
La base de données Oracle NoSQL
Publié: 2022-12-17La base de données Oracle NoSQL est une base de données clé-valeur distribuée. Il est conçu pour fournir une gestion des données évolutive et performante tout en conservant une interface simple. La base de données Oracle NoSQL est construite sur Oracle Berkeley DB Java Edition, qui fournit un moteur de base de données intégrable hautes performances. La base de données Oracle NoSQL est disponible en tant qu'image de machine virtuelle téléchargeable ou en tant que service cloud.
In-Memory utilise une architecture unique à double format qui permet aux tables d'être représentées simultanément en mémoire. Étant donné que le nouveau format de colonne est un format purement en mémoire et ne nécessite pas de stockage sur disque, il n'y a pas de coût de stockage supplémentaire ni de problème de synchronisation du stockage. La capacité des bases de données en mémoire à gérer les requêtes à la vitesse étonnante de milliards de lignes par seconde sur un cœur de processeur est stupéfiante. La plupart de ces index analytiques peuvent être éliminés avec In-Memory en utilisant le format de colonne In-Memory, qui réduit la quantité de données à récupérer tout en offrant des performances comparables à celles d'un index sur chaque colonne. La suppression des index analytiques accélère les opérations OLTP car les index n'ont plus besoin d'être maintenus par chaque transaction. Seules les tables et partitions privilégiées en mémoire peuvent être insérées dans la mémoire des utilisateurs.
Le système de gestion de base de données NoSQL en mémoire, tel que MongoDB et Redis, stocke toutes les données dans la mémoire principale et les met à jour sur disque indéfiniment. Pour assurer la persistance, chaque demande de modification est enregistrée dans un journal binaire. Étant donné que le journal est en ajout uniquement, il est rarement problématique de l'écrire rapidement.
La base de données Oracle est-elle en mémoire ?

Oui, Oracle Database est en mémoire. La fonctionnalité de stockage de colonnes en mémoire d'Oracle permet de stocker et d'accéder aux données en mémoire, ce qui améliore considérablement les performances des charges de travail analytiques. Lorsqu'il est combiné avec la technologie Real Application Clusters (RAC) d'Oracle, Oracle Database peut fournir un niveau encore plus élevé d'évolutivité et de disponibilité.
Database In-Memory est un ensemble de fonctionnalités qui améliore l'analyse en temps réel et les charges de travail mixtes en offrant des gains de performances significatifs. Le magasin de colonnes (magasin de colonnes IM) a été ajouté à Oracle Database 12c Release 1 (12.1.0.2) en tant que composant d'Oracle Database 12c Release 1 (12.1.0.2). Dans les bases de données relationnelles traditionnelles, les données peuvent être stockées sous forme de lignes ou de colonnes. La sélection de colonnes dans une base de données en colonnes correspond à la sélection de lignes dans une base de données de lignes. La base de données en mémoire comprend un magasin de colonnes dans la base de données, des optimisations avancées des requêtes et des solutions d'accès. Le magasin de colonnes IM conserve des copies de toutes les colonnes, tables, partitions, etc. dans un format de colonne compressé conçu pour une analyse rapide. En utilisant le traitement parallèle, les entrepôts de données et les bases de données à usage mixte peuvent gérer des ordres de grandeur plus rapidement.
Suite au remplissage, les données basées sur les lignes sur le disque sont transformées en données en colonnes dans le magasin de colonnes IM. Par exemple, si vous souhaitez diviser une table ou une vue en partitions partitionnées, toutes ou une partie des partitions peuvent être configurées pour la population. L'expression en mémoire (expression IM) dans DBMS_INMEMORY_ADMIN.IME_CAPTURE_EXPRESSIONS permet l'identification et la sélection d'expressions actives. Lorsqu'une instance de base de données redémarre, la méthode Database In-Memory FastStart (IM FastStart) permet de gagner du temps en réduisant la quantité de données à remplir dans le magasin de colonnes IM. Le format colonnaire est idéal pour la numérisation de données en raison de son débit élevé. Vous pouvez utiliser l'analyse de données en temps réel pour explorer de nouvelles possibilités et itérations. Il est possible d'analyser les données dans leur format compressé sans les décompresser au préalable dans la base de données Oracle.
Un prédicat de clause WHERE est utilisé sur les données compressées dans la base de données lorsque les colonnes sont compressées à l'aide d'algorithmes qui permettent de compresser automatiquement les colonnes. Les filtres Bloom font avancer les jointures en convertissant les prédicats sur les tables de petite dimension en filtres sur les grandes dimensions. Lorsque les données sont stockées dans le magasin de colonnes IM, il est plus facile d'organiser et d'effectuer des requêtes complexes. La création de structures d'accès est une étape critique dans l'amélioration des performances des requêtes analytiques. L'approche la plus courante consiste à créer des index analytiques, des vues matérialisées et des cubes OLAP. Une ligne doit être insérée dans une table, ce qui nécessite de modifier tous les index. Les bases de données Oracle sont stockées dans le format de stockage sur disque d'Oracle, qui est identique au format en colonnes.
Il est entièrement pris en charge par RMAN, Oracle Data Guard et Oracle ASM. Il ne nécessite pas l'utilisation d'un outil de migration de données géré par l'utilisateur. Si vous utilisez les fonctions analytiques d'Oracle ou un code PL/SQL personnalisé, vous aurez accès à un plus large éventail de requêtes analytiques. Les seules tâches requises sont le dimensionnement du magasin de colonnes IM et la spécification des valeurs d'objet pour la population. Dans le tableau ci-dessous, vous trouverez une liste des tâches de configuration les plus élémentaires de IM Column Store. Vous pouvez télécharger le conseiller en mémoire pour PL/SQL et l'utiliser pour analyser la charge de travail de traitement analytique de votre base de données. Le traitement analytique diffère des autres activités de base de données en fonction de la cardinalité du plan, de l'utilisation des requêtes parallèles et d'autres facteurs.
Le conseiller en mémoire n'est pas inclus dans les packages PL/SQL stockés sur le système. Vous devez d'abord obtenir le package auprès du support Oracle. Les estimations du conseiller indiquent des améliorations des performances de traitement analytique basées sur les facteurs suivants. Les temps d'attente pour les E/S utilisateur, les transferts de cluster et les événements de verrouillage du cache de tampon peuvent tous être éliminés. Selon le type de compression, les coûts de compression entraînent des heuristiques.
Qu'y a-t-il en mémoire dans la base de données ?
Une base de données en mémoire, par opposition à une base de données sur disque ou SSD, est conçue pour stocker des données en mémoire principalement à des fins de stockage de données. Les magasins de données créés en mémoire utilisent une méthode peu coûteuse pour éliminer le besoin d'accéder aux disques afin de réduire les temps de réponse.
Avantages des bases de données en mémoire
Les bases de données en mémoire sont devenues plus populaires ces dernières années car elles offrent de nombreux avantages par rapport aux bases de données traditionnelles. Leur premier avantage est qu'ils peuvent stocker tous les types de données dans le même système, ce qui les rend idéaux pour les applications qui doivent stocker de grandes quantités de données non structurées. Outre la rapidité et l'efficacité des bases de données en mémoire, les utilisateurs peuvent accéder aux données plus rapidement. De plus, les bases de données en mémoire peuvent être utilisées par les petites entreprises et les consommateurs car elles sont simples à utiliser et gérables.
Oracle a-t-il une base de données Nosql ?
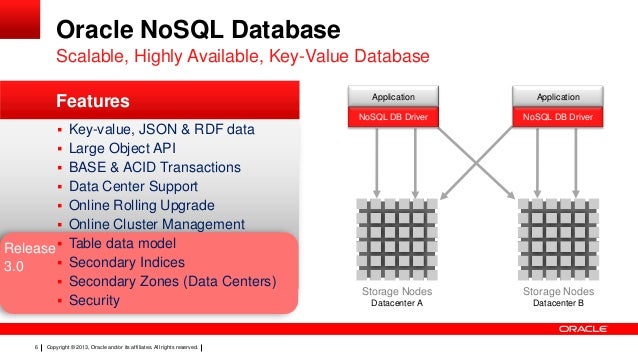
Oui, Oracle a une base de données nosql appelée Berkeley DB. Berkeley DB est une base de données open source hautes performances et évolutive.
Où les données Nosql sont-elles stockées ?
Au lieu de stocker des données dans une base de données relationnelle, les bases de données NoSQL stockent les données dans des documents. En d'autres termes, nous les divisons en SQL et en une variété de modèles de données flexibles afin de les classer. Une base de données NoSQL peut être une base de données de documents purs, une base de données de stockage clé-valeur, une base de données à colonnes larges ou une base de données de graphes.
L'une des utilisations les plus courantes des bases de données NoSQL est le stockage rapide de grandes quantités de données non liées. NoSQL est un type de base de données qui ne partage pas de données relationnelles. Au cours des années 1970, les bases de données relationnelles sont devenues la norme en matière de stockage de données. Selon Ben Finkel, formateur CBT, NoSQL privilégie la rapidité et la flexibilité à la cohérence et à l'efficacité. Malgré leur rapidité et leur efficacité, les bases de données construites à l'aide de la technologie relationnelle ne sont pas aussi simples qu'elles le paraissent. La base de données NoSQL ne nécessite pas la conception ou la planification des structures de données. Cela permet aux développeurs de créer, de prototyper et de déployer des applications beaucoup plus rapidement.
Ils fonctionnent de la même manière que le développement logiciel agile, qui est également populaire. Les bases de données NoSQL peuvent stocker une variété de types de données, ce qui les rend simples à configurer. Les bases de données NoSQL nécessitent plus de puissance de calcul pour fonctionner que les bases de données relationnelles. Le Raspberry Pi a la capacité d'exécuter de petites bases de données NoSQL , mais les serveurs Web seront nettement plus exigeants. Les graphiques, contrairement aux paires clé:valeur ou aux documents, sont abstraits. Les nœuds et les arêtes sont les deux composants des graphes. Les nœuds peuvent contenir des informations sur un objet (personne, lieu, chose, idée, etc.). La relation entre un nœud et ses arêtes s'explique par les arêtes. Le modèle de données à colonne large est similaire aux lignes et aux colonnes d'une base de données relationnelle.
Plusieurs facteurs contribuent à la popularité croissante des bases de données NoSQL. Les bases de données relationnelles traditionnelles sont inefficaces, chronophages et sujettes à la corruption des données, tandis que les bases de données basées sur des microservices sont plus performantes. Pour une bonne raison, JSON est le format préféré pour les bases de données NoSQL. En termes simples, les documents JSON sont plus compacts et lisibles que les autres types de documents. JSON est un format de représentation de données créé en JavaScript.
JSON est plus lisible et compact que le format texte standard.
Les bases de données NoSQL sont plus efficaces que les bases de données relationnelles traditionnelles en termes de vitesse et de performances.
Ils facilitent son utilisation.
Ils sont plus résistants à la corruption des données que les autres animaux.

Les différents types de bases de données Nosql
Les bases de données NoSQL, telles que MongoDB, sont populaires en raison de leur simplicité de stockage des données, qui est beaucoup plus facile à saisir que les types de modèles de données utilisés dans les bases de données SQL. Les développeurs ont souvent un accès direct à la structure d'une base de données NoSQL.
Une base de données NoSQL est une base de données non tabulaire qui stocke les données d'une manière différente d'une base de données relationnelle (alias SQL). Les différents types de bases de données NoSQL sont basés sur leurs modèles de données. Les principaux types de documents sont les graphiques, les diagrammes et les déclarations clé-valeur.
Comment installer Nosql pour stocker des données sous forme structurée ?
Les données peuvent être structurées, semi-structurées ou non structurées dans une base de données NoSQL, ce qui permet d'y accéder via un certain nombre de mécanismes. L'avantage majeur de leur logiciel est qu'il est semi-structuré (JSON, XML, mais tous les champs ne sont pas connus), ce qui conduit à des données non structurées.
Comment les données peuvent-elles être stockées dans une base de données non relationnelle ?
Étant donné qu'une base de données non relationnelle n'utilise pas le schéma tabulaire de la plupart des bases de données traditionnelles, il n'y a ni lignes ni colonnes. Les bases de données non relationnelles, quant à elles, utilisent un modèle de stockage optimisé pour le type de données à stocker.
Qu'est-ce que la base de données Oracle Nosql
Une base de données Oracle NoSQL est un magasin clé-valeur évolutif et distribué conçu pour fournir des performances élevées, une évolutivité horizontale et une disponibilité facile. Oracle NoSQL Database est une base de données compatible NoSQL qui fournit un stockage de données de paires clé-valeur. Oracle NoSQL Database s'exécute sur un cluster de serveurs de base et fournit une API Java simple pour accéder à la base de données.
Le SDK Oracle NoSQL pour Spring Data inclut un module de mise en œuvre de Spring Data. Cette fonctionnalité peut être utilisée pour se connecter à un cluster Oracle NoQL Database ou au service Oracle NoQL Cloud. Ajoutez une dépendance maven au XML de votre projet pour une utilisation avec le SDK. Pour avoir accès à ces informations, il faut utiliser les éléments suivants. Nosql.spring est un client d'Oracle. Utilisation d'une méthode NosqlDbConfig pour configurer une base de données. Définissez une classe d'entité comme suit.
Il est recommandé de créer un référentiel pour l'extension Nosql . La classe d'application doit être écrite. En ajoutant des fichiers de dépendance à org.springframework.boot:spring-boot, vous pouvez démarrer avec Spring Framework.
Exemple Oracle en mémoire
Un exemple d'Oracle en mémoire serait une entreprise utilisant une base de données Oracle pour stocker et traiter ses données en mémoire. Cela permettrait un traitement et une récupération plus rapides des données, tout en réduisant le besoin de stockage sur disque.
Sans modification de la base de code, les types de requêtes tels que les opérations group by (requêtes analytiques) ont été améliorés de 4 à 27 fois. Une requête d'analyse en ligne nécessitant 11 secondes pour être complétée a pris 399 millisecondes à l'aide d'OIM. Garder les partitions les plus fréquemment interrogées en mémoire pour les grandes tables partitionnées est une bonne idée. Lorsqu'une table comporte des colonnes très larges, il est recommandé d'exclure les colonnes qui sont rarement interrogées. Étant donné que chaque colonne n'est pas un composant en mémoire d'une requête, Oracle définit le cache de tampon sur 0. Le taux de compression est augmenté afin que moins de traitement soit nécessaire pour le traiter, ce qui permet d'économiser de l'espace. Plus la requête est spécifique, plus l'augmentation de vitesse fournie par OIM est importante. Une requête renvoyant 75 lignes à partir d'une table de 20 millions de lignes exécutant Oracle In-Memory a pris 69 fois plus de temps qu'avec un SGBD standard . En conséquence, il peut fournir des gains de performances jusqu'à 67 fois plus rapides (sur des requêtes très sélectives).
Pourquoi la zone Pl/sql mérite plus de mémoire
Pour PL/SQL et ses objets associés, les procédures PL/SQL et les objets globaux sont tous deux stockés dans la mémoire de la zone PL/SQL. Tous ces objets ont des fonctions définies par l'utilisateur, sont liés à un package PL/SQL et disposent de privilèges d'objet. L'exécution parallèle d'Oracle Database à l'aide de la mémoire de la zone PL/SQL est également possible.
La recommandation générale d'Oracle est d'allouer 95 % de la mémoire totale à la SGA et 5 % à la zone PL/SQL.
Oracle Nosql contre Cassandra
Il existe quelques différences clés entre Oracle NoSQL et Cassandra. D'une part, Cassandra est un projet open source, tandis qu'Oracle NoSQL est un système propriétaire. Cassandra est également une base de données orientée colonnes, tandis qu'Oracle NoSQL est une base de données orientée lignes. Enfin, Cassandra se concentre sur la haute disponibilité et l'évolutivité horizontale, tandis qu'Oracle NoSQL se concentre sur la facilité d'utilisation et la gestion des données hiérarchiques.
Apache Cassandra est une base de données NoSQL bien adaptée aux hautes performances, à l'évolutivité linéaire, à la cohérence réglable et aux charges de travail à faible latence sur diverses charges de travail. Dans la plupart des cas, Apache Cassandra ne sera pas le meilleur choix pour votre cas d'utilisation car il manque une sémantique cohérente entre votre base de données relationnelle et les bases de données NoSQL avec des transactions ACID. Si vous avez besoin d'une redondance réduite des données et d'une conformité ACID, vous devez envisager d'utiliser des bases de données SQL plutôt qu'Oracle. HBase n'est pas couramment utilisé par les développeurs Web ou mobiles, car il est conçu pour fonctionner avec des cas d'utilisation de lac de données froids ou historiques. Une application Cassandra est, en revanche, plus facilement disponible et capable de gérer des environnements très exigeants.
Quelle est la différence entre Cassandra et Oracle ?
Le système de gestion de base de données Oracle (ODMS) est un système de gestion de base de données relationnelle (RDBMS) disponible en deux formats : S.NO.ORACLE CASSANDRA1. Il a été développé par Oracle Corporation en 1980 et a été créé par Apache Software Foundation en 2008 ; 2. Il a été écrit Le logiciel open-source est accessible en exécutant sept lignes de plus.
Oracle est-il une base de données Nosql ?
Oracle NoSQL Database Cloud Service permet aux développeurs de créer facilement des applications à l'aide de modèles de base de données de documents, de colonnes et de valeurs-clés en offrant des temps de réponse prévisibles en millisecondes, une réplication de données pour une haute disponibilité et des applications basées sur des documents.
Cassandra et Nosql sont-ils identiques ?
Cassandra est un système de gestion de base de données de magasin à larges colonnes gratuit et open-source, distribué et basé sur le projet open source Cassandra.
Netflix utilise-t-il Cassandra ?
Cassandra sur Amazon Web Services sert de composant d'infrastructure clé du service de streaming mondial de Netflix.
Base de données Oracle Nosql contre Mongodb
Il existe de nombreuses différences entre Oracle NoSQL Database et MongoDB. Premièrement, MongoDB est une base de données orientée document tandis qu'Oracle NoSQL Database est un magasin clé-valeur. Cela signifie que MongoDB stocke les données dans des documents de type JSON, tandis qu'Oracle NoSQL Database stocke les données dans des paires clé-valeur. Deuxièmement, MongoDB prend en charge les index secondaires, contrairement à Oracle NoSQL Database. Troisièmement, MongoDB a un langage de requête plus riche qu'Oracle NoSQL Database. Quatrièmement, MongoDB prend en charge le partitionnement automatique, contrairement à Oracle NoSQL Database. Enfin, MongoDB est open source, contrairement à Oracle NoSQL Database.
MongoDB est simple à configurer et offre une flexibilité incroyable en termes de flexibilité de conception. Si vos formats de données ne sont pas cohérents, une base de données NoSQL comme Oracle NoSQL Database est un bon choix. Si vous avez besoin de moins de redondance de données et de conformité ACID, l'utilisation d'une base de données SQL peut être la meilleure option pour vous. Étant donné que les bases de données NoSQL, telles que MongoDB, manquent d'interfaces graphiques, elles ne sont généralement pas destinées à être utilisées conjointement avec des bases de données traditionnelles. Pour améliorer la convivialité, vous devez installer des applications tierces qui vous permettent de visualiser visuellement les schémas et les documents stockés. Si vous ne connaissez pas un DBA ou un administrateur système comment utiliser MongoDB, c'est une bonne idée d'aller avec un fournisseur d'hébergement MongoDB tiers.
Principales différences entre Mongodb et Oracle
Il existe plusieurs différences importantes entre MongoDB et Oracle qui doivent être prises en compte lors du choix du logiciel à acheter. La plate-forme MongoDB est bien connue pour sa capacité à gérer de grandes quantités de données, tandis qu'Oracle est plus couramment utilisé pour créer des applications d'entreprise. De plus, MongoDB inclut des fonctionnalités avancées pour rechercher n'importe quel champ ou gamme de requêtes, alors que les capacités d'Oracle sont moins limitées. Oracle évolue verticalement car il est basé sur le sharding, tandis que MongoDB évolue horizontalement car il est basé sur le sharding. De plus, MongoDB est construit sur une architecture de système distribué plutôt que sur une conception monolithique à nœud unique, ce qui le distingue d'Oracle en termes d'architecture.