
Bases de données NoSQL : bases de données à l'échelle du Web pour un trafic élevé et de grands ensembles de données
Publié: 2022-11-18Les bases de données Nosql sont des bases de données à l'échelle du Web qui peuvent gérer un trafic élevé et de grands ensembles de données. Ils sont conçus pour être évolutifs et supporter des charges élevées. Une base de données nosql peut être mise à l'échelle horizontalement en ajoutant plus de serveurs au système. Cela permet au système de gérer plus de trafic et de stocker plus de données.
L'augmentation de la demande d'applications complexes nécessite une plus grande flexibilité. Il est tout aussi important de sélectionner des magasins de données faciles à mettre à l'échelle et à exécuter efficacement. Le problème le plus important est de savoir si les bases de données 'ASL' ou 'NoSQL' sont meilleures pour exécuter une application. Les bases de données SQL sont utilisées depuis un certain temps, mais les bases de données NoSQL sont connues pour être plus faciles à mettre à l'échelle. Pour les bases de données NoSQL, l'hypothèse est que le partitionnement doit être effectué dans toutes les opérations. Un nœud peut être identifié par une fonction de qualification, qui est attendue de chaque opération de données dans la base de données. Étant donné que les données sont stockées sur plusieurs machines, il est très efficace de gérer les opérations de données, même sur les machines les plus élémentaires.
Avec cette fonctionnalité, de simples machines de base peuvent être utilisées pour faire évoluer les magasins NoSQL. NoSQL suppose que l'utilisateur peut planifier et structurer les données de sorte qu'elles ne soient récupérées qu'à partir du même nœud à un moment donné pour une opération donnée. De plus, la dénormalisation des données entre les nœuds (données précuites pour le démarrage) peut être effectuée. Il y a une place pour les jointures NoSQL, mais ne vous attendez pas à ce qu'elles soient riches en SQL ou optimisées. En pratique, on suppose que les données seront toujours cohérentes avec les applications NoSQL. Il existe de nombreux systèmes NoSQL qui fournissent des commutateurs pour modifier la cohérence dans le temps si la cohérence est importante. L'objectif de toute décision d'architecture, comme l'objectif d'évaluation du cas d'utilisation, est de sélectionner le magasin de données approprié.
Un pool de ressources de mise à l'échelle horizontale peut être étendu en y ajoutant plus de machines, tandis qu'un pool de mise à l'échelle verticale peut être étendu en y ajoutant plus de machines.
Les bases de données SQL et les bases de données NoSQL utilisent la mise à l'échelle verticale en raison de la manière dont les données sont stockées (tables liées par rapport aux collections non liées), tandis que les bases de données NoSQL utilisent la mise à l'échelle horizontale car elles n'utilisent pas de tables liées.
Le type de mise à l'échelle pris en charge par NoSQL est horizontal.
Pour évoluer horizontalement, MongoDB utilise un mécanisme intégré qui vous permet de déplacer des données sur plusieurs serveurs. Ce processus est appelé partitionnement et vous pouvez l'exécuter en appuyant sur un bouton bascule sur la page de configuration de l'interface utilisateur Atlas. En dehors de cela, le processus peut également être terminé sans temps d'arrêt.
Comment fonctionne la mise à l'échelle horizontale dans Nosql ?
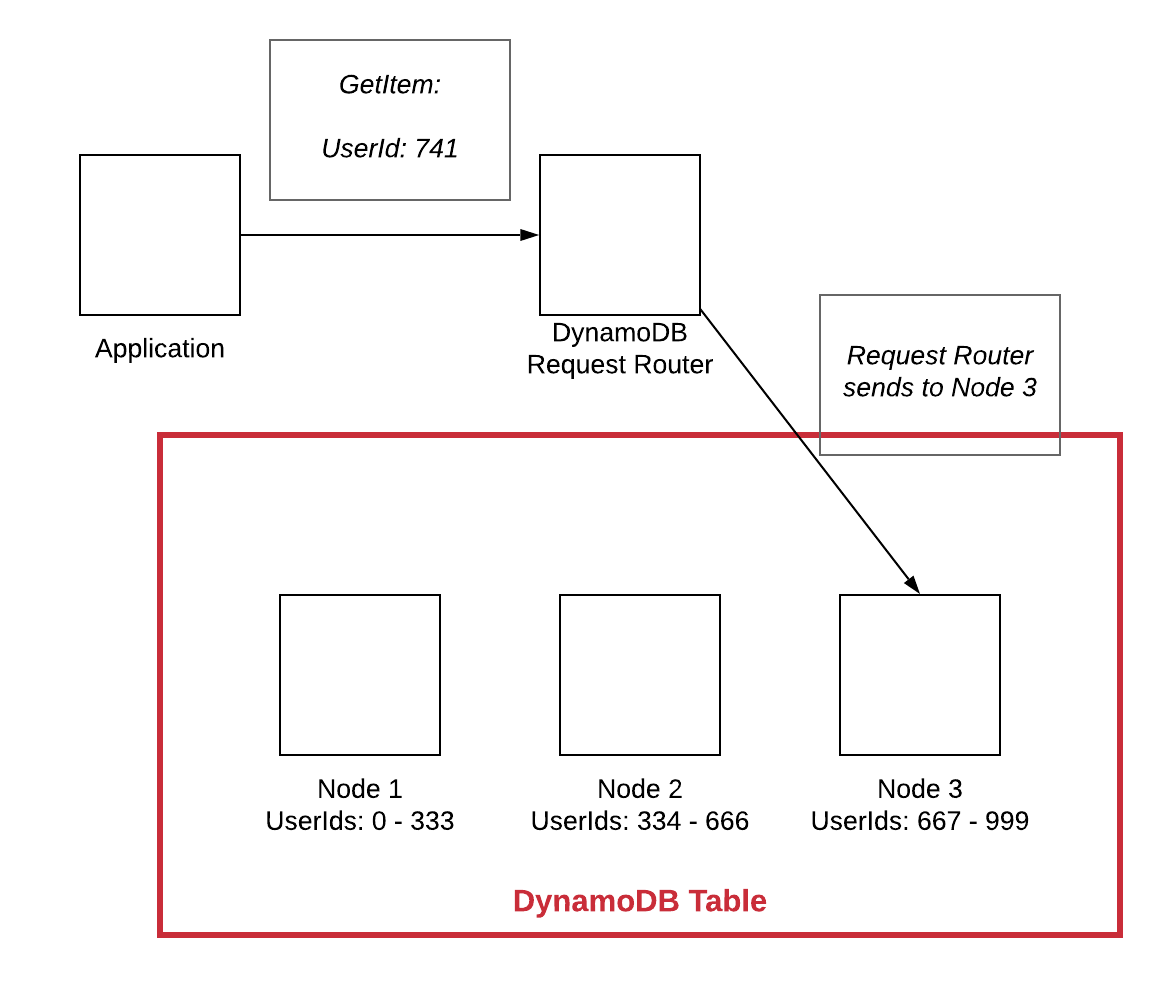
La mise à l'échelle horizontale dans une base de données NoSQL signifie que la base de données peut être mise à l'échelle en ajoutant plus de machines au système, plutôt que de rendre une seule machine plus rapide ou plus puissante. Cela permet au système de gérer plus de trafic et de données sans rencontrer de problèmes de performances.
Les avantages de la mise à l'échelle horizontale sont nombreux : vous pouvez facilement ajouter plus de serveurs pour gérer l'augmentation du trafic, et vous n'aurez pas à vous soucier de charger des lignes à partir de plusieurs serveurs en même temps. Par conséquent, les bases de données NoSQL constituent d'excellents choix pour les entreprises qui souhaitent stocker des données à la demande tout en économisant de l'argent sur le stockage des données .
Les bases de données Nosql sont meilleures pour gérer de grands ensembles de données
En raison des limites des bases de données relationnelles , elles ne peuvent pas gérer de grands ensembles de données. Les bases de données NoSQL, telles que MongoDB, stockent vos données dans un format de document autonome, vous permettant de distribuer vos données sur plusieurs nœuds. Grâce à cette fonctionnalité, la base de données est capable de gérer rapidement et facilement de grands ensembles de données.
Comment Mongodb peut-il évoluer horizontalement ?
MongoDB peut évoluer horizontalement en utilisant le sharding. Le sharding est un processus de fractionnement des données sur plusieurs serveurs. Chaque serveur possède sa propre partie de l'ensemble de données et les données sont réparties uniformément sur les serveurs. Lorsqu'une demande est faite, le serveur MongoDB déterminera quel serveur possède les données demandées et les récupérera à partir de ce serveur. Ce processus permet à MongoDB d'évoluer horizontalement et de gérer de grandes quantités de données.
Lorsqu'il s'agit de faire évoluer l'infrastructure, de nombreuses entreprises trouvent qu'elles traversent une période difficile. La plate-forme de base de données MongoDB en tant que service prend en charge un large éventail d'options de mise à l'échelle et est intégrée à son backend. La technique de mise à l'échelle horizontale est connue sous le nom de sharding (parce qu'elle est préférée). Le terme « mise à l'échelle à plusieurs niveaux » fait référence à la capacité d'un serveur ou d'un cluster unique à évoluer vers le haut. Il s'agit d'une méthode de mise à l'échelle horizontale qui consiste à répartir les données sur plusieurs nœuds. La plate-forme MongoDB Atlas configure automatiquement une clé de partition, qui dépend toujours de nous. Il est clair que les jeux de réplicas et le sharding sont similaires, mais les jeux de données ne sont pas les mêmes.
De plus, ils peuvent causer des problèmes avec de grandes quantités de transactions d'écriture pour les applications. MongoDB Atlas prend également en charge la mise à l'échelle horizontale et verticale. Le déploiement d'un cluster partitionné permet une mise à l'échelle horizontale. En un mot, la mise à l'échelle verticale est aussi simple que la configuration d'un niveau de cluster. Dans le cas d'un arrêt complet, le cluster peut être mis en pause pour maintenir le cluster à 0, mettant ainsi à l'échelle l'ensemble du cluster à 0, à l'exception du stockage.
MongoDB est une excellente base de données NoSQL, tout comme une application moderne qui doit évoluer horizontalement pour gérer de grands ensembles de données. MongoDB dispose d'une API simple qui permet aux développeurs d'accéder et de manipuler facilement les données, et son stockage sans schéma facilite le stockage et la récupération des données. De plus, comme MongoDB prend en charge la réplication, les données peuvent être facilement répliquées sur plusieurs serveurs, garantissant ainsi qu'elles restent disponibles pour une utilisation future.
L'évolutivité de Mongodb
MongoDB est l'un des langages de programmation les plus élastiques. Dans une base de données orientée document comme MongoDB, les données sont stockées dans des documents de type JSON. Le processus MongoDB évolue horizontalement grâce à l'utilisation du sharding. Srave est une technique de distribution de données qui utilise plusieurs collections et machines pour distribuer les données entre les bases de données et les machines.
Sql Db est-il évolutif horizontalement ?
Dans la mise à l'échelle horizontale, des bases de données sont ajoutées ou supprimées pour effectuer une tâche spécifique, telle que l'augmentation ou la diminution de la capacité ou des performances globales. La mise à l'échelle horizontale est généralement mise en œuvre en combinant des données provenant de plusieurs bases de données structurées de manière identique, puis en les séparant dans des tables distinctes.
Chaque base de données, chaque jour, doit être mise à l'échelle pour gérer le volume de données générées. La mise à l'échelle est classée en deux types : verticale et horizontale. La mémoire d'un serveur de 2 To est suffisante pour stocker plus de données. Il s'agit d'acheter un gros serveur à un prix extrêmement élevé. L'ajout de plusieurs machines au serveur est appelé mise à l'échelle horizontale. Son objectif est de diviser l'ensemble de données en plusieurs serveurs, ou fragments. Il serait inutile d'avoir un seul point de vérité basé sur la dénormalisation. Cette approche présente un inconvénient : si le maître ne parvient pas à mettre à jour les répliques esclaves lors d'une écriture, le maître ne mettra pas à jour les répliques esclaves.

Une réplication est l'acte d'échanger des données entre les nœuds d'un cluster. En répliquant les données, vous pouvez augmenter la disponibilité et la récupération d'un serveur. De plus, la réplication peut être utilisée pour répartir la charge sur plusieurs clusters de nœuds. Une organisation peut diviser horizontalement ses données en blocs plus petits et répartir ces blocs sur plusieurs nœuds. Le partitionnement horizontal améliore les performances. Il existe plusieurs types de clusters MongoDB , en plus des clusters MongoDB par défaut. Le cluster à nœud unique, en général, est le type de cluster le plus simple et convient bien aux tests et au développement. Un cluster à deux nœuds est le type de cluster le plus courant et convient aux applications de moyenne à grande échelle. Un cluster à trois nœuds est également populaire et convient aux applications à grande échelle. Dans un cluster à deux nœuds, par exemple, les données sont divisées en deux partitions distinctes sur chaque nœud. Dans ce cas, chaque nœud possède une copie des données. Lorsque la charge d'un nœud augmente, l'autre nœud peut être en mesure de gérer la charge. Un cluster à charge équilibrée est l'un des types de clusters les plus courants. Un cluster à trois nœuds est composé de trois centres de données distincts, chacun contenant trois fragments distincts. Si la charge d'un nœud augmente, les deux autres nœuds peuvent prendre le relais. Un cluster équilibré est l'un de ces clusters. La base de données MongoDB est une base de données moderne basée sur des documents avec des capacités de mise à l'échelle horizontale : réplication et partitionnement horizontal (ou sharding). Le processus de mise à l'échelle horizontale d'une base de données implique l'ajout d'instances ou de nœuds supplémentaires pour faire face à une demande accrue. Lorsque vous avez besoin de plus de capacité, vous ajoutez simplement plus de serveurs au cluster. De plus, les serveurs sont généralement plus petits et moins chers que ceux utilisés pour l'informatique de bureau. Il s'agit d'un processus de copie de données entre les nœuds d'un cluster. Le partitionnement des données les divise horizontalement en plus petits morceaux et les distribue sur plusieurs nœuds dans un système distribué. Il existe plusieurs types de clusters MongoDB, chacun avec un ensemble distinct de fonctionnalités. Les clusters à trois nœuds sont également courants, bien qu'ils ne soient pas aussi efficaces qu'un cluster à quatre nœuds.
Mise à l'échelle horizontale avec une base de données relationnelle
Une base de données SQL traditionnelle ne peut généralement pas évoluer horizontalement car elle doit héberger plus de serveurs, mais nous pouvons toujours ajouter des répliques d'autres machines. Le journal Write Ahead est utilisé pour propager toutes les opérations d'écriture du serveur principal vers d'autres machines. En raison de la flexibilité de la syntaxe des requêtes, les bases de données relationnelles ne peuvent pas évoluer horizontalement. Pour vous assurer qu'aucune partie de vos données n'est récupérée jusqu'à ce que vous exécutiez votre requête, SQL vous permet d'ajouter tellement de conditions et de filtres à vos données qu'il est impossible pour votre base de données de prédire quelles parties seront récupérées. Par conséquent, la base de données peut devenir lente lorsqu'elle tente de traiter de grandes quantités de données. Étant donné que les bases de données relationnelles peuvent évoluer horizontalement, elles peuvent aider à couvrir des domaines où Spark est généralement moins efficace, que ce soit en agissant comme un support de stockage pour Spark Streaming ou des calculs par lots. La plate- forme cloud SQL ne prend pas en charge ces configurations de manière native, mais elles peuvent être implémentées à l'aide d'outils industriels tels que ProxySQL. Cependant, le concept sous-jacent de Cloud SQL n'est pas destiné à ces types de scénarios.
Pourquoi Nosql est-il évolutif horizontalement
Les bases de données NoSQL peuvent évoluer horizontalement ou verticalement en fonction de leurs besoins. Vous pouvez gérer les situations de trafic élevé en partitionnant votre base de données NoSQL, en ajoutant plus de serveurs au processus. Les bases de données NoSQL sont le choix préféré pour les ensembles de données volumineux et fréquemment modifiés, car elles peuvent évoluer horizontalement plutôt que verticalement.
Il devrait être capable de gérer de très grandes bases de données , avec des taux de requêtes très élevés, avec une latence très faible. La mise à l'échelle et la disponibilité sont des exigences essentielles pour les sites Web à volume élevé tels qu'eBay, Amazon, Twitter et Facebook. Lorsque vous avez la possibilité d'exécuter plusieurs instances sur un serveur en même temps, la mise à l'échelle horizontale est idéale.
En raison de leur évolutivité et de leur flexibilité, les bases de données NoSQL gagnent en popularité par rapport aux bases de données SQL. En outre, elles sont plus performantes que les bases de données basées sur des tables pour les données non structurées, qui peuvent être difficiles à traiter et à stocker.
Comment mettre à l'échelle la base de données Nosql
Il n'y a pas de réponse unique à cette question, car la meilleure façon de faire évoluer une base de données NoSQL dépend des besoins spécifiques de l'application et des données stockées. Cependant, certains conseils sur la mise à l'échelle d'une base de données NoSQL incluent l'ajout de nœuds supplémentaires au cluster pour augmenter la capacité et les performances, l'utilisation du partitionnement pour répartir les données sur plusieurs nœuds et la réplication des données sur plusieurs nœuds pour garantir une haute disponibilité.
Plusieurs points importants sont abordés lorsque Rahim Yaseen de Couchbase nous les explique. Les organisations se démènent pour gérer, stocker et monétiser leurs énormes quantités de données. Une décision importante concernant la base de données est de savoir s'il faut ou non évoluer. L'inscription est distribuée aux guichets d'enregistrement en partage manuel. Ceci est accompli grâce à un schéma bien défini et prédéfini. Dans le cadre du partitionnement automatique, vous devez vous rendre sur chaque stand pour savoir qui s'est enregistré avec un nom de famille commençant par S. Les bases de données de documents ont des modèles d'accès qui obligent les utilisateurs à naviguer vers un autre document via une clé spécifique et à accéder aux données via un seul clé. À mesure que la taille d'un ensemble de données distribué augmente, il devient de plus en plus difficile de l'indexer et de l'interroger.
Il est inutile d'utiliser une technique de map-reduce car chaque nœud de la requête doit y participer. À mesure que les données augmentent en volume, la mise à l'échelle du modèle RDBMS devient de moins en moins faisable. Dans le cas d'un ensemble de données volumineux, la défaillance d'une architecture à grande échelle est susceptible d'être un point de défaillance très important. Internet est un exemple de cluster ultra-évolutif sans partage.
Bases de données Nosql : l'avenir de l'évolutivité
Comme les données sont envoyées sur plusieurs machines dans les bases de données Nosql, elles sont extrêmement évolutives. Par conséquent, au lieu d'acheter des machines coûteuses qui nécessitent un équipement spécialisé, nous pouvons facilement ajouter de la puissance CPU. De plus, les bases de données Nosql peuvent contenir une grande quantité de données sans limite, ce qui en fait un système de gestion de données très polyvalent.
La base de données SQL peut-elle évoluer horizontalement
Oui, les bases de données SQL peuvent évoluer horizontalement. Cela signifie qu'ils peuvent être répartis sur plusieurs serveurs, chacun d'entre eux gérant une partie des données totales. Cela permet une plus grande évolutivité qu'un seul serveur pourrait fournir.
Pourquoi les bases de données SQL ne sont-elles pas évolutives horizontalement ?
En raison de la flexibilité de la syntaxe des requêtes, il est impossible de procéder à une mise à l'échelle horizontale dans une base de données relationnelle . Grâce à SQL, vous pouvez ajouter un nombre illimité de conditions et de filtres à vos données qui empêchent le système de base de données de savoir quels éléments seront renvoyés tant que la requête n'est pas terminée.
Pourquoi SQL évolue-t-il verticalement ?
L'objectif de la mise à l'échelle verticale est d'augmenter la consommation d'énergie et la capacité de la RAM des systèmes existants, en augmentant essentiellement les ressources disponibles. La mise à l'échelle verticale est non seulement plus facile, mais elle est également moins coûteuse. Le problème ne nécessite pas non plus une solution à long terme.