
MapReduce: Model Pemrograman Untuk Kumpulan Data Besar
Diterbitkan: 2023-01-08MapReduce adalah model pemrograman dan implementasi terkait untuk memproses dan menghasilkan kumpulan data besar dengan algoritme terdistribusi paralel pada sebuah cluster.
Kami mengubah cara kami bekerja dengan data dalam jumlah besar menggunakan teknologi baru. Gudang data, seperti Hadoop, NoSQL, dan Spark, adalah beberapa pemain paling menonjol di lapangan. DBA dan insinyur/pengembang infrastruktur adalah generasi baru profesional yang berspesialisasi dalam mengelola sistem dengan tingkat kecanggihan yang tinggi. Alih-alih basis data, Hadoop adalah ekosistem perangkat lunak yang memungkinkan komputasi paralel dalam bentuk file besar. Teknologi ini telah memberikan manfaat yang signifikan dalam hal mendukung kebutuhan pemrosesan big data yang masif. Untuk transaksi data besar, rata-rata klaster Hadoop mungkin hanya membutuhkan waktu tiga menit untuk memproses transaksi besar yang biasanya memakan waktu 20 jam dalam sistem database relasional terpusat.
Cluster mapreduce adalah cluster dengan algoritma paralel dan model pemrograman yang memproses dan menghasilkan kumpulan data besar dengan cara yang sama seperti cluster normal.
Ekosistem Apache Hadoop dirancang untuk mendukung komputasi terdistribusi dan menyediakan lingkungan yang dapat diandalkan, dapat diskalakan, dan siap pakai. Modul MapReduce dari proyek ini adalah model pemrograman yang digunakan untuk memproses kumpulan data besar yang berada di Hadoop (sistem file terdistribusi).
Modul ini adalah komponen ekosistem sumber terbuka Apache Hadoop dan digunakan untuk membuat kueri dan memilih data dalam Sistem File Terdistribusi Hadoop (HDFS). Data dapat dipilih untuk berbagai kueri menggunakan algoritme MapReduce yang tersedia untuk keperluan pembuatan pilihan tersebut.
Menggunakan MapReduce, dimungkinkan untuk menjalankan tugas pemrosesan data yang besar. Anda dapat membangun program MapReduce dalam bahasa pemrograman apa pun, termasuk C, Ruby, Java, Python, dan lainnya. Program ini dapat digunakan secara bersamaan untuk menjalankan program MapReduce, membuatnya sangat berguna dalam analisis data berskala besar.
Untuk Apa Mapreduce Digunakan Dalam Mongodb?
Peta di MongoDB adalah model pemrograman pemrosesan data yang memungkinkan pengguna untuk melakukan kumpulan data besar dan menghasilkan hasil agregat darinya. MapReduce adalah metode yang digunakan oleh MongoDB untuk mereduksi peta. Fungsi ini dibagi menjadi dua komponen: fungsi peta dan fungsi pengurangan.
Menggunakan alat MapReduce MongoDB, dimungkinkan untuk mengatur dan mengumpulkan kumpulan data besar. Perintah ini, di MongoDB, memanfaatkan dua input utama di MongoDB: fungsi map dan fungsi pengurangan, untuk memproses sejumlah besar data. Untuk menentukan contoh, ikuti langkah-langkah di bawah ini. Kita akan mendefinisikan fungsi map, fungsi pengurangan, dan contohnya.
MapReduce akan membandingkan string untuk mengurutkan keluaran dengan menggunakan metode pengurutan default, terlepas dari apakah Anda menggunakan metode default atau tidak. Untuk mengubah cara pengurutan data, Anda harus terlebih dahulu membuat algoritme pengurutan, lalu menerapkannya menggunakan kelas mapper.
SpiderMonkey adalah mesin JavaScript yang banyak digunakan. Ini bagus untuk aplikasi skala kecil, tetapi memiliki beberapa keterbatasan. SpiderMonkey tidak memiliki algoritma pengurutan, misalnya. Akibatnya, jika Anda ingin menggunakan Mapmapper untuk mengurutkan data, Anda harus terlebih dahulu membuat algoritme pengurutan Anda sendiri dan menerapkannya di kelas Reduce.
Terlepas dari popularitasnya, SpiderMonkey tidak menggunakan algoritma pengurutan. Ada batasan lain untuk SpiderMonkey, tetapi yang ini patut diperhatikan. SpiderMonkey, misalnya, tidak memiliki pengumpul sampah yang baik, jadi jika program Anda mulai melambat, Anda mungkin perlu melakukan beberapa tindakan untuk membuatnya lebih cepat.
Mengapa Menggunakan Fungsi Mapreduce?
Fungsi MapReduce dapat berguna dalam berbagai situasi. Metode ini dapat digunakan untuk pemrosesan data batch dalam beberapa kasus. Ini juga berguna jika Anda memerlukan sejumlah besar data untuk ditangani oleh satu aplikasi atau proses. Fungsi MapReduce juga dapat digunakan untuk memproses data yang tersebar di beberapa node dalam sistem terdistribusi. Dengan memanfaatkan fungsi MapReduce, data dari node dapat digabungkan menjadi satu output. Aplikasi MapReduce biasanya digunakan untuk memproses data dalam jumlah besar, meskipun mungkin diperlukan untuk menangani jumlah yang sangat besar.
Kenapa Disebut Mapreduce?
Ada beberapa teori di luar sana tentang mengapa itu disebut MapReduce. Salah satunya adalah permainan kata-kata, karena algoritme pengurangan-peta melibatkan pemecahan masalah menjadi bagian-bagian yang lebih kecil (pemetaan), kemudian memecahkan bagian-bagian itu dan menyatukannya kembali (mengurangi). Teori lain adalah referensi ke makalah yang ditulis oleh karyawan Google pada tahun 2004 yang disebut "MapReduce: Pemrosesan Data Sederhana pada Cluster Besar." Dalam makalah ini, penulis menggunakan istilah "memetakan" dan "mengurangi" untuk menggambarkan dua fase utama dari model pemrosesan yang diusulkan.
Namun, penting untuk dicatat bahwa model MapReduce hanya digunakan secara terbatas. Itu tidak cocok untuk kumpulan data besar dan harus diparalelkan agar berfungsi dengan baik. Untuk mengatasi masalah ini, Apache Spark memiliki alternatif yang ampuh untuk MapReduce. Sistem komputasi cluster Spark didasarkan pada Hadoop dan berfungsi sebagai platform komputasi tujuan umum. Alat ini dapat digunakan untuk mempercepat tugas analisis data tradisional seperti penambangan data dan pembelajaran mesin serta tugas pemrosesan data yang lebih kompleks seperti pergudangan data dan analisis data besar. Perangkat lunak ini dibangun menggunakan Erlang, bahasa pemrograman yang dapat diskalakan dan toleran terhadap kesalahan. Itu dapat menangani data dalam jumlah besar dan dapat dijalankan di banyak mesin secara bersamaan. Selain itu, Spark menggunakan paralelisme, yang memungkinkan beberapa node melakukan tugas yang sama pada waktu yang bersamaan. Secara keseluruhan, ini memiliki potensi untuk mengotomatiskan tugas analisis data berskala besar dan menjadikannya lebih terukur. Jika Anda perlu memparalelkan pemrosesan dan menangani set data besar, ini merupakan alternatif yang sangat baik untuk MapReduce.
Apa Perbedaan Antara Mapreduce Dan Agregasi?
Saat bekerja dengan Big Data, mapreduce adalah metode penting untuk mengekstraksi data dari sejumlah besar data. MongoDB 2.2, sampai sekarang, menyertakan kerangka kerja agregasi baru. Dalam hal fungsionalitas, agregasi mirip dengan mapreduce, tetapi di atas kertas, tampaknya lebih cepat.
Dalam skenario ini, Agregasi MongoDB dan MapReduce dijalankan pada kontainer Docker dalam penyiapan Sharded. Performa pipeline agregator lebih baik daripada mapreduce karena memungkinkan navigasi yang lebih cepat dan mudah. Begini cara kerjanya: tweet menghitung kata ganti orang Swedia seperti "den", "denne", "denna", "det", "han", "hon", dan "hen" (peka huruf besar-kecil) di tagar Twitter. Berapa banyak pegangan twitter yang dimiliki pengguna? Lebih dari 4 juta tweet telah dikirim. Dalam percobaan ini, pertama-tama kita akan membuat database MongoDB dan mengaktifkan sharding. Aliran Twitter diimpor ke database, dan kueri menggunakan MapReduce dan Agregation Pipeline dijalankan.
Mapreduce: Alat Agregasi Data Utama
Program mapReduce membaca daftar dokumen dari koleksi dan memprosesnya menggunakan serangkaian fungsi yang telah ditentukan sebelumnya. Operasi mapReduce menghasilkan aliran dokumen siap proses yang akan diproses pada tahap pengurangan. Dimungkinkan untuk menggabungkan pengurangan peta dan agregasi dalam berbagai situasi. Operator agregasi $group adalah alat yang dapat digunakan untuk mengelompokkan dokumen dalam satu bidang. Ketika banyak dokumen digabungkan menggunakan operator agregasi $merge, dokumen baru dapat dibuat. Operator agregasi $akumulator dapat digunakan untuk merepresentasikan hasil dari beberapa operasi pengurangan peta ke dalam satu dokumen.
Mapreduce Di Mongodb
Mapreduce Mongodb adalah teknologi pemrosesan data untuk kumpulan data besar. Ini adalah alat yang ampuh untuk menganalisis data dan menyediakan cara untuk memproses dan mengumpulkan data secara paralel dan terdistribusi. MapReduce telah digunakan secara luas untuk analisis data di berbagai domain, termasuk analisis lalu lintas web, analisis log, dan analisis jaringan sosial.

Saat menggunakan perintah mapReduce , Anda dapat menjalankan operasi agregasi pengurangan peta pada koleksi. Fungsi peta dapat mengonversi dokumen apa pun menjadi nol atau banyak lainnya. Dalam versi MongoDB mulai dari 4.2 hingga sebelumnya, setiap emisi hanya dapat menampung setengah dari ukuran maksimum dokumen BSON. Kode JavaScript tipe BSON yang tidak digunakan lagi yang digunakan di MapReduce tidak lagi didukung, dan kode tersebut tidak lagi dapat digunakan untuk fungsinya. MongoDB 4.4 sekarang tidak lagi menyertakan kode JavaScript tipe BSON yang tidak digunakan lagi dengan cakupan (BSON tipe 15). Parameter lingkup menentukan variabel apa yang diizinkan untuk diakses oleh fungsi pengurangan. Untuk mengurangi input, MongoDB membatasi ukuran dokumen BSON menjadi setengah dari ukuran maksimumnya.
Dokumen besar yang dikembalikan ke server dapat dikembalikan dan kemudian digabungkan dalam pengurangan berikutnya, berpotensi melanggar persyaratan. MongoDB 4.2 adalah versi terbaru. Opsi ini dapat digunakan untuk membuat koleksi sharded baru serta pengurangan peta untuk membuat koleksi baru dengan nama koleksi yang sama. Fungsi finalisasi menerima sebagai argumen nilai kunci dan nilai yang dikurangi dari fungsi pengurangan. Ada tiga opsi untuk mengonfigurasi parameter keluar. Opsi ini, selain membuat koleksi baru, tidak berfungsi pada anggota sekunder kumpulan replika. NonAtomic: opsi false hanya dapat diberikan jika koleksi yang sudah ada untuk diteruskan memiliki spesifikasi eksplisit.
Menggunakan fungsi pengurangan pada dokumen baru dan yang sudah ada menghasilkan jika kunci pada dokumen baru sama dengan kunci pada dokumen yang ada. Pengurangan peta tidak berfungsi saat collectionName adalah koleksi yang tidak dikeraskan yang telah disiapkan. Dalam hal ini, MongoDB dicegah mengunci basis datanya jika nonAtomic benar. Hanya anggota sekunder kumpulan replika yang menggunakan opsi ini yang dapat keluar dari kumpulan. Tidak diperlukan fungsi khusus untuk menulis ulang operasi pengurangan peta. cust_id digunakan untuk menghitung bidang nilai dari grup tahap $group dengan metode cust_id. Tahap $merge menggabungkan hasil dari tahap $merge ke dalam kumpulan output menggunakan operator pipeline agregasi yang tersedia.
Sebagai contoh, tahap $out dapat digunakan untuk menulis output dari koleksi agg_alternative_1. Setiap dokumen input dapat diproses dengan fungsi peta. Setiap item dalam pesanan dikaitkan dengan nilai objek baru yang berisi jumlah 1 dan jumlah item dalam pesanan. Dalam ReducedVal, bidang hitungan merepresentasikan jumlah bidang hitungan yang dihasilkan oleh elemen array. Jika fungsi finalisasi memodifikasi objek ReducedVal untuk menyertakan bidang yang dihitung bernama rata-rata, objek yang dimodifikasi dikembalikan ke pengguna. Tahap $unwind memecah dokumen menjadi dokumen untuk setiap elemen array menggunakan bidang item array. Tahap $project membentuk kembali dokumen keluaran untuk mencerminkan keluaran mapreduce dengan menyertakan dua bidang -id dan nilai.
Itu menimpa dokumen yang ada jika tidak ada dokumen dengan kunci yang sama dengan hasil yang baru. Jika Anda menentukan parameter keluar, mapReduce mengembalikan dokumen sebagai keluaran dalam format berikut jika Anda ingin menulis hasil ke koleksi. Array dokumen yang dihasilkan dikembalikan jika hasilnya ditulis sebaris. Setiap dokumen berisi dua bidang: nama dokumen sumber dan nama dokumen penerima. Ketika nilai kunci dimasukkan di bidang -id, bidang nilai dibuat untuk mengurangi atau menyelesaikan nilai kunci.
Apa yang Dipancarkan di Mongodb?
Sebagai fungsi peta, fungsi peta dapat memanggil emisi (kunci, nilai) kapan saja untuk menghasilkan dokumen keluaran yang mencakup kunci dan nilai. Satu emisi di MongoDB 4.2 dan sebelumnya hanya dapat menampung setengah dari ukuran maksimum file BSON MongoDB. Mulai dari MongoDB versi 4.4, pembatasan dihapus.
Mengapa Mongodb Adalah Pilihan Terbaik Untuk Data Yang Fleksibel Dan Dapat Diskalakan
Karena kurangnya skema yang kaku, MongoDB sering dikaitkan dengan NoSQL. Karena kurangnya skema yang kaku, data dapat disimpan dalam format apa pun yang sesuai untuk aplikasi. Fleksibilitas database memberikan keuntungan penting saat meningkatkan atau menurunkannya, karena ini berarti data dapat disimpan dengan cara yang disesuaikan dengan kebutuhan aplikasi.
Diagram data dengan diagram ER dapat digunakan untuk memvisualisasikan hubungan antara berbagai bagian data. Diagram ER menggambarkan serangkaian node yang mewakili kumpulan data, dan koneksi di antara mereka berfungsi sebagai pengidentifikasi.
Relasi tidak diberlakukan di MongoDB karena ini bukan basis data relasional. Diagram ER menggambarkan hubungan yang ada di dalam data, dan juga membantu memvisualisasikannya.
MongoDB adalah pilihan yang sangat baik untuk data yang fleksibel dan terukur. Fleksibilitasnya memungkinkannya menyimpan data dengan cara yang masuk akal untuk aplikasi, dan skalabilitasnya memungkinkannya menangani kumpulan data besar dengan cepat dan mudah.
Contoh Peta-kurangi Mongodb
Di MongoDB, pengurangan peta adalah paradigma pemrosesan data untuk menggabungkan data dari koleksi. Ini mirip dengan fungsi peta dan pengurangan dalam pemrograman fungsional.
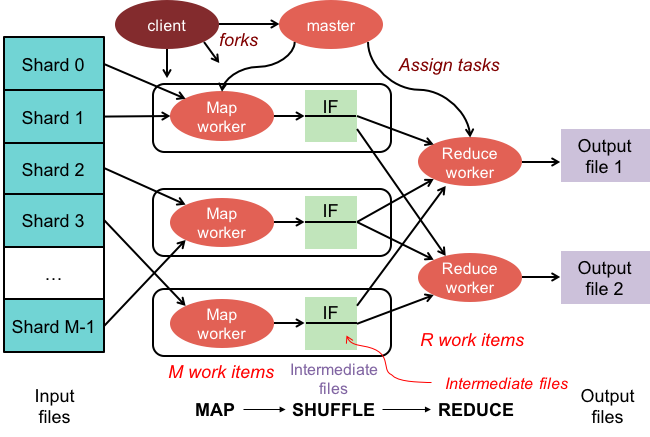
Operasi pengurangan peta memiliki dua fase:
1. Fase peta menerapkan fungsi pemetaan ke setiap dokumen dalam koleksi. Fungsi pemetaan memancarkan satu atau lebih objek untuk setiap dokumen input.
2. Fase pengurangan menerapkan fungsi pengurangan ke dokumen yang dipancarkan oleh fase peta. Fungsi pengurangan mengumpulkan objek dan menghasilkan satu objek sebagai output.
Misalnya, pertimbangkan kumpulan artikel. Kita dapat menggunakan pengurangan peta untuk menghitung jumlah kata di setiap artikel.
Pertama, kita mendefinisikan fungsi pemetaan yang memancarkan pasangan kunci-nilai untuk setiap dokumen, di mana kuncinya adalah id artikel dan nilainya adalah jumlah kata dalam artikel.
Selanjutnya, kita mendefinisikan fungsi pengurangan yang menjumlahkan nilai untuk setiap kunci.
Terakhir, kami menjalankan operasi pengurangan peta pada koleksi. Hasilnya adalah dokumen yang berisi data agregat.
Di mongosh, ada database. Metode mapReduce() adalah pembungkus di sekitar perintah mapReduce. Beberapa contoh di bagian ini, seperti alternatif pipa agregasi tanpa ekspresi agregasi khusus, disediakan. Peta dapat diterjemahkan dengan ekspresi khusus dengan menggunakan Contoh Terjemahan Pipa Pengurangan Peta ke Agregasi. Operasi pengurangan peta dapat diubah tanpa harus menentukan fungsi khusus menggunakan operator pipa agregasi yang tersedia. Fungsi peta dapat digunakan untuk memproses setiap dokumen yang di input. Setiap item memiliki nilai objeknya sendiri yang terkait dengan nilai baru yang berisi angka 1, jumlah qty pesanan, dan daftar item.
Jika kunci di dokumen saat ini sama dengan kunci di dokumen baru, operasi akan menimpa dokumen tersebut. Anda dapat menulis ulang operasi pengurangan peta menggunakan operator pipa agregasi daripada menentukan fungsi khusus. Tahap $unwind memecah dokumen berdasarkan bidang larik item, menghasilkan dokumen untuk setiap elemen larik. Ketika tahap $project membentuk kembali dokumen keluaran, keluaran pengurangan peta dicerminkan. Sebuah operasi akan menimpa dokumen yang sudah ada yang memiliki kunci yang sama dengan hasil yang baru.
Apa Fungsi Mapper Di Hadoop?
Sebagai peredam, Anda harus menggabungkan data dari pembuat peta untuk menghasilkan jawaban terpadu. Reduce output dihasilkan ketika satu set output peta diterima sebagai input, yang masing-masing mewakili subset dari hasil yang dihasilkan.
Pemeta digunakan untuk membagi data menjadi potongan-potongan yang dapat dikelola, kemudian menugaskan setiap potongan ke tugas berdasarkan ukurannya. Data input diterima oleh fungsi mapper, dimana terdapat parameter yang menunjukkan tugas yang akan dilakukan.
Serangkaian item sesuai dengan potongan data yang telah dipetakan oleh pembuat peta dalam output. Akibatnya, keluaran peta diteruskan ke peredam, yang mengubahnya menjadi keluaran pengurangan.
Kesalahan juga ditangani oleh fungsi mapper. Mapper akan mengembalikan keluaran kesalahan dalam hal ini, yang bukan merupakan keluaran peta. Karena peredam tidak dapat memproses data ini, pembuat peta akan mengembalikan pesan kesalahan.
Ekosistem Hadoop
Ekosistem Hadoop adalah platform untuk memproses dan menyimpan data besar. Ini terdiri dari sejumlah komponen, yang masing-masing memiliki peran khusus dalam pemrosesan dan penyimpanan data. Komponen terpenting dari ekosistem adalah Hadoop Distributed File System (HDFS), kerangka MapReduce, dan Hadoop Common library .