
Babi: Platform Tingkat Tinggi Untuk Apache Hadoop
Diterbitkan: 2023-02-22Pig adalah platform tingkat tinggi untuk membuat program yang berjalan di Apache Hadoop. Istilah "Babi" mengacu pada lapisan infrastruktur platform, yang terdiri dari kompiler dan lingkungan eksekusi, serta sekumpulan operator tingkat tinggi. Lapisan infrastruktur Pig menyediakan seperangkat alat bagi pengembang untuk membuat, memelihara, dan menjalankan program Pig mereka. Pig adalah proyek open source yang merupakan bagian dari ekosistem Apache Hadoop . Model pemrograman Pig didasarkan pada aliran data, yang membuatnya mudah untuk menulis program yang memproses data dalam jumlah besar. Program babi terdiri dari serangkaian operator yang dieksekusi dalam grafik asiklik terarah. Pig adalah pilihan tepat untuk memproses data dalam jumlah besar karena dapat diskalakan, efisien, dan mudah digunakan.
Sebagai solusi NoSQL, Anda memerlukan cara khusus yang telah ditentukan sebelumnya untuk menganalisis dan mengakses data. SQL (UNION, INTERSECT, dll.) adalah ekspresi kueri umum yang jarang digunakan dalam dunia big data. Karena Hive dioptimalkan untuk pemrosesan batch dan data besar, yang terbaik adalah menyentuh setiap baris. Hive menghabiskan lebih sedikit waktu dan uang untuk operasi daripada Hadoop, yang memiliki keunggulan skala. Bahkan kueri kecil pada sistem dev bisa menjadi PESANAN besarnya lebih lambat daripada kueri serupa di RDBMS. Hive tidak meng-cache hasil kueri. Mengirim ulang kueri berulang adalah praktik umum di MapReduce.
Ada dua jenis Hive: 1) Hive bukan database; melainkan, ini adalah mesin kueri yang mendukung bagian SQL khusus untuk data kueri b) Hive adalah database dengan dukungan SQL c) Hive adalah database khusus SQL. Hive adalah sistem gudang data berbasis SQL untuk Hadoop yang mencakup Pig dan Python, antara lain; Hive digunakan untuk menyimpan data Hadoop .
Apakah Babi A Sql?
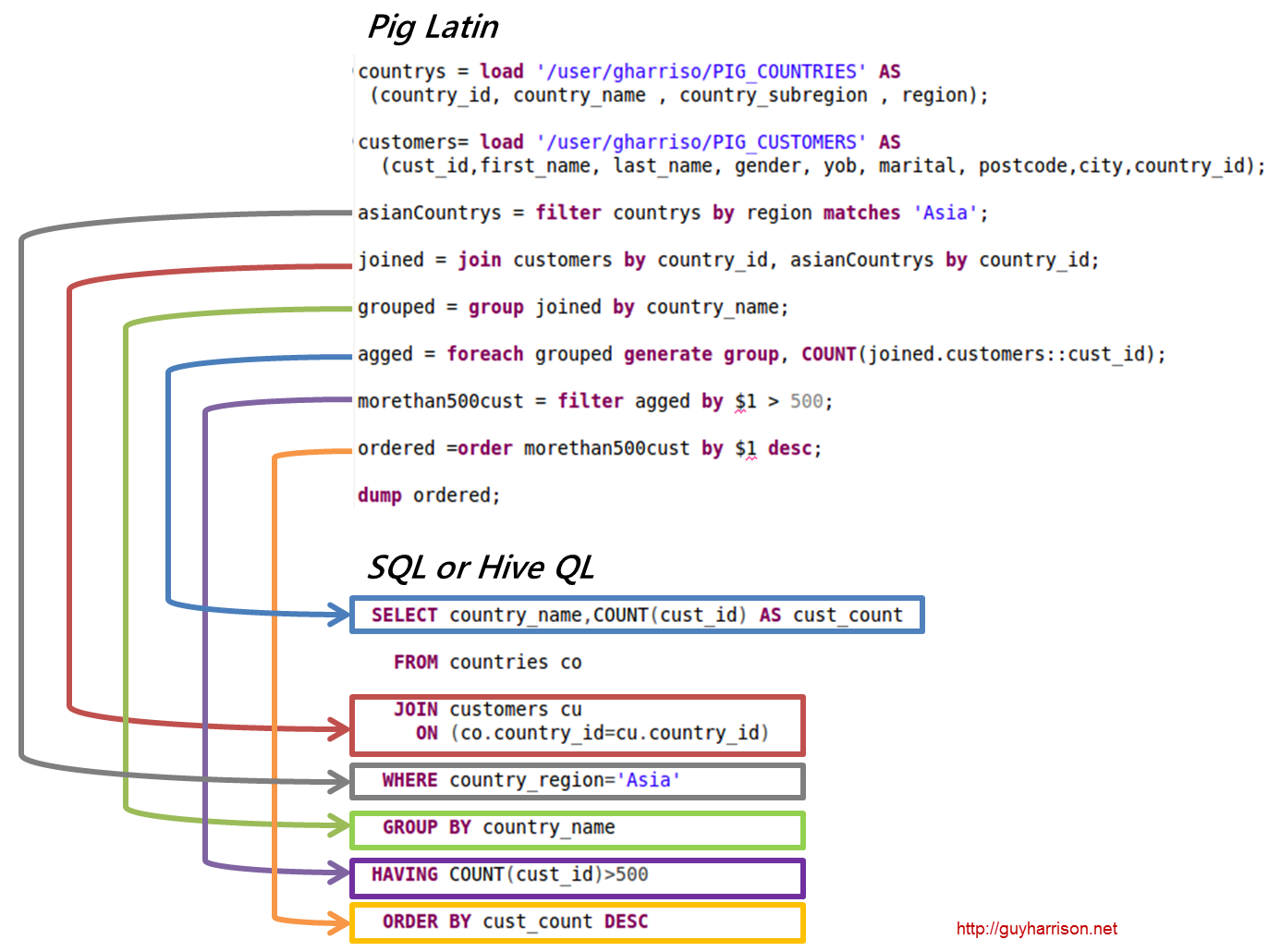
Tidak ada jawaban benar atau salah untuk pertanyaan ini, karena tergantung pada pendapat pribadi. Beberapa orang mungkin percaya bahwa pig adalah sql, sementara yang lain mungkin tidak. Pada akhirnya, terserah individu untuk memutuskan apakah babi adalah sql atau tidak.
Saat ini, Apache Hive dan Pig adalah dua istilah yang dengan cepat menjadi sinonim dengan big data. Dengan alat ini, pengembang dan analis data dapat menggunakannya untuk mengurangi kerumitan MapReduce sambil tetap mempertahankan integritas data tingkat tinggi. Hive adalah infrastruktur gudang data yang juga dikenal sebagai alat ETL (ekstraksi, pemuatan, dan transformasi). Apache Hive, Pig, dan SQL adalah tiga alat populer untuk analisis dan pengelolaan data. Anda harus mengetahui platform mana yang terbaik untuk kebutuhan Anda, dan seberapa sering Anda harus menggunakannya. Mari kita lihat tiga cara berbeda untuk menggunakan Hive, Pig, dan SQL dalam konteks ketiga teknologi ini. SQL masih menjadi raja dalam manajemen dan analisis data besar, terlepas dari dominasi Apache Hive dan Apache Pig. Karena masing-masing menjalankan fungsi tertentu, persyaratannya disesuaikan dengan bisnis. Apache Pig didasarkan pada skrip dan membutuhkan pengetahuan khusus, sedangkan Apache Hive adalah satu-satunya solusi basis data asli pengembang.
Babi adalah hewan serbaguna dengan banyak fleksibilitas. Pig, misalnya, dapat memproses file log yang berisi data JSON atau XML, memungkinkan Anda untuk membaca datanya. Dimungkinkan juga untuk menyimpan data dari layanan web di Pig.
Tipe data peta, tupel, dan tipe data bag dapat digunakan secara bergantian. Mereka mampu menangani data dari sumber manapun.
Apakah Babi Alat Etl?
Tidak ada jawaban pasti untuk pertanyaan ini karena tergantung pada bagaimana Anda mendefinisikan alat ETL. Secara umum, alat ETL adalah aplikasi perangkat lunak yang membantu Anda mengekstrak data dari satu atau lebih sumber, mengubahnya menjadi format yang kompatibel dengan sistem target Anda, dan memuatnya ke dalam sistem tersebut. Beberapa orang akan mengatakan bahwa babi adalah alat ETL karena dapat melakukan semua fungsi tersebut. Orang lain mungkin berpendapat bahwa babi bukanlah alat ETL karena tidak dirancang khusus untuk transformasi data. Pada akhirnya, jawaban atas pertanyaan ini bergantung pada definisi Anda sendiri tentang alat ETL.

Bagaimana Cara Menggunakan Babi Untuk Pemrosesan Etl?
Aplikasi Pig dapat digambarkan sebagai model transaksi ETL, yang menjelaskan bagaimana suatu proses mengekstraksi data dari suatu objek dan mengubahnya menjadi penyimpanan data berdasarkan kumpulan aturan. Pengguna menentukan Fungsi yang Ditentukan Pengguna (UDF) dari Babi untuk menyerap data dari file, aliran, dan sumber lainnya.
Apa itu Alat Babi?
Platform atau alat yang dikenal sebagai Pig memproses kumpulan data besar. Pustaka ini berisi abstraksi tingkat tinggi untuk memproses data dalam proses MapReduce. Pig Latin adalah bahasa skrip tingkat tinggi yang digunakan dalam proses pengkodean untuk mengembangkan kode analisis data.
Apa Perbedaan Antara Babi Dan Sql?
SQL Pig Latin dan Apache Pig adalah bahasa prosedural. SQL adalah bahasa scripting yang bersifat deklaratif. Ini sepenuhnya tergantung pada Apache Pig apakah skema digunakan atau tidak. Data dapat disimpan tanpa memerlukan skema (tipe nilai disimpan dalam $, $, dan seterusnya).
Apakah Babi Bagian Dari Hadoop?
Aplikasi Pig Hadoop adalah bahasa pemrograman tingkat tinggi yang dapat digunakan untuk menganalisis kumpulan data yang sangat besar. Proyek Pig Hadoop Yahoo! adalah salah satu proyek Hadoop pertama . Secara umum, ini melakukan sejumlah besar pekerjaan administrasi data saat menjalankan Hadoop.
Di bidang analisis data besar, Pig Hadoop adalah bahasa pemrograman tingkat tinggi. Untuk menganalisis data menggunakan Apache Pig, pertama-tama kita harus menulis skrip menggunakan Pig Latin. skrip yang akan diubah menjadi tugas MapReduce . Ini dicapai dengan memanfaatkan Pig Engine, ekstensi Apache Pig. Dengan mengikuti langkah-langkah di bawah ini, Anda dapat menginstal Apache Pig di Linux/CentOS/Windows (melalui VM atau Cloudera). Langkah pertama adalah mengunduh dan menginstal Apache Pig. Langkah kedua adalah mengubah variabel lingkungan Apache Pig menggunakan file bashrc.
Pada langkah 3, tentukan versi Pig . File ini dapat disimpan di direktori lain setelah dipindahkan. Langkah kelima adalah meluncurkan Grunt Shell (skrip yang digunakan untuk menjalankan Pig Latin) dengan mengklik perintah Pig.
Mengapa Pig Latin Adalah Bahasa Skrip Tingkat Tinggi Terbaik Untuk Analisis Data
Kode analisis data Pig Latin ditulis dalam bahasa skrip tingkat tinggi. Ini adalah bahasa seperti SQL yang dimaksudkan untuk memproses aliran data secara paralel.
Contoh Babi Apache
Pig adalah platform tingkat tinggi untuk membuat program yang berjalan di Apache Hadoop. Bahasa untuk platform ini disebut Pig Latin. Pig dapat mengeksekusi pekerjaan Hadoop di MapReduce, Tez, atau Spark. Pig Latin mengabstraksi pemrograman dari idiom Java MapReduce menjadi notasi yang membuat pemrograman MapReduce lebih mudah. Misalnya, pernyataan Pig Latin berikut setara dengan kode Java MapReduce di atas: A = LOAD 'mydata' MENGGUNAKAN PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); DUMP A;