
La puissance de MarkLogic : gestion et sécurité du Big Data en un seul endroit
Publié: 2023-01-29MarkLogic est une puissante base de données Nosql qui permet aux organisations de stocker, gérer et rechercher facilement et rapidement de gros volumes de données. Il est hautement évolutif et offre des performances élevées, ce qui le rend idéal pour les applications Big Data. MarkLogic dispose également de fonctions de sécurité intégrées qui protègent les données contre les accès non autorisés et garantissent l'intégrité des données.
En réponse à une demande pour un moyen plus flexible et efficace de stocker de grandes quantités de données, un mouvement connu sous le nom de NoSQL est né. Cet article est destiné à être une introduction générale à toute personne intéressée par ce domaine émergent. Ces efforts ont été faits pour atténuer les limitations spécifiques qui existent dans le monde RDBMS . Les jointures ne sont pas possibles dans certaines options NoSQL, vous devez donc conserver plusieurs copies des données. Cela est probablement dû à un manque d'index globaux et au fait que les données sont partitionnées sur des serveurs de base à l'aide d'une clé utilisée pour la récupération. Les utilisateurs de NoSQL s'attendent à des moteurs de recherche en texte intégral comme Lucene, Solr et Sphinx, mais ils ne sont pas les meilleurs. La solution évolutive MarkLogic s'est avérée déployable horizontalement sur du matériel standard d'une capacité de pétaoctets.
C'est un type de base de données très différent des autres bases de données à part entière. MarkLogic n'a jamais été créé pour pouvoir résoudre un problème spécifique. Il a été conçu dès le départ comme une plate-forme pour les applications de classe entreprise, quelle que soit leur taille.
L'entrepôt de données opérationnelles de nouvelle génération de MarkLogic est un outil logiciel permettant d'effectuer des analyses opérationnelles.
Accédez à http://localhost:8000/appservices/ pour trouver la page Application Services. Avec la section Base de données de MarkLogic Server , vous pouvez accéder à toutes les bases de données et supprimer des bases de données, ainsi que créer et configurer une base de données.
Quelle base de données Marklogic utilise-t-il ?
La plupart des organisations ont aujourd'hui besoin d'une base de données pour exécuter leurs opérations. Il est utilisé pour exécuter des applications transactionnelles, opérationnelles et analytiques à partir du centre de données et gérer en toute sécurité un large éventail de sources de données.
La plate-forme de MarkLogic permet le chargement, l'interrogation, la manipulation et le rendu simultanés du contenu. Vous pouvez rechercher rapidement du contenu s'il est automatiquement converti en XML et indexé. Big Publishing a utilisé la requête d'éléments XML, la recherche de proximité XML et la recherche de texte intégral pour améliorer ses capacités de recherche. En 4 à 5 mois, une entreprise pourrait mettre en place une solution et commencer à l'utiliser. Le gouvernement du comté de Quakezone souhaite faciliter l'accès des employés, des développeurs et des résidents du comté aux informations en temps réel en leur facilitant la tâche. Ils ont besoin d'une solution d'infrastructure informatique qui sera mise en œuvre rapidement et facilement. Avec MarkLogic, le comté peut visualiser et corréler les données de différentes manières, notamment en les transformant et en les enrichissant.
Time Traders Services a remplacé son ancien système par MarkLogic Server. La solution est considérablement réduite en termes de latence des alertes tout en fournissant des informations immédiates et pertinentes au portail et aux e-mails du client. Les traders financiers bénéficient d'un avantage au bureau et sur le parquet en informant les clients des nouvelles recherches disponibles. MarkLogic est utilisé pour maintenir des installations top secrètes au sein du gouvernement fédéral. Les bourses bénéficient d'un système matériel à moindre coût lorsque MarkLogic optimise le matériel de base. Avec des performances élevées, il y a moins de serveurs matériels à gérer. Au lieu d'acheter des serveurs plus gros et plus chers, une augmentation de l'évolutivité permet l'installation d'un plus grand nombre de serveurs de base.
L'un des principaux avantages de MarkLogic Data Hub est sa capacité à s'intégrer à d'autres sources de données. Le logiciel peut facilement se connecter aux systèmes hérités tels que l'ERP et le CRM ainsi qu'aux sources plus récentes telles que les entrepôts de données client et les sources de données en continu. De plus, MarkLogic Data Hub est capable de traiter une large gamme de formats de données, ce qui simplifie l'ingestion des données. Enfin, MarkLogic Data Hub est extrêmement facile à utiliser. C'est un programme gratuit, vous n'avez donc pas à payer pour l'utiliser. De plus, le programme est open source, vous pouvez donc le personnaliser pour répondre à vos besoins spécifiques.
Bases de données multi-modèles : le meilleur des deux mondes
Le tableau suivant répertorie les types de base de données les plus courants pour les bases de données multimodèles. Une base de données multi-modèles vous permettra de sélectionner des modèles de données moins coûteux à maintenir. L'indexation de type recherche et le stockage des données transactionnelles de MarkLogic lui permettent de combiner et d'enrichir les données au sein de ses systèmes. Par conséquent, il peut être utilisé pour exécuter des processus ETL. De plus, comme MarkLogic est une base de données de graphes, il s'agit d'une excellente option à triple pile pour ceux qui recherchent une base de données de graphes.
Ldap est-il un Nosql ?
Étant donné que chaque base de données NoSQL est livrée avec son propre protocole, en sélectionner un vous enferme essentiellement dans ce type de base de données. Si vous devez modifier le serveur, vous devez également modifier les clients.
Lorsqu'il était utilisé par Pearson Education, NoSql était utilisé pour héberger des cours en ligne, des dossiers d'étudiants, etc. Dans ce cas, tous les membres de l'équipe devaient être rapidement opérationnels avec Mongo. Il est facile d'oublier le service LDAP, qui est utilisé par des centaines de milliers de serveurs et de postes de travail dans le monde. À l'aide de l'outil de console 389-ds, vous pouvez facilement créer de nouveaux objets et attributs. En termes de cloud computing, je mettrais deux disques maîtres dans chaque zone pour assurer une réplication wan (multimaîtres). Vous pouvez affiner les niveaux de réplication. Pour modifier le schéma, vous pouvez le faire en ligne.
Qu'est-ce qu'un exemple de Nosql ?
La majorité des industries dans lesquelles les bases de données NoSQL sont utilisées en dépendent à diverses fins. Le type de base de données NoSQL utilisé dans un cas donné aura un impact sur son fonctionnement. Les bases de données de documents telles que MongoDB sont des exemples de bases de données à usage général . De grandes quantités de données peuvent être stockées dans des bases de données clé-valeur, ce qui simplifie les requêtes de recherche.
Les avantages des bases de données Nosql
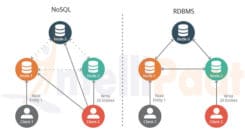
Contrairement aux bases de données relationnelles traditionnelles, les bases de données NoSQL se distinguent d'elles en ce qu'elles rompent avec le modèle traditionnel d'organisation des données au profit d'une structure plus flexible qui permet des magasins de données beaucoup plus dynamiques et vastes. C'est un avantage lorsqu'il s'agit de faire évoluer un magasin de données pour un trafic plus important ou lorsque vous devez répondre aux différents besoins des utilisateurs. En raison de l'ensemble unique d'avantages disponibles dans les bases de données NoSQL, elles deviennent de plus en plus populaires tout le temps, et toutes les applications n'en bénéficieront pas. Si vous recherchez un magasin de données plus flexible capable de gérer un plus large éventail de demandes, les bases de données NoSQL sont un excellent choix.
Uber utilise-t-il Sql ou Nosql ?
Lorsqu'une base de données sans algorithme est utilisée pour stocker des données, on parle de base de données NoSQL. Étant donné que les bases de données NoSQL ne prennent pas en charge les index (en raison de leur manque de transactions distribuées), l'équipe d'exécution d'Uber utilise une table distincte pour stocker l'index.
Uber a publié un article sur son site Web expliquant pourquoi Uber est passé de PostgreSQL à InnoDB. Ce message était composé de l'article Uber dans le but de fournir une meilleure compréhension. PostgreSQL doit toujours mettre à jour tous les index d'une table lors de la mise à jour des lignes lorsqu'il indexe une table, comme décrit en détail dans cet article. Cette approche entraîne également une augmentation des E/S disque pour les mises à jour qui modifient les colonnes non indexées. Dans cet article, ils décrivent la pénalité d'index clusterisé comme un léger inconvénient, ce qui est important si vous exécutez de nombreuses requêtes à l'aide d'index secondaires. L'article omet de mentionner que cette pénalité s'applique à toute instruction avec une clause where, pas seulement à select. Une analyse d'index Postgres uniquement, en revanche, est tout à fait inutile.
Ils semblent bien fonctionner dans un important cas d'utilisation de magasin de clés à l'avenir. Des packages destinés à fonctionner avec des interfaces SQL (mais ayant très peu de fonctions) sont disponibles. Uber a créé sa propre base de données (Schemaless) en plus d'utiliser InnoDB et MariaDB. Une division de nœud est une opération importante dans un arbre B. Une division de nœud se produit lorsqu'un ou plusieurs nœuds sont incapables d'héberger une nouvelle entrée. Dans le pire des cas, la division remontera jusqu'au nœud racine, qui sera également divisé et sera remplacé par un nouveau nœud. En conséquence, l'arbre entier tombe, ce qui fait que l'équilibre de l'indice reste constant.
Un bogue dans le processus de réplication peut laisser de grandes parties de l'arborescence complètement irréparables. Il est possible que le maître ne soit pas en mesure de déterminer ce que les répliques tentent de faire et supprime les données qui sont encore nécessaires pour que la requête soit terminée. Ce problème peut être résolu en retardant l'application du flux de réplication pendant un délai configurable, permettant à la transaction de lecture d'effectuer son tour. Certains ingénieurs ne sont pas des experts en bases de données et ne comprennent pas toujours ce problème, en particulier lors de l'utilisation d'un ORM qui masque les détails de bas niveau comme les transactions ouvertes. La majorité des développeurs savent que les transactions peuvent être utilisées pour annuler l'écriture. Si plus de personnes sont embauchées par une entreprise, leur qualification sera plus proche de la moyenne. L'augmentation de la taille de l'échantillon est motivée par l'embauche de plus de personnes.
Les cas d'utilisation d'Uber ont nécessité l'utilisation de Schemaless, une nouvelle base de données NoSQL . Leur article suggère que Postgres a été remplacé par MySQL, mais ce n'est pas le cas ; au lieu de cela, leur solution sur mesure est soutenue par MySQL. Il n'y a aucune mention de la façon dont leurs exigences ont changé lorsqu'ils sont passés de MySQL à PostgreSQL dans cet article, il n'y a donc aucun moyen de le savoir. Il n'y a qu'une chose qui ressort à l'esprit du lecteur : Postgres est terrible.
Pourquoi les bases de données Nosql sont parfaites pour Ube
La base de données MySQL d'Uber est construite sur une base de données NoSQL, il peut donc être déduit du texte qu'ils utilisent cette base de données. De plus, il peut être déduit des données que cette base de données NoSQL est utilisée pour mettre en cache et mettre en file d'attente des données. Amazon est une autre société de bases de données NoSQL, car elle fournit un ensemble complet d'outils pour développer des applications basées sur des bases de données.
Marklogic Nosql
MarkLogic est une puissante base de données NoSQL qui permet aux développeurs de créer rapidement et facilement des applications qui gèrent de gros volumes de données. MarkLogic est facile à utiliser et à faire évoluer, ce qui en fait un choix idéal pour les organisations qui doivent gérer de grandes quantités de données.
Le serveur MarkLogic est une base de données qui a été entièrement conçue pour permettre aux utilisateurs de rechercher facilement de grandes quantités de données hétérogènes. MarkLogic intègre les composants internes de la base de données, les index de type recherche et les comportements du serveur d'applications dans un système unifié pouvant être exécuté simultanément. Les documents XML et JSON sont utilisés comme modèles de données et leurs données transactionnelles sont stockées dans un référentiel de données transactionnelles . Les données de document peuvent commencer au format XML ou JSON, mais elles peuvent également être transformées une fois ingérées. Les modèles de données de document contiennent généralement toutes les données associées dans le même document, de sorte que les données sont dénormalisées avant d'être rendues publiques. Le contenu XML peut être défini sous forme de schémas pour représenter une classe de modèles de contenu de documents. Lorsqu'un document spécifique doit être structuré d'une manière spécifique, il est essentiel d'avoir un identifiant pour le document.
Les schémas XML peuvent être soit importés dans la base de données Schemas, soit placés dans le répertoire Config. Ensuite, vous pouvez spécifier un ensemble de schémas pour un serveur d'application spécifique ou un groupe de serveurs. MarkLogic prend également en charge les schémas SQL virtuels qui fournissent le contexte des vues SQL, comme défini dans le Guide de modélisation des données SQL. MarkLogic Server peut rechercher, stocker et gérer des données sémantiques dans des triplets RDF, qui sont stockés en mémoire. La sémantique est un ensemble de normes W3C qui permettent un échange de données lisible par machine (et des informations sur les relations entre les données). MarkLogic vous permet de stocker, rechercher et gérer ce type de données à l'aide de SPARQL et SPARQL Update natifs, ainsi que de JavaScript, XQuery et REST. Vous pouvez optimiser la gestion des données binaires avec la suite de mécanismes de MarkLogic Server.

Un document binaire peut être stocké en fonction de sa taille, qui est déterminée par un ensemble de seuils. MarkLogic est une application monothread conçue pour plusieurs processeurs en même temps. Il existe de nombreux ports socket qui peuvent être utilisés pour la communication externe. La plate-forme MarkLogic est conçue pour fournir à la fois vitesse et évolutivité. Les requêtes avancées dans MarkLogic sont écrites en téraoctets de données. Les plus grands déploiements en direct ont maintenant dépassé 200 téraoctets et un milliard de documents. Lorsque des clusters sont utilisés, un haut niveau de disponibilité est atteint.
Ce type de serveur est généralement hébergé dans un boîtier à 4 ou 8 cœurs, 64 ou 128 Go, ou une capacité supérieure. Les équilibreurs de charge élastiques (ELB) sont intégrés à Amazon Elastic Compute Cloud (EC2), ce qui permet aux clusters MarkLogic de distribuer et d'équilibrer automatiquement le trafic des applications. Pour améliorer la disponibilité de l'environnement EC2, les D-Nodes peuvent être regroupés au même emplacement.
Qu'est-ce que la base de données Marklogic
MarkLogic est une puissante base de données NoSQL qui permet aux développeurs de créer des applications plus rapidement en leur fournissant les outils dont ils ont besoin pour travailler avec tous les types de données. MarkLogic est la seule base de données NoSQL qui combine la puissance d'une base de données orientée document avec la flexibilité d'un magasin clé-valeur, ce qui en fait la plate-forme idéale pour les applications modernes d'aujourd'hui.
Il s'agit d'une plate-forme de gestion de données puissante qui fournit un système unifié de gestion des données. Des modèles de données de document en XML et JSON sont utilisés et stockent les documents dans un référentiel transactionnel. Le hub de données est situé au-dessus du lac de données et contient des données de haute qualité, organisées, sécurisées, dédupliquées, indexées et interrogeables. De plus, le hub de données MarkLogic est conçu pour gérer des ensembles de données volumineux avec une hiérarchisation automatisée des données qui stocke et récupère les données d'un lac de données en toute sécurité.
Pourquoi les bases de données graphiques prennent le dessus
Les bases de données graphiques deviennent rapidement l'option incontournable pour stocker des données dans une grande variété de formats difficiles à gérer manuellement. Les bases de données SQL traditionnelles ne peuvent pas gérer ce type de requête, et elles peuvent être très utiles pour traiter ce type de requête. Si vous avez besoin d'interroger des données d'une manière que les bases de données SQL peuvent gérer, ainsi que si vous avez besoin de stocker des données dans des graphiques, MarkLogic est une bonne option.
Base de données Marklogic contre Mongodb
La base de données NoSQL d'entreprise de MarkLogic inclut toutes les fonctionnalités dont vous avez besoin, sur une seule plateforme. MongoDB, en revanche, est utilisé pour organiser de grandes idées. MongoDB est un service MongoDB qui stocke des données dans des documents de type JSON qui peuvent être structurés de différentes manières.
Si vous avez des données META, vous pouvez utiliser MarkLogic car il récupère tout très rapidement. Il existe de meilleures alternatives à l'utilisation d'une base de données relationnelle en cas de besoin. MongoDB est un outil incroyable pour une variété d'applications en raison de son incroyable flexibilité et de sa facilité d'utilisation. Malgré le fait que l'open source est utilisé dans presque tout le reste, la base de données principale est d'une importance cruciale. Le support client de MarkLogic est extrêmement réactif et professionnel. Ils réagissent rapidement aux problèmes majeurs et aux problèmes de qualité de production. J'ai hâte d'utiliser les ressources de MongoDB pour bénéficier d'une partie de sa puissance.
Seuls quelques aspects peuvent être améliorés ou simplifiés. Si vous ne disposez pas déjà d'un administrateur de base de données ou d'un administrateur système connaissant MongoDB, vous devez vous adresser à un fournisseur d'hébergement MongoDB spécialisé dans le domaine. Lorsque votre ensemble de données augmente, vous pouvez utiliser le moteur de stockage de Cassandra pour créer des écritures à temps constant. MongoDB peut être utilisé pour l'analyse à l'aide de la prise en charge native de Hadoop.
Base de données de graphes Marklogic
MarkLogic est une base de données de graphes. Il utilise un modèle de données graphique pour stocker et interroger les données. Une base de données de graphes est une base de données qui utilise un modèle de données de graphe pour stocker et interroger des données.
Le Guide du développeur de graphes sémantiques est une lecture incontournable pour toute personne intéressée par le domaine des graphes sémantiques. Les sujets inclus dans ce guide incluent : Les données peuvent être téléchargées. En utilisant l'échantillon complet de données personnelles de DBPedia (en tortue et en anglais), vous pouvez leur montrer comment utiliser un mot tortue ou anglais. La base de données Documents possède un triple index et un lexique de collection qui peuvent être activés par défaut. Avant d'utiliser une base de données pour les triplets, assurez-vous que les deux options sont activées. mlcp est une méthode idéale pour charger en bloc des triplets sur un environnement de bureau Windows. La fonction SPARQL native ou la fonction intégrée sem:sparQL sont toutes deux des méthodes acceptables pour exécuter des requêtes MarkLogic . La section Téléchargement du jeu de données suppose que vous avez chargé l'exemple de jeu de données.
Centre de données Marklogic
Le Data Hub de MarkLogic est une interface logicielle open source gratuite qui ingère des données provenant de plusieurs sources, les harmonise, les maîtrise, puis les recherche et les analyse. La solution est exécutée sur MarkLogic Server et vise à fournir une plate-forme unifiée pour les applications critiques.
À quoi sert Marklogic
MarkLogic est une base de données puissante qui vous permet de stocker, de gérer et de rechercher des données plus efficacement. Il est utilisé par des organisations de divers secteurs pour alimenter leurs applications et leurs sites Web. MarkLogic est particulièrement bien adapté pour gérer de grandes quantités de données et des requêtes complexes.
Serveur Marklogic
MarkLogic Server est une plate-forme de base de données NoSQL puissante qui permet aux développeurs de créer rapidement et facilement des applications sophistiquées qui exploitent toutes leurs données, quelle que soit leur structure ou leur emplacement. MarkLogic Server est construit sur une architecture unique qui combine le meilleur des mondes relationnel et NoSQL, offrant aux développeurs la flexibilité de travailler avec leurs données de la manière qui répond le mieux à leurs besoins.
DocumentManager, une instance DatabaseClient créée spécifiquement pour la gestion de documents, peut être utilisée pour gérer des documents. Pour montrer comment lire un document XML, utilisez ReadXMLDocument.java basé sur Java de Marklogic. La bibliothèque Java ReadMetadata vous montre comment détecter le type de document que vous avez reçu ainsi que comment le gérer correctement. L'insertion d'un document texte est similaire à l'insertion d'un document PDF, mais vous devez utiliser un StringHandle ou fournir le format comme indiqué dans l'exemple précédent. L'API Java peut être utilisée pour accéder aux documents et aux métadonnées de différentes manières. La méthode DeleteDocument.java peut être utilisée pour supprimer plusieurs documents à la fois. Téléchargements de documents de grandes proportions.
Un document à la fois peut être coûteux lors de l'utilisation de schémas d'authentification Digest, car un seul document est nécessaire pour le téléchargement. Nous utilisons des termes tels que recherche et requête de la même manière dans MarkLogic, quel que soit le contexte dans lequel nous les utilisons. Si vous souhaitez exprimer un large éventail de résultats de recherche, une syntaxe de requête est un moyen simple et puissant de le faire. Le texte de recherche est spécifié à l'aide de la méthode setCriteria de notre gestionnaire de requêtes après avoir récupéré une instance de requête de chaîne initiale de notre gestionnaire de requêtes. Il est vrai que même une simple recherche peut être très puissante si elle est utilisée dans la configuration de recherche par défaut de MarkLogic. Comme spécifié dans la définition de la requête, trois méthodes sont utilisées pour implémenter chaque requête. Les deux premières options vous permettent de spécifier un emplacement de requête ou un ensemble de collections.
Le dernier vous permet d'associer une requête à un ensemble d'options de recherche personnalisées qui sont stockées sur le serveur. Voici une liste des résultats de la recherche. En exécutant le programme et en inspectant la console, vous pouvez voir comment MarkLogic représente ses résultats de recherche en XML. Le projet de didacticiel inclut un script Java appelé Search ResultsAsJSON. Java. Si vous exécutez le programme, vous verrez les résultats de recherche JSON bruts qui ont été récupérés à partir du serveur. Obtenez les résultats de la recherche au format POJO en appelant sa méthode getMatchResults().
Vous pouvez obtenir un tableau d'objets MatchDocumentSummary en lui transmettant une chaîne. Lorsqu'un document contient un résultat de recherche, il peut être représenté par un objet MatchLocation. Une option nommée par défaut est utilisée si vous ne spécifiez pas explicitement un nom. En raison de son importance dans Mark Logic, la contrainte est fréquemment utilisée. La configuration d'un jeu d'options entier est stockée dans src/main/ml-options/options lors de la création ou du remplacement d'un jeu d'options. Les contraintes répertoriées ici sont disponibles sous diverses formes. Faites un programme.
Cette méthode doit renvoyer les mêmes résultats que CollectionSearch java. Suite à cette nouvelle chaîne de recherche, le critère de collection Shakepeare est désormais fourni dans le cadre de la chaîne de recherche par la contrainte de balise. Comme vous pouvez le voir, nous utilisons la commande suivante pour déployer notre configuration. Vous pouvez, à la place, ouvrir une nouvelle invite de commande et accéder à mlwatch, où les modifications apportées à votre script seront transmises à Mark Logic. Le contexte d'un mot est testé plutôt que sa clé ou son élément en termes de contrainte de mot, qui est similaire à une contrainte de valeur. Les mots correspondants sont également formés par des tiges souches, ce qui signifie que des mots similaires seront utilisés, tels que stratégies et stratégies. Nous devons créer/modifier les fichiers suivants afin d'activer le stemming : src/main/ml-config/databases/content-database.
L'exécution de la commande ci-dessous vous aidera à comprendre la procédure. Le module gradle mlUpdateIndexes est utilisé pour mettre à jour les tables d'index dans le module gradle mlReindexDatabase. En utilisant la contrainte de propriétés, nous pouvons rechercher les propriétés d'un document par métadonnées. Nous utilisons nos métadonnées extraites lors de l'ingestion et stockées en tant que propriétés de document pour générer nos images. Lorsque nous entrons dans une recherche de mot pour "propriétés", elle ne sera appliquée qu'à cette propriété de document. La méthode search() est utilisée dans le gestionnaire de requêtes pour exécuter la requête.
À quoi sert Marklogic ?
MarkLogic Server est un outil logiciel qui stocke et gère une variété de données afin d'exécuter des applications transactionnelles, opérationnelles et analytiques.
Le hub de données : votre solution unique pour la gestion des données
Les hubs de données vous donnent un contrôle total sur la façon dont les données sont gérées et accessibles à partir d'un lac de données. Dans MarkLogic, la hiérarchisation automatisée des données garantit que les données sont stockées en toute sécurité et accessibles à partir d'un lac de données, et simplifie l'intégration des données.
Comment puis-je me connecter à Marklogic ?
Après l'installation et le lancement de MarkLogic, accédez à l'interface d'administration basée sur un navigateur (à l'adresse http://localhost:8001/), où vous apprendrez comment obtenir une licence de développeur et configurer un administrateur.
Marklogic : le serveur d'applications avec une API de repos
L'utilisation d'applications clientes d'API REST pour interagir avec MarkLogic Server à l'aide d'une instance d'API REST est de plus en plus courante. MarkLogic emploie 500 personnes et est l'un des plus grands fournisseurs de serveurs d'applications sur le marché. Selon leurs projections de revenus, ils auront un revenu maximal de 100,0 millions de dollars en 2021, avec un revenu moyen par employé de 200 000 $.