
Le format de données HDF5 : une option attrayante pour stocker et gérer de grandes collections de données
Publié: 2023-02-13HDF5 est un format de données conçu pour stocker et gérer de grandes collections de données complexes. Il est fréquemment utilisé dans les applications scientifiques et d'ingénierie, et sa popularité n'a cessé d'augmenter ces dernières années. HDF5 n'est pas une base de données, mais il peut être utilisé pour stocker des données dans un format hiérarchique similaire à un système de fichiers. Cela fait de HDF5 une option attrayante pour les applications qui doivent stocker et gérer de grandes quantités de données.
Vous pouvez extraire les métadonnées et les données brutes des fichiers HDF5 et netCDF4 et utiliser le streaming Hadoop pour analyser les données Hadoop à l'aide du pilote de fichier virtuel (VFD) du connecteur HDF5 du système de fichiers distribués Hadoop (HDFS).
Hdf5 est-il une base de données ?
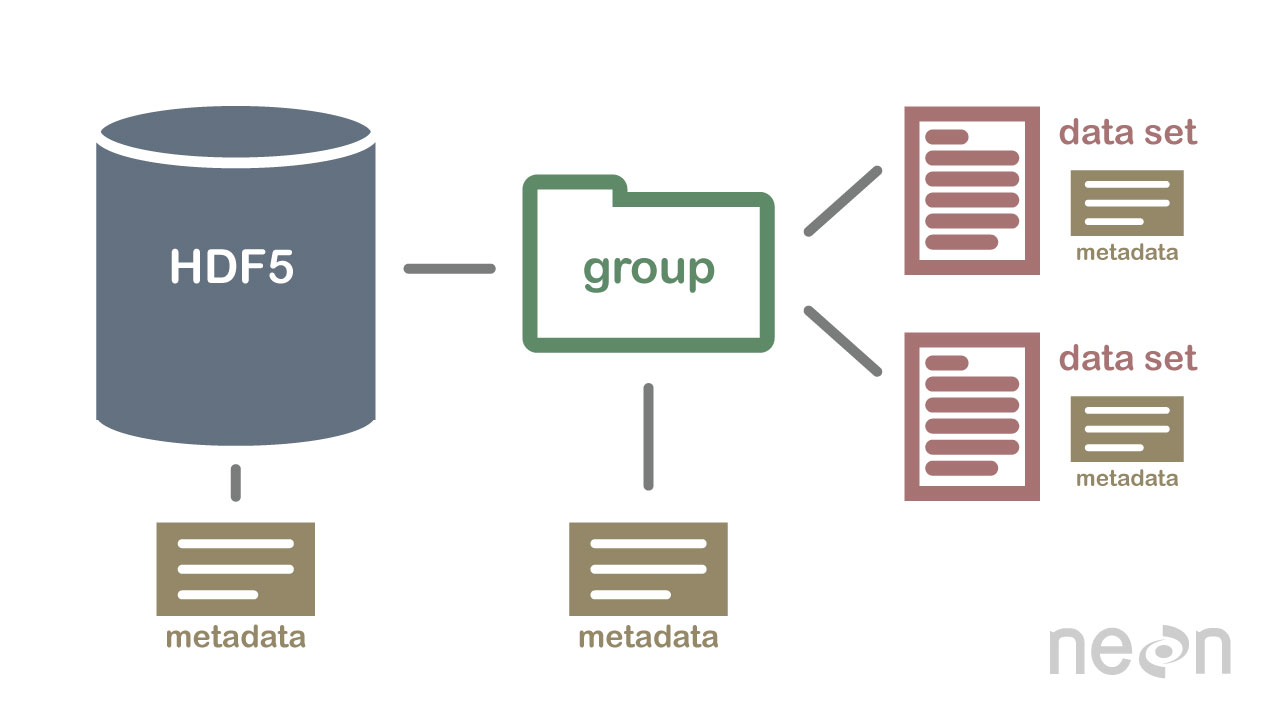
HDF5 n'est pas une base de données, mais il peut être utilisé pour stocker des données dans une structure hiérarchique, similaire à un système de fichiers. HDF5 peut être utilisé pour stocker des données dans une variété de formats, y compris du texte, des images et des données binaires .
Les données au format hiérarchique (HDF5) sont extrêmement utiles dans la recherche scientifique. Le système de fichiers HDF5, car il est similaire à un système de fichiers en ce sens qu'il est très efficace, est un excellent format. Lorsqu'il s'agit de données encodées dans ce format, il peut être difficile d'y accéder. Ce guide vous expliquera comment Apache Drill peut vous aider à accéder facilement aux ensembles de données HDf5 et à les interroger. Drill a accès aux fichiers HDF5 individuels via l'option defaultPath. Ceci est accompli en exécutant directement la fonction table() au moment de la requête ou via la configuration. Les résultats de cette requête se trouvent dans le tableau ci-dessous. Drill peut ensuite sélectionner les colonnes et les filtrer individuellement, filtrées, agrégées ou combinées avec d'autres données qu'il peut interroger.
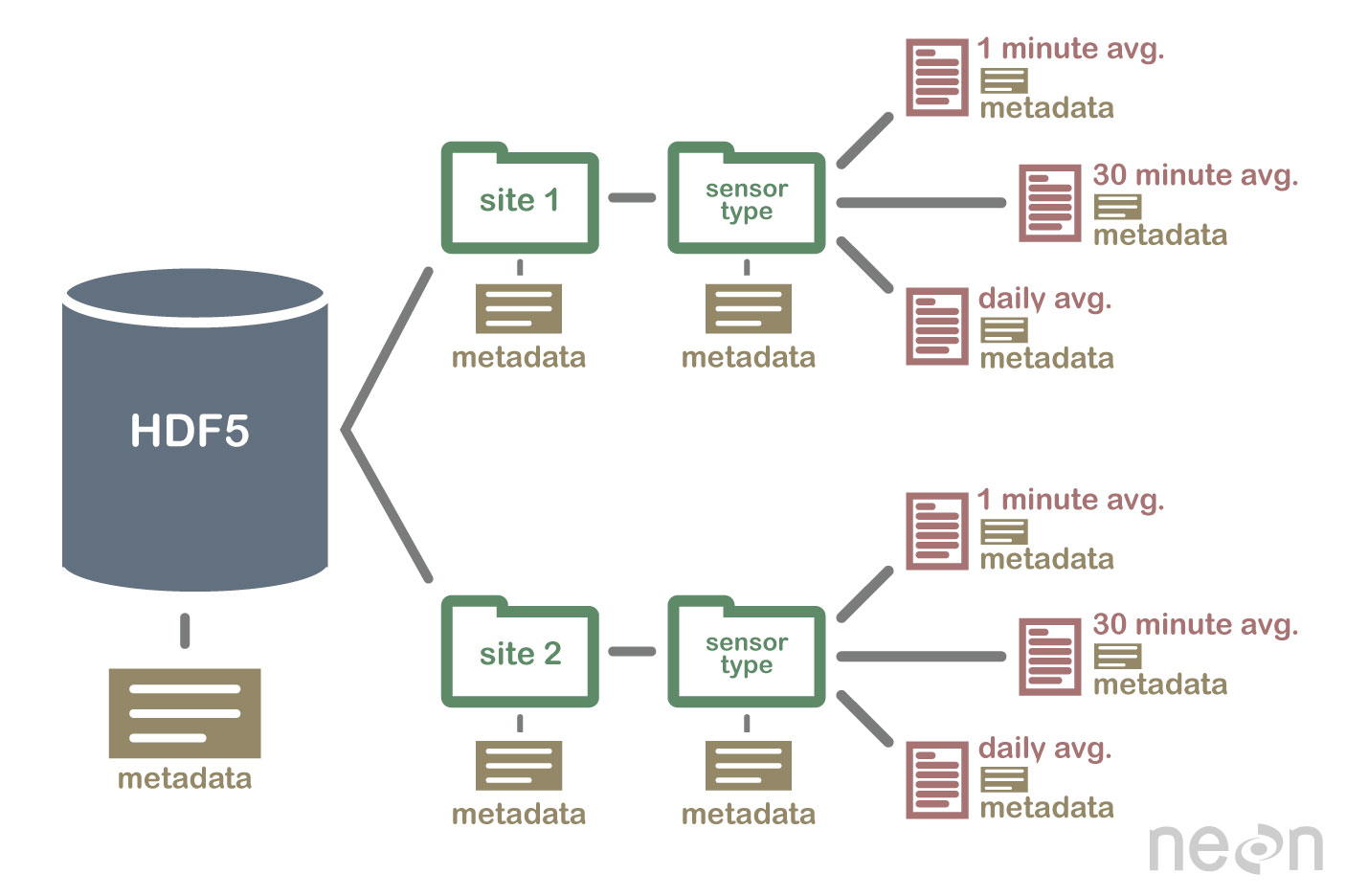
La spécification HDF5 définit un format de fichier pour stocker des tableaux de données. Un tableau de données peut être composé de n'importe quel type de données, y compris des données de chaîne, flottantes, complexes et entières. Un tableau peut contenir des données de n'importe quelle taille et il peut être de n'importe quelle forme. Dans HDF5, il faut d'abord créer un fichier d'en-tête afin de créer un jeu de données. Le fichier d'en-tête comprend des informations sur l'ensemble de données ainsi que des métadonnées. Le fichier d'en-tête comprend deux informations importantes : le nom de l'ensemble de données et le numéro de version de l'ensemble de données. Un tableau de données est utilisé pour stocker les données d'un ensemble de données. Les blocs sont constitués de données dans un tableau de données. Dans un tableau de données, chaque bloc de données contient un ensemble contigu de données. Le nombre de blocs d'un jeu de données est déterminé par le nombre d'octets qu'il contient. Les données sont accessibles via un certain nombre de méthodes conformément à la spécification HDF5. les méthodes d'indexation sont les plus couramment utilisées pour obtenir des données dans un ensemble de données. En utilisant ces méthodes, vous pouvez accéder aux données en entrant le nom d'un bloc dans le tableau de données auquel vous souhaitez accéder. La méthode de structure peut être utilisée pour accéder aux données d'un jeu de données. Lorsque vous employez ces méthodes, vous pouvez accéder aux données en utilisant la structure d'un tableau de données. Dans l'exemple suivant, vous pouvez accéder aux données d'un tableau de données en utilisant les valeurs de décalage et de longueur de la méthode de structure. Une autre façon d'obtenir des données à partir d'un ensemble de données consiste à utiliser des méthodes de fonction. Vous pouvez obtenir des données en utilisant l'une des méthodes en sélectionnant la fonction dans le fichier d'en-tête pour les données. La méthode d'accès à un tableau de données peut être utilisée en définissant la valeur dans le fichier d'en-tête comme élément de tableau de données du tableau. Enfin, vous pouvez accéder aux données d'un jeu de données à l'aide de la méthode d'accès. En employant ces méthodes, vous pouvez accéder aux données en utilisant les privilèges d'accès définis dans le fichier d'en-tête. En d'autres termes, l'utilisation du privilège de lecture peut accéder aux données d'un tableau de données via la méthode d'accès. Les données peuvent être créées et utilisées de différentes manières à l'aide de la spécification HDF5. La méthode create est la méthode la plus courante pour créer un jeu de données. À l'aide de la méthode de création, vous pouvez créer un jeu de données en saisissant le nom du jeu de données et le numéro de version du jeu de données. En plus de la spécification HDF5, l'utilisation d'ensembles de données peut être réalisée de différentes manières. La méthode la plus couramment utilisée.

Hdf5 est-il une base de données relationnelle ?
HDF5 n'est pas une base de données relationnelle.
Est-ce que Graphql Nosql ou Sql ?
L'objectif principal de GraphQL est d'utiliser un système de type pour renvoyer les données plus rapidement et plus efficacement. SQL (langage de requête structuré) est un langage plus ancien et plus largement utilisé pour stocker des données dans des systèmes de bases de données tabulaires ou relationnelles . Si vous souhaitez que votre API soit construite sur une base de données NoSQL, ce serait une bonne idée de travailler avec GraphQL.
Le Type Mismatch est une base de données GraphQL et NoSQL créée par Herman Camarena et Roger Cochrane. L'utilisation de GraphQL peut entraîner l'introduction d'un système de type plutôt qu'un système NoSQL, éliminant ainsi la flexibilité créée par les systèmes NoSQL. Une collection GraphQL contient une grande variété de documents dont la structure est cohérente et qui contiennent quelques exceptions. Étant donné que GraphQL possède un ensemble intégré de types de données qui correspondent aux types de backends, les développeurs peuvent choisir les types de données à créer. GraphQL devrait résoudre le problème des incompatibilités de type afin de réaliser pleinement son potentiel. En termes de fonctionnalités, il fournit une solution d'inadéquation de niveau inférieur en raison de ses nombreux avantages. Le travail est de plus en plus automatisé avec des outils comme JSON2SDL de StepZen.
C'est un outil puissant qui peut être utilisé pour créer des applications plus résilientes et efficaces, mais SQL n'est pas un substitut. Au niveau de la maintenance, cela peut avoir un impact négatif car cela rend certaines tâches plus difficiles.
Graphql : un langage de requête pour n'importe quelle base de données
Le langage de requête GraphQL permet aux clients et aux serveurs de communiquer entre eux. Une instance GraphQL peut récupérer et conserver les modifications à partir d'une source de données ou d'un état persistant. Un résolveur est un ensemble de fonctions arbitraires utilisées pour accéder aux données et les manipuler. L'API est disponible dans une variété de bases de données et GraphQL peut être utilisé avec n'importe laquelle. La base de données MongoDB est une base de données de source de données populaire qui est indépendante de divers types de données.
Nosql utilise-t-il des arbres B ?
Les bases de données NOSQL n'utilisent pas d'arbres B car elles ne sont pas basées sur le modèle relationnel. Les bases de données NOSQL sont souvent basées sur des paires clé-valeur, des magasins de documents ou des bases de données de graphes.
Les arbres B sont la structure d'indexation par défaut dans MongoDB. Dans le stockage de données , un B-tree est une méthode plus efficace. Les données peuvent être organisées à l'aide d'entiers et de chaînes s'ils sont utilisés ensemble. Par conséquent, les bases de données avec un volume élevé de données devraient envisager de l'utiliser. Parce que les arbres B peuvent prendre beaucoup de place, ils constituent un modèle efficace. Ceci est avantageux pour les bases de données qui doivent conserver une grande quantité de données. Les arbres B sont également un bon choix pour les bases de données qui doivent organiser les données d'une manière spécifique.
Quelle base de données utilise B-tree ?
Il existe depuis longtemps et peut être utilisé dans un large éventail de bases de données. Les bases de données NoSQL peuvent être construites sur des moteurs B-tree, en plus des moteurs B-tree. MongoDB, par exemple, indexe les données dans des arbres B. L'algorithme est le même pour le SGBD que pour une base de données relationnelle, à quelques exceptions près. Les chaînes et les entiers peuvent être utilisés pour organiser les données dans le B-tree.
Quelle base de données utilise B-tree ? Mysql, dans l'article qui suit, utilise à la fois Btree et B+tree. SQL Server stocke les index basés sur des données persistantes basées sur des clés sous la forme d'un BTree. Par conséquent, chaque nœud d'un tel arbre apparaît comme une seule page.