
Basis Data NoSQL: Impala
Diterbitkan: 2023-03-03NoSQL adalah istilah yang digunakan untuk mendeskripsikan database yang tidak menggunakan struktur database relasional tradisional. Sebaliknya, basis data NoSQL sering kali dirancang untuk memberikan solusi yang lebih sederhana dan dapat diskalakan.
Impala adalah database NoSQL yang dirancang untuk memberikan solusi yang cepat dan dapat diskalakan untuk mengelola kumpulan data yang besar. Impala didasarkan pada model data Google Bigtable dan menggunakan format penyimpanan berbentuk kolom. Impala tersedia sebagai proyek sumber terbuka dan didukung oleh Cloudera.
Apache Impala adalah mesin kueri SQL sumber terbuka yang diinstal pada kluster Hadoop dan melakukan pemrosesan paralel masif (MPP) untuk data yang disimpan di sistem. Awalnya dikembangkan pada tahun 2012, proyek sumber terbuka ini dikenal sebagai "Microsoft Formula 1".
Platform Impala memungkinkan pengguna untuk melakukan kueri SQL latensi rendah ke data Hadoop yang disimpan di HDFS dan Apache HBase tanpa harus memindahkan atau mengubah data.
Apakah Berbasis Impala Sql?
Impala adalah mesin kueri berbasis SQL yang berjalan di Apache Hadoop. Ini memungkinkan pengguna untuk meminta data yang disimpan dalam HDFS dan HBase menggunakan SQL. Impala memberikan kinerja tinggi dan latensi rendah dibandingkan dengan mesin kueri Hadoop lainnya seperti Hive dan Pig.
Basis data MPP analitik Impala memberikan wawasan waktu tercepat di industri. Ini terintegrasi dengan CDH dan dapat diakses melalui Cloudera Enterprise. Database MPP untuk Apache Hadoop, seperti Impala, menggunakan HDFS untuk menyediakan wawasan yang lebih cepat.
Impala Adalah Basis Data
Ini adalah database yang saya yakini.
Apakah Impala Alat Etl?
Impala bukan alat ETL, ini adalah mesin kueri SQL yang dapat digunakan untuk melakukan kueri SQL setelah data dibersihkan melalui suatu proses.
Untuk Apa Apache Impala Digunakan?
Menggunakan kueri mirip SQL, kita dapat membaca data dari berbagai sumber menggunakan Impala. Apache Impala bekerja lebih baik daripada Hive dan mesin SQL lainnya dalam hal akses ke data yang disimpan di Hadoop Distributed File System . Kami menggunakan Impala untuk menyimpan data di Hadoop HBase, HDFS, dan Amazon S3.
19 Perusahaan Yang Menggunakan Apache Impala Di Tech Stacks Mereka
Apache Impala adalah mesin pengolah data yang populer untuk berbagai bisnis besar. Menurut laporan, 19 perusahaan teknologi, termasuk Stripe, Agoda, dan Expedia.com, menggunakan Apache Impala. Platform Impala fleksibel dan efisien, mampu menangani kumpulan data besar dengan cepat dan efektif. Penggunaan alat ini secara luas menunjukkan betapa bermanfaatnya, dan betapa bermanfaatnya dalam pemrosesan data.
Apa Perbedaan Antara Sql Hive Dan Impala?
Sasaran Hive adalah untuk menangani kueri yang berjalan lama yang membutuhkan banyak transformasi dan penggabungan. Karena latensi rendah dan kemampuannya untuk menangani kueri yang lebih kecil, mesin pemrosesan kueri Impala ideal untuk komputasi interaktif. Spark mendukung kueri jangka pendek dan jangka panjang selain kueri jangka pendek dan panjang.
Hive Lebih Cocok Untuk Pekerjaan Batch Jangka Panjang
Tujuan utama alat bukan untuk memproses kumpulan. Hive lebih cocok untuk pekerjaan batch jangka panjang daripada Impulsa, yang dapat menangani kumpulan data yang lebih kecil.
Apakah Impala Sebuah Basis Data
Impala adalah database yang menyimpan data dalam format kolom. Ini dirancang agar dapat diskalakan dan memberikan kinerja tinggi untuk kumpulan data besar.
Dalam rilis awal Impala, tipe data kolom inti berikut ini didukung: STRING, VARCHAR, VARCHar2, INT, dan FLOAT daripada angka, dan tidak ada tipe BLOB yang didukung. Impala SQL-92 menyertakan beberapa penyempurnaan standar standar SQL, tetapi tidak menggabungkan semuanya. Ketika data terlalu besar untuk diproduksi, dimanipulasi, dan dianalisis pada satu server, Impala bekerja lebih baik daripada gudang data lainnya dan lebih mendukung skalabilitas. Tidak perlu menghapus lokasi asli file data saat memuat Impala karena ringan. Langkah pertama dalam mempelajari tentang pengujian kinerja, skalabilitas, dan konfigurasi klaster multi-node biasanya mengumpulkan data dalam jumlah besar. Cloudera Impala dioptimalkan untuk pemuatan data dan pembacaan massal dalam set data besar, memungkinkan Anda melakukan lebih banyak hal dengan lebih sedikit. Ukuran blok HDFS multimegabyte memungkinkan Impala untuk memproses sejumlah besar data secara paralel di beberapa server jaringan.
Alih-alih merencanakan indeks yang dinormalisasi dan waktu serta upaya yang diperlukan untuk membuatnya, Anda akan melakukannya di Impala. Mesin kueri Impala dapat menangani sejumlah besar data yang berasal dari gudang data. Ini menganalisis cluster dan mendistribusikan tugas di antara node untuk mengurangi jumlah sumber daya yang dikonsumsi. Partisi gudang data adalah konsep yang akrab di Impala. Mempartisi mengurangi I/O disk dan meningkatkan skalabilitas kueri di Impala. File data diperlukan karena Anda tidak akan dapat mengakses tabel bawaan apa pun di Impala. INSERT adalah salah satu opsi yang tersedia.
Untuk membuat dua tabel mainan, gunakan pernyataan nilai. Jika Anda telah menggunakan perangkat lunak berorientasi batch, Anda dapat mencobanya. Anda dapat memasukkan teknologi SQL-on-hadoop ke dalam konfigurasi Apache Hive Anda. Tabel Hive di Impala tidak dimuat atau diubah dengan cara yang memakan waktu.
Impala: Alat Manajemen Data yang Kuat untuk Hadoop
Sintaks SQL akrab bagi pengguna Impala, yang dapat meminta data yang disimpan di HDFS dan Apache HBase. Dengan cara ini, Hadoop dan Impulsa dapat digunakan daripada basis data relasional tradisional . Selain itu, ini adalah alat manajemen data yang kuat berkat fitur-fiturnya. Selain itu, kemampuannya untuk kumpulan data besar sangat mengesankan, dan dapat menanganinya dengan sangat mudah.
Impala Dalam Data Besar
Impala adalah mesin kueri MPP SQL open source yang berjalan di Apache Hadoop. Ini memberikan kueri SQL interaktif yang cepat pada data yang disimpan dalam HDFS dan HBase. Impala dirancang untuk meningkatkan kinerja Apache Hadoop dengan menyediakan antarmuka SQL interaktif yang cepat untuk data yang disimpan dalam HDFS dan HBase.

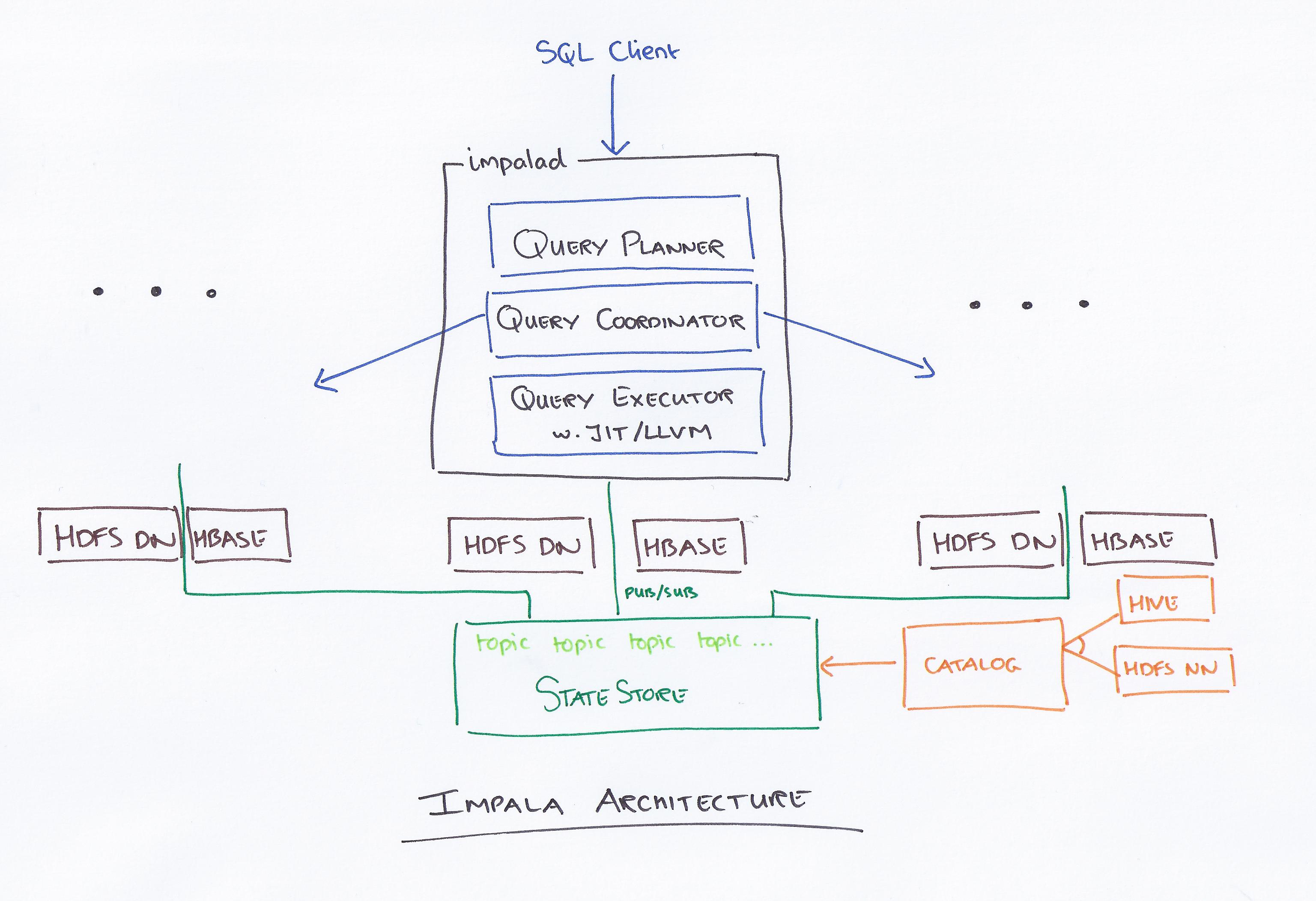
Impala, dipimpin oleh Cloudera, adalah sistem kueri baru. Hadoop memiliki HDFS dan HBase, sehingga dapat meminta data besar level PB yang disimpan di sana. Teknologi ini didasarkan pada sarang dan memori untuk perhitungan, serta memperhitungkan gudang data, dan menyediakan pemrosesan batch waktu nyata dan beberapa pemrosesan bersamaan. Klien mengirimkan permintaan kueri ke sebuah node dalam jaringan impalad, tempat ID kueri dikembalikan untuk operasi klien selanjutnya. Selama langkah pertama proses pembuatan penganalisis, rencana eksekusi yang berdiri sendiri (rencana mesin tunggal, rencana eksekusi terdistribusi) dibuat, dan SQL juga akan dieksekusi, seperti perubahan urutan gabungan, penurunan predikat, dan sebagainya. Semua node menyimpan salinan informasi meta-data terbaru untuk memastikan bahwa Anda tidak ketinggalan informasi. Sebelum menggunakan Hadoop, Hive, atau Ipurbia, Anda harus menginstal perangkat lunak pengolah data yang diperlukan terlebih dahulu.
File konfigurasi Impala dapat diubah. Setiap node melakukan perubahan konfigurasi di Impala. Semua node bertanggung jawab untuk menghubungkan paket driver MySQL ke database. Node mengubah jalur Java Bigtop.
Perbandingan Sarang Dan Impala
Ada beberapa perbedaan kecil juga, selain tiga perbedaan utama ini. Di Hive, ada subset dari HiveQL, sedangkan di Implisit, ada subset dari HiveQL. Hive dan Impala masing-masing digunakan untuk pergudangan data dan kueri interaktif. Hive, berbeda dengan Impala, tidak ditujukan untuk komputasi interaktif.
Apa Impala Di Hadoop
Impala adalah mesin kueri SQL sumber terbuka untuk data yang disimpan di kluster Hadoop. Ini dirancang untuk menyediakan kueri SQL interaktif yang cepat pada data yang disimpan di HDFS, HBase, atau sumber data Hadoop lainnya.
Impala mempekerjakan berbagai macam komponen Hadoop akrab . INSERT hanya dapat menulis data yang bertipe Impala dapat membaca, sedangkan SELECT dapat membaca data yang bertipe Impala dapat membaca. Saat menggunakan format file Avro, RCFile, atau SequenceFile, data dimuat ke Hive. Statistik tabel dan statistik kolom dapat digunakan selain statistik tabel dan kolom. Semua pernyataan DDL dan DML diperbarui secara otomatis menggunakan daemon katalog di Impala 1.2 dan lebih tinggi jika dikirim melalui daemon katalog. Metode INVALIDATE METADATA mengembalikan metadata untuk semua tabel di metastore yang telah diakses. File data disimpan dalam direktori untuk tabel baru dan dibaca terlepas dari nama file saat Impala sedang berjalan.
Secara keseluruhan, Apache Hive bekerja dengan baik sebagai platform pergudangan data, sedangkan Impala lebih cocok untuk pemrosesan paralel. Hive toleran terhadap kesalahan, sedangkan Impulsa tidak.
Apache Impala
Apache Impala adalah mesin query SQL yang cepat dan interaktif untuk Apache Hadoop. Ini memungkinkan pengguna untuk mengeluarkan kueri SQL latensi rendah ke data yang disimpan di HDFS dan Apache HBase tanpa memerlukan pemindahan atau transformasi data.
Konsep arsitektur Impala memungkinkannya menangani kueri interaktif menggunakan HDFS secara lebih efisien daripada mesin kueri lainnya. Hive jauh lebih lambat karena operasi I/O disknya, tetapi Apache jauh lebih cepat karena merupakan mesin yang sama sekali berbeda. Tidak ada perbedaan antara Impulsa dan Presto karena Impulsa menggunakan teknologi yang jauh lebih cepat dan Presto menggunakan arsitektur serupa. Ketika datang ke file Parket, Impala melakukan yang terbaik. Tentukan data apa yang harus Anda partisi berdasarkan permintaan analis Anda. Dengan Compute Stats Statistics, kueri Anda akan jauh lebih mudah, terutama jika melibatkan lebih dari satu tabel (bergabung). Kami mengalami kerusakan server katalog Impala empat kali per minggu, dan permintaan kami memakan waktu terlalu lama untuk diselesaikan.
Selain itu, jumlah file yang kami buat sangat memengaruhi kinerja kueri kami. Hasilnya, kami mulai mengelola partisi kami dan menggabungkannya menjadi ukuran file optimal sekitar 256MB. Dinyatakan bahwa setiap partisi hanya memiliki satu file (kecuali ukurannya > 256MB). Jenis kolom yang paling sesuai harus dipilih dari antara semua jenis data yang didukung oleh Implisit. Untuk membatasi jumlah kueri bersamaan atau memori Y yang diakses oleh pengguna, gunakan Kontrol Penerimaan Impala. Jika kueri berlangsung lebih dari 30 menit, kueri dianggap mati.
Mesin Terbaik Untuk Big Data: Impala
Mesin Impala adalah mesin pengolah data Hadoop yang dirancang khusus untuk cluster besar. Ini menggunakan energi yang jauh lebih sedikit dan mengkonsumsi sumber daya yang jauh lebih sedikit daripada mesin MapReduce standar Hadoop. Implisit menggunakan HDFS sistem file terdistribusi sebagai media penyimpanan data utamanya, mengandalkan redundansi HDFS untuk mencegah pemadaman perangkat keras atau jaringan pada basis node-by-node. File data yang mewakili data tabel secara fisik diwakili oleh format file HDFS dan codec kompresi yang sudah dikenal.
Mesin Kueri Pemrosesan Paralel
Mesin kueri pemrosesan paralel adalah jenis mesin basis data yang dirancang untuk memproses kueri secara paralel. Ini dapat dilakukan dengan menggunakan banyak prosesor, banyak inti, atau banyak mesin. Pemrosesan paralel dapat sangat meningkatkan kinerja mesin kueri, terutama untuk kueri yang kompleks.
Komputer multiprosesor digunakan untuk mengubah kueri kompleks menjadi rencana eksekusi yang dapat dijalankan secara bersamaan, memungkinkannya memproses data dalam jumlah besar sekaligus. Eksekusi yang efisien, seperti waktu respons kueri yang baik atau throughput kueri yang tinggi, diperlukan untuk kinerja tinggi. Ini dicapai melalui penggunaan teknik eksekusi paralel yang efisien dan pengoptimalan kueri.
Pemrosesan Paralel: Masa Depan Etl?
Kueri tingkat tinggi dapat diubah menjadi rencana eksekusi yang dapat dieksekusi secara efisien oleh komputer multiprosesor menggunakan pemrosesan kueri paralel. Pemrosesan paralel menggunakan teknik menggabungkan data paralel dan terdistribusi, serta berbagai teknik eksekusi yang disediakan oleh sistem basis data paralel . Pemrosesan kueri paralel diimplementasikan dalam ETL dengan membagi kumpulan catatan di setiap tabel sumber yang ditugaskan untuk mentransfer ke dalam potongan dengan ukuran yang sama, dan kemudian melakukan proses transformasi data untuk setiap tabel sumber dalam satu siklus, memilih data secara berurutan, potongan demi potongan .