
Mise à l'échelle d'une base de données NoSQL : trucs et astuces
Publié: 2022-11-18Les bases de données NoSQL deviennent de plus en plus populaires alors que la quantité de données générées par les entreprises continue de croître de façon exponentielle. Cependant, de nombreuses organisations hésitent à passer au NoSQL car elles craignent qu'il soit plus difficile à faire évoluer. La mise à l'échelle d'une base de données NoSQL n'est en fait pas si différente de la mise à l'échelle d'une base de données relationnelle. La principale différence est que les bases de données NoSQL sont conçues pour être évolutives horizontalement, ce qui signifie qu'elles peuvent évoluer en ajoutant plus de nœuds au système. Cela contraste avec les bases de données relationnelles , qui sont évolutives verticalement, ce qui signifie qu'elles ne peuvent évoluer qu'en ajoutant plus de ressources à un seul serveur. Il y a quelques points à garder à l'esprit lors de la mise à l'échelle d'une base de données NoSQL : 1. Assurez-vous que vos données sont réparties uniformément sur tous les nœuds. 2. Ajoutez des nœuds progressivement pour éviter de surcharger le système. 3. Surveillez de près les performances du système pour identifier tout goulot d'étranglement. 4. Réglez régulièrement le système pour garantir des performances optimales. Avec ces conseils à l'esprit, la mise à l'échelle d'une base de données NoSQL ne devrait pas être plus difficile que la mise à l'échelle d'une base de données relationnelle.
Il existe de nombreuses méthodes et principes de mise à l'échelle d'une base de données, en fonction de son type. La mise à l'échelle des bases de données NoSQL et sql dépend du concept de partitionnement de base de données. Les avantages de pouvoir stocker plus de données augmentent lorsque les serveurs sont distribués, mais nous héritons également des problèmes liés à la distribution. Le partitionnement automatique n'est pas pris en charge par une base de données monolithique, et les ingénieurs devraient écrire manuellement une logique pour le gérer. Pour résoudre ce problème, un proxy, tel qu'un équilibreur de charge, peut être installé devant le service de requête et la base de données. Nous pouvons obtenir des requêtes plus rapides lorsque le fragment est volumineux, car ce proxy peut à nouveau être utilisé. En raison du manque d'utilisateurs finaux qui en sont conscients, la mise à l'échelle des bases de données NoSQL est en grande partie invisible.
Chaque fragment est unique, contrairement à une architecture maître-esclave. S'il y a des requêtes de lecture sur le fragment maître, une demande sera envoyée aux fragments esclaves. Au niveau du centre de données, nous pouvons répliquer la base de données pour nous assurer d'avoir une sauvegarde. Le nœud est un nœud qui peut communiquer et échanger des informations avec d'autres nœuds. Chaque nœud communique avec un nombre fixe d'autres nœuds via un protocole. Étant donné que tous les nœuds sont égaux dans Cassandra, un nœud peut répliquer ses données de l'un à l'autre sans avoir à se soucier de perdre des données. Le protocole Gossip est l'une des nombreuses façons dont les nœuds peuvent partager des informations.
Une base de données distribuée peut présenter un certain nombre d'avantages en plus d'obtenir des propriétés supplémentaires. La réplication des données est un élément essentiel pour garantir la disponibilité. Lorsque vous utilisez la réplication asynchrone pour votre base de données, elle ne sera pas toujours complètement cohérente au début, mais elle le deviendra davantage avec le temps. Les bases de données SQL sont utilisées dans les applications financières qui nécessitent une grande précision des données, tandis que les bases de données NoSQL sont utilisées dans des applications moins importantes telles que le nombre de vues.
La mise à l'échelle verticale fait référence au processus d'augmentation progressive de la charge de travail informatique avec l'utilisation de mises à niveau matérielles. Passer à une architecture distribuée et ajouter plus d'ordinateurs pour résoudre notre problème implique une mise à l'échelle, également appelée mise à l'échelle horizontale ou mise à l'échelle.
NoSQL peut prendre en charge la mise à l'échelle basée sur les méthodes horizontales.
MongoDB, en tant que base de données NoSQL, est évolutive car ses données ne sont pas stockées dans des bases de données relationnelles. Les données sont stockées sous forme de documents de type JSON facilement accessibles via une requête HTTP. La distribution de documents peut être effectuée horizontalement sur plusieurs nœuds à l'aide de cette méthode.
Comment mettre à l'échelle la base de données Nosql ?
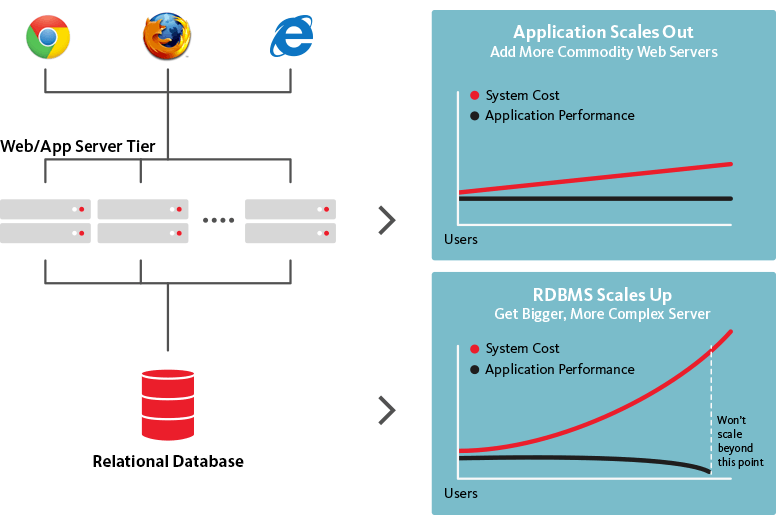
Les bases de données NoSQL, d'autre part, sont évolutives horizontalement, ce qui signifie qu'elles peuvent gérer un trafic accru selon les besoins en ajoutant simplement plus de serveurs à la base de données. Parce que les bases de données NoSQL peuvent être transformées en structures beaucoup plus grandes et plus puissantes, c'est le choix logique pour les grands ensembles de données et les bases de données en constante évolution.
Pour que ce didacticiel fonctionne, vous devez disposer d'un environnement Node.js opérationnel. Dans cet article, je vais décompresser les fichiers DynamoDB dans un dossier nommé nodejs-dynamodb-sample. Pour une version détaillée de ceci, rendez-vous sur ma page GitHub : https://www.gofundme.com/adamfowleruk/nodesurvey.html. L'exemple d'application peut rechercher et récupérer des informations sur les films à partir de DynamoDB. Nous allons stocker les données dans S3 sur Amazon Web Services et accéder à DynamoDB via le service de gestion des identités et des accès (IAM) d'Amazon. Pour utiliser le service In-App Analytics d'Amazon, vous devez d'abord vous inscrire et créer un compte. Notez l'année et le titre de chaque film que vous souhaitez POSTER /films.
Vous pouvez entrer un champ key'ed pour trouver des films d'une certaine année. Ensuite, vous pouvez concevoir votre propre application à partir de zéro. Vous pouvez utiliser vos tableaux jusqu'à ce que vous les ayez terminés, mais vous devez les supprimer une fois qu'ils ont été utilisés. Visitez la console DynamoDB sur Amazon Web Services pour voir la quantité de stockage que vous avez utilisée jusqu'à présent. L'onglet "Films" vous permet de visualiser les éléments d'un tableau et les métriques de votre application, ainsi que le coût mensuel estimé par mois dans l'onglet Capacité. Ce code se trouve sur ma page GitHub : https://github.com/adamfowleruk/nodejs-dynamodb-sample.
MongoDB, Apache HBase et Cassandra sont trois bases de données NoSQL idéales pour une mise à l'échelle horizontale. Comme leurs structures de données sont plus horizontales, cela facilite l'ajout de serveurs supplémentaires au système, tout en éliminant la nécessité de les modifier. De plus, ces bases de données sont relativement nouvelles, elles sont donc encore en cours de développement et de perfectionnement, ce qui signifie qu'elles sont susceptibles de s'améliorer au fil du temps.
Pourquoi est-il facile de faire évoluer Nosql ?
Nosql est facile à mettre à l'échelle car il est conçu pour être évolutif horizontalement. Cela signifie qu'il peut évoluer en ajoutant plus de nœuds à un cluster nosql . Nosql est également facile à mettre à l'échelle car il peut gérer de grandes quantités de données et un grand nombre de requêtes par seconde.
Les applications nécessitent un haut niveau d'évolutivité pour fonctionner correctement. Choisir des magasins de données avec une interface utilisateur simple et efficace est tout aussi important. Le principal point de discorde est de savoir si l'utilisation d'une base de données 'ASL' ou 'Nosql' est préférable. Les bases de données NoSQL, par opposition aux bases de données SQL, sont populaires car elles sont simples à construire. L'arrêt de toutes les opérations dans une base de données NoSQL dépend intrinsèquement du partitionnement. En général, chaque opération de données nécessite l'utilisation d'un opérateur de qualification, qui peut être utilisé pour identifier un nœud avec les données. Les données sont stockées sur plusieurs machines, ce qui facilite grandement l'exécution d'opérations sur les données, même sur les plus petites machines.

En conséquence, les magasins NoSQL peuvent évoluer pour utiliser une machine de base relativement simple. Il est supposé que les utilisateurs planifieront et structureront les données de manière à ce qu'elles puissent être récupérées en une seule fois depuis le même nœud pour effectuer une opération spécifique sur la base de données NoSQL. La dénormalisation des données de cette manière pourrait également impliquer que le nœud est prêt à exécuter des données précuites. Les jointures en NoSQL sont possibles, mais elles ne sont pas aussi robustes que les jointures SQL. Dans le monde pratique de NoSQL, les concepteurs d'applications pensent que la cohérence des données finira par se produire. En plus de fournir des commutateurs pour ajuster la cohérence entre différents systèmes NoSQL, de nombreux systèmes NoSQL fournissent des routines pour rendre la cohérence plus visible. Une partie importante de toute décision d'architecture consiste à évaluer le cas d'utilisation et à choisir le magasin de données approprié en fonction de ce cas.
Toutes les bases de données Nosql sont-elles évolutives ?
À la suite de l'ère d'Internet et du cloud computing, des bases de données NoSQL ont été créées afin de faciliter la mise en œuvre d'une architecture évolutive. l'évolutivité est obtenue en combinant le stockage des données avec le travail nécessaire pour les traiter sur un grand nombre d'ordinateurs dans une architecture évolutive.
Le système doit être capable de gérer des bases de données extrêmement volumineuses avec une latence très faible tout en gérant des taux de requêtes très élevés. Lorsqu'il s'agit de sites Web à grand volume comme eBay, Amazon, Twitter et Facebook, l'évolutivité et la haute disponibilité sont essentielles. Vous pouvez exécuter plusieurs instances d'un serveur en même temps avec une mise à l'échelle horizontale.
La base de données de MongoDB est évolutive à la fois horizontalement et verticalement, à la fois en termes d'échelle et de nombre d'utilisateurs. Dans MongoDB, vous pouvez faire évoluer votre cluster verticalement ou horizontalement en ajoutant plus de ressources et en divisant vos données en plus petits morceaux. Par conséquent, MongoDB est un choix populaire pour les applications et les magasins de données à grande échelle .
Meilleures bases de données Nosql pour une mise à l'échelle rapide et un volume de données élevé
D'autres bases de données NoSQL peuvent être mises à l'échelle pour répondre à vos besoins spécifiques, tout comme vous le pouvez avec d'autres bases de données. MongoDB, par exemple, est un langage de programmation populaire car il peut évoluer rapidement et gérer un grand nombre de données. Les banques de données basées sur Redis sont largement utilisées en raison de leurs capacités en mémoire et de leur vitesse.
Mise à l'échelle verticale Nosql
Les bases de données Nosql sont évolutives horizontalement, ce qui signifie qu'elles peuvent gérer un trafic accru en ajoutant plus de nœuds au système. Cela contraste avec la mise à l'échelle verticale, où le système est mis à l'échelle en ajoutant plus de ressources à un seul nœud.
Chaque base de données doit être mise à l'échelle pour gérer le volume de données générées quotidiennement. Le terme « mise à l'échelle » est classé en deux types : vertical et horizontal. Si vous souhaitez stocker plus de données, vous devez investir dans un serveur de 2 To. Un serveur unique devient de plus en plus cher et plus gros. Le processus d'ajout de machines à un serveur entraîne une mise à l'échelle horizontale. Dans ce cas, les données sont divisées en un ensemble et distribuées sur plusieurs serveurs ou partitions. Parce qu'il suit le modèle de dénormalisation, il n'y a pas besoin d'un seul point de vérité. Cette approche peut ne pas entraîner une mise à jour des informations lorsque le maître ne parvient pas à effectuer une écriture, car elle ne met pas à jour les informations sur les répliques esclaves lorsque le maître ne parvient pas à effectuer une écriture.
Qu'est-ce que la mise à l'échelle verticale dans SQL ?
L'objectif de l' approche de mise à l'échelle verticale est d'augmenter la capacité d'une seule machine en augmentant les ressources du même serveur logique. Les logiciels existants doivent être mis à niveau avec des ressources telles que la mémoire, le stockage et la puissance de traitement afin de fonctionner au mieux.
Comment mettre à l'échelle horizontalement la base de données
Qu'est-ce que la mise à l'échelle horizontale et comment ça marche ? Une méthode de mise à l'échelle horizontale est une méthode qui nécessite l'ajout de nœuds supplémentaires afin de s'adapter à la charge. Ceci est extrêmement difficile avec les bases de données relationnelles en raison de la difficulté à distribuer les données associées entre les nœuds.
En plus d'ajouter plus d'instances pour partager la charge, la mise à l'échelle horizontale (ou la mise à l'échelle horizontale) implique d'augmenter le nombre d'instances d'une application ou d'un service. En revanche, la mise à l'échelle verticale nécessite l'ajout de ressources supplémentaires à l'instance, telles que la puissance du processeur et la mémoire. En raison des protocoles sous-jacents de HTTP, de la majorité des applications Web et des API, ils peuvent être facilement mis à l'échelle indépendamment les uns des autres. Certaines bases de données vous permettent désormais de synchroniser et de partager vos données écrites entre plusieurs instances. Si le trafic est acheminé de cette manière, davantage de ressources sont dédiées aux éléments les plus fréquemment demandés. Bien que les proxys inverses soient couramment utilisés pour gérer les requêtes HTTP, les bases de données ne sont pas toujours utilisées pour le faire. La plupart des bases de données peuvent être transmises avec des logiciels tels que nginx ou HAproxy, qui peuvent tous deux être effectués au niveau TCP.
Si votre proxy peut comprendre le fonctionnement des connexions au niveau du protocole, il peut déterminer si un réplica en lecture est désynchronisé ou incapable de réagir même si la connexion réseau est active. La route peut être ajustée en fonction de la charge sur la réplique ainsi que du nombre de connexions. Certains serveurs proxy peuvent exécuter diverses fonctions. Quelques avancées ont été réalisées dans les volumes persistants et les réclamations, mais il existe également des difficultés inhérentes si vous ne sélectionnez pas une base de données qui valorise chaque instance de manière égale. Étant donné que les conteneurs sont déplacés dans le cluster, le redémarrage de l'un de vos réplicas en lecture devrait suffire. Si cela arrive à la base de données principale , vous ne serez probablement pas ravi.