
Les facteurs de différenciation de Hadoop : évolutivité open-source et tolérance aux pannes
Publié: 2022-11-18Hadoop est une infrastructure logicielle open source pour le stockage et le traitement distribués d'ensembles de données volumineuses sur des grappes d'ordinateurs. Il est conçu pour passer d'un serveur unique à des milliers de machines, chacune offrant un calcul et un stockage locaux. Plutôt que de compter sur le matériel pour offrir une haute disponibilité, le cadre est conçu pour détecter et gérer les défaillances au niveau de la couche application. Hadoop est une base de données nosql car elle utilise une architecture complètement différente d'une base de données relationnelle traditionnelle. Hadoop est conçu pour évoluer horizontalement, ce qui signifie qu'il peut évoluer pour accueillir plus de données en ajoutant plus de serveurs de base au cluster. Hadoop est également conçu pour être tolérant aux pannes, ce qui signifie que si un serveur du cluster tombe en panne, le système peut continuer à fonctionner sans ce serveur.
Hadoop n'est pas utilisé pour stocker des données et ne nécessite pas non plus l'utilisation d'un stockage relationnel ; il est plutôt utilisé pour stocker de grandes quantités de données sur des serveurs distribués. Une base de données Hadoop est un type de données plutôt qu'un système logiciel qui permet un calcul parallèle massif. Il s'agit d'un type de liaison de base de données NoSQL (tel que HBase) qui permet aux utilisateurs d'interroger et de rechercher des bases de données dans une variété liée. Le SGBDR, dans sa forme actuelle, ne serait pas en mesure de concurrencer Hadoop car il est capable de gérer à la fois des données relatives et transactionnelles. Hadoop a la capacité de gérer tout type de données, qu'elles soient structurées, semi-structurées ou non structurées, et prend en charge un large éventail de méthodes. L'analyse des mégadonnées donne aux entreprises un avantage concurrentiel réel en fournissant des informations plus approfondies. Hadoop, en tant que service, prend en charge l'utilisation du traitement analytique en ligne (OLAP) dans le traitement des données. Il est important de se rappeler que la vitesse de traitement des données est déterminée par le nombre de demandes de données. Vous pouvez utiliser Hadoop si vous ne voulez pas de transactions ACID ou de support OLAP, par exemple.
Hadoop et les bases de données en mémoire sont deux technologies complètement différentes qui se chevauchent. Ils ne sont pas les mêmes, mais ils sont d'accord sur certaines choses.
Les applications analytiques qui utilisent SQL-on-Hadoop combinent des méthodes de requête de style SQL établies avec des éléments de structure de données Hadoop plus récents . SQL-on-Hadoop permet aux développeurs d'entreprise et aux analystes commerciaux de collaborer sur des clusters Hadoop avec des requêtes SQL familières.
Il s'agit d'une base de données NoSQL qui fournit un moyen de stocker et de récupérer des données. Non relationnel/non-SQL est l'un des termes couramment utilisés dans cet espace.
Les données sont gérées de différentes manières par Hadoop et SQL. SQL est un langage de programmation, tandis que Hadoop est un cadre de composants logiciels. Les deux outils sont utiles pour le Big Data, mais ils ont des inconvénients. La plate-forme Hadoop peut gérer un ensemble de données beaucoup plus important, mais elle n'écrit les données qu'une seule fois.
Quelle est la différence entre Hadoop et Nosql ?
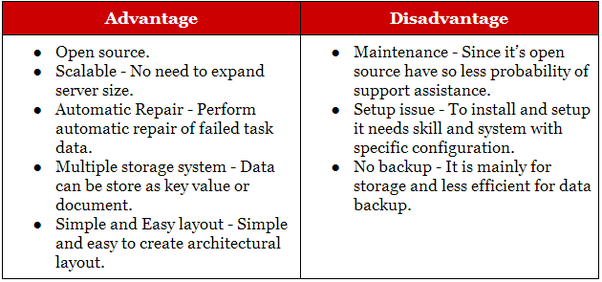
Hadoop est adapté aux applications d'archivage analytique et historique, tandis que NoSQL est idéal pour les charges de travail opérationnelles qui complètent leurs homologues relationnels. Les bases de données NoSQL ont commencé comme des bases de données de stockage clé-valeur , mais plus tard, les bases de données document/json et graphe les ont rejointes.
Le traitement en temps réel, les données volumineuses et les données non structurées ne sont que quelques-uns des scénarios dans lesquels la technologie NoSQL peut être utilisée. Par conséquent, certains de ces défis, tels que l'évolutivité et la disponibilité, peuvent être résolus. La base de données NoSQL présente un certain nombre d'avantages par rapport à la base de données relationnelle traditionnelle. Ils peuvent traiter des ensembles de données de manière beaucoup plus rapide et plus évolutive qu'auparavant. Les systèmes d'administration de bases de données utilisent également moins de connaissances et d'expertise que les bases de données traditionnelles , ce qui les rend plus faciles à utiliser. Une base de données NoSQL présente de nombreux avantages par rapport à une base de données relationnelle traditionnelle. La chose la plus importante à considérer est de savoir si vous en avez besoin pour le traitement en temps réel et les grands ensembles de données.
Les bases de données Nosql sont le meilleur choix pour les entreprises avec des charges de travail Big Data
Si vos charges de travail de données se concentrent davantage sur l'analyse et le traitement de grandes quantités de données variées et non structurées, telles que le Big Data, les bases de données NoSQL constituent un meilleur choix. Contrairement aux bases de données relationnelles , les bases de données NoSQL ne reposent pas sur un modèle de schéma fixe. Le SGBDR est plus flexible que les SGBDR traditionnels en termes de stockage, de traitement et de gestion des données, ce qui en fait une meilleure option pour les entreprises qui ont besoin de pouvoir accéder rapidement à de grandes quantités de données et qui ont besoin de les stocker indéfiniment.
Le Big Data SQL ou Nosql est-il ?

Si vos charges de travail de données sont principalement concernées par le traitement et l'analyse rapides de grandes quantités de données diverses et non structurées, telles que le Big Data, NoSQL est votre meilleur pari. Le modèle de base de données NoSQL est unique en ce sens qu'il ne repose pas sur la même structure de schéma qu'une base de données relationnelle.
Il ne s'agit plus de savoir si les mégadonnées amélioreront la fabrication ; c'est une question de quand. Dans le Big Data, il existe des quantités vastes, diverses et complexes de données structurées et non structurées disponibles. Les capteurs, les caméras sur le lieu de production et les appareils grand public peuvent tous être utilisés pour collecter des mégadonnées dans la fabrication. Étant donné que la plupart des données de fabrication ne sont pas structurées, les architectures NoSQL ne peuvent pas rivaliser avec des approches rigides telles que SQL. Une base de données NoSQL ne nécessite aucun schéma pour stocker les données dans la même table de base de données, ce qui permet aux utilisateurs de stocker des données dans différentes structures. La ligne de séparation d'une entreprise peut être déterminée par la quantité de données qu'elle a l'intention d'utiliser. Les transactions doivent respecter quatre principes de fonctionnement fondamentaux pour être considérées comme une transaction de base de données relationnelle.
Étant donné que les systèmes NoSQL et les systèmes cloud peuvent être intégrés, il est judicieux d'utiliser des infrastructures de cloud computing pour prendre en charge les systèmes NoSQL. L'optimisation des processus de fabrication en temps réel via NoSQL peut être réalisée grâce à l'intégration avec les systèmes d'exécution de fabrication (MES). Ce succès a été rendu possible grâce à l'utilisation d'analyses de mégadonnées pour produire des réponses plus rapides aux conditions changeantes. MongoDB est une bonne base de données NoSQL car elle est simple à configurer et peut être utilisée pour l'analyse. L'utilisation d'architectures de base de données à réponse plus rapide telles que NoSQL permet à la direction d'effectuer de meilleures simulations, leur permettant de prendre de meilleures décisions sur les produits dans le monde réel. Les bases de données B2B sont vulnérables aux attaques intersites, ainsi qu'aux attaques par injection et aux attaques par force brute. Une attaque par injection se produit lorsqu'un attaquant ajoute des données aux commandes de requête NoSQL ou aux instructions de stockage.

Le secteur manufacturier est particulièrement préoccupé par la sécurité de l'architecture NoSQL. Si une attaque par déni de service ou par injection réussit, un fabricant peut être en mesure de modifier les spécifications. De ce fait, les concurrents peuvent être en mesure d'obtenir un avantage sur un marché hautement concurrentiel.
Les processus métier qui s'appuient sur des données en temps réel sont de plus en plus courants à mesure que les entreprises cherchent des moyens d'améliorer leur efficacité et leur réactivité aux besoins des clients. Les bases de données NoSQL basées sur le cloud, telles que Cloud Bigtable, offrent un moyen rapide et efficace de stocker et d'accéder à de grands ensembles de données, ce qui en fait une excellente solution pour ces types d'applications.
Cloud Bigtable est un service de base de données NoSQL entièrement géré et offrant une disponibilité de 99,999 %. Il est idéal pour les charges de travail analytiques et opérationnelles car il a des vitesses de flux de données élevées et est simple à mettre à l'échelle. Par conséquent, c'est un excellent choix pour le traitement de données en temps réel dans des applications telles que les jeux mobiles et l'analyse de la vente au détail.
Nosql est-il la meilleure base de données pour les données volumineuses ?
MongoDB, par exemple, est un excellent choix pour stocker de grandes quantités de données. Ils permettent une large gamme de scénarios de traitement agiles et hautes performances. De plus, les données non structurées sont stockées dans des bases de données NoSQL sur plusieurs nœuds de traitement et sur plusieurs serveurs. Par conséquent, les bases de données NoSQL ont été le choix par défaut de certains des plus grands entrepôts de données au monde . Quelle base de données est la meilleure pour les données volumineuses ? En ce qui concerne cette question, il n'est pas possible de prédire quelle base de données est la meilleure pour les données volumineuses en raison des besoins variables de l'organisation. Amazon Redshift, Azure Synapse Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 et de nombreuses autres bases de données font partie des options les plus populaires pour le stockage de données volumineuses.
Hadoop est-il une base de données
Hadoop est un système de fichiers distribué et une infrastructure permettant d'exécuter des applications sur de grands clusters de matériel de base. Hadoop n'est pas une base de données.
Hadoop, un framework open source, permet le stockage et le traitement efficaces d'ensembles de données volumineux. Les tables Hive et Imperative peuvent être créées à l'aide de fichiers texte dans HDFS. Il prend en charge les trois principaux formats de fichiers : fichiers de séquence, fichiers de données Avro et fichiers Parquet. Une série d'octets est représentée par la sérialisation des données en tant qu'unité de mémoire. Avro, un framework de sérialisation de données efficace, est largement pris en charge par Hadoop et son écosystème.
L'utilisation de fichiers texte comme format de stockage pour les tables Hive et Implicit simplifie la gestion et la manipulation des données. En conséquence, c'est un bon choix pour le traitement par lots ou le stockage de données dans une variété de formats. De plus, la sérialisation des données via Avro permet un stockage et une récupération des données à la fois efficaces et pratiques. Par conséquent, c'est une bonne option pour stocker des données dans une variété de formats ou pour effectuer un traitement parallèle.
Hadoop contre Nosql
Hadoop gère le Big Data pour un cluster de matériel de base. Si la fonctionnalité ne répond pas à vos besoins ou n'est pas fonctionnelle, elle peut être modifiée. C'est ce qu'on appelle NoSQL, et c'est un type de système de gestion de base de données qui stocke des données structurées, semi-structurées et non structurées.
MongoDB, en tant que base de données NoSQL (Not Only SQL), a été créée en 2007 à la suite du développement C++. Un Hadoop est une collection de logiciels open source qui sont principalement écrits en Java pour le traitement de données volumineuses. Cette plate-forme comprend également une recherche en texte intégral, des outils d'analyse avancés et un langage de requête facile à utiliser. Bien que Hadoop soit surtout connu pour sa capacité à stocker et à traiter de grandes quantités de données, il le fait également par petits lots. MongoDB fournit une variété d'outils de traitement de données en temps réel. Les connecteurs de MongoDB pour les outils externes, tels que Kafka et Spark, simplifient l'ingestion et le traitement des données. En ce qui concerne la gestion des données, Hadoop et MongoDB offrent un large éventail d'avantages par rapport aux bases de données traditionnelles. Hadoop est un excellent outil pour traiter de grandes structures de données en raison de son système de fichiers distribué. MongoDB est la seule base de données pouvant être utilisée en remplacement des bases de données traditionnelles.
Spark est-il une base de données Nosql
Dans la documentation, il est indiqué qu'un NoSQL DataFrame est un Spark DataFrame basé sur le format Spark pour le stockage des données. Contrairement aux sources de données précédentes, celle-ci prend en charge l'élagage et le filtrage des données (refoulement des prédicats), permettant aux requêtes Spark d'interroger moins de données et de charger uniquement les données requises selon les besoins.
Il est essentiel de maintenir une conscience tactique lors de l'utilisation conjointe des bases de données Apache Spark et NoSQL ( Apache Cassandra et MongoDB) dans une application. Ce blog se concentre sur l'utilisation d'Apache Spark dans une application NoSQL. CassandraLand et MongoLand à TCP/IP sPark sont deux des manèges les plus populaires, et c'est un endroit formidable à visiter si vous aimez les parcs à thème. Lors de la recherche de données du ministère de l'Énergie, notre application Spark a commencé à tourner en rond. Voici une leçon rapide sur l'importance de la séquence de touches Cassandra en matière d'interrogation. Il y a aussi les montagnes russes Partitioner à CassandraLand. Les clients qui aiment les montagnes russes peuvent partager leurs informations avec les opérateurs de manèges afin qu'ils puissent suivre qui les a montés au quotidien.
La première leçon de MongoDB Leçon 1 consiste à gérer correctement les connexions MongoDB. Lorsque vous avez besoin de mettre à jour des informations sur le nouveau statut d'adhésion au parc du ministère de l'Énergie, les index Mongo sont extrêmement utiles. En tant que client MongoDB ou Spark, vous devez maintenir une connexion et des index appropriés en cas de mises à jour du système.