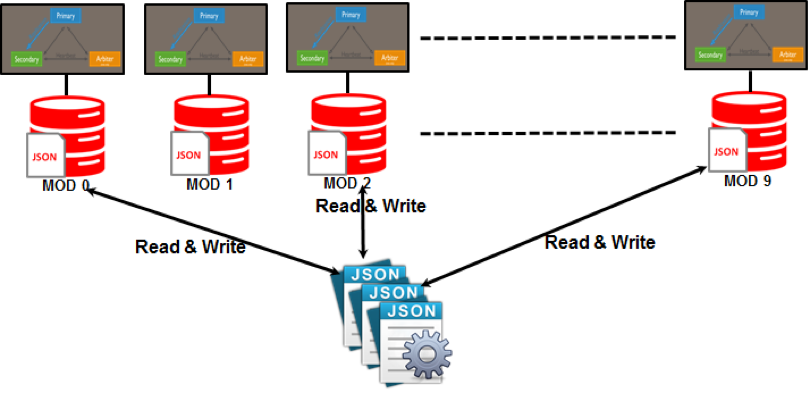
Les modèles de partition tels que le partage sont utilisés dans NoSQL. Le partitionnement est un processus qui attribue chaque partition à un serveur susceptible d'être indépendant du reste du réseau. Grâce à cette évolution, vous pouvez fournir aux utilisateurs du monde entier un accès à un ensemble de données diversifié tout en maintenant le niveau de performances le plus élevé possible.
MySQL Cluster est la solution. MySQL Cluster est un ensemble de logiciels qui partitionne automatiquement les tables entre les nœuds et permet aux bases de données de s'adapter horizontalement sur du matériel de base à faible coût pour servir les charges de travail intensives en lecture et en écriture à l'aide de SQL ainsi que directement via les API NoSQL. MySQL Cluster a le potentiel d'être utilisé pour bien plus que de simples blockchains. Il peut également être utilisé pour faire évoluer vos applications à l'aide de MySQL Cluster. La raison en est que MySQL Cluster est un système de planification. Par conséquent, vous pouvez faire évoluer vos applications en décidant quand et comment les fragments seront générés. Il s'agit d'un avantage majeur car vous n'avez pas besoin de compter sur le cloud computing . Cela est dû au fait que les fragments sont produits sur les nœuds où la charge de travail est exécutée. Par conséquent, vous pouvez contrôler la quantité de simultanéité requise. En conséquence, MySQL Cluster dispose d'un ensemble de fonctionnalités très puissant. Il peut être utilisé pour faire évoluer vos applications et contrôler le niveau de simultanéité dont vous avez besoin.
Qu'est-ce que le partage et la réplication dans Nosql ?
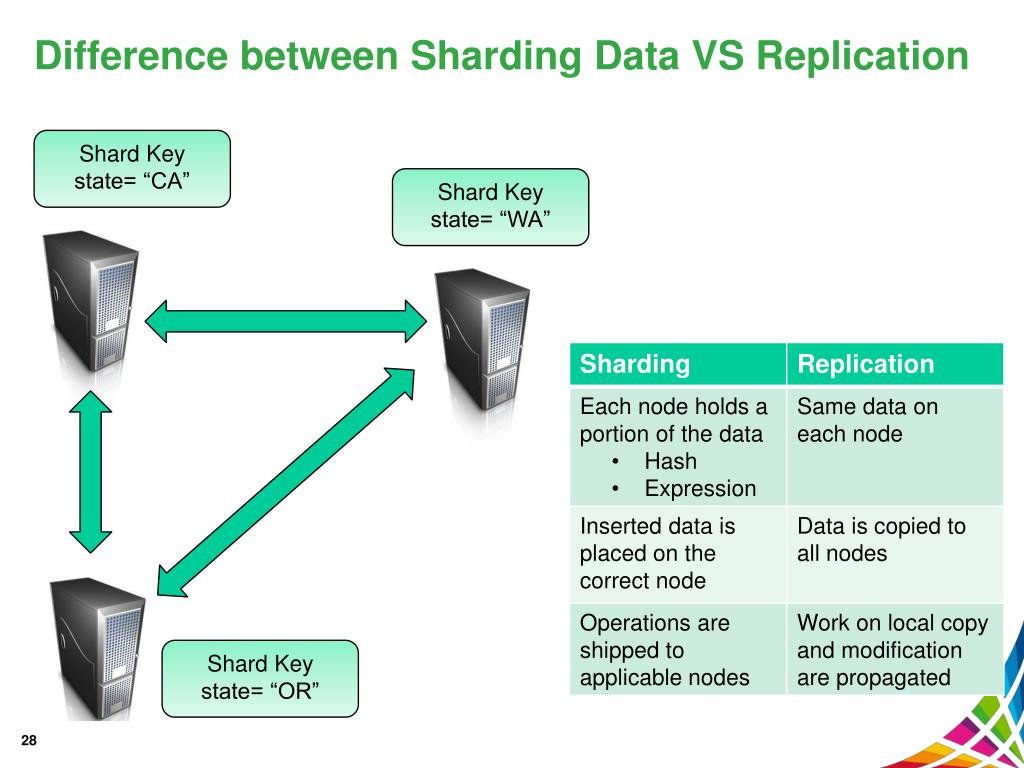
Quelle est la différence entre la réplication et le sharding ? La réplication de données consiste à transférer des données du nœud de serveur principal vers les nœuds de serveur secondaires . En tant que sauvegarde en cas de défaillance du serveur principal, cela peut aider à garantir que les données sont disponibles. Cette fonction peut être utilisée pour mettre à l'échelle horizontalement les serveurs à l'aide d'une clé de partition.
Les avantages du partage
Lorsque vous traitez des données qui doivent être partitionnées mais qui manquent de ressources pour les répliquer, l'espacement peut être bénéfique dans diverses situations. Lorsque vous devez mettre à l'échelle les lectures, la réplication est utile, mais les écritures de données peuvent être gérées plus efficacement avec le partitionnement. Choisir la mauvaise clé de partition peut avoir un impact négatif sur les performances du système.
Mongodb utilise-t-il le partage ?
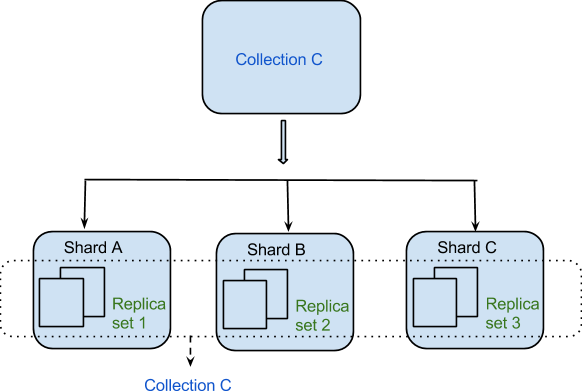
Les données sont réparties entre les machines de manière distribuée grâce au Sharding. MongoDB utilise le sharding pour prendre en charge les déploiements à grande échelle qui nécessitent un haut niveau de débit. Il peut être difficile de créer un serveur unique pour un système de base de données avec un grand nombre d'ensembles de données ou une application à haut débit.
La stratégie la plus courante pour résoudre les problèmes de partage à distance consiste à l'aborder dans son sens le plus général. Le nœud racine du cluster a un nombre prédéterminé de fragments qui peuvent être divisés en fonction de leur distance par rapport au centre de données du cluster. Le nœud principal est appelé nœud racine car il s'agit du premier nœud à être créé dans l'ensemble de données. Un autre type de fragment est appelé fragment secondaire. Une transaction à distance ou de hachage est possible. La valeur de la clé de hachage d'un fragment spécifique détermine la quantité de données qu'il peut générer. Un identifiant est créé par la clé de hachage pour chaque élément de données dans une transaction. Il y a de nombreux avantages et inconvénients à chaque stratégie. Il est plus simple d'implémenter le fractionnement de plage lorsque l'ensemble de données est petit, par opposition à un grand ensemble, et il est plus efficace lorsqu'il est petit. Lorsque l'ensemble de données est volumineux, le hachage est plus efficace. La réputation de vitesse de MongoDB découle du fait qu'il prend en charge la délégation de données à d'autres services MongoDB. Les fragments d'ensemble de données peuvent être distribués entre plusieurs serveurs dans MongoDB pour améliorer la vitesse de traitement des données. MongoDB prend en charge plusieurs options de réplication en plus du sharding. Par conséquent, la réplication permet à un ensemble de données d'être distribué sur plusieurs serveurs afin de maintenir la cohérence. La réplication des données est nécessaire si vous voulez vous assurer que les informations sont toujours exactes et à jour. De plus, les clusters dispersés dans MongoDB peuvent être utiles pour améliorer les performances. Le sraving est une technique permettant de transférer de grandes quantités de données d'un serveur à un autre de la même manière que la réplication. Une clé de shard est une donnée qui peut être copiée (ou « shards ») d'un serveur à un autre. Les deux principales méthodes de distribution des données sur les clusters partitionnés dans MongoDB sont basées sur la plage et distribuées. Le hachage peut être effectué en utilisant un serveur crypté. En divisant les choses, vous pouvez accomplir plus d'une chose.

Devriez-vous partager votre Mongodb ?
Il n'est pas certain que le sharding améliore ou non les performances dans certains cas, mais il a été démontré qu'il augmente les performances dans certains cas. De plus, par conséquent, le sharding introduit son propre ensemble de défis, tels que la garantie de sauvegardes et de restaurations robustes. Avant de décider d'une stratégie de partitionnement, vous devez réfléchir aux avantages et aux inconvénients de le faire.
Partage dans Nosql
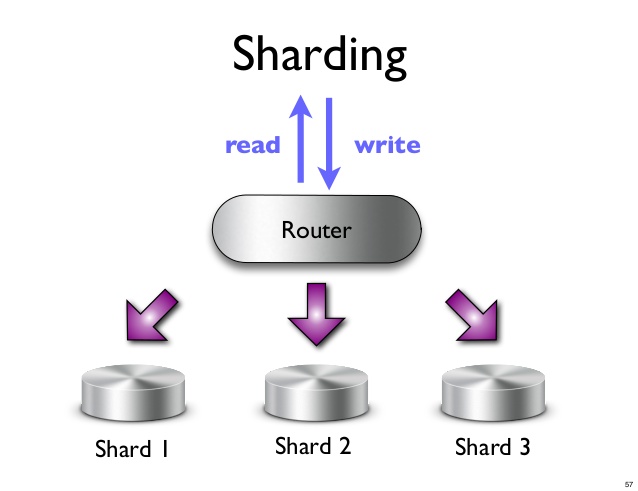
Une partition est une partition horizontale de données dans une base de données ou un moteur de recherche. Chaque partition est une base de données indépendante ou une instance de moteur de recherche. Dans une base de données NoSQL, une collection de documents peut être divisée en partitions, chacune étant stockée sur un serveur séparé.
Partage contre réplication
La distinction entre la réplication et le sharding est que la réplication est la duplication des données, tandis que le sharding est la division des données en morceaux discrets. Dans ce cas, vous avez divisé votre collection en plusieurs parties en fonction du sharding. La récupération de votre base de données génère des images de tous vos ensembles de données.
Les avantages du partage
Les données sont réparties sur plusieurs machines afin d'augmenter le nombre d'utilisateurs simultanés et d'améliorer les performances. Les données sont stockées sur des partitions séparées dans chacune des machines.
Réplication dans Nosql
Il existe différentes manières de gérer la réplication dans une base de données NoSQL. Une façon consiste pour la base de données à se répliquer automatiquement sur un serveur secondaire chaque fois qu'une modification est apportée. Cela garantit qu'il y a toujours une sauvegarde disponible en cas de panne du serveur principal. Une autre méthode consiste à répliquer manuellement les données sur un serveur secondaire de manière régulière. Cela donne à l'administrateur plus de contrôle sur le moment où la réplication se produit, mais cela signifie également qu'il est possible que le serveur secondaire ne soit pas à jour en cas de panne.
Qu'est-ce que le partage dans la base de données
Le sharding est un processus de partitionnement horizontal des données dans une base de données. Dans le sharding, une base de données est divisée en parties plus petites, appelées shards. Chaque fragment est stocké sur un serveur distinct. Le processus de partitionnement permet d'améliorer les performances d'une base de données en répartissant la charge sur plusieurs serveurs.
Une seule donnée peut être répliquée en une seule transaction à l'aide du sharding. En divisant un jeu de données en plus petits morceaux et en les répartissant sur plusieurs serveurs, la capacité de stockage globale du système peut être augmentée. Dans certains cas, cela peut être utile si les données sont volumineuses et nécessitent plusieurs serveurs pour les conserver. Les wrappers de données étrangères sont également utilisés pour lire les données à partir de serveurs distants, ce qui donne encore plus de flexibilité au stockage des données.
Quelle est la différence entre le partitionnement et le sharding ?
Le partitionnement et le partitionnement sont deux approches pour structurer de grandes collections de données en petits fragments. Le partitionnement et la partition signifient que les données sont réparties sur plusieurs ordinateurs, mais ils sont distincts. La procédure de partitionnement d'une instance de base de données implique le regroupement de sous-ensembles de données en son sein.
Quelle base de données est la meilleure pour le partage ?
Le partage de base de données est pris en charge par Cassandra, HBase, HDFS, MongoDB et Redis. Les bases de données qui ne prennent pas en charge nativement PostgreSQL, Memcached, Zookeeper, MySQL et Sqlite sont considérées comme des bases de données. La logique Jarryd doit être présente dans une application si elle n'a pas de prise en charge intégrée des bases de données.
Le partage est-il possible dans SQL ?
Il est cependant possible d'implémenter le sharding basé sur la plage (essentiellement horizontal), d'une manière qui le rend plus transparent pour l'application. La manière habituelle de procéder dans SQL Server consiste à utiliser une vue partitionnée, mais cela n'est pas obligatoire.