
Les avantages et les inconvénients des bases de données en colonnes
Publié: 2022-11-19Les bases de données NoSQL sont un excellent choix pour de nombreuses applications modernes, mais il y a quelques éléments clés à prendre en compte avant de faire le changement. Un facteur important est de savoir si vous avez besoin d'une base de données relationnelle ou non. Si vous le faites, une base de données en colonnes n'est peut-être pas le bon choix. Les bases de données en colonnes sont bien adaptées aux applications qui doivent analyser rapidement de grandes quantités de données. Ils constituent également un bon choix pour les applications qui n'ont pas besoin du modèle relationnel complet et qui peuvent se contenter d'un modèle de données plus simple. Cependant, les bases de données en colonnes présentent quelques inconvénients. Elles peuvent être plus difficiles à utiliser que les bases de données relationnelles et peuvent ne pas prendre en charge toutes les fonctionnalités dont vous avez besoin. Avant de décider si une base de données en colonnes convient à votre application, assurez-vous de bien comprendre les avantages et les inconvénients.
Une base de données en colonnes organise et stocke les données par colonnes plutôt que par lignes. Ils utilisent des fonctions et des opérations d'agrégation pour optimiser les colonnes de données. Les colonnes de base de données sont évolutives et se compriment bien par rapport à d'autres types de bases de données. Dans une base de données en colonnes, chaque ligne de données est séparée en plusieurs colonnes par un certain nombre de colonnes. Les bases de données en colonnes sont bien adaptées au traitement du Big Data, à la Business Intelligence (BI) et à l'analyse. Les opérations sur les lignes ont un temps beaucoup plus lent que les opérations sur les colonnes. Les enregistrements IoT peuvent ne contenir qu'un petit nombre d'éléments de données lorsque de nouveaux enregistrements arrivent dans un flux cohérent. Le Big Data a le potentiel de transformer le fonctionnement des systèmes de bases de données opérationnelles.
Les deux types de bases de données de base de données, ligne et colonne, peuvent charger des données et effectuer des requêtes à l'aide de langages de requête de base de données traditionnels tels que SQL. Dans de nombreux cas, les dorsales de bases de données, telles que les bases de données en lignes et en colonnes, peuvent servir de moteur pour l'extraction, la transformation, le chargement et la création d'outils de données communes.
Une base de données en colonnes, un type de système de gestion de base de données (SGBD), stocke les données dans des colonnes plutôt que dans des lignes. Afin d'accélérer le retour d'une requête, les colonnes d'une base de données en colonnes peuvent être écrites et lues efficacement depuis et sur le disque dur.
Aujourd'hui, nous allons examiner le fonctionnement des colonnes dans une base de données en colonnes et les comparer à une base de données orientée lignes plus traditionnelle (par exemple, MySQL). Nous verrons ce qu'est une base de données en colonnes dans cet article, ainsi que ses avantages et ses inconvénients.
Quels sont quelques exemples d'une base de données NoSQL ? Microsoft SQL Server est un système de gestion de base de données relationnelle créé par Microsoft.
Mongodb est-il une base de données en colonnes ?
Mongodb n'est pas une base de données en colonnes.
Il devient de plus en plus populaire car il offre des performances de requête améliorées dans les requêtes analytiques. Les données dans les bases de données en colonnes sont stockées de manière plus efficace que dans les magasins de données basés sur des bases de données car les données sont stockées dans des colonnes. Les requêtes analytiques effectuées sur des bases de données en colonnes présentent un plus grand avantage en termes de performances. Par rapport au stockage orienté lignes, le stockage en colonnes est beaucoup plus efficace en termes d'espace de stockage et de performances des requêtes. Étant donné que les données sont stockées sous forme de colonnes, les données peuvent être lues et écrites plus facilement.
Quelles sont les bases de données Nosql ?
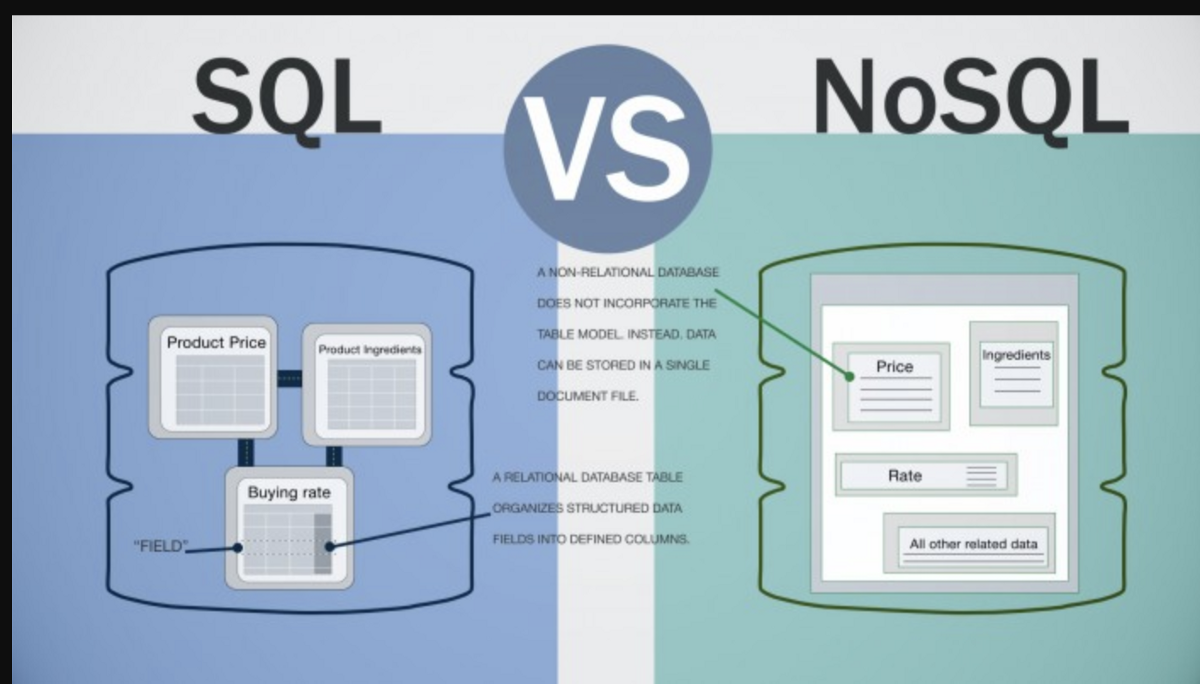
Les bases de données NoSQL sont des bases de données qui n'utilisent pas le modèle de base de données relationnelle traditionnel. Au lieu de cela, ils utilisent une variété de modèles différents, y compris document, graphique, clé-valeur et colonne. Les bases de données NoSQL sont souvent mieux adaptées pour gérer de grandes quantités de données qui ne sont pas bien adaptées au modèle relationnel.
Un système NoSQL est un type de base de données qui n'est pas basé sur SQL. Le modèle de données utilisé par l'équipe de modélisation des données diffère du modèle traditionnel de table en lignes et colonnes utilisé dans les systèmes de gestion de bases de données relationnelles. Les bases de données NoSQL, en plus d'être assez différentes les unes des autres, sont également assez différentes les unes des autres. Les bases de données de documents sont généralement implémentées avec une architecture évolutive pour les types de documents les plus courants. Les plates-formes de commerce électronique, les plates-formes de trading et le développement d'applications mobiles sont tous des exemples de la façon dont ces plates-formes peuvent bénéficier à une entreprise. L'objectif principal de la comparaison de MongoDB et Postgres est de fournir une comparaison détaillée des principales bases de données NoSQL. La capacité d'une base de données en colonnes à agréger la valeur d'une seule colonne est idéale pour analyser rapidement une colonne spécifique.
Parce que la manière dont les données sont écrites rend difficile la cohérence, elles doivent s'appuyer sur une variété de sources. Les bases de données de graphes sont optimisées pour capturer et rechercher des connexions entre des éléments de données afin de les capturer et de les rechercher. La surcharge associée à JOINING plusieurs tables dans SQL est éliminée avec l'utilisation de ces méthodes.
MongoDB stocke généralement les documents dans une collection appelée collection. C'est la collection de documents qui sont liés entre eux par un aspect. Les données des collections sont généralement utilisées par plusieurs applications pour stocker des données.
Les données de MongoDB sont stockées dans un arbre B, ce qui signifie qu'elles sont organisées en compartiment ou en niveau. Un compartiment est une collection de données fréquemment consultée par un navigateur. Le niveau est plus grand car il contient plus de seaux. Les données d'un arbre B peuvent être triées par ordre croissant de clé.
Parce que MongoDB est si simple à mettre à l'échelle, c'est une plate-forme fantastique pour la mise à l'échelle. Si votre cluster subit une augmentation de la charge, vous devrez peut-être ajouter plus de serveurs. De plus, MongoDB peut être mis en cluster pour fournir des données HA (haute disponibilité).
Pourquoi les bases de données Nosql gagnent en popularité
Malgré le fait que les bases de données NoSQL deviennent de plus en plus populaires dans de nombreux cas, elles restent une alternative aux bases de données relationnelles. Les données qui ne peuvent pas être stockées dans une base de données relationnelle, telles que les grands graphiques ou les données qui changent régulièrement, les intéressent particulièrement.
Exemple de base de données en colonnes Nosql
Une base de données en colonnes est un système de gestion de base de données (SGBD) qui stocke les données dans des colonnes au lieu de lignes. Les systèmes orientés colonnes sont souvent plus rapides pour les charges de travail analytiques que les systèmes traditionnels orientés lignes.
Par exemple, une base de données en colonnes peut stocker des données sur les employés, chaque colonne contenant des données telles que l'ID de l'employé, le nom, le titre du poste, le salaire, etc. Une base de données orientée ligne stockerait les mêmes données, chaque ligne contenant l'ID, le nom, le titre du poste, le salaire, etc. d'un employé.
NoSQL est une avancée importante dans le domaine des données relationnelles car il élimine le besoin de systèmes hautement spécialisés ou chronophages. Les bases de données NoSQL de document, de graphique, de colonne et de valeur de ligne sont les quatre principaux types. Les magasins de documents contiennent à la fois des schémas de données complexes et des paires de clés associatives. Les colonnes de base de données organisent les données en colonnes et fonctionnent de la même manière que les bases de données relationnelles. Il existe une évolutivité de grille horizontalement à l'infini disponible dans les bases de données de colonnes . La compression est une méthode de stockage bien faite et les magasins de colonnes fournissent beaucoup d'espace de stockage. La vitesse à laquelle les requêtes d'agrégation sont exécutées est généralement plus rapide que celle d'une base de données relationnelle.
En raison de la nature horizontale de la conception des données, les applications OLTP ne peuvent pas être utilisées conjointement avec des magasins en colonnes. Les magasins de colonnes , en tant que solution, ont le potentiel d'être extrêmement puissants, mais ils ont également le potentiel d'être extrêmement limités. Bien que les colonnes offrent moins de garanties de cohérence et d'isolation que les lignes, chaque ligne doit être réécrite plusieurs fois. Les bases de données NoSQL sont plus vulnérables aux attaques en ligne en raison du manque de fonctionnalités de sécurité natives. Si la cybersécurité est une priorité pour vous, vous devez utiliser un modèle relationnel ou définir votre schéma.
Base de données Nosql
Une base de données NoSQL est une base de données non relationnelle qui n'utilise pas le modèle traditionnel de base de données relationnelle basé sur des tables. Les bases de données NoSQL sont souvent utilisées pour le Big Data et les applications Web en temps réel.
Base de données Les bases de données NoSQL ne stockent pas les données dans les bases de données relationnelles traditionnelles . Les types de documents, les types de valeurs-clés, les types de colonnes larges et les types de graphiques sont les plus courants. Le coût de stockage des données a considérablement diminué ces dernières années, entraînant le développement des bases de données NoSQL. Ils peuvent stocker une grande quantité de données non structurées, permettant aux développeurs de sélectionner les aspects des données qu'ils souhaitent enregistrer. Les bases de données de documents, les bases de données clé-valeur, les magasins à colonnes étendues et les bases de données de graphes sont des exemples de bases de données NoSQL. Comme aucune jointure n'est requise, les requêtes sont exécutées plus rapidement. Des cas d'utilisation gourmands en données tels que l'analyse financière et les lectures IoT de bacs à litière pour chats intelligents peuvent être utilisés, tandis que des applications moins sérieuses telles que des cas d'utilisation amusants et divertissants tels que des emballages alimentaires intelligents peuvent être utilisées.
Dans ce didacticiel, nous verrons quand et pourquoi vous devriez envisager les bases de données NoSQL. De plus, nous examinerons certaines des idées fausses les plus courantes sur les bases de données NoSQL. Selon DB-Engines, MongoDB est la base de données NoSQL la plus populaire au monde. Dans ce tutoriel, vous apprendrez à interroger une base de données MongoDB sans rien installer sur votre ordinateur. Les clusters de bases de données sont un exemple de base de données MongoDB. Dès que vous aurez un cluster, Atlas commencera à stocker des données. Vous avez trois options pour créer une base de données dans Atlas Data Explorer, MongoDB Shell ou MongoDB Compass : manuelle ou automatisée.
Dans ce cas, l'exemple de jeu de données d'Atlas sera importé. Les bases de données NoSQL présentent de nombreux avantages en plus de leurs modèles de données flexibles, de leur mise à l'échelle horizontale, de leurs requêtes ultra-rapides et de leur facilité d'utilisation. L'explorateur de données peut être utilisé pour insérer de nouveaux documents, modifier des documents existants et les supprimer. L'utilisation du cadre d'agrégation est un outil extrêmement puissant pour analyser vos données. L'utilisation de graphiques pour visualiser les données stockées dans Atlas et Atlas Data Lake est le moyen le plus simple de le faire.
Une base de données clé-valeur est le type le plus simple de NoSQL, avec plusieurs tables contenant des clés et des valeurs. La clé n'est requise que pour l'accès aux données, ce qui simplifie la lecture et l'écriture. Cependant, ce type de base de données n'est pas adapté aux grands ensembles de données car chaque clé de la base de données doit être unique.
Les données sont stockées dans des tables contenant des colonnes, qui stockent les clés et les valeurs des bases de données basées sur des colonnes. En raison de sa polyvalence, une base de données basée sur des colonnes peut stocker des données plus longtemps qu'une base de données sans colonnes.
Les bases de données de documents, contrairement aux bases de données de colonnes, stockent les données dans des tables avec des colonnes qui stockent des clés et des valeurs. Les bases de données basées sur des documents, quant à elles, stockent les données dans des fichiers, similaires aux e-mails. Parce que les documents sont simples à lire et à comprendre, les données peuvent être recherchées et visualisées de manière simple.
Une base de données basée sur des graphiques est similaire à une base de données basée sur des documents en ce sens que les données sont stockées dans des tables contenant des colonnes avec des clés et des valeurs. En revanche, les graphes, qui sont similaires aux réseaux en termes de stockage de données, sont stockés dans des bases de données basées sur des graphes. Les nœuds de données peuvent être connectés et les modèles peuvent être identifiés facilement.

Types de base de données Nosql pour chaque besoin
Les bases de données documentaires telles que MongoDB sont bien adaptées aux applications qui doivent stocker des informations dans un format flexible et modulaire. Dans MongoDB, JSON, texte et BSON sont tous pris en charge. Cela en fait un excellent choix pour les applications telles que les blogs et les wikis, qui stockent de grandes quantités de données non structurées.
Cassandra et d'autres bases de données basées sur des colonnes sont d'excellentes options pour les applications qui doivent stocker de grandes quantités de données dans un format en colonnes. Des formats de données tels que le propre format binaire d'Avro et de Cassandra peuvent être utilisés en plus du stockage basé sur du texte dans HBase. Parce qu'il a la capacité de stocker des données qui ne peuvent pas tenir dans une base de données relationnelle, il est bien adapté aux applications qui nécessitent une grande quantité de données.
DynamoDB et d'autres bases de données clé-valeur sont bien adaptées aux applications qui stockent généralement de petites à moyennes quantités de données. DynamoDB, par exemple, prend en charge les formats de données JSON et binaires. Cela en fait un excellent choix pour les applications qui stockent des données trop petites pour une table relationnelle et fréquemment consultées mais qui ne nécessitent pas de format spécifique, ainsi que pour les applications qui doivent stocker des données fréquemment consultées mais qui ne nécessitent pas de format spécifique. format.
Il est bien adapté aux applications qui nécessitent l'intégration d'éléments de données stockés dans des bases de données de graphes, telles que Neo4j. Par exemple, les formats de données tels que JSON, Atom et Graph peuvent être utilisés dans les bases de données de graphes. Il est idéal pour les applications qui doivent stocker des données trop complexes pour être stockées dans une base de données relationnelle ou qui stockent des données auxquelles on accède fréquemment mais qui ne doivent pas être stockées dans un format spécifique.
Base de données en colonnes open source
Une base de données en colonnes est un type de base de données qui stocke les données dans des colonnes au lieu de lignes. Ce type de base de données est souvent utilisé pour les applications d'entreposage et d'analyse de données, car il peut offrir de meilleures performances et une meilleure évolutivité qu'une base de données traditionnelle basée sur des lignes.
Il existe un certain nombre de bases de données en colonnes open source disponibles, telles qu'Apache Cassandra, Apache HBase et Apache Drill. Chacune de ces bases de données a ses propres forces et faiblesses, il est donc important de choisir la bonne pour vos besoins spécifiques.
Ces bases de données sont idéales pour un flux de travail d'analyse efficace, car elles sont à la fois rapides et évolutives. Au lieu de stocker des données dans des lignes, des colonnes sont utilisées dans la base de données en colonnes. L'utilisation du stockage basé sur des colonnes améliore les performances des requêtes de base de données en réduisant considérablement le nombre de tentatives d'E/S. Il a été utilisé pour alimenter Amazon Redshift et Snowflake ainsi que d'autres entrepôts relationnels. Pour améliorer le débit des bases de données en colonnes, des clusters matériels à faible coût sont utilisés pour les mettre à l'échelle. Dans les bases de données traditionnelles , les lignes sont divisées en différentes sections de données. Les éléments les plus pertinents d'une base de données en colonnes sont accessibles en quelques secondes.
Même si la base de données est volumineuse, cela augmente la vitesse des requêtes. Le coût de traitement et de stockage de la quantité accrue de données augmente également. Parquet et ORC sont deux des formats les plus largement utilisés pour les colonnes dans les bases de données. Parquet est utilisé pour présenter des colonnes plates de données de manière plus efficace. ORC est un format de fichier spécialement conçu pour les charges de travail Hadoop et optimisé pour les lectures en continu volumineuses. Hevo Data, un pipeline de données sans code, vous permet d'intégrer les données de diverses bases de données avec plus de 100 autres sources et de les charger dans votre outil de BI préféré. Apache Druid est une base de données d'analyse en temps réel basée sur un logiciel open source qui peut exécuter des requêtes OLAP sur de grands ensembles de données à un rythme beaucoup plus rapide.
Le moteur de stockage de données distribué open source Apache Kudu est utilisé pour exécuter des processus analytiques rapides sur des quantités massives d'informations. Le modèle de stockage de MonetDB est basé sur la fragmentation verticale et son architecture d'exécution des requêtes est basée sur des ordinateurs modernes. Le moteur de rapport analytique ClickHouse permet la génération de rapports en temps réel. BigQuery est le résultat du moteur de requête distribué de Google, connu sous le nom de Dremel. L'architecture sans serveur de Dremel peut traiter des téraoctets de données en quelques secondes en utilisant l'informatique distribuée. La compression, la projection juste-à-temps et le partitionnement horizontal et vertical sont quelques-uns des avantages du stockage basé sur des colonnes. Les données peuvent être stockées en lignes dans une base de données en colonnes, qui est une base de données orientée lignes.
Ils évoluent en utilisant des clusters avec une technologie à faible coût pour augmenter le débit. Les bases de données en colonnes peuvent être utilisées à diverses fins dans le traitement du Big Data, l'informatique décisionnelle (BI) et l'analyse. Les appareils de l'Internet des objets (IoT) stockent une grande quantité de données dans leurs centres de données.
Les trois bases de données de stockage de données orientées colonnes les plus populaires
Apache Cassandra est un système de stockage de données bien connu dans une variété de bases de données orientées colonnes. Cassandra est un projet open source côté serveur qui peut gérer d'énormes quantités de données sur de nombreux serveurs de base. DynamoDB, quant à lui, utilise un modèle de base de données NoSQL et peut stocker tout type de données. MariaDB conserve le modèle relationnel et SQL tout en permettant une génération de requêtes analytiques plus rapide et plus facile, ce qui en fait un choix populaire pour de nombreuses bases de données en colonnes.
Meilleure base de données en colonnes
Il n'y a pas de réponse définitive à cette question car cela dépend des préférences et des besoins individuels. Cependant, certaines des bases de données en colonnes les plus populaires incluent Amazon Redshift, Google BigQuery et Microsoft SQL Server. Ces bases de données sont toutes hautement évolutives et offrent d'excellentes performances pour les charges de travail d'entreposage et d'analyse de données.
Les données d'une base de données en colonnes sont stockées dans des colonnes plutôt que dans des lignes. Par rapport aux bases de données en ligne traditionnelles, les bases de données en colonnes offrent une variété d'avantages, notamment la vitesse et l'efficacité. Sadas Engine est le système de gestion de base de données en colonnes le plus puissant et le plus flexible disponible à la fois sur site et dans le cloud. ClickHouse est un système de gestion de base de données open source facile à utiliser. Amazon Redshift, l'entrepôt de données cloud le plus rapide au monde, continue de croître en vitesse. ClickHouse utilise tout le matériel disponible à son plein potentiel afin de traiter chaque requête le plus rapidement possible. Le moteur de recherche et d'analyse de Rockset alimente les affichages de tableau de bord en direct et les applications en temps réel.
Vertica est la base de données analytique avancée la plus rapide et la plus évolutive du marché. Le langage SQL ANSI est idéal pour l'analyse des pétaoctets car il peut gérer les données à des vitesses ultra-rapides tout en éliminant les frais généraux opérationnels. Analyses à la demande à grande échelle avec un coût de possession sur trois ans de 26 à 34 % inférieur à celui des alternatives d'entrepôt de données cloud. Vous pouvez crypter vos données à la demande et à la maison avec des clés de cryptage gérées par l'entreprise ou vous pouvez les régler sur cryptage à volonté. Greenplum Database est une plate-forme de données massivement parallèle open source qui fournit des capacités d'analyse, d'apprentissage automatique et d'intelligence artificielle. L'outil fournit une analyse de données en temps réel sur des volumes de données à l'échelle du pétaoctet à une vitesse fulgurante. Avec sa conception de base, Druid combine des idées d'entrepôts de données, de bases de données de séries chronologiques et de systèmes de recherche pour créer une base de données d'analyse haute performance en temps réel.
Apache 2 est le code source de ce projet. MariaDB Platform, une base de données open source d'entreprise, est la base de cette solution. Cette plate-forme peut prendre en charge un large éventail de charges de travail transactionnelles, analytiques et hybrides. MariaDB peut être déployée sur du matériel standard ou dans un cloud public, selon le type de matériel utilisé. Les étudiants, les enseignants, les chercheurs, les entrepreneurs, les petites entreprises et les multinationales du monde entier peuvent rejoindre la communauté MonetDB. Nous fournissons une base de données en tant que service pour CrateDB, qui est entièrement gérée. Le stockage de table facilite la mise à l'échelle de vos données en éliminant le besoin de partitionnement manuel.
Trois fois les données stockées d'une région sont répliquées à l'aide d'un stockage géo-redondant. Il est simple de porter des applications héritées ou d'en créer de nouvelles avec le modèle de données simple de Kudu. Parquet permet de spécifier des schémas de compression colonne par colonne, et il est évolutif afin que de nouveaux schémas de compression puissent être ajoutés si nécessaire. Hypertable, comme son nom l'indique, est conçu pour résoudre le problème d'évolutivité selon ses propres termes. Il est conçu pour prendre en charge les charges de travail OLAP basées sur le SGBD en colonne InfiniDB . Les performances de QikkDB dans les opérations de big data et de polygones complexes sont inégalées. La base de données qikkDB est construite avec les fonctionnalités suivantes : Il s'agit d'une base de données en colonnes de séries chronologiques historiques multiplateforme hautes performances avec un moteur de calcul en mémoire.
Q, processeur de streaming et langage de programmation, est destiné à vous permettre de vous exprimer en temps réel. L'index trié, l'index bitmap et l'index inversé sont les trois technologies d'indexation auxquelles vous pouvez vous connecter. Apache Version 2.0 a été concédé sous licence pour ce projet.
Les bases de données orientées colonnes sont l'avenir
Un grand nombre de bases de données ont été conçues autour de colonnes ces dernières années. Étant donné que ces bases de données stockent les données dans des lignes et des colonnes, elles sont simples à utiliser et à gérer. Plusieurs bases de données orientées colonnes sont disponibles, notamment MariaDB, CrateDB, ClickHouse, Greenplum Database, Apache Hbase, Apache Kudu, Apache Parquet, Hypertable et MonetDB. Les données de document, de graphique et de colonne peuvent être générées dans DynamoDB à l'aide d'un modèle de base de données NoSQL. MongoDB, la société à l'origine de la base de données du magasin de documents, a annoncé la sortie de l'indexation columnstore, qui permet aux développeurs de créer des requêtes analytiques dans leurs applications.
Exemple de base de données en colonnes
Une base de données en colonnes est un type de base de données qui stocke les données dans des colonnes au lieu de lignes. Ce type de base de données est souvent utilisé pour les applications d'entreposage et d'analyse de données, car il peut offrir de meilleures performances et une meilleure évolutivité qu'une base de données traditionnelle basée sur des lignes. Apache HBase est un exemple de base de données en colonnes.
Les opérations de base de données diffèrent de celles des autres bases de données dans la mesure où les colonnes distribuent généralement les informations en lignes. La capacité d'analyser de grands ensembles de données est particulièrement attrayante pour les bases de données en colonnes. Les magasins de documents qui utilisent des bases de données NoSQL ont gagné en popularité ces dernières années. Les bases de données de graphes deviennent également de plus en plus populaires à mesure que de plus en plus de personnes les utilisent, car elles peuvent cartographier très précisément des données hautement en réseau. Pendant longtemps, les systèmes de gestion de bases de données en colonnes ont été utilisés. Malgré le fait qu'il existe encore quelques implémentations disponibles, plusieurs systèmes ont été développés. L'accès aux applications transactionnelles est généralement différent de l'accès aux autres applications. Cette tâche serait effectuée beaucoup plus lentement dans une base de données en colonnes que dans une base de données conventionnelle .
Pourquoi les bases de données orientées colonnes deviennent de plus en plus populaires
Les bases de données orientées colonnes telles que Cassandra, MariaDB et CrateDB gagnent en popularité en tant que solutions de stockage de données pour les applications qui gèrent de grandes quantités de données. Étant donné que les données peuvent être stockées dans une base de données avec plusieurs lignes de la même table (famille de colonnes), il est plus facile de stocker des données et d'améliorer les performances.
Plusieurs bases de données orientées colonnes, telles que MariaDB, CrateDB, ClickHouse, Greenplum Database, Apache Hbase, Apache Kudu et Apache Parquet, sont disponibles. Toutes ces bases de données sont open source et ont été utilisées avec succès dans une variété d'applications.