
Google's Bigtable: Penyimpanan Data Berorientasi Kolom yang Paling Banyak Digunakan
Diterbitkan: 2022-12-19Bigtable adalah penyimpanan data berorientasi kolom yang dibuat oleh Google. Ini dirancang untuk menangani data dalam jumlah besar dengan tingkat fleksibilitas yang tinggi. Bigtable telah digunakan oleh Google selama lebih dari satu dekade, dan menjadi dasar bagi banyak layanannya, termasuk Gmail, Google Maps, dan YouTube. Meskipun Bigtable bukan penyimpanan data berorientasi kolom pertama, ini pasti yang paling banyak digunakan dan terkenal.
Pada artikel ini, kita akan membahas model penyimpanan NoSQL tiga dimensi yang dikembangkan oleh Bigtable. Untuk memverifikasi bahwa itu terstruktur dengan benar, pertama-tama kita akan melihat bagaimana penerapannya dalam istilah teoritis dan kemudian menggunakan klien Node.js untuk melakukannya. Model penyimpanan di Bigtable berbeda dari cara Anda menemukannya di database serupa. Beberapa sel dalam kombinasi baris/kolom dapat diurutkan berdasarkan stempel waktu per sel. Alih-alih menyimpan sel dalam urutan yang sewenang-wenang, setiap sel memiliki nilai dan stempel waktu untuk memastikan bahwa sel disimpan dalam urutan yang teratur. Untuk contoh ini, kami akan menggunakan Node.js dan JavaScript biasa untuk membuat Google Cloud Bigtable. Dalam artikel ini, kita akan membahas cara membuat instance Bigtable baru menggunakan kode.
Kita mulai dengan menciptakan lingkungan yang bersih, membaca dan menulis di atasnya, lalu merobohkannya. Saat menjalankan kode menggunakan klien Node.js Bigtable, klien Node.js Bigtable dapat menyebabkan error Permission Denied dan membuat link untuk mengaktifkan Cloud Bigtable Admin API. Anda juga harus membuat akun layanan terpisah di project GCP untuk menangani peran Administrator Bigtable. Untuk membuat tabel Bigtable, pertama-tama kita harus membuat instance database dan sekelompok tabel. Cukup tentukan ID tabel dan keluarga kolom di klien Node.js untuk melakukan ini, dan Anda siap melakukannya. Baris sederhana dapat dibuat dengan menggunakan Bigtable dalam database. Satu-satunya cara untuk mengkueri data adalah dengan menggunakan kunci baris untuk mengkueri baris atau grup baris tertentu.
Meskipun waktu penyerapan tidak berpengaruh pada urutan penyimpanan versi, waktu tersebut berpengaruh pada cara penyimpanannya. Tidak diperlukan untuk memberikan seluruh kunci baris; cukup awalan saja. Saat Anda perlu membuat kueri beberapa baris dari Bigtable, saya selalu menyarankan untuk menggunakan streaming. Saat menggunakan streaming, Bigtable tidak perlu menyangga data di server sebelum mengirimkan baris, sehingga menghasilkan kinerja yang lebih cepat. Filter dapat digunakan untuk membatasi versi sel, hanya mengembalikan kolom tersebut dengan nama keluarga tertentu atau kolom dengan kriteria kualifikasi tertentu. Ini sangat berguna jika Anda memiliki banyak versi untuk disimpan, tetapi hanya versi terbaru yang diperlukan untuk tujuan tertentu. Filter terutama digunakan untuk mengurangi jumlah data yang diminta dan dikirim untuk meningkatkan kinerja kueri.
Dengan kata lain, Cloud Bigtable adalah database NoSQL yang didesain untuk beban kerja analitik dan operasi. Sistem basis data ini adalah hibrid lintas platform yang menggunakan Hadoop daripada HBase, yang menggunakan basis data kolumnar. Cloud bigtable dapat digunakan untuk mendukung aplikasi dengan throughput dan skalabilitas tinggi, dengan kapasitas kurang dari 10 MB.
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable, dan Microsoft Azure CosmosDB adalah contoh penyimpanan kolom lebar.
Tabel tidak sama dengan database relasional dalam hal penyimpanan kunci/nilai. Transaksi hanya dapat dilakukan satu kali, dan bergabung tidak didukung.
Apakah Google Bigtable Database Nosql?
Google Bigtable adalah database NoSQL yang dirancang untuk menyimpan dan mengelola data dalam jumlah besar. Bigtable adalah basis data berorientasi kolom, yang berarti bahwa data diatur ke dalam kolom, bukan baris. Ini membuatnya sangat cocok untuk menyimpan data yang terus berubah, seperti log web atau data media sosial. Bigtable juga sangat skalabel, artinya dapat dengan mudah menangani data dalam jumlah besar.
Basis data NoSQL ini dapat menyimpan berbagai tipe data dan sangat stabil. Itu juga menangani sharding dan replikasi, memastikan bahwa database sangat tersedia dan dapat diandalkan. Banyak aplikasi Google yang menggunakannya, antara lain Google Analytics, web indexing, MapReduce, dan Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code Hosting, dan aplikasi Google For yang membutuhkan database yang mampu menangani jumlah item data, Datastore adalah pilihan yang bagus.
Dalam Urutan Mana Data Disimpan Dalam Bigtable?
Tidak ada urutan khusus di mana data disimpan dalam bigtable. Data disimpan dalam urutan acak, sehingga sulit untuk mengakses data tertentu.
Bigtable Google: Bukan Hanya Untuk Menyimpan Data
Data tidak dapat ditempatkan dalam urutan tertentu dalam igtable. Karena Bigtable adalah basis data berorientasi baris, semua data dalam satu baris diatur dalam kolom, diikuti oleh kolom. Karena data disimpan dalam urutan kronologis terbalik, mudah dan cepat untuk meminta nilai terbaru, tetapi sulit dan memakan waktu untuk meminta yang terlama.
Data Anda disimpan di Colossus, sistem file internal Google yang tahan lama, yang ditempatkan di dalam pusat data Google, sebagai hasil dari penggunaan Colossus oleh Bigtable. Bigtable gratis untuk digunakan, dan Anda tidak perlu menggunakan cluster HDFS atau sistem file lainnya.
Kueri ke sumber data eksternal dapat dilakukan tanpa membuat tabel permanen dengan perintah gabungan: File definisi tabel dengan kueri. Ada definisi skema sebaris serta kueri. File definisi skema JSON dengan kueri.
Bigtable Vs Datastore
Ada beberapa perbedaan utama antara Bigtable dan Datastore. Pertama, Bigtable adalah penyimpanan data berorientasi kolom, sedangkan Datastore berorientasi baris. Ini berarti bahwa di Bigtable, data diatur ke dalam kolom, sedangkan di Datastore diatur ke dalam baris. Kedua, Bigtable tidak memiliki konsep transaksi, sedangkan Datastore memilikinya. Artinya, di Bigtable, Anda tidak dapat mengembalikan perubahan ke status sebelumnya, sedangkan di Datastore Anda bisa. Terakhir, Bigtable dirancang untuk throughput tinggi dan latensi rendah, sedangkan Datastore dirancang untuk ketersediaan dan skalabilitas tinggi.
Penyimpanan data awan mana yang dapat digunakan untuk membangun basis data awan Google? Karena Bigtable mendukung beban kerja besar dengan beban kerja ujung belakang yang kompleks, Bigtable ditujukan untuk organisasi dan perusahaan yang lebih besar. Berbeda dengan SQL, yang menggunakan bahasa kueri GQL yang lebih ketat, penyimpanan data melakukan transaksi ACID pada subset data yang dikenal sebagai grup entitas (meskipun bahasa kueri GQL jauh lebih terbuka). Google Cloud Datastore dan Google Cloud Bigtable adalah dua layanan berbeda yang memiliki sejumlah fitur berbeda. Selain itu, informasi pada gambar di bawah ini dapat membantu Anda dalam memilih penyedia layanan yang sesuai untuk Anda. Jawaban di atas, serta apa yang dibahas dalam buku teks Coursea Google Cloud Platform Big Data dan Machine Learning Fundamentals, akan menjadi panduan saya untuk artikel ini.
Apa Perbedaan Antara Bigtable Dan Datastore?
Apa perbedaan antara datastore dan database? Bigtable dan datastore masing-masing dirancang untuk pemrosesan dan analitik data bervolume tinggi, sedangkan datastore dirancang untuk data transaksi bernilai tinggi. Datastore juga dikenal sebagai database NoSQL karena tidak mematuhi standar SQL tradisional, memungkinkannya menyimpan data dengan cara yang lebih fleksibel dan dapat diskalakan. Jenis datastore apa itu Google Bigtable? Model penyimpanan Bigtable menyimpan data dalam tabel yang dapat diskalakan secara besar-besaran yang diurutkan berdasarkan peta kunci dan nilai. Sebuah tabel terdiri dari baris, yang masing-masing menggambarkan satu entitas, dan kolom, masing-masing dengan nilainya sendiri. Apakah datastore sudah usang? Karena Cloud Datastore API v1beta3 telah dirilis, maka tidak tersedia lagi. Meskipun demikian, produk Cloud Datastore berfungsi penuh dan didukung.
Database Besar
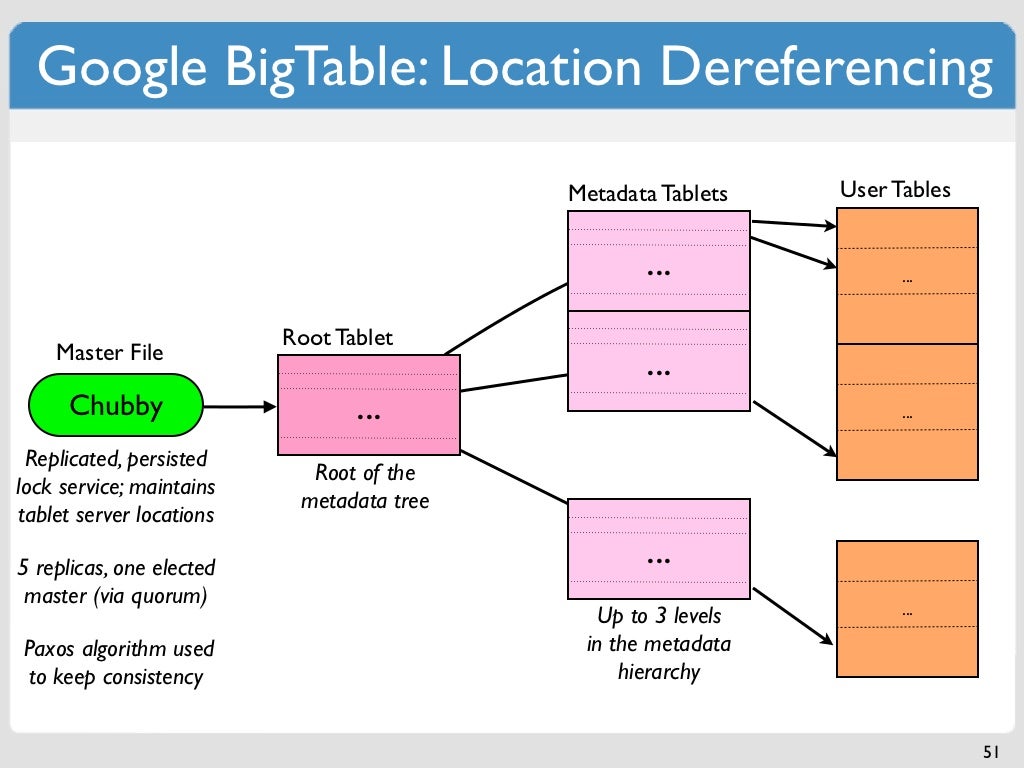
Bigtable adalah sistem penyimpanan terdistribusi untuk mengelola data terstruktur yang dirancang untuk skala ke ukuran yang sangat besar: petabyte data di ribuan server komoditas. Bigtable adalah basis data berorientasi kolom, yang berarti data disimpan berdasarkan kolom, bukan baris.
Tabel adalah struktur yang jarang dan padat penduduk dengan baris dan kolom yang dapat mencapai miliaran baris. Bigtable adalah pilihan yang sangat baik untuk menyimpan data dalam jumlah besar dengan latensi rendah. Karena mendukung throughput baca dan tulis yang tinggi pada latensi rendah, ini merupakan sumber data yang cocok untuk operasi MapReduce. Saat menggunakan tabel Bigtable, itu dipartisi menjadi blok-blok baris yang berdekatan yang dikenal sebagai tablet untuk memudahkan kueri. Dalam sistem file bernama Colossus, yang digunakan Google, tablet disimpan dalam format SSTable. Node Bigtable adalah subset dari setiap tablet, yang merupakan bagian dari instance Bigtable. Menambahkan node ke cluster dapat meningkatkan jumlah permintaan bersamaan yang dapat ditanganinya.

Baris berisi satu set entri kunci atau nilai, yang merupakan kombinasi dari keluarga kolom, stempel waktu kolom, dan kunci. Bigtable memperlakukan semua data dengan cara yang sama: sebagai string byte mentah. Karena Bigtable menyimpan mutasi secara berurutan dan memadatkannya secara teratur, jumlah mutasi yang dapat disimpan pada waktu tertentu memerlukan lebih banyak ruang penyimpanan. Bigtable memampatkan data Anda dengan menggunakan algoritme canggih yang otomatis. Karena penghapusan sebenarnya adalah jenis mutasi baru, penghapusan membutuhkan lebih banyak ruang penyimpanan dalam jangka pendek. Metode penyimpanan milik Google memungkinkannya mencapai daya tahan data yang melebihi yang dicapai oleh replikasi tiga arah HDFS standar. Selain mengelola akses ke tabel Bigtable, Anda dapat mengelola akses ke layanan Google Cloud lainnya dengan menetapkan peran kepada pengguna di bagian Identity and Access Management (IAM) project Google Cloud Anda. Menurut kebijakan enkripsi default Google Cloud, semua data di cloud dienkripsi saat tidak aktif menggunakan sistem pengelolaan kunci yang diperkeras yang sama dengan yang kami gunakan untuk data terenkripsi kami. Dengan menggunakan cadangan, Anda dapat menyimpan salinan skema dan data tabel, lalu memulihkan salinan data tersebut ke tabel baru di masa mendatang.
Meja Besar Vs Cassandra
Cassandra dan Bigtable menggunakan metode berbeda untuk menentukan node pemrosesan mana yang harus melakukan operasi baca dan tulis. Di Cassandra, kunci partisi disebut sebagai kunci, sedangkan di Bigtable, kunci baris disebut sebagai kunci. Kebijakan load balancing untuk Cassandra harus ditinjau oleh klien sebagai bagian dari proses.
Basis data terdistribusi adalah basis data yang digunakan bersama oleh beberapa orang. Perusahaan ini menggabungkan penyimpanan nilai kunci multidimensi dalam sistemnya, memungkinkannya memproses puluhan ribu kueri per detik (QPS). Tujuan dari dokumen ini adalah untuk membandingkan dan membedakan dua sistem basis data. Fitur utama Bigtable meliputi: Sistem Penyimpanan Terdistribusi untuk kertas Data Terstruktur telah dibuat. Jika Bigtable menentukan bahwa penyeimbangan ulang rentang diperlukan untuk kumpulan data, node pemrosesan dapat dengan mudah mengubah rentang data karena lapisan penyimpanan terpisah dari lapisan pemrosesan. Bigtable juga dapat digunakan untuk mendukung replikasi asinkron di seluruh cluster yang terdistribusi secara geografis hingga empat cluster dalam topologi. Toleransi kesalahan Cassandra terkait dengan tingkat konsistensi merdunya.
Dengan mengonfigurasi strategi topologi replikasi data, Anda dapat menentukan replikasi geografis. Secara umum, pengaturan aQUORUM (atau LOCAL_QUORUM di beberapa pusat data) digunakan. Agar dianggap berhasil, pengaturan tingkat konsistensi operasi harus dipenuhi dengan simpul replika yang sebagian besar merespons simpul koordinator. Menggunakan pusat data dan konfigurasi rak, replika Cassandra mampu menahan lebih banyak tekanan jika dibandingkan dengan replika tradisional. Saat melakukan operasi baca dan tulis, topologi menentukan node mana yang diperlukan untuk menjamin konsistensi. Instance Bigtable dapat berisi satu kluster atau grup hingga empat replika besar. Bigtable dan Cassandra adalah penyimpanan data NoSQL yang merupakan penyimpanan kolom lebar.
Kunci baris Bigtable digunakan untuk mengurutkan data global dalam tabel berdasarkan pesanan. Node Bigtable secara otomatis menyeimbangkan tanggung jawab nodal untuk rentang kunci, juga dikenal sebagai tablet, sebagai bagian dari fitur Node Bigtable. Layanan Bigtable klien tidak menerapkan jenis data kolom yang dikirimkannya. Di Bigtable, setiap kolom dalam tabel diberi nama keluarga. Terlepas dari kenyataan bahwa tabel sering memiliki lebih banyak keluarga kolom (jumlah maksimum kolom per tabel adalah 100), setiap tabel membutuhkan setidaknya satu keluarga kolom. Persimpangan kunci baris terdiri dari dua sel (keluarga kolom digabungkan dengan kualifikasi kolom). Di Cassandra dan Bigtable, ada metode untuk memilih node pemrosesan untuk operasi baca dan tulis.
Di Cassandra, kunci partisi diidentifikasi, sedangkan di Bigtable, kunci baris digunakan. Kebijakan load balancing yang memperhatikan pusat data, seperti kebijakan multi-cluster, memberikan potensi failover. Kedua database menggunakan metode serupa untuk menyelesaikan penulisan dan telah dioptimalkan untuk kecepatan. Data disimpan dalam dua database melalui file SSTable yang tidak dapat diubah. Di Cassandra, koordinator harus memberi tahu klien bahwa penulisan telah selesai sebelum beberapa replika merespons. Penulisan yang sukses di Bigtable hanya dapat dikonfirmasi oleh respons dari satu node, karena setiap kunci baris hanya ditetapkan ke satu node. Sel di salah satu database mungkin tidak disertakan dalam SSTable yang digabungkan.
Karena klausa WHERE dalam kueri CQL, tidak mungkin mengembalikan lebih dari satu baris di Cassandra. Hanya node yang bertanggung jawab atas rentang kunci yang perlu dikonsultasikan di Bigtable. Di node pemrosesan, dimungkinkan untuk membatasi jumlah data yang dapat dibaca. Selama fase pemadatan, SSTables digabungkan secara teratur, dan data disimpan di Bigtable dan Cassandra disimpan di dalamnya. Tidak ada aturan yang mengatur jumlah versi stempel waktu untuk setiap sel, tetapi mungkin ada batas ukuran baris lainnya. Jaminan daya tahan data disediakan oleh sistem replikasi Colossus. Bigtable, seperti Cassandra, memiliki antarmuka baris perintah dan pustaka klien untuk banyak bahasa pemrograman umum.
Setiap node diberi SSTable di Bigtable, dan data yang disimpan di dalamnya dilayani oleh node tersebut. Saat mengukur klaster Cassandra, Anda tidak perlu memperhitungkan replika penyimpanan seperti yang Anda lakukan dengan Bigtable. Solid-state drive (SSD) atau hard disk drive (HDD) adalah jenis penyimpanan yang paling umum digunakan untuk instans Bigtable . Seperti yang ditunjukkan oleh Cassandra, tidak ada kehilangan kepadatan penyimpanan untuk mencapai toleransi kesalahan. Anda dapat menskalakan instans Bigtable untuk memenuhi persyaratan beban kerja dengan upaya minimal dan waktu nonaktif minimal. Meskipun hanya ada empat klaster, setiap klaster dapat dibuat di semua wilayah cloud yang didukung di seluruh dunia. Google merekomendasikan agar Anda menguji performa Bigtable dengan data dan kueri representatif untuk menghasilkan metrik QPS per node.
Cassandra melakukan sejumlah besar fungsi administrasi menggunakan komponen terkelola Bigtable. Cadangan tabel besar membuat salinan tabel yang dapat dipulihkan, yang disimpan sebagai objek di kluster. Pencadangan menghabiskan lebih sedikit sumber daya node dan lebih murah daripada penyimpanan cloud. Metode lain untuk mencadangkan Bigtable adalah menggunakan ekspor data terkelola ke Cloud Storage. Tugas pemeliharaan internal seperti penambalan OS, pemulihan node, perbaikan node, pemantauan pemadatan penyimpanan, dan rotasi sertifikat SSL semuanya ditangani dengan mulus oleh layanan Bigtable. Dasbor tersedia untuk memantau throughput dan metrik penggunaan pada tingkat instance, cluster, dan tabel di halaman Bigtable Google Cloud Console . Anda dapat menggunakan dasbor pemantauan untuk melakukan penyetelan kinerja tingkat lanjut.
Makalah Bigtable menjelaskan sistem penyimpanan data yang mendukung skala besar-besaran. Setiap tabel dalam data dibagi menjadi beberapa partisi. Anda dapat mengkueri tabel dengan menggunakan kunci baris atau dengan menggunakan rentang kunci baris. Makalah Bigtable juga menjelaskan metode untuk mendistribusikan pekerjaan tabel di sekelompok node. Apache Cassandra, database sumber terbuka, didasarkan pada beberapa konsep dari makalah Bigtable. Pusat data menggunakan arsitektur node terdistribusi, di mana penyimpanan dibagi antara server yang melayani data. Akses ke sistem penyimpanan data Bigtable disediakan dengan menggunakan antarmuka baris perintah cbt dan pustaka klien. Bigtable menyertakan sejumlah bahasa pemrograman selain Python, membuatnya mudah untuk diintegrasikan dengan aplikasi.
Datastax Astra Cassandra Google Sebagai Layanan: Mudah Diterapkan dan Diskalakan
DataStax Astra Cassandra as a Service Google adalah pilihan yang sangat baik untuk belajar tentang Cassandra. Antarmuka pengguna Operator Kubernetes memudahkan untuk mengonfigurasi, mengelola, dan menskalakan penerapan Cassandra Anda.
Dokumentasi Bigtable
Dokumentasi Bigtable adalah sumber yang bagus untuk mempelajari tentang alat canggih ini. Ini memberikan ikhtisar tentang fitur dan kemampuan Bigtable, serta informasi mendetail tentang cara menggunakannya. Dokumentasinya diatur dengan baik dan mudah diikuti, menjadikannya sumber yang berharga bagi siapa pun yang tertarik mempelajari alat canggih ini.
Google Cloud Platform bertanggung jawab untuk menghosting basis data Bigtable Google . Sangat mudah untuk menggunakan OpenTSDB 2.1 dan yang lebih baru bila digunakan bersamaan dengan backend Google. Yang harus Anda lakukan adalah membuat instance Bigtable, menyiapkan tabel TSDB Anda menggunakan shell Bigtable HBase, dan memulai TSD. Klien Bigtable saat ini dalam versi beta dan mengalami berbagai perubahan.
Tata Letak Data Bigtable yang Efisien
Bigtable juga cocok untuk operasi MapReduce. Karena tata letak datanya yang efisien, MapReduce dapat menangani volume data yang besar dalam waktu singkat.