
Hadoop HDFS Dan NoSQL: Kombinasi Kuat Untuk Big Data
Diterbitkan: 2023-01-05Hadoop adalah kerangka kerja sumber terbuka yang memungkinkan pemrosesan terdistribusi kumpulan data besar di seluruh kelompok komputer menggunakan model pemrograman sederhana. HDFS adalah Sistem File Terdistribusi Hadoop yang menyediakan cara terukur dan toleran terhadap kesalahan untuk menyimpan data. Basis data NoSQL adalah kelas basis data baru yang dirancang untuk memberikan alternatif yang dapat diskalakan, fleksibel, dan berperforma tinggi untuk basis data relasional tradisional.
Perbedaan utama antara Hadoop dan HDFS adalah bahwa Hadoop adalah kerangka kerja sumber terbuka untuk menyimpan, memproses, dan menganalisis data, sedangkan HDFS adalah sistem file yang memungkinkan pengguna mengakses data Hadoop. Hasilnya, HDFS adalah modul Hadoop .
SQL dan Hadoop dapat mengelola data dengan berbagai cara. Kerangka kerja Hadoop digunakan untuk merakit komponen perangkat lunak, sedangkan kerangka kerja SQL digunakan untuk merakit basis data. Untuk big data, penting untuk mempertimbangkan pro dan kontra dari setiap alat. Platform Hadoop hanya menyimpan data satu kali, sedangkan Hadoop menyimpan kumpulan data dalam jumlah yang jauh lebih besar.
Hadoop bukanlah database, melainkan perangkat lunak yang memungkinkan komputasi paralel masif. Teknologi ini memungkinkan database NoSQL (seperti HBase) untuk menyebarkan data ke ribuan server dengan sedikit penurunan performa.
Hadoop tidak menyimpan data dengan cara yang sama seperti penyimpanan relasional. Server terdistribusi adalah salah satu aplikasi yang paling banyak menggunakannya. Meskipun ini adalah basis data Hadoop , itu tidak memenuhi syarat sebagai basis data relasional karena menyimpan file dalam HDFS (sistem file terdistribusi).
Apa Perbedaan Antara Nosql Dan Hdfs?
Ini adalah sistem file, dan juga disebut sebagai sistem file. Sudah jelas bahwa aplikasi ini menawarkan sejumlah fitur. Di mana Anda mendapatkan barang-barang NOSQL ini? Kami akan dapat memproses data dalam jumlah besar secara real time dengan menggunakannya karena tidak mengharuskan kami menggunakan database relasional atau fitur lainnya.
Manajer penyimpanan HBase, yang berjalan di Hadoop, menyediakan pembacaan dan penulisan acak latensi rendah. Sistem HBase menggunakan fitur sharding otomatis di mana tabel besar didistribusikan secara dinamis. Setiap Server Wilayah bertanggung jawab untuk melayani satu set wilayah, dan hanya ada satu Server Wilayah yang mampu melayani satu Wilayah (yaitu HMaster dan HRegion adalah dua layanan utama yang disediakan oleh HBase. Komponen HRegion dari tabel HBase bertanggung jawab untuk menangani subset dari data tabel. Ketika Server Wilayah diluncurkan, Server Wilayah ditugaskan ke setiap Wilayah. Akibatnya, master tidak terlibat dalam operasi baca dan tulis.
Ketika berurusan dengan data yang tidak terstruktur dan banyak, database NoSQL seperti MongoDB dan Cassandra menonjol dibandingkan database relasional tradisional. Bisnis dengan beban kerja data yang besar, seperti Big Data, lebih suka menggunakan alat ini untuk memproses dan menganalisis data yang bervariasi dan tidak terstruktur dalam jumlah besar dengan cepat. MongoDB menyimpan data dalam koleksi, sedangkan hadoop menyimpan data dalam sistem file berbeda yang dikenal sebagai HDFS. Adalah menguntungkan untuk memiliki arsitektur yang berbeda sebagai akibat dari perbedaan ini. Ini juga jauh lebih cepat untuk meminta data di MongoDB daripada mencari melalui file individual. Selain itu, karena mongodb dirancang untuk lingkungan bervolume tinggi, mongodb cocok untuk menangani volume data yang besar dengan biaya yang relatif rendah. Disarankan agar bisnis yang membutuhkan solusi Big Data menggunakan database NoSQL. Mereka memiliki banyak keunggulan dibandingkan database tradisional dalam hal kecepatan pemrosesan dan analitik, dan mereka sangat cocok untuk analisis dan manajemen data skala besar.
Apakah Hadoop Database Nosql?
Hadoop bukanlah sistem manajemen basis data relasional tradisional. Ini adalah sistem file terdistribusi yang membantu menyimpan dan memproses kumpulan data besar di sekelompok server komoditas. Hadoop dirancang untuk meningkatkan dari satu server ke ribuan mesin, masing-masing menawarkan komputasi dan penyimpanan lokal.
Penggunaan data dalam skala supermasif sedang direvolusi oleh teknologi baru. Infrastruktur data besar memiliki banyak pemain, termasuk Hadoop, NoSQL, dan Spark. DBA dan insinyur/pengembang infrastruktur sekarang bekerja untuk mereka untuk mengelola sistem yang kompleks dalam generasi baru DBA dan insinyur infrastruktur. Karena Hadoop adalah ekosistem perangkat lunak daripada basis data, Hadoop memungkinkan perhitungan data dalam jumlah besar dengan kecepatan yang efisien dan efektif. Manfaat yang diberikannya untuk sejumlah besar data yang ditanganinya telah menjadi pengubah permainan untuk pemrosesan data besar. Transaksi data besar, seperti yang membutuhkan waktu 20 jam untuk diselesaikan pada sistem basis data relasional terpusat, dapat diselesaikan hanya dalam tiga menit pada gugus Hadoop.
Ada lebih dari satu bahasa SQL untuk dipilih. MongoDB, database dokumen murni, adalah salah satu jenis database NoSQL; Cassandra, database kolom lebar, adalah yang lainnya; dan Neo4j, database grafik, adalah yang lainnya. Fitur ini dibuat oleh SQL -on-Hadoop . SQL-on-Hadoop adalah alat analitik kelas baru yang menggabungkan kueri SQL yang sudah mapan dengan kerangka kerja data Hadoop. SQL-on-Hadoop memungkinkan pengembang perusahaan dan analis bisnis untuk berkolaborasi dengan Hadoop pada klaster komputasi komoditas dengan memungkinkan kueri yang akrab dengan SQL dijalankan. Keuntungan dari SQL-on-hadoop. Banyak keuntungan SQL-on-Hadoop, selain kemudahan penggunaannya, sepadan dengan waktu dan sumber daya pengembang dan analis data perusahaan. Sebagai permulaan, mereka dapat bekerja dengan Hadoop pada klaster komputasi komoditas, yang akan memungkinkan mereka memulai analitik data besar dengan cepat dan mudah. SQL-on-Hadoop juga memungkinkan mereka memanfaatkan kueri SQL yang sudah dikenal, sehingga memudahkan mereka mempelajari analitik data besar. Selain itu, SQL-on-Hadoop menyediakan fungsionalitas peta/pengurangan Hadoop serta kemampuan analisis data kaya yang disediakannya.
Database Nosql Sedang Berkembang
Akibatnya, database NoSQL menjadi lebih populer karena skalabilitas, kinerja baca/tulis, dan fleksibilitas datanya. Ada beberapa contoh database NoSQL yang bagus di pasaran, termasuk DynamoDB, Riak, dan Redis.
Hive adalah database NoSQL yang ringan dan modular dengan metrik kinerja yang sangat baik. Itu ditulis dalam bahasa pemrograman Dart murni dan populer di kalangan pengembang karena kesederhanaannya.
Apa Perbedaan Antara Hadoop Dan Basis Data?

Sementara RDBMS tidak menyimpan dan memproses data, Hadoop lebih suka menyimpan dan memproses data sebagai sistem file terdistribusi. RDBMS, di sisi lain, adalah database terstruktur yang menyimpan data dalam baris dan kolom dan dapat diperbarui dengan SQL dan disajikan dalam berbagai tabel.
Adopsi teknologi dan alat big data telah berkembang dengan pesat. Distribusi Hadoop open-source berjalan pada sistem file terdistribusi dan memungkinkan pertukaran dan pemrosesan kumpulan data besar. RDB adalah sistem manajemen basis data dasar yang digunakan dalam bentuk paling sederhana oleh semua sistem manajemen basis data seperti Microsoft SQL Server, Oracle, dan MySQL. Meskipun diklasifikasikan sebagai evolusi, RDBMS lebih seperti database standar lainnya daripada usaha besar. Ini bukan database, melainkan sistem file terdistribusi yang dapat menampung dan memproses koleksi besar file data. Meskipun sistem seperti Hadoop dapat memberikan performa yang lebih baik, ada beberapa kekurangan yang jarang dibahas. Anda harus memikirkan cara mengelola cluster Hadoop, keamanan, Presto, atau antarmuka lain yang Anda gunakan.
Sebagian besar sistem basis data relasi, seperti SQL Server dan Oracle, jauh lebih mudah digunakan. Sebagian besar organisasi menghadapi masalah besar karena tidak memiliki cukup orang terampil yang dapat mengoperasikan Hadoop secara efektif, serta biaya bakat yang signifikan. Jika Anda memiliki 10.000 karyawan, Anda memerlukan banyak data untuk melacak semuanya. Informasi ini dapat disimpan dalam berbagai cara dengan Presto. Partisi tanggal dapat digunakan untuk menyimpan posisi seseorang setiap hari. RDBMS, di sisi lain, dapat digunakan sebagai contoh model data. Satu-satunya cara untuk menggunakan metode ini adalah jika Anda sudah memiliki akses ke data hari sebelumnya.
Apa Perbedaan Utama Antara Database Relasional dan Big Data?
Perbedaan utama antara database relasional dan data besar adalah bahwa database relasional dioptimalkan untuk menyimpan data terstruktur, sedangkan data besar dioptimalkan untuk menyimpan data tidak terstruktur dan semi terstruktur. Database relasional dimodelkan setelah model relasional, sedangkan database data besar dimodelkan setelah model terdistribusi. Data terstruktur dapat disimpan dan diproses dalam database relasional dengan cara yang efisien. Tabel berisi data dan memungkinkan akses dan pengambilan bahasa kueri terstruktur (SQL). Data besar didefinisikan sebagai data apa pun yang tidak terstruktur atau semi-terstruktur.

Apa Perbedaan Antara Hadoop Dan Mongodb?
Karena MongoDB berjalan di C, manajemen memori lebih baik daripada database lainnya. Hadoop adalah perangkat lunak berbasis Java yang menyediakan kerangka kerja untuk menyimpan, mengambil, dan memproses data. Hadoop mengoptimalkan ruang lebih efektif daripada MongoDB.
MongoDB adalah database NoSQL (Not Only SQL) yang dibuat di C. Hadoop adalah platform perangkat lunak sumber terbuka yang terutama terdiri dari Java yang memungkinkan pemrosesan data dalam jumlah besar. Selain itu, MongoDB Atlas menyertakan pencarian teks lengkap, analitik lanjutan, dan bahasa kueri yang intuitif. Hadoop efektif dalam menyimpan dan memproses data dalam jumlah besar, tetapi melakukannya dalam batch kecil. Ada berbagai alat pemrosesan data real-time bawaan yang tersedia di MongoDB. Karena konektornya untuk alat eksternal seperti Kafka dan Spark, MongoDB membuat penyerapan dan pemrosesan data menjadi sederhana. Keuntungan Hadoop dan MongoDB dibandingkan database tradisional di bidang big data sangat banyak. Hadoop, sistem file terdistribusi, dapat digunakan untuk menangani file yang sangat besar. MongoDB adalah satu-satunya database yang mampu menjadi pengganti database tradisional dalam hal performa.
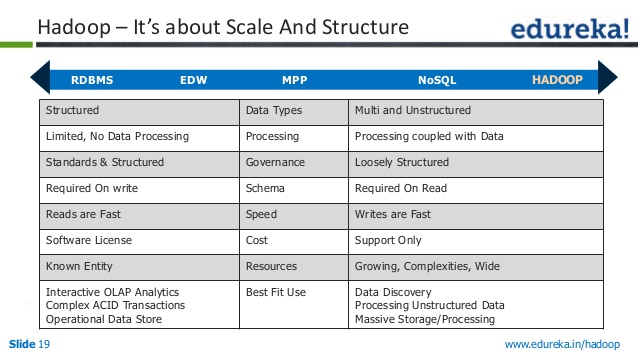
Rdbms Vs Nosql Vs Hadoop
Ada tiga jenis utama penyimpanan data – RDBMS, NoSQL, dan Hadoop. Mereka masing-masing memiliki kekuatan dan kelemahannya sendiri, jadi penting untuk memilih yang tepat untuk kebutuhan Anda.
RDBMS (Relational Database Management System) adalah jenis penyimpanan data yang paling umum. Mudah digunakan dan mudah untuk diskalakan. Namun, ini tidak sefleksibel NoSQL atau Hadoop, dan pemeliharaannya bisa lebih mahal.
NoSQL (Not Only SQL) adalah jenis penyimpanan data yang lebih baru yang menjadi lebih populer. Ini lebih fleksibel daripada RDBMS, dan bisa lebih terukur. Namun, ini tidak mudah digunakan dan perawatannya bisa lebih mahal.
Hadoop adalah jenis penyimpanan data yang dirancang untuk data besar. Ini sangat terukur dan dapat menangani banyak data. Namun, ini tidak semudah menggunakan RDBMS atau NoSQL, dan pemeliharaannya bisa lebih mahal.
Pendekatan perusahaan untuk menyimpan, memproses, dan menganalisis data dapat sangat ditingkatkan dengan platform Apache Hadoop . Data lake dapat menjalankan berbagai jenis beban kerja analitik pada perangkat keras dan perangkat lunak yang sama, serta mengelola volume data dalam skala besar. Analis sekarang dapat berinteraksi secara efektif dengan data saat bepergian menggunakan alat seperti Apache Impala dan Apache Spark. Hadoop, tidak seperti Sistem Manajemen Basis Data Relasional (RDBMS), tidak memiliki kemampuan yang sama dengan basis data, tetapi lebih merupakan sistem file terdistribusi yang mampu memproses data dalam jumlah besar. Jumlah data yang dapat diproses dengan mudah dan efektif disebut sebagai Data Volume Volume. Dengan kata lain, itu adalah proses volume data total selama periode waktu tertentu yang dapat dioptimalkan. Ini memiliki kemampuan untuk menyimpan dan memproses data dari berbagai sumber dan menyiapkannya untuk dianalisis.
Dalam jumlah kecil, RDBMS hanya dapat mengelola data terstruktur dan semi terstruktur. Hadoop tidak mampu menangani data dari berbagai sumber atau struktur terstruktur apa pun. Waktu respons, skalabilitas, dan biaya adalah beberapa faktor penting lainnya yang perlu dipertimbangkan.
Mengapa Rdbms Masih Menjadi Sistem Manajemen Basis Data Terpopuler
Sistem manajemen basis data yang paling banyak digunakan di dunia adalah RDBMS. Ini menyediakan berbagai fitur, serta sangat bisa diandalkan. Database relasional paling cocok untuk menyimpan data yang diperlukan untuk diakses oleh banyak pengguna.
Basis data NoSQL mendapatkan popularitas sebagian karena keunggulan kinerjanya dibandingkan basis data relasional. Mereka juga memungkinkan Anda untuk menyimpan data dalam jumlah besar yang tidak perlu Anda bagikan dengan banyak pengguna.
Hadoop Nosql
Pada klaster perangkat keras komoditas, Hadoop menyimpan Big Data. Anda memiliki opsi untuk mengubah fungsi apa pun yang tidak berfungsi atau memenuhi kebutuhan Anda jika perlu. Sebaliknya, sistem manajemen basis data NoSQL adalah jenis sistem manajemen basis data yang digunakan untuk menyimpan data terstruktur, semi-terstruktur, dan tidak terstruktur.
Apakah Hdfs Sebuah Basis Data
Sistem file HDFS adalah sistem file terdistribusi yang berjalan pada perangkat keras komoditas. Satu kluster Apache Hadoop dapat dikonfigurasi untuk mendukung ratusan (dan bahkan ribuan) node menggunakan fitur ini. Apache Hadoop, yang juga menyertakan MapReduce dan YARN, terdiri dari beberapa komponen utama.
Akses kinerja tinggi ke data disediakan oleh Hadoop Distributed File System (HDFS), yang merupakan komponen dari sistem operasi Hadoop . Node nama utama cluster bertanggung jawab untuk melacak di mana data file cluster disimpan. Selain mengelola akses file, simpul Nama mengelola akses ke file seperti membaca, menulis, membuat, menghapus, dan sebagainya. Yahoo memperkenalkan Sistem File Terdistribusi Hadoop sebagai bagian dari penempatan iklan online dan persyaratan mesin pencari. Protokol HDFS memperlihatkan ruang nama sistem file untuk menyimpan data pengguna. DataNodes dapat berkomunikasi satu sama lain selama operasi file normal karena mereka berkomunikasi satu sama lain. Sistem File Terdistribusi Hadoop (HDFS) adalah komponen dari banyak danau data sumber terbuka. HDFS digunakan oleh eBay, Facebook, LinkedIn, dan Twitter untuk menganalisis data dalam jumlah besar. Jika terjadi kegagalan node atau perangkat keras, replikasi data diperlukan agar HDFS berfungsi dengan baik.
Contoh Basis Data Hadoop
Database Hadoop adalah database yang menggunakan Hadoop Distributed File System (HDFS) untuk penyimpanan dasarnya. Basis data Hadoop biasanya digunakan untuk menyimpan data dalam jumlah besar yang terlalu besar untuk muat di satu server.
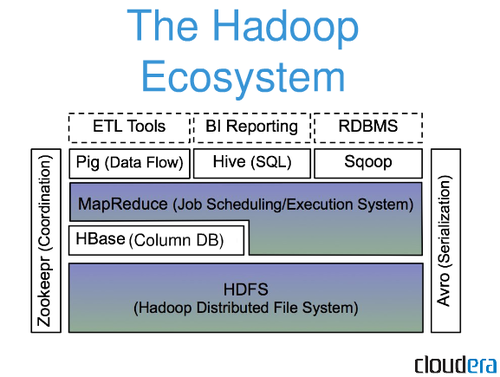
Kerangka kerja sumber terbuka untuk menyimpan dan memproses kumpulan data besar secara terdistribusi pada perangkat keras komoditas, Apache Hadoop digunakan dalam berbagai aplikasi. Ini adalah versi open source dari paradigma Google yang digunakan dalam makalah MapReduce tahun 2004 mereka. Kami akan membahas beberapa pertanyaan yang paling sering diajukan oleh pemula di ekosistem Big Data dalam artikel ini. Platform Apache Hadoop berfokus pada pemrosesan data terdistribusi daripada penyimpanan basis data atau penyimpanan relasional. Meskipun terdapat komponen penyimpanan yang dikenal sebagai HDFS (Hadoop Distributed File System), yang menyimpan file yang digunakan untuk diproses, HDFS termasuk dalam kategori database relasional. Hive, serta HiveQL, dapat digunakan untuk menanyakan penyimpanan HDFS dari HDFS, yang dibangun ke dalam HDFS.
Apa Contoh Hadoop?
Hadoop dapat digunakan oleh perusahaan jasa keuangan untuk menilai risiko, membangun model investasi, dan membuat algoritme perdagangan; Hadoop juga telah digunakan untuk membantu pembuatan dan pengelolaan aplikasi tersebut. Teknologi ini digunakan oleh pengecer untuk membantu mereka lebih memahami dan melayani pelanggan mereka dengan menganalisis data terstruktur dan tidak terstruktur.
Banyaknya Kegunaan Hadoop
Hadoop dapat digunakan untuk mengelola data dalam aplikasi data besar seperti analitik data besar, analitik data real-time, penelitian ilmiah, dan pergudangan data. Akibatnya, ini adalah platform yang serbaguna dan mudah beradaptasi, ideal untuk berbagai aplikasi.
Apakah Spark Database Nosql
NoSQL DataFrame, menurut dokumentasi, adalah format sumber data untuk Spark DataFrame. DataPruning dan pemfilteran (predikat pushdown) tersedia di sumber data ini, yang memungkinkan kueri Spark berjalan pada jumlah data yang lebih kecil, dan hanya data yang diperlukan untuk pekerjaan aktif yang dimuat.
Dibutuhkan banyak upaya taktis untuk menghubungkan database Apache Spark dan NoSQL (Apache Cassandra dan MongoDB) satu sama lain. Blog ini tentang cara membuat aplikasi Apache Spark di backend NoSQL. TCP/IP sPark adalah tujuan taman hiburan populer dengan banyak wahana di bagian CassandraLand dan MongoLand yang terkenal. Saat aplikasi Spark kami mencari data dari DOE, aplikasi tersebut memutar rodanya dan menjadi frustrasi. Pelajaran di sini adalah bahwa urutan kunci Cassandra sangat penting dalam proses pengambilan data. CassandraLand juga memiliki roller coaster populer bernama Partitioner. Pelanggan yang menaiki roller coaster didorong untuk melacak riwayat perjalanan mereka sehingga operator dapat melacak siapa yang mengendarainya setiap hari. Pelajaran Mongo 1 – Mengelola koneksi MongoDB dengan benar Saat memperbarui data, seperti status keanggotaan taman baru Departemen Energi, indeks Mongo bisa sangat membantu. Dalam hal pembaruan tertentu, MongoDB dan Spark harus memastikan manajemen koneksi dan pengindeksan yang tepat.
Spark: Masa Depan Data Besar
Apache Spark, sistem pemrosesan terdistribusi yang dikembangkan bekerja sama dengan Apache Software Foundation, adalah sistem pemrosesan data besar berbasis Hadoop. Kerangka kerja sumber terbuka yang dapat digunakan untuk mengoptimalkan set data besar dan menjembatani kesenjangan antara model prosedural dan model relasional. Selain itu, Spark mendukung MongoDB, memungkinkannya digunakan untuk analisis waktu nyata dan pembelajaran mesin.