
Solr - Une plate-forme de recherche puissante
Publié: 2022-11-18Solr est une plateforme de recherche puissante qui vous permet d'interroger très rapidement de grandes quantités de données. Il est construit au-dessus de la bibliothèque de recherche Apache Lucene et fournit une API de type REST pour une intégration facile avec votre application. L'une des principales caractéristiques de Solr est son évolutivité - il peut gérer facilement des milliards de documents et de requêtes. Solr est souvent décrit comme une base de données NoSQL car il n'utilise pas le modèle de base de données relationnelle traditionnel. Cependant, il est important de noter que Solr n'est pas une base de données traditionnelle et ne doit pas être utilisée comme telle. Il est conçu pour l'indexation et la recherche, pas pour le stockage de données. Si vous avez besoin de stocker des données, vous devez utiliser une base de données NoSQL telle que MongoDB ou Cassandra.
Avec Elasticsearch comme seul projet open source capable de rivaliser avec Solr, Solr est l'un des deux moteurs de recherche open source les plus populaires au monde. NoSQL signifie Not Only SQL, ce qui signifie qu'il utilise des langages de requête distincts du SQL traditionnel et pas seulement des bases de données. Malgré son excellente fonctionnalité de recherche en texte intégral, Solr peut être extrêmement utile dans une base de données NoSQL. Les données de santé ont été extraites directement de HBase via les anciennes applications Explorys et Worklist. Solr a donné à Worklist trois fonctionnalités essentielles : il était extrêmement facile à utiliser et les fonctionnalités étaient très intuitives. Le processus de filtrage et de tri est très efficace. Étant donné que le filtrage de Solr est basé sur les ID de document et la mise en cache, il peut calculer presque instantanément le nombre de documents qui répondent aux critères de filtrage.
Solr est une excellente solution de base de données NoSQL qui est fréquemment associée à d'autres services de Big Data. Nous avons fourni des commentaires immédiats à nos utilisateurs alors qu'ils travaillaient sur l'ajout et la configuration de filtres en envoyant le paramètre rows=0 à Solr. Il est essentiel de considérer plus que la simple maintenance d'un schéma Solr afin de créer un moteur de recherche qui soit pertinent.
Pouvez-vous utiliser Solr comme base de données ?
Oui, vous pouvez utiliser Solr comme base de données. C'est un puissant moteur de recherche qui peut être utilisé pour indexer et rechercher des données. Il peut être utilisé pour stocker des données dans un format structuré et pour les récupérer rapidement.
L'utilisation d'un index de recherche comme base de données est-elle incorrecte ? Dans mon cas, j'ai eu une idée similaire pour stocker quelques éléments de données de base dans Solr. Cependant, le processus de mise à niveau de Solr m'a fait changer d'avis et je dois admettre que je me suis trompé. Si vous avez mis à jour 2 versions majeures mais que vous n'avez pas réindexé (par exemple, supprimer les documents originaux puis les fichiers d'index eux-mêmes), le noyau n'est plus reconnu.
Algolia, Elastic Observability, Coveo et Yext ne sont que quelques-unes des alternatives populaires à Apache Solr. Algolia est un moteur de recherche en langage naturel qui analyse et traite les requêtes de recherche en fonction de ce que nous savons d'une personne ou d'un sujet en langage naturel. Elastic Observability est une plateforme de données qui fournit des informations en temps réel sur les données et les applications. Coveo, une plateforme de marketing sur les moteurs de recherche, vous permet de cibler et de mesurer vos efforts de marketing sur les moteurs de recherche. En utilisant Yext, vous pouvez cibler et mesurer vos campagnes de marketing sur les moteurs de recherche.
Quelles sont les bases de données Nosql ?
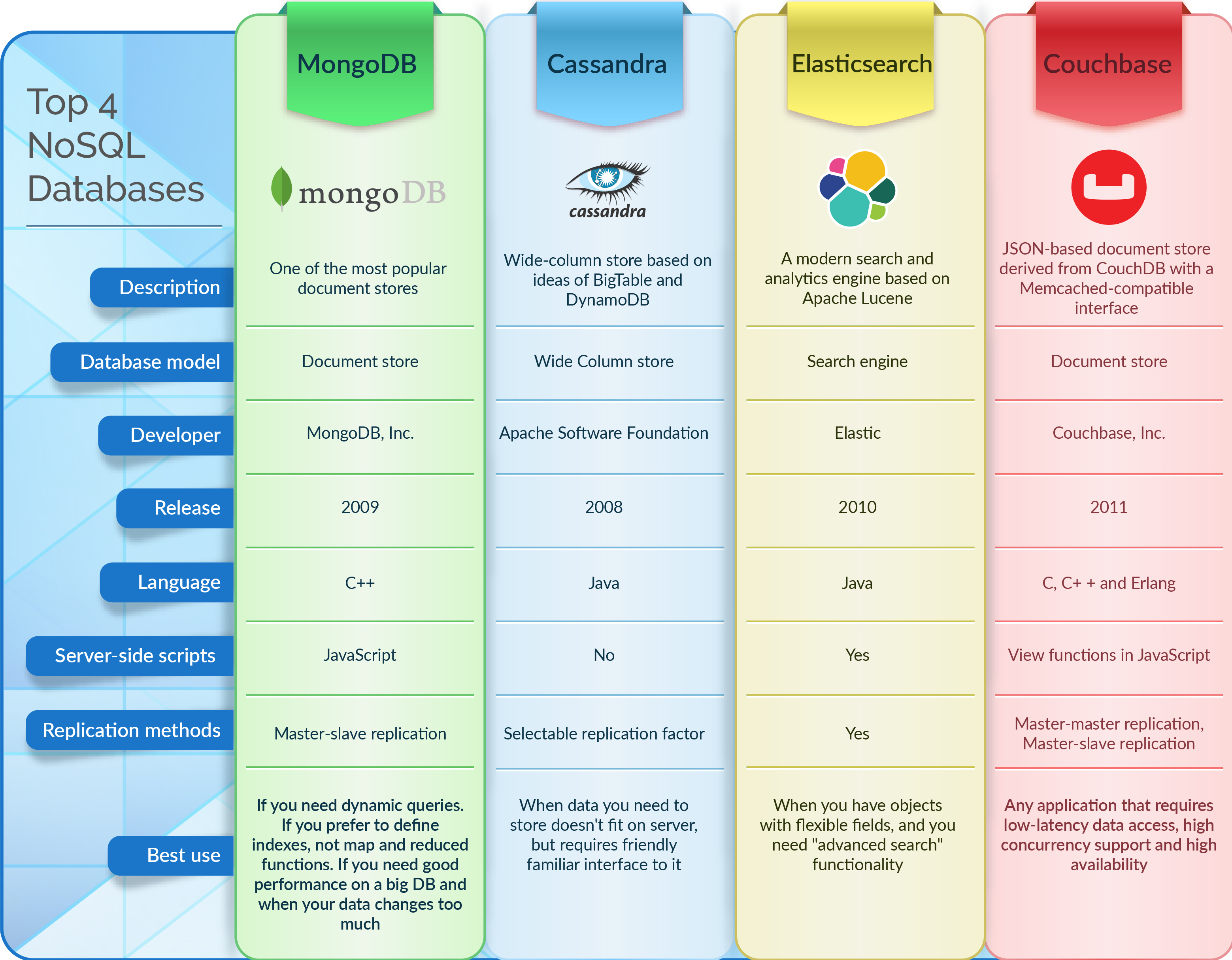
Les bases de données Nosql sont des bases de données qui n'utilisent pas le modèle de base de données relationnelle traditionnel. Au lieu de cela, ils utilisent une variété de modèles, y compris des bases de données de valeurs-clés, de documents, de colonnes et de graphiques.
Les bases de données NoSQL basées sur des documents stockent les données de la même manière que les bases de données relationnelles. Le logiciel de gestion des données est conçu pour être adaptable, évolutif et capable de répondre aux besoins des entreprises modernes en temps opportun. Les bases de données de documents , les magasins clé-valeur, les bases de données à colonnes larges et les bases de données de graphes ne sont que quelques-uns des types de bases de données NoSQL. La majorité des 2000 plus grandes entreprises du monde adoptent rapidement des bases de données NoSQL pour alimenter des applications critiques. Dans ce contexte, cinq tendances présentent des défis techniques trop difficiles à relever pour la majorité des bases de données relationnelles. En raison du modèle de données fixe, les bases de données relationnelles constituent un obstacle majeur au développement agile. Le modèle d'application définit le modèle de données de NoSQL.
Les données doivent être modélisées dans un modèle NoSQL quelle que soit leur structure. Le format JSON est le format par défaut pour le stockage des données dans une base de données orientée document. Les cadres ORM peuvent être réduits de cette manière, ce qui réduit les frais généraux de développement d'applications. N1QL (prononcé nickel) est un langage de requête SQL vers JSON qui a été publié dans le cadre de Couchbase Server 4.0. L'outil prend également en charge l'agrégation (GROUP BY), le tri (SORT BY), les jointures (LEFT OUTER / INNER) et une variété d'autres fonctionnalités. Une base de données distribuée NoSQL avec une architecture évolutive, aucun point de défaillance unique et des avantages opérationnels convaincants est l'une des fonctionnalités les plus attrayantes. Alors que de plus en plus d'interactions avec les clients ont lieu en ligne via des applications Web et mobiles, la disponibilité est un problème.
Les bases de données NoSQL sont simples à apprendre et à utiliser. Ils sont destinés à stocker des informations, écrire et lire des livres. Ils sont également capables de gérer et de surveiller des clusters de différentes tailles à n'importe quelle taille. La réplication intégrée qui est incluse dans une base de données NoSQL distribuée est fournie par la base de données elle-même - aucun logiciel supplémentaire n'est requis. De plus, les routeurs matériels garantissent un accès immédiat et cohérent aux données critiques. Pendant que les administrateurs de base de données enquêtent sur un problème, les applications n'ont pas besoin d'attendre que la base de données découvre un problème avant d'effectuer leur propre récupération. La technologie NoSQL gagne en popularité en tant que plate-forme pour les applications Web, mobiles et IoT d'aujourd'hui.
Il existe de nombreuses raisons pour lesquelles les bases de données NoSQL deviennent de plus en plus populaires. Ils peuvent être mis à l'échelle pour répondre aux besoins des grandes organisations et ils sont adaptables. À titre d'exemple, considérons Ryanair et Marriott comme clients de MongoDB. Ces organisations, en plus d'utiliser MongoDB pour alimenter leurs applications mobiles et leurs systèmes de réservation, l'utilisent également pour alimenter leurs sites Web. Le système de gestion de contenu Presto de la société est également construit avec NoSQL. Le système aide à la gestion efficace du contenu exclusif de l'entreprise.
L'avenir du travail L'avenir du travail est éloigné
Qu'est-ce qui n'est pas une base de données Nosql ?
Quelle est la différence entre les bases de données NoSQL et non NoSQL ? Microsoft SQL Server, le système de gestion de bases de données relationnelles de l'entreprise, est le produit principal.
À la fin des années 2000, les bases de données NoSQL ont mis l'accent sur la mise à l'échelle, les résultats rapides des requêtes et la simplification de la programmation. Les bases de données NoSQL sont simples à créer car elles disposent d'un modèle de données flexible, d'un modèle de données évolutif et d'une interface utilisateur simple à utiliser. Les bases de données relationnelles SQL (Structured Query Language) sont généralement construites avec des schémas rigides, complexes et tabulaires, ainsi qu'une mise à l'échelle verticale prohibitive. La version 4.0 de MongoDB incluait la prise en charge des transactions ACID multi-documents, et sa version 4.2 ajoutait la prise en charge des clusters fragmentés. Il n'y a pas de modèles de données dans la liste. Dans la plupart des bases de données NoSQL, les requêtes sont optimisées plutôt que la duplication des données. De plus, certains No.
Les bases de données NoSQL prennent en charge la compression afin de réduire les empreintes de stockage. Les bases de données de graphes, par exemple, peuvent être utiles pour analyser les relations, mais elles peuvent ne pas être les plus pratiques pour récupérer des données quotidiennes. L'utilisation de MongoDB ou d'une autre base de données dans votre cas d'utilisation sera démontrée dans le livre blanc Où utiliser MongoDB. L'utilisation de MongoDB Atlas comme point de départ est l'un des moyens les plus simples d'apprendre les bases de données NoSQL. MongoDB University propose une formation en ligne entièrement gratuite pour vous aider à apprendre MongoDB.
Les bases de données NoSQL présentent cependant certains inconvénients. Les bases de données NoSQL, en plus d'être sans ACID, n'ont pas les mêmes propriétés que les bases de données relationnelles. Les transactions dans votre application peuvent entraîner des problèmes si votre système en dépend. De plus, les bases de données NoSQL n'offrent généralement pas le même niveau de flexibilité d'exécution que les bases de données SQL. Vous devez éviter d'utiliser des bases de données NoSQL si votre application doit modifier dynamiquement ses modèles de données.
Lequel des éléments suivants n'est pas une base de données ?
Étant donné que toutes les requêtes, rapports et tables sont liés à des bases de données, les relations ne sont pas des objets de base de données ; ils sont liés aux mathématiques.
Mongodb est-il une base de données Nosql ?
Le programme de gestion de base de données MongoDB NoSQL est open source et gratuit. Le langage NoSQL est une alternative aux bases de données relationnelles traditionnelles. Les bases de données NoSQL sont excellentes pour la distribution de données à grande échelle. Les informations orientées document peuvent être gérées, stockées ou récupérées à l'aide de MongoDB, qui est un outil de gestion de documents.
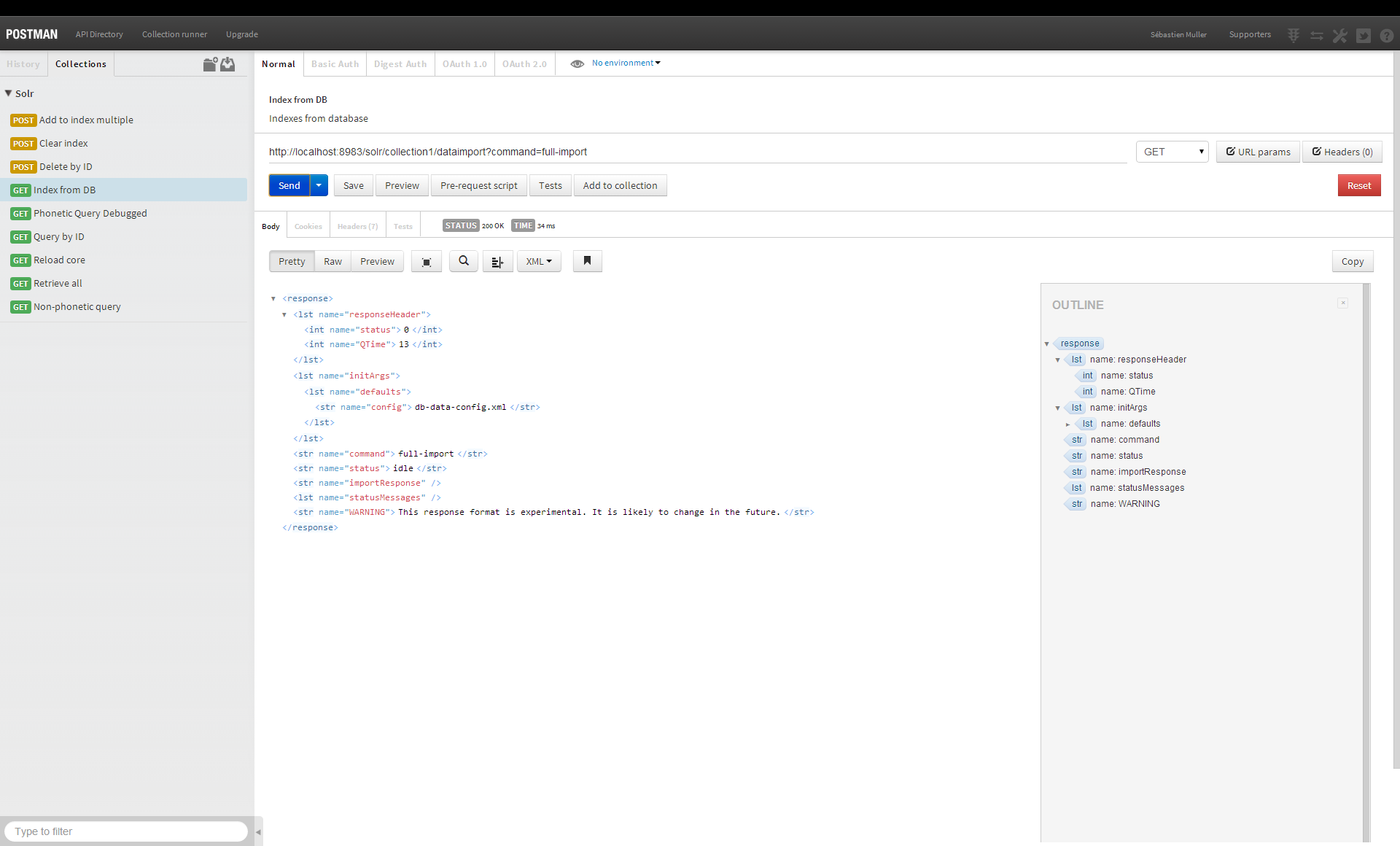
Comment Solr stocke-t-il les données
Apache Solr indexe les données dans le système de fichiers local, comme son nom l'indique. Grâce au HDFS (Hadoop Distributed File System), les utilisateurs peuvent profiter de nombreux avantages, notamment un stockage à grande échelle et distribué avec des capacités de redondance et de basculement. Apache Solr inclut la prise en charge de HDFS.
Contrairement à de nombreux autres moteurs de recherche, Solr peut produire des résultats immédiats car il recherche un index plutôt que de rechercher directement le texte. En scannant l'index à la fin d'un livre, l'index peut être utilisé pour récupérer des pages liées à un mot-clé. Cet index est stocké dans le répertoire de données sous la forme d'un index dans un répertoire dit répertoire de données. Le moteur de recherche Solr est alimenté par Lucene, un moteur de recherche en texte intégral open source. La relation entre Solr et Lucene est similaire à celle d'une voiture et de son moteur. Nous passerons en revue les différences entre Lucene et Solr en détail dans cet article.

Comment utiliser les champs stockés dans Sol
Le format de champ d'un document est utilisé dans Solr. Un document peut contenir une certaine forme de champ, qui est simplement une collection de données. Lorsque vous recherchez un document à l'aide de Solr, les résultats incluront les correspondances pour tous les champs du document qu'il indexe.
Un champ stocké est un champ qui n'a pas besoin d'être recherché mais doit toujours être affiché lors de la recherche de quelque chose. Dans Solr, ceux-ci sont appelés champs stockés. Solr indexe tous les champs stockés grâce à son algorithme d'indexation. Ainsi, lorsque vous recherchez un document, Solr renvoie des résultats qui incluent tous les champs stockés.
Le stockage des champs présente de nombreux avantages. Si vous souhaitez afficher le titre d'un document dans la liste des résultats, vous devrez peut-être enregistrer le titre sous forme de fichier. Si vous voulez être en mesure de trouver tous les documents que vous avez déjà recherchés en utilisant le même ID, vous pouvez suivre l'ID d'un document grâce à plusieurs recherches.
Les résultats de la recherche peuvent également être affichés en stockant des champs. Le titre d'un document peut apparaître dans la liste des résultats s'il est étiqueté. Vous pouvez également afficher l'ID du document afin de pouvoir le trouver facilement en recherchant le document sur plusieurs sites.
Les capacités de Solr incluent la possibilité d'indexer les données ainsi que de les stocker. Pour indexer un document, Solr doit d'abord créer une base de données de tous les champs qu'il contient, puis les informations sur la position de chaque champ seront enregistrées. Vous pouvez rechercher et afficher des résultats à partir de ce type d'informations.
En plus de ses puissantes capacités de recherche, Solr vous permet d'utiliser de puissantes applications de récupération de documents. Lorsque vous fournissez des données aux utilisateurs en fonction de leur requête, elles sont basées sur leur requête.
Tutoriel de base de données Solr
Une base de données solr est un type de base de données qui utilise le logiciel solr pour indexer et rechercher des données. C'est un outil puissant qui peut être utilisé pour indexer et rechercher très rapidement de grandes quantités de données.
Étant donné que ce didacticiel a été vérifié avec Solr 8, il peut également fonctionner avec des versions plus anciennes. Le champ id est déjà prédéfini dans chaque Lucene et Solr, il faut donc comprendre quels types de champs il peut indexer correctement. Les champs dynamiques peuvent être créés à la volée sans avoir besoin de pré-définition, ce qui vous permet de les modifier à tout moment. La bibliothèque Lucene que Solr utilise pour la recherche en texte intégral utilise des instantanés ponctuels qui doivent être actualisés régulièrement pour s'assurer que de nouveaux détails sont présentés aux requêtes. Solr, contrairement au format de données indépendant JSON ou XML, est indépendant du format de données.
Comment utiliser le moteur de recherche Solr en Java
Le client Java est requis pour se connecter au serveur Solr, utilisez donc le fichier org.apache.solr.client.solrjimpl. La classe qui utilise le protocole HttpSolrServer est nommée HttpSolrServer. Cette classe utilise Java Socket pour communiquer avec le serveur Solr. Lorsque vous créez une application serveur Solr, vous devez d'abord charger les classes appropriées. En Java, par exemple, la fonctionnalité de recherche Solr est accessible à l'aide du fichier org.apache.solr.client.solrj.impl. La classe org.apache.solr.client.solrj.request est le composant de la classe SolrServer. Cette classe crée une classe RequestHandler. Ce puissant moteur de recherche vous permet de trouver facilement les informations dont vous avez besoin. Pour accéder au serveur Solr, utilisez le client Java.
Solr contre Lucene
En ce qui concerne les projets Apache Solr et Lucene, ils sont constitués des mêmes composants. Apache Solr, d'autre part, est un serveur autonome, mais avec de nombreuses fonctionnalités avancées. Apache Lucene, quant à lui, est une solution basée sur une bibliothèque Java qui indexe (stocke) et recherche des données.
En raison de son cache, Solr a un avantage dans le domaine des données statiques, ce qui peut faciliter la récupération des résultats. Les données de séries chronologiques sont fréquemment traitées par Elasticsearch, qui utilise ses filtres et ses capacités de regroupement, en plus des données de séries chronologiques.
Solr contre Elasticsearch
Il n'y a pas de réponse définitive à cette question car cela dépend des besoins et des préférences de chacun. Cependant, certaines différences clés entre Solr et Elasticsearch incluent :
-Solr est basé sur un modèle de base de données relationnelle traditionnel, tandis qu'Elasticsearch utilise une approche orientée document.
-Solr est généralement plus rapide pour l'indexation et la recherche de grands ensembles de données, tandis qu'Elasticsearch est généralement plus évolutif.
-Solr prend en charge des fonctionnalités de requête plus avancées telles que les jointures et les objets imbriqués, tandis qu'Elasticsearch a une syntaxe de requête plus simple.
Il existe une grande communauté de contributeurs aux deux technologies et une assistance d'experts est disponible. Elasticsearch était auparavant connu sous le nom d'Apache 2.0 et était open source. À partir de 2021 avec la sortie de la version 7.11, Elasticsearch sera libre d'utilisation sous la licence publique côté serveur. Il est destiné aux recherches de texte au niveau de l'entreprise qui nécessitent la récupération d'informations et/ou une analyse. Les recherches en texte intégral sont également possibles dans Elasticsearch, et des documents riches tels que PDF et Word peuvent être lus. Elasticsearch nécessite plus de mémoire de tas que Solr (1 Go contre 512 Mo), mais ces valeurs par défaut peuvent être modifiées. La plate-forme Elasticsearch permet une plus grande automatisation en combinant le rééquilibrage des clusters avec le nettoyage des données, qui est généralement sans intervention.
Le sharding est une méthode de distribution de données sur plusieurs serveurs prise en charge par Solr et Elastic. Solr et ElasticSearch sont des bases de données de moteurs de recherche populaires avec de grandes communautés impliquées et des capacités similaires. Elasticsearch est plus convivial que Solr, plus facile à mettre à l'échelle et offre de meilleures capacités d'analyse et de requête. La bibliothèque Apache Tika, utilisable par les deux bases de données, leur permet d'effectuer des recherches en texte intégral et de lire des documents riches.
Utilisation d'Apache Solr
Parce qu'il peut indexer et rechercher des documents et des pièces jointes, ainsi qu'indexer et rechercher plusieurs sites Web, il s'agit d'un outil populaire pour les sites Web ainsi que pour la recherche d'entreprise.
Il s'agit d'une plate-forme de recherche open source utilisée pour créer des applications de recherche. Il est basé sur le célèbre moteur de recherche en texte intégral Lucene . Solr est une plate-forme cloud native hautement flexible, prête pour les opérations d'entreprise. Les requêtes parallèles ont été activées dans la version la plus récente de Solr, Solr 6.0, qui a été publiée en 2016. La plate-forme Solr nous permet de mettre à l'échelle, de distribuer et de gérer des index pour des applications (Big Data) à grande échelle. Lorsque vous travaillez avec Solr, vous n'avez pas besoin d'être un programmeur avec des compétences Java. Au lieu de Lucene, il fournit un service très simple et facile à utiliser pour créer un champ de recherche qui inclut la saisie semi-automatique.
Les nombreux avantages d'Apache Sol
Le moteur de recherche Apache Solr est un moteur de recherche populaire parmi les petites et les grandes organisations. Ce logiciel est très polyvalent, ce qui lui permet d'être utilisé dans une variété de situations, y compris l'analyse et la récupération de données. Solr est un service qui offre des capacités de recherche d'entreprise, ce qui en fait un choix idéal pour gérer de grandes quantités de données.
Solution de base de données Nosql utile
Il existe aujourd'hui de nombreuses solutions de base de données NoSQL utiles . Les bases de données NoSQL sont souvent plus évolutives et performantes que les bases de données relationnelles traditionnelles. Ils sont également généralement plus flexibles, ce qui facilite la modélisation des données et l'évolution des schémas. Certaines bases de données NoSQL populaires incluent MongoDB, Cassandra et HBase.
Les bases de données NoSQL ne seront plus utilisées par les développeurs à l'avenir. L'avenir est ici où ces bases de données seront un outil commun pour alimenter les applications populaires. Vous ne savez peut-être pas que certaines applications populaires s'exécutent sur des bases de données NoSQL et pourquoi NoSQL est idéal pour ces applications. En 1996, Forbes a été la première publication commerciale à lancer un site Web. Forbes a migré son service vers MongoDB Atlas afin de répondre aux besoins de ses 140 millions d'utilisateurs en ligne. En raison de l'impact de la pandémie de COVID-19, la publication est passée à une infrastructure cloud et a pu faire face à des moments difficiles. BangDB a été choisi par Accenture comme base de données NoSQL pour son application de notation des prospects.
Facebook Messenger s'exécute sur la base de données Cassandra NoSQL sans point de défaillance unique, ce qui lui permet de faire évoluer ses opérations sur plusieurs plates-formes. Bigtable est un composant de Google Mail qui assiste Google Bigtable, une société en ligne qui gère une variété de transactions Google Mail. La base de données Espresso garantit que toutes les applications LinkedIn peuvent fonctionner normalement. Téléchargez BangDB gratuitement pour voir si c'est le bon outil pour vous.
Les avantages des bases de données Nosql
De nombreuses bases de données NoSQL peuvent être utilisées pour stocker et modéliser des données structurées, semi-structurées et non structurées dans une seule base de données, ce qui les rend idéales pour stocker et modéliser les structures et la sémantique des données. Elles peuvent être plus performantes et plus stables que les bases de données relationnelles traditionnelles, et elles peuvent être plus faciles à mettre en œuvre pour les développeurs. Avec la popularité croissante des bases de données NoSQL, elles devraient continuer à gagner en popularité.
Mongodb »
MongoDB est un puissant système de base de données orienté document. Il dispose d'une fonction de recherche basée sur un index qui rend la récupération des données rapide et facile. MongoDB offre également une fonctionnalité d'évolutivité, lui permettant de gérer des données à grande échelle.