
Apakah Spark Untuk Nosql
Diterbitkan: 2023-02-05Spark adalah alat yang ampuh untuk bekerja dengan data, terutama kumpulan data besar. Ini dirancang agar cepat dan efisien, dan mendukung berbagai format data, termasuk database NoSQL . Basis data NoSQL menjadi semakin populer, karena cocok untuk menangani data dalam jumlah besar. Spark dapat membantu Anda melakukan kueri dan memanipulasi data NoSQL secara efisien.
Agar bekerja secara efektif, sangat penting untuk mengelola database aplikasi Anda menggunakan Apache Spark dan NoSQL ( Apache Cassandra dan MongoDB). Tujuan dari blog ini adalah untuk memberikan tips untuk mengembangkan aplikasi Apache Spark menggunakan backend NoSQL. Ini adalah taman hiburan, dan TCP/IP sPark memiliki wahana di CassandraLand dan MongoLand. Saat kami mencoba menanyakan data DOE, aplikasi Spark kami mulai berputar sendiri dari porosnya. Pelajarannya di sini adalah saat Anda menanyakan Cassandra, urutan kunci itu penting. CassandraLand juga menawarkan roller coaster Partitioner, yang merupakan salah satu atraksi terpopulernya. Sementara pelanggan menikmati perjalanan roller coaster mereka, operator perjalanan dapat melacak siapa yang telah menaikinya setiap hari dengan menyimpan informasi mereka.
Di pelajaran pertama, kita akan membahas pengelolaan koneksi MongoDB. Saat Anda perlu memperbarui informasi tentang taman, seperti status keanggotaan taman baru Departemen Energi, Anda dapat menggunakan indeks mongo . MongoDB dan Spark harus digunakan untuk memastikan bahwa koneksi Anda dikelola dengan benar, serta indeks dalam kasus tertentu.
Apache Spark adalah sistem pemrosesan terdistribusi populer yang bersifat open-source dan dibuat untuk digunakan dalam beban kerja data yang besar. Fitur ini, selain caching dalam memori dan eksekusi kueri yang dioptimalkan, memungkinkan kueri analitik cepat terhadap data dalam jumlah besar.
Dengan kode yang hampir sama, ini lebih efisien dan serbaguna, memungkinkannya memproses data batch dan real-time secara bersamaan. Akibatnya, alat Big Data lama menjadi semakin usang karena kurangnya fungsi ini.
Apa Jenis Basis Data Spark?
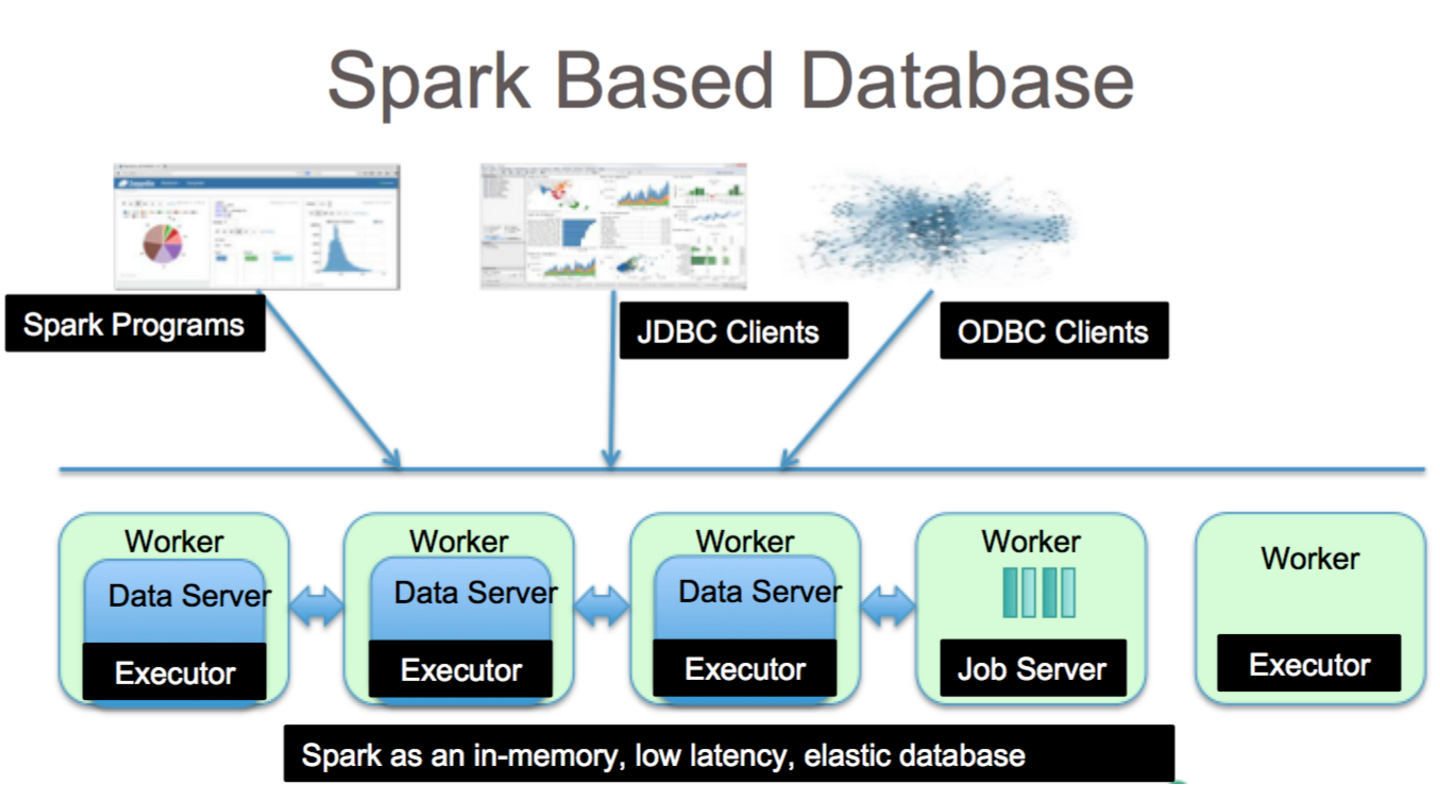
Apache Spark adalah kerangka pemrosesan data yang dapat menangani data dari berbagai repositori data, termasuk (HDFS), database NoSQL, dan database relasional.
Meskipun ada banyak siklus hype untuk database relasional, mereka akan terus menjadi populer, terlepas dari kemajuan terbaru dan kebangkitan database NoSQL. Seiring waktu, semakin sulit untuk menyimpan data dalam basis data relasional. Pada artikel ini, kita akan melihat beberapa kemajuan signifikan dalam memanfaatkan kekuatan database relasional dalam skala global. Saat pertama kali dirilis, antarmuka antara Spark dan Big Data Analysis sangat minim. Banyak orang menulis banyak kode untuk menjalankan program ini, yang hebat tetapi relatif lambat. Pengguna akan dapat menggabungkan kedua model ini di database Spark SQL dengan mudah. Itu juga menerima berbagai format data dari berbagai sumber.
Proyek sumber terbuka Apache Spark adalah yang paling aktif, dengan ratusan kontributor yang berkontribusi padanya. Selain sebagai proyek sumber terbuka gratis, Spark SQL mulai mendapatkan popularitas di industri arus utama. Selain Spark SQL, sekitar dua pertiga pelanggan Databricks Cloud (layanan yang dihosting yang menjalankan Spark) menggunakan bahasa pemrograman lain. Mengikuti kesimpulan dari studi kasus pertama kami, kami akan mendemonstrasikan bagaimana menerapkan databricks ke kasus dalam studi kasus praktis ini. Spark DataFrame adalah sekumpulan baris (tipe baris) yang didistribusikan dengan skema yang sama. Setiap kolom dalam kumpulan data diberi label dengan nama. API DataFrame memungkinkan pengembang untuk mengintegrasikan kode prosedural dan relasional.
Spark juga dapat menangani fungsi lanjutan seperti UDF. Tabel dalam basis data relasional serupa dengan kerangka data dalam basis data kerangka data, tetapi ada lebih banyak pengoptimalan yang terlibat. Mereka dapat dimanipulasi dengan cara yang sama seperti koleksi terdistribusi asli (RDD) Spark. Secara umum, kueri Spark SQL lebih cepat daripada kueri Hiu dan lebih kompetitif dengan Impulsa. Pada Query 3a, dimana selektivitas query menyebabkan salah satu tabel menjadi sangat kecil, terdapat perbedaan yang signifikan antara Impala dan Impala.

Ini adalah alat yang fantastis untuk analisis data dengan Spark SQL. Sintaks HiveQL, Hive SerDes, dan HiveDFs dapat diakses melalui sintaks HiveQL, serta Hive SerDes dan HiveDFs. Hive metastores , SerDes, dan UDFs telah diimplementasikan. Terlepas dari kenyataan bahwa Spark adalah database, itu juga merupakan database NoSQL. Akibatnya, saat Anda membuat tabel terkelola di Spark, Anda akan dapat menggunakan berbagai alat yang sesuai dengan SQL untuk menyimpan data Anda. Ekspresi SQL dapat digunakan untuk mengakses tabel di Spark dengan menghubungkan ke JDBC melalui konektor dari jdbc.org. Hasilnya, Anda juga dapat menggunakan alat pihak ketiga seperti Tableau, Talend, dan Power BI. Kemampuan untuk menggunakan Spark sangat ideal untuk analisis data, dan merupakan alat yang berguna untuk berbagai industri.
Spark Sql: Yang Terbaik Dari Kedua Dunia
Ini menjembatani kesenjangan antara dua model yang disebutkan sebelumnya, model prosedural dan relasional, dengan memasukkan dua komponen utama. Hasilnya, Anda dapat menjalankan operasi relasional skala besar pada sumber data eksternal dan koleksi terdistribusi bawaan Spark dengan menggunakan DataFrame API.
Apa itu percikan dalam basis data? Ini adalah kerangka kerja sumber terbuka yang menggunakan pembelajaran mesin, pemrosesan kueri interaktif, dan beban kerja waktu nyata. Perusahaan ini tidak memiliki sistem penyimpanan sendiri; melainkan menggunakan analitik pada sistem penyimpanan lain seperti HDFS, Amazon Redshift, Amazon S3, Couchbase, dan lain-lain, selain miliknya sendiri. Dalam hal pemrosesan data terstruktur, Spark SQL bukan hanya sebuah database; itu juga modul. Sebagian besar ditulis di DataFrames, yang merupakan abstraksi pemrograman yang bekerja bersama dengan kueri SQL.
Apa jenis SQL sql untuk "sparksql"? Hive SQL mendukung sintaks HiveQL, serta Hive SerDes dan UDF, memungkinkan Anda untuk mengakses gudang Hive yang telah dibuat sebelumnya. Menggunakan metastore Hive, SerDes, dan UDF yang ada di Spark SQL tidaklah sulit.
Bisakah Mongodb Menjalankan Spark?
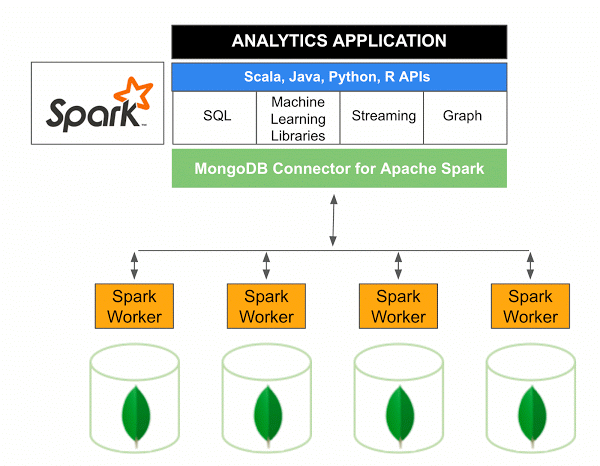
MongoDB Connector untuk Apache Spark versi 10.0 mencakup dukungan untuk Streaming Terstruktur Spark melalui Spark Data Sources API V2 baru serta implementasi Spark Data Sources API V2 baru.
Konektor MongoDB untuk Spark adalah proyek sumber terbuka yang memungkinkan Anda menulis data dari MongoDB dan membacanya dari MongoDB menggunakan Scala. Karena metode utilitas konektor, interaksi antara Spark dan MongoDB disederhanakan, menjadikannya kombinasi yang kuat untuk membuat aplikasi analitis yang canggih. Menggunakan fitur replikasi dan sharding bawaannya, Spark dapat diimplementasikan dalam berbagai beban kerja yang menggunakan database MongoDB .
Spark: Cara Cepat Membangun Aplikasi Kaya Data
Dengan bantuan Spark, alat yang ampuh, Anda dapat dengan cepat mengembangkan aplikasi yang lebih fungsional. Dengan menggabungkan MongoDB, pengembang dapat mempercepat proses pengembangan dengan memanfaatkan teknologi basis data tunggal. Selain itu, Spark adalah cloud-native dan menyertakan dukungan untuk penyimpanan data NoSQL , menjadikannya ideal untuk aplikasi intensif data.