
Pig : une plate-forme de haut niveau pour Apache Hadoop
Publié: 2023-02-22Pig est une plate-forme de haut niveau pour créer des programmes qui s'exécutent sur Apache Hadoop. Le terme « Pig » fait référence à la couche d'infrastructure de la plate-forme, qui se compose d'un compilateur et d'un environnement d'exécution, ainsi que d'un ensemble d'opérateurs de haut niveau. La couche d'infrastructure de Pig fournit un ensemble d'outils permettant aux développeurs de créer, de maintenir et d'exécuter leurs programmes Pig. Pig est un projet open source qui fait partie de l' écosystème Apache Hadoop . Le modèle de programmation de Pig est basé sur le flux de données, ce qui facilite l'écriture de programmes traitant de grandes quantités de données. Les programmes Pig sont composés d'une série d'opérateurs qui sont exécutés dans un graphe orienté acyclique. Pig est un excellent choix pour traiter de grandes quantités de données car il est évolutif, efficace et facile à utiliser.
En tant que solution NoSQL, vous avez besoin de moyens spécifiques et prédéfinis pour analyser et accéder aux données. SQL (UNION, INTERSECT, etc.) est une expression de requête courante qui n'est pas très souvent utilisée dans le monde du Big Data. Étant donné que Hive est optimisé pour le traitement par lots et Big Data, il est préférable de toucher chaque ligne. Hive consacre beaucoup moins de temps et d'argent aux opérations que Hadoop, qui a l'avantage de l'échelle. Même les petites requêtes sur les systèmes de développement peuvent être ORDERS plus lentes que les requêtes similaires sur RDBMS. Hive ne met pas en cache les résultats de la requête. Soumettre à nouveau une requête répétée est une pratique courante dans MapReduce.
Il existe deux types de Hive : 1) Hive n'est pas une base de données ; il s'agit plutôt d'un moteur de requête qui prend en charge les parties SQL spécifiques aux données de requête b) Hive est une base de données avec prise en charge SQL c) Hive est une base de données spécifique à SQL. Hive est un système d'entrepôt de données basé sur SQL pour Hadoop qui inclut Pig et Python, entre autres ; Hive est utilisé pour stocker les données Hadoop .
Le cochon est-il un Sql ?
Il n'y a pas de bonne ou de mauvaise réponse à cette question, car cela dépend de l'opinion personnelle. Certaines personnes peuvent croire que le cochon est un sql, tandis que d'autres non. En fin de compte, c'est à l'individu de décider si oui ou non le cochon est un sql.
Aujourd'hui, Apache Hive et Pig sont deux termes qui deviennent rapidement synonymes de big data. Grâce à ces outils, les développeurs de données et les analystes peuvent les utiliser pour réduire la complexité de MapReduce tout en conservant un haut niveau d'intégrité des données. Hive est une infrastructure d'entrepôt de données également connue sous le nom d'outil ETL (extraction, chargement et transformation). Apache Hive, Pig et SQL sont trois outils populaires pour l'analyse et la gestion des données. Vous devez savoir quelle plate-forme sera la mieux adaptée à vos besoins et à quelle fréquence vous devez l'utiliser. Examinons les trois manières différentes d'utiliser Hive, Pig et SQL dans le contexte de ces trois technologies. SQL est toujours le roi du perchoir dans la gestion et l'analyse de données volumineuses, malgré la domination d'Apache Hive et d'Apache Pig. Parce que chacun remplit une fonction spécifique, leurs exigences sont adaptées à l'entreprise. Apache Pig est basé sur des scripts et nécessite des connaissances particulières, alors qu'Apache Hive est la seule solution de base de données native pour le développeur.
Le cochon est un animal polyvalent avec une grande flexibilité. Pig, par exemple, peut traiter des fichiers journaux contenant des données JSON ou XML, vous permettant de lire les données. Il est également possible de stocker des données de services Web dans Pig.
Les types de données de carte, les tuples et les types de données de sac peuvent être utilisés de manière interchangeable. Ils sont capables de traiter des données de n'importe quelle source.

Pig est-il un outil ETL ?
Il n'y a pas de réponse définitive à cette question car cela dépend de la façon dont vous définissez un outil ETL. De manière générale, un outil ETL est une application logicielle qui vous aide à extraire des données d'une ou plusieurs sources, à les transformer dans un format compatible avec votre système cible et à les charger dans ce système. Certaines personnes diraient que pig est un outil ETL car il peut remplir toutes ces fonctions. D'autres pourraient soutenir que pig n'est pas un outil ETL car il n'est pas spécifiquement conçu pour la transformation de données. En fin de compte, la réponse à cette question dépend de votre propre définition d'un outil ETL.
Comment pouvez-vous utiliser Pig pour le traitement ETL ?
Une application Pig peut être décrite comme un modèle de transaction ETL, qui décrit comment un processus extrait des données d'un objet et les transforme en un magasin de données basé sur un ensemble de règles. Les utilisateurs définissent les fonctions définies par l'utilisateur (UDF) du Pig afin d'ingérer des données à partir de fichiers, de flux et d'autres sources.
Qu'est-ce que Pig Tool ?
Une plate-forme ou un outil connu sous le nom de Pig traite de grands ensembles de données. Cette bibliothèque contient un haut niveau d'abstraction pour le traitement des données dans le processus MapReduce. Pig Latin est un langage de script de haut niveau qui est utilisé dans le processus de codage pour développer les codes d'analyse de données.
Quelle est la différence entre Pig et Sql ?
SQL Pig Latin et Apache Pig sont des langages procéduraux. SQL est un langage de script de nature déclarative. Il appartient entièrement à Apache Pig d'utiliser ou non le schéma. Les données peuvent être stockées sans avoir besoin d'un schéma (les types de valeur sont stockés dans $, $, etc.).
Pig fait-il partie de Hadoop ?
Une application Pig Hadoop est un langage de programmation de haut niveau qui peut être utilisé pour analyser des ensembles de données massifs. Le projet Pig Hadoop de Yahoo! a été l'un des premiers projets Hadoop . En général, il effectue une quantité importante de travail d'administration de données lors de l'exécution de Hadoop.
Dans le domaine de l'analyse de données volumineuses, Pig Hadoop est un langage de programmation de haut niveau. Afin d'analyser des données à l'aide d'Apache Pig, nous devons d'abord écrire des scripts à l'aide de Pig Latin. scripts qui seront transformés en tâches MapReduce . Ceci est réalisé en utilisant Pig Engine, une extension Apache Pig. En suivant les étapes ci-dessous, vous pouvez installer Apache Pig sur Linux/CentOS/Windows (via VM ou Cloudera). La première étape consiste à télécharger et installer Apache Pig. La deuxième étape consiste à modifier les variables d'environnement Apache Pig à l'aide du fichier bashrc.
À l'étape 3, déterminez la version de Pig . Ce fichier peut être enregistré dans un autre répertoire après avoir été déplacé. La cinquième étape consiste à lancer le Grunt Shell (le script utilisé pour exécuter Pig Latin) en cliquant sur la commande Pig.
Pourquoi Pig Latin est le meilleur langage de script de haut niveau pour l'analyse de données
Le code d'analyse de données Pig Latin est écrit dans un langage de script de haut niveau. C'est un langage de type SQL qui est destiné à traiter des flux de données en parallèle.
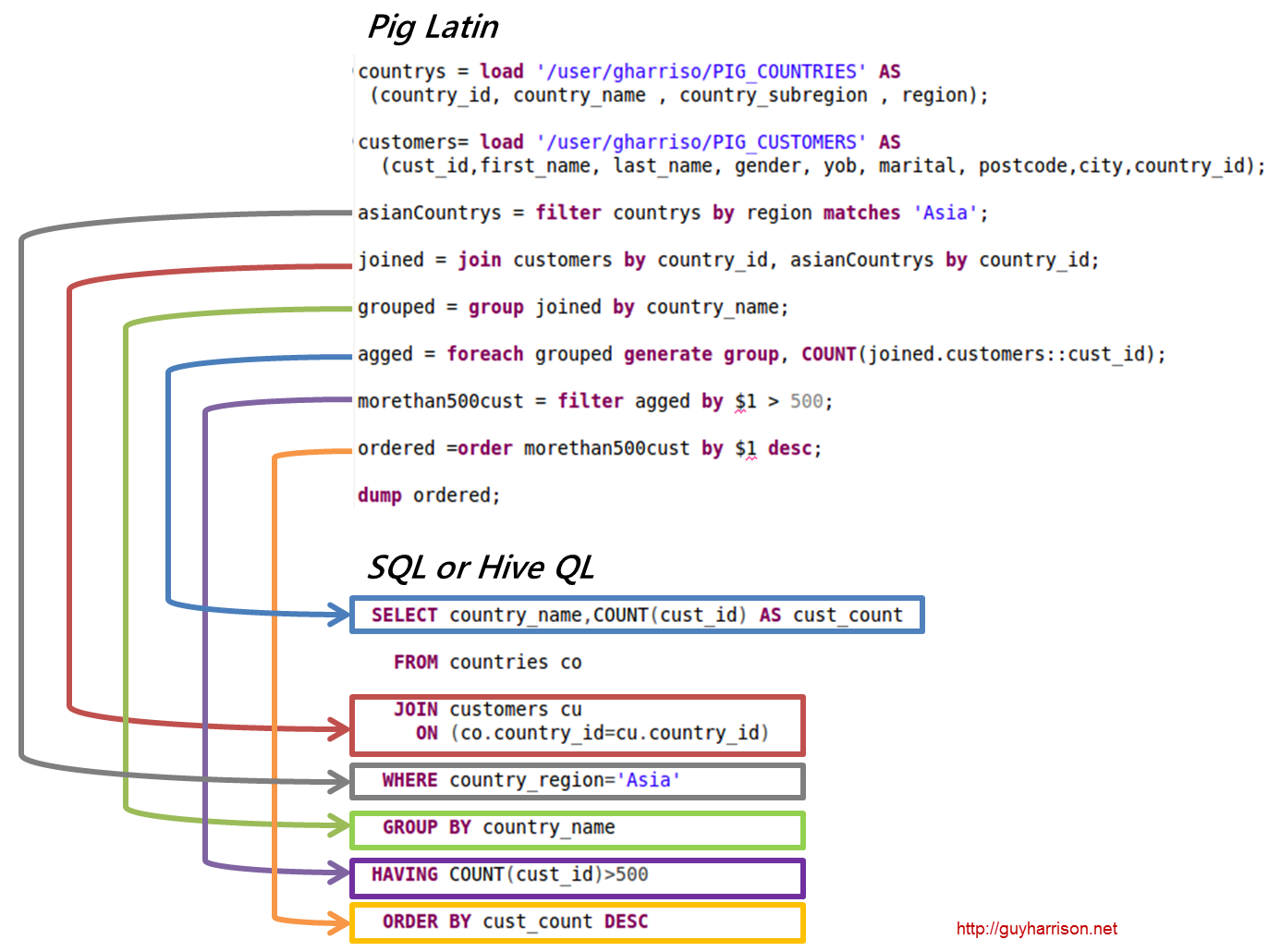
Apache Cochon Exemple
Pig est une plate-forme de haut niveau pour créer des programmes qui s'exécutent sur Apache Hadoop. La langue de cette plate-forme s'appelle Pig Latin. Pig peut exécuter ses tâches Hadoop dans MapReduce, Tez ou Spark. Pig Latin résume la programmation de l'idiome Java MapReduce en une notation qui facilite la programmation MapReduce. Par exemple, l'instruction Pig Latin suivante est équivalente au code Java MapReduce ci-dessus : A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); VIDAGE A ;