
Les différents types de clusters informatiques
Publié: 2023-02-16En informatique, un cluster est un groupe de systèmes informatiques indépendants qui fonctionnent ensemble de sorte que, à bien des égards, ils peuvent être considérés comme un système unique. Les clusters sont généralement déployés pour améliorer les performances et la disponibilité par rapport à celles d'un seul ordinateur, tout en étant généralement beaucoup plus rentables que des ordinateurs uniques de vitesse ou de disponibilité comparables. Il existe différents types de grappes d'ordinateurs, y compris les grappes de calcul haute performance, les grappes d'ordinateurs utilisées à des fins commerciales et les grappes de stockage. Dans chaque type de cluster, les systèmes composants fonctionnent ensemble pour effectuer une ou plusieurs tâches communes. Les clusters de calcul haute performance (HPC) sont utilisés pour les applications scientifiques et d'ingénierie qui nécessitent une grande puissance de calcul et/ou de stockage de données. Ces clusters consistent généralement en un groupe d'ordinateurs de base, connectés par un réseau local (LAN) rapide. Les ordinateurs d'un cluster HPC exécutent généralement le même système d'exploitation (OS) ou un système d'exploitation similaire et ont des composants matériels identiques ou similaires. Les clusters commerciaux sont utilisés pour exécuter des applications métier qui nécessitent un degré élevé de disponibilité et/ou d'évolutivité. Ces clusters sont souvent constitués de serveurs qui exécutent une variété de systèmes d'exploitation et ont une variété de composants matériels. Dans de nombreux cas, les serveurs d'un cluster commercial sont également connectés à un réseau de stockage (SAN) afin qu'ils puissent accéder à des magasins de données communs. Les clusters de stockage sont utilisés pour fournir un référentiel de stockage centralisé auquel un groupe d'ordinateurs peut accéder. Les clusters de stockage consistent généralement en un groupe de serveurs de stockage connectés à un SAN. Les serveurs d'un cluster de stockage exécutent généralement une variété de systèmes d'exploitation et ont une variété de composants matériels.
Qu'est-ce qu'un cluster mongodb fragmenté et quel est l'intérêt de s'y connecter dans MongoDB ? Comment puis-je me connecter à l'un ou simplement me connecter au localhost ? La médaille d'or est décernée dans l'insigne Noob 7461. Dix insignes d'argent et 23 insignes de bronze ont été produits. Un cluster répliqué est composé de dix serveurs, un pour l'interface mongos, trois pour chaque jeu de répliques et un pour chaque jeu de répliques de serveur de configuration. Dans un système de réplication, un composant est dupliqué afin qu'il y ait toujours une sauvegarde en cas de problème. Tous les fragments doivent être des répliques pour pouvoir être fabriqués.
Un cluster mongodb, par exemple, est couramment utilisé pour décrire un cluster fragmenté dans MongoDB. Un mongodb partitionné remplit les fonctions suivantes : Scale lit et écrit à partir de plusieurs nœuds. Étant donné que chaque nœud ne gère pas l'intégralité de l'ensemble de données, vous ne pouvez partitionner les données qu'en régions dans la partition.
Un cluster de bases de données , comme son nom l'indique, est un ensemble de bases de données pouvant être exécutées par une instance d'un serveur de base de données en cours d'exécution. Postgres, qui signifie base de données « par défaut » dans PostgreSQL, sera inclus en tant que base de données par défaut dans un cluster de bases de données après sa création.
Un cluster MongoDB peut également être appelé « jeu de réplicas » ou « cluster fragmenté ». Dans un jeu de répliques, plusieurs serveurs transportent des copies des mêmes données. Les nœuds d'un jeu de répliques sont généralement trois. Lorsqu'une application cliente effectue des opérations sur un nœud, toutes les lectures et écritures sont envoyées à ce nœud ; en cas de problème, deux nœuds secondaires le protègent.
Le cluster et la base de données sont-ils identiques ?
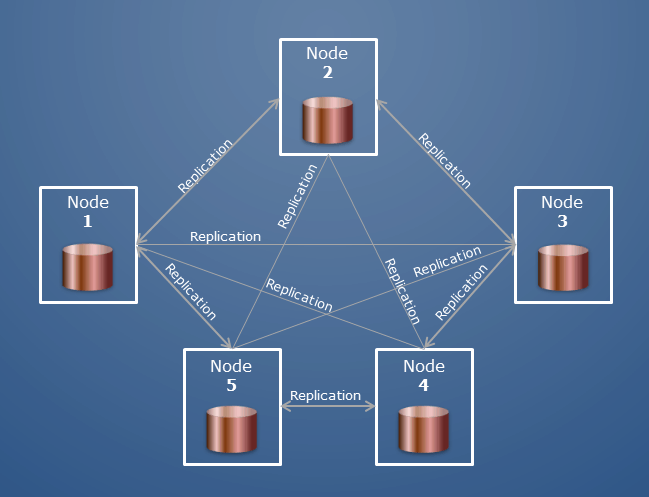
Plusieurs clusters d'hôtes constituent un cluster. Les hôtes d'un cluster partitionné sont classés dans une variété de rôles. Une base de données est une collection de collections ; dans Oracle, cela équivaudrait à une base de données et à un schéma.
Un cluster de bases de données est un ensemble de serveurs ou d'instances qui connectent une base de données à une autre. La mise en cluster de bases de données est utilisée par les serveurs pour diverses raisons, dont les principales sont la redondance des données, l'équilibrage de charge, la haute disponibilité, la surveillance et l'automatisation. Par conséquent, si un ordinateur tombe en panne, toutes nos données seront disponibles pour les autres, ce qui nous donne l'avantage de la redondance des données. Avec le clustering, il est possible d'automatiser de nombreux processus de la base de données tout en créant des règles pour identifier les problèmes potentiels. Dans l'architecture en cluster, toutes les requêtes sont acheminées vers un certain nombre d'ordinateurs, chacun étant capable de gérer la requête et de la produire pour l'utilisateur. Un cluster de basculement ou à haute disponibilité réplique les serveurs et reconfigure le matériel pour garantir la disponibilité du service. Ces types de clusters sont rentables pour les utilisateurs d'ordinateurs qui dépendent entièrement de leurs systèmes. L'objectif des clusters hautes performances est d'augmenter la capacité du réseau tout en améliorant les performances.
Dans un système distribué Hadoop, les nœuds agissent comme des centres de stockage et de traitement des données. La principale distinction entre un cluster et un serveur est que le cluster utilise plusieurs nœuds qui communiquent entre eux pour effectuer un ensemble d'opérations. Un cluster contient un certain nombre de nœuds qui effectueront un ensemble d'opérations. Le système distribué Hadoop peut prendre en charge jusqu'à 10 000 bases de données. Des résultats de requête similaires peuvent être obtenus lorsque les données de plusieurs tables de la même base de données sont combinées dans une requête de plusieurs bases de données du même cluster.
Les bienfaits du cluster
À l'aide d'un cluster, vous pouvez facilement gérer plusieurs bases de données en fournissant un stockage uniforme des tables et des colonnes sur chacune d'elles. Cela améliore les performances et l'intégrité des données, et rend ainsi le système plus efficace.
Où est le nom du cluster dans Mongodb ?
Il n'y a pas de réponse définie à cette question car le nom du cluster peut être trouvé à différents endroits selon le type de cluster MongoDB utilisé. Par exemple, dans un jeu de répliques, le nom du cluster est généralement stocké dans la collection local.system.replset, tandis que dans un cluster fragmenté, il se trouve généralement dans la collection config.shards.
MongoDB Atlas est une offre de base de données NoSQL en tant que service MongoDB en tant que service disponible dans les clouds publics Microsoft Azure, Google Cloud Platform et Amazon Web Services. Vous pouvez créer un cluster MongoDB fonctionnel en quelques minutes à l'aide de votre navigateur Web préféré en cliquant sur un lien pour le configurer. Il n'est pas nécessaire d'installer de logiciel sur votre poste de travail pour vous connecter au Web via celui-ci, et vous pouvez utiliser l'interface Web pour le faire. Lorsque des ensembles de répliques MongoDB sont utilisés conjointement avec plusieurs serveurs MongoDB, la redondance des données et la haute disponibilité sont assurées. Le cluster MongoDB dispose d'une capacité d'opérations de lecture supplémentaire, lui permettant de diriger les clients vers des serveurs supplémentaires. Dans une réplication, un ou plusieurs membres du jeu de réplicas sont répliqués de manière asynchrone de l'oplog du nœud principal vers les secondaires, permettant au jeu de réplicas de fonctionner malgré toute défaillance potentielle de ses membres. Dans MongoDB, vous pouvez effectuer des opérations de lecture et d'écriture supplémentaires en plus des commandes d'entrée et de sortie standard.
Dans la plupart des cas, le nœud principal est la source de toutes les opérations de lecture, mais le routage vers les secondaires peut être configuré. Le risque de données potentiellement obsolètes est plus élevé lorsque le nœud le plus proche est un nœud secondaire. Pour que l'écriture se propage correctement dans le cluster, vous devez inclure des options d'écriture de données dans un jeu de réplicas MongoDB. Dans le cadre de ce processus, une propriété de préoccupation d'écriture doit être ajoutée à insérer. Lorsqu'une demande d'écriture est reçue, le cluster est invité à reconnaître qu'il a réussi dans la grande majorité des nœuds porteurs de données. La configuration d'un cluster partitionné lui permet également d'être configuré en tant que jeu de répliques. Un jeu de répliques contient à la fois des processus mongod primaires et secondaires. En cas de défaillance du maître, il est recommandé que le nombre total de ces processus soit impair afin de s'assurer que la majorité est effectuée.
Les clusters MongoDB , comme leur nom l'indique, sont des clusters de nœuds qui fonctionnent ensemble pour stocker et gérer des données. Lors de la création d'un cluster MongoDB, vous spécifiez le nombre de nœuds à inclure et ce pour quoi ils doivent être configurés. Vous pouvez connecter votre application à votre cluster MongoDB avec Node une fois qu'il est créé. MongoDB Compass peut être considéré comme un pilote pour la bibliothèque MongoDB JS ou un pilote PyMongo pour MongoDB. Le principal avantage de connecter votre application à un cluster est qu'elle peut y lire et y écrire des données. Avec MongoDB Compass, vous pouvez explorer, modifier et visualiser vos données de différentes manières. Un exemple de la façon dont vous pouvez afficher vos données peut être trouvé dans une grille, qui vous permet d'observer comment les données changent au fil du temps et qui distribue les données dans votre cluster.
Où se trouve le cluster dans l'atlas de Mongodb ?
Il n'y a pas de réponse définitive à cette question car l'emplacement d'un cluster dans MongoDB Atlas peut varier en fonction d'un certain nombre de facteurs, notamment la région géographique dans laquelle il se trouve et les besoins spécifiques de l'application qu'il alimente. Cependant, en général, un cluster dans MongoDB Atlas se trouve dans la section "Clusters" de la console MongoDB Atlas.

Un cluster peut être soit un jeu de réplicas, soit un ensemble partitionné. Le nombre total de nœuds de chaque projet est limité par une contrainte spécifique basée sur leur gamme de fonctions dans les régions. Chaque projet Atlas peut déployer jusqu'à 25 bases de données. Veuillez contacter les administrateurs de base de données pour toute question concernant la limite de déploiement de la base de données. TLS version 1.2 est la version TLS par défaut pour les clusters créés après le 1er juillet 2020.
Qu'est-ce qu'un cluster dans Mongodb
Dans MongoDB, un cluster est un groupe de serveurs de base de données qui conservent des copies des mêmes données. Chaque serveur d'un cluster est appelé un nœud. Un cluster peut avoir un ou plusieurs nœuds.
À quoi sert le clustering de bases de données ? Le processus de connexion de plusieurs serveurs ou instances à une seule base de données est appelé connexion SQL. Dans MongoDB, un cluster est soit un jeu de répliques, soit un cluster fragmenté, selon le type de MongoDB. J'aborderai plus en détail chacun des aspects distincts de ces clusters dans les paragraphes suivants. En raison de l'équilibrage de charge et du nombre de machines de MongoDB, il a un haut niveau de disponibilité. Un cluster peut être utilisé pour automatiser de nombreux processus de base de données tout en permettant la création de règles pour alerter les problèmes potentiels. Une base de données MongoDB peut être divisée en deux types : les jeux de répliques et les clusters de partitionnement.
Les données sont stockées sur plusieurs machines dans un Shard. La méthode de MongoDB pour fournir l'évolutivité des données est basée sur cela. Cela réduit le temps nécessaire pour gérer de grandes quantités de données. En raison de la quantité de données fournies par les répliques, les applications distribuées peuvent également en bénéficier.
Des problèmes de performances et des conflits de données peuvent survenir si plusieurs projets Atlas sont déployés dans le même cluster. Atlas vous recommande de n'utiliser qu'un seul cluster gratuit par projet Atlas. Un bon outil de regroupement de données est requis dans un large éventail d'applications d'analyse de données et d'exploration de données. Pour éviter les problèmes de performances potentiels et les conflits de données dans les projets Atlas, Atlas vous recommande de n'utiliser qu'un seul cluster gratuit par projet.
Architecture de cluster Mongodb
Un cluster MongoDB est un groupe de serveurs MongoDB qui fonctionnent ensemble pour stocker vos données. Chaque serveur d'un cluster est appelé un nœud. Un cluster peut avoir n'importe quel nombre de nœuds. Un cluster est composé d'un jeu de répliques, qui est un groupe de nœuds qui ont chacun une copie de vos données. Un jeu de réplicas a au moins trois nœuds, de sorte que si un nœud tombe en panne, vos données sont toujours disponibles.
L'architecture des jeux de réplicas est un facteur important dans la capacité et les capacités de MongoDB. Les clusters MongoDB sont généralement distribués dans trois répliques de nœuds. La récupération de la base de données après un sinistre doit être constamment stable, en particulier après coup. L'une des meilleures façons de déployer un cluster partitionné consiste à utiliser une stratégie de réplication. Les données contenues dans les Shard Keys doivent être distribuées de la même manière. Vous devez redimensionner la base de données horizontalement et réduire le nombre d'opérations pouvant être effectuées sur une seule instance. Avec peu de fragments, les opérations de lecture et d'écriture peuvent devenir lentes car le nombre de fragments limite le nombre d'opérations.
Chaque élément de données dans un fragment est composé d'un sous-ensemble de cet élément basé sur un ensemble spécifique de critères. Il est courant que le nombre minimum de fragments requis pour atteindre l'importance du partitionnement soit de deux. Les requêtes scatter-gather ne doivent être utilisées que si elles peuvent être utilisées simultanément les unes avec les autres sur toutes les partitions. Lors de la sélection d'un cluster, il est essentiel d'avoir au moins sept membres votants afin que le processus d'élection soit aussi simple que possible. Si vous n'avez que sept membres votants ou moins mais un nombre égal de membres, l'arbitre doit être utilisé. Les arbitres ne stockent pas de copies de données, ce qui réduit les ressources nécessaires pour traiter les données. Il est préférable d'utiliser le nom d'hôte DNS logique plutôt que l'adresse IP lors de la configuration des membres du jeu de réplicas ou des membres du cluster partitionné. Étant donné que certaines connexions d'ensembles de réplicas de groupes de pilotes se font par noms d'ensembles de réplicas, ces noms doivent être utilisés séparément pour les ensembles. La répartition géographique des nœuds du jeu de répliques est idéale pour traiter la redondance redondante et assurer la tolérance aux pannes si l'un des centres de données est absent.
Nom du cluster Mongodb
Un cluster MongoDB est un groupe de serveurs MongoDB qui fonctionnent ensemble pour fournir une haute disponibilité et une évolutivité. Un cluster a généralement un serveur principal qui agit en tant que serveur maître et un ou plusieurs serveurs secondaires qui agissent en tant qu'esclaves. Le serveur principal contient les données et les serveurs secondaires copient les données du serveur principal.
Les programmes de base de données orientés document sont créés pour un stockage à volume élevé à l'aide de MongoDB, un programme multiplateforme. MongoDB, un programme de base de données NoSQL, est classé comme tel car il utilise des documents de style JSON avec des schémas facultatifs. Vous pouvez améliorer les performances en installant votre base de données dans le même centre de données que vos autres ressources DigitalOcean. La région possède un ou plusieurs centres de données, et chacun possède son propre réseau VPC. Le type de machine, le nombre et la taille des nœuds de la base de données peuvent tous être sélectionnés. En d'autres termes, vous pouvez ajouter jusqu'à deux nœuds de secours à votre cluster. Ajoutez un nom de projet, complétez-le et utilisez les balises que vous souhaitez utiliser lors de sa création. L'exécution d'un cluster peut prendre jusqu'à cinq minutes.
Le pouvoir de Mongodb Atlas Cluster
MongoDB Atlas Cluster est une solution de base de données NoSQL en tant que service dans le cloud public qui s'exécute dans MongoDB. Il s'agit d'une plate-forme de données robuste et évolutive qui vous permet de créer et de déployer rapidement des applications. En utilisant MongoDB Atlas Cluster, vous pouvez vous connecter en toute sécurité à MongoDB depuis n'importe quel endroit dans le monde.
Comment créer un cluster dans Mongodb
Utilisez les étapes suivantes pour créer un cluster dans MongoDB :
1. Choisissez une topologie de déploiement.
2. Sélectionnez le type de jeu de répliques que vous souhaitez déployer.
3. Choisissez le nombre de jeux de répliques que vous souhaitez déployer.
4. Configurez les jeux de répliques.
5. Connectez-vous au routeur mongos.
6. Configurez la clé de partition.
7. Ajoute des partitions au cluster.
8. Vérifiez que le cluster est opérationnel.
MongoDB Atlas est un niveau gratuit de MongoDB, qui est le service de base de données cloud entièrement géré de MongoDB. Le service est conçu pour les charges de travail d'entreprise, ainsi que pour les clusters mondiaux . Vous n'avez pas besoin de créer un compte avec Amazon Web Services (AWS), Google Cloud Platform ou Microsoft Azure. Il vous demandera de créer un compte administrateur afin d'accéder au service. Pour accéder au service, un cluster doit être lié à une adresse IP. Les paramètres de sécurité par défaut de MongoDB Atlas empêchent toutes les connexions externes. Votre mot de passe ne doit comporter aucun caractère spécial et uniquement des caractères alphanumériques pour faciliter la connexion à Studio 3T. Lors de la création d'une chaîne de connexion pour MongoDB, les caractères spéciaux doivent être encodés. À l'étape 1, choisissez Java dans la liste déroulante DRIVER, puis dans la liste déroulante VERSION. Si vous sélectionnez le pilote et la version, le service mettra automatiquement à jour la chaîne de connexion à l'étape 2.
Clustering Mongodb : une excellente option pour un débit à forte demande
À l'aide du clustering MongoDB , vous pouvez répondre aux exigences de débit, de disponibilité et de débit élevés pour les grands environnements. Les clusters MongoDB peuvent être configurés pour prendre en charge un large éventail de types d'ensembles de réplicas MongoDB, des configurations simples à nœud unique aux configurations hautement disponibles à plusieurs nœuds.
Tutoriel sur le cluster Mongodb
Un cluster MongoDB est un groupe de serveurs MongoDB qui fonctionnent ensemble pour stocker vos données. Un cluster MongoDB peut être aussi petit qu'un seul serveur ou aussi grand que des centaines de serveurs. Lorsque vous créez un cluster MongoDB, vous spécifiez le nombre de serveurs (nœuds) que vous souhaitez dans le cluster. Chaque nœud d'un cluster MongoDB stocke un sous-ensemble de vos données. Les clusters MongoDB sont conçus pour être évolutifs et offrir une haute disponibilité. Vous pouvez ajouter des nœuds à un cluster à tout moment pour augmenter sa capacité ou pour remplacer un nœud défaillant. Lorsque vous supprimez un nœud d'un cluster, les autres nœuds redistribuent les données du nœud supprimé afin que les données soient toujours réparties uniformément sur le cluster.
Le guide facile de Hevo sur le clustering MongoDB est la première étape. Lorsqu'une base de données est trop petite ou trop lente pour faire fonctionner un système, les opérations d'une organisation se poursuivent. MongoDB possède de nombreuses fonctionnalités avancées conçues pour le cloud, telles que le partage et la réplication. MongoDB permet de stocker plusieurs copies des mêmes données, ce qui les rend extrêmement accessibles. Si un serveur tombe en panne, les données de l'autre peuvent être récupérées immédiatement. Vous pouvez automatiser, simplifier et enrichir le processus de réplication des données en utilisant Hevo Data. La réplication de données est simple et facile à utiliser lorsque vous avez accès à notre essai gratuit de 14 jours.
Pour configurer les clusters MongoDB, vous devez d'abord installer les trois composants nécessaires. Avec la plate-forme automatisée et sans code de Hevo, vous pouvez suivre tout ce que vous devez faire pour une expérience de réplication de données fluide. Pour assurer une disponibilité maximale, plusieurs serveurs de configuration ou routeurs doivent être présents. Lorsque le routeur détermine dans quelle partition les données sont hébergées, il envoie des requêtes au cluster approprié. Dans le processus d'établissement des clusters MongoDB, les étapes suivantes seront nécessaires pour leur ajouter des fragments. Dans une configuration en cluster, le port 27018 est utilisé par défaut pour les serveurs de partition. Cela signifie qu'il s'agit d'un serveur de fragments plutôt que d'un serveur de configuration.