
Menskalakan Basis Data NoSQL: Tip dan Trik
Diterbitkan: 2022-11-18Basis data NoSQL semakin populer karena jumlah data yang dihasilkan oleh perusahaan terus bertambah secara eksponensial. Namun, banyak organisasi yang enggan beralih ke NoSQL karena mereka khawatir akan lebih sulit untuk diskalakan. Menskalakan basis data NoSQL sebenarnya tidak jauh berbeda dengan menskalakan basis data relasional. Perbedaan utamanya adalah database NoSQL dirancang untuk dapat diskalakan secara horizontal, artinya database tersebut dapat diskalakan dengan menambahkan lebih banyak node ke sistem. Ini berbeda dengan database relasional , yang dapat diskalakan secara vertikal, yang berarti bahwa mereka hanya dapat diskalakan dengan menambahkan lebih banyak sumber daya ke satu server. Ada beberapa hal yang perlu diingat saat menskalakan database NoSQL: 1. Pastikan data Anda terdistribusi secara merata di semua node. 2. Tambahkan node secara bertahap untuk menghindari kelebihan sistem. 3. Pantau kinerja sistem dengan cermat untuk mengidentifikasi kemacetan apa pun. 4. Tune sistem secara teratur untuk memastikan kinerja yang optimal. Dengan mengingat tips ini, menskalakan database NoSQL seharusnya tidak lebih sulit daripada menskalakan database relasional.
Ada banyak metode dan prinsip untuk menskalakan basis data, bergantung pada jenisnya. Penskalaan database NoSQL dan sql bergantung pada konsep sharding database. Manfaat untuk dapat menyimpan lebih banyak data bertambah saat server didistribusikan, tetapi kami juga mewarisi masalah yang muncul saat didistribusikan. Pecahan otomatis tidak didukung oleh database monolitik, dan teknisi harus menulis logika secara manual untuk menanganinya. Untuk mengatasi masalah ini, proxy, seperti penyeimbang muatan, dapat dipasang di depan layanan kueri dan basis data. Kita bisa mendapatkan query lebih cepat ketika shard besar karena proxy tersebut dapat digunakan kembali. Karena kurangnya pengguna akhir yang menyadarinya, penskalaan basis data NoSQL sebagian besar tidak terlihat.
Setiap pecahan itu unik, tidak seperti arsitektur master-budak. Jika ada kueri baca di shard master, permintaan akan dikirim ke shard slave. Di tingkat pusat data, kami dapat mereplikasi database untuk memastikan bahwa kami memiliki cadangan. Node adalah node yang dapat berkomunikasi dan bertukar informasi dengan node lainnya. Setiap node berkomunikasi dengan sejumlah node lain melalui protokol. Karena semua node sama di Cassandra, sebuah node dapat mereplikasi datanya dari satu node ke node berikutnya tanpa perlu khawatir kehilangan data apa pun. Protokol gosip adalah salah satu dari banyak cara node dapat berbagi informasi.
Basis data terdistribusi dapat memiliki sejumlah keuntungan selain mendapatkan properti tambahan. Komponen penting untuk memastikan ketersediaan adalah replikasi data. Ketika Anda menggunakan replikasi asinkron untuk database Anda, itu tidak akan selalu sepenuhnya konsisten pada awalnya, tetapi akan menjadi lebih konsisten seiring berjalannya waktu. Basis data SQL digunakan dalam aplikasi keuangan yang membutuhkan data presisi tinggi, sedangkan basis data NoSQL digunakan dalam aplikasi yang kurang signifikan seperti jumlah tampilan.
Penskalaan vertikal mengacu pada proses peningkatan beban kerja komputasi secara bertahap dengan penggunaan peningkatan perangkat keras. Pindah ke arsitektur terdistribusi dan menambahkan lebih banyak komputer untuk menyelesaikan masalah kita memerlukan penskalaan, juga dikenal sebagai penskalaan horizontal atau penskalaan.
NoSQL dapat mendukung penskalaan berdasarkan metode Horizontal.
MongoDB, sebagai database NoSQL, dapat diskalakan karena datanya tidak disimpan dalam database relasional. Data disimpan sebagai dokumen mirip JSON yang mudah diakses melalui permintaan HTTP. Distribusi dokumen dapat dilakukan secara horizontal di beberapa node dengan menggunakan metode ini.
Bagaimana Anda Menskalakan Basis Data Nosql?
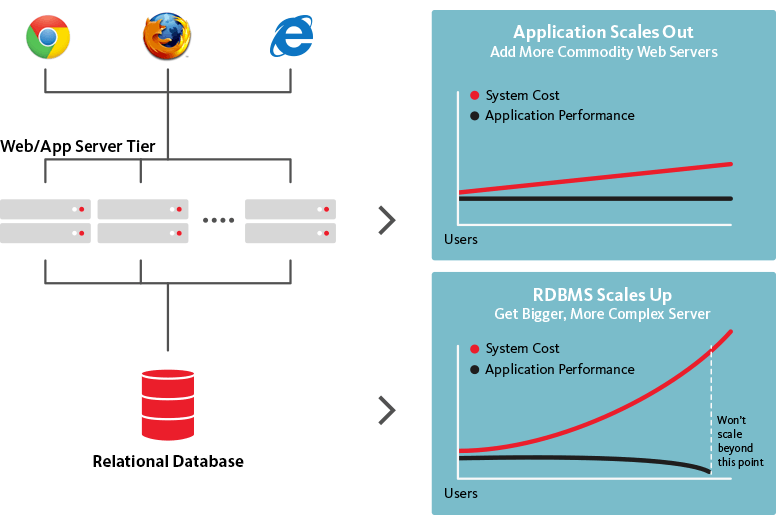
Basis data NoSQL, di sisi lain, dapat diskalakan secara horizontal, yang berarti mereka dapat menangani peningkatan lalu lintas sesuai kebutuhan hanya dengan menambahkan lebih banyak server ke basis data. Karena basis data NoSQL dapat diubah menjadi struktur yang jauh lebih besar dan lebih kuat, ini adalah pilihan logis untuk kumpulan data besar dan basis data yang terus berkembang.
Agar tutorial ini berfungsi, Anda harus memiliki lingkungan Node.js yang berfungsi. Pada postingan kali ini, saya akan meng- unpack file DynamoDB di folder bernama nodejs-dynamodb-sample. Untuk versi detailnya, buka halaman GitHub saya: https://www.gofundme.com/adamfowleruk/nodesurvey.html. Aplikasi sampel dapat mencari dan mengambil informasi film dari DynamoDB. Kami akan menyimpan data di S3 di Amazon Web Services dan mengakses DynamoDB melalui layanan Identity and Access Management (IAM) Amazon. Untuk menggunakan layanan In-App Analytics Amazon, Anda harus terlebih dahulu mendaftar dan membuat akun. Catat tahun dan judul setiap film yang ingin di POSTING / film.
Anda dapat memasukkan bidang kunci untuk menemukan film dari tahun tertentu. Setelah itu, Anda dapat mendesain aplikasi Anda sendiri dari bawah ke atas. Anda dapat menggunakan tabel sampai selesai, tetapi Anda harus menghapusnya setelah digunakan. Kunjungi konsol DynamoDB di Amazon Web Services untuk melihat berapa banyak penyimpanan yang telah Anda gunakan sejauh ini. Tab 'Film' memungkinkan Anda melihat item dalam tabel dan metrik dari aplikasi Anda, serta perkiraan biaya bulanan per bulan di tab Kapasitas. Kode ini dapat ditemukan di halaman GitHub saya: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
MongoDB, Apache HBase, dan Cassandra adalah tiga database NoSQL yang ideal untuk penskalaan secara horizontal. Karena struktur datanya lebih horizontal, ini membuat penambahan lebih banyak server ke sistem menjadi lebih mudah, sekaligus menghilangkan kebutuhan untuk mengubahnya. Selain itu, database ini relatif baru, sehingga masih dikembangkan dan disempurnakan, yang berarti kemungkinan besar akan meningkat seiring waktu.
Mengapa Mudah Menskalakan Nosql?
Nosql mudah untuk diskalakan karena dirancang untuk dapat diskalakan secara horizontal. Ini berarti dapat menskalakan dengan menambahkan lebih banyak node ke nosql cluster . Nosql juga mudah untuk diskalakan karena dapat menangani data dalam jumlah besar dan kueri dalam jumlah besar per detik.
Aplikasi membutuhkan skalabilitas tingkat tinggi agar dapat berfungsi dengan baik. Memilih penyimpanan data dengan antarmuka pengguna yang sederhana dan efisien sama pentingnya. Perdebatan utama adalah apakah menggunakan database 'ASL' atau 'Nosql' lebih baik. Basis data NoSQL, berbeda dengan basis data SQL, populer karena mudah dibuat. Menghentikan semua operasi dalam Database NoSQL secara inheren bergantung pada sharding. Secara umum, setiap operasi data memerlukan penggunaan operator kualifikasi, yang dapat digunakan untuk mengidentifikasi node dengan data. Data disimpan di banyak mesin dan ini membuatnya sangat mudah untuk melakukan operasi data bahkan di mesin terkecil sekalipun.

Akibatnya, penyimpanan NoSQL dapat diskalakan untuk menggunakan mesin komoditas yang relatif sederhana. Diasumsikan bahwa pengguna akan merencanakan dan menyusun data sedemikian rupa sehingga dapat diambil sekaligus dari node yang sama untuk melakukan operasi tertentu pada database NoSQL. De-normalisasi data dengan cara ini juga dapat menyiratkan bahwa node siap menjalankan data yang sudah dimasak sebelumnya. Bergabung di NoSQL dimungkinkan, tetapi tidak sekuat gabungan SQL. Dalam dunia praktis NoSQL, perancang aplikasi percaya bahwa konsistensi data pada akhirnya akan terjadi. Selain menyediakan sakelar untuk menyesuaikan konsistensi di berbagai sistem NoSQL, banyak sistem NoSQL menyediakan rutinitas untuk membuat konsistensi tampak lebih menonjol. Bagian penting dari setiap keputusan arsitektur adalah mengevaluasi kasus penggunaan dan memilih penyimpanan data yang sesuai berdasarkan kasus tersebut.
Apakah Semua Basis Data Nosql Dapat Diskalakan?
Sebagai hasil dari era internet dan cloud computing, database NoSQL telah dibuat untuk memudahkan penerapan arsitektur scale-out. skalabilitas dicapai dengan menggabungkan penyimpanan data dengan pekerjaan yang diperlukan untuk memprosesnya di sejumlah besar komputer dalam arsitektur skala besar.
Sistem harus mampu menangani database yang sangat besar dengan latensi yang sangat rendah sekaligus menangani tingkat permintaan yang sangat tinggi. Ketika datang ke situs web volume besar seperti eBay, Amazon, Twitter, dan Facebook, skalabilitas dan ketersediaan tinggi sangat penting. Anda dapat menjalankan beberapa contoh server secara bersamaan dengan penskalaan horizontal.
Basis data MongoDB dapat diskalakan secara horizontal dan vertikal baik dalam skala maupun jumlah penggunanya. Di MongoDB, Anda dapat menskalakan klaster Anda secara vertikal atau horizontal dengan menambahkan lebih banyak sumber daya dan membagi data Anda menjadi potongan yang lebih kecil. Akibatnya, MongoDB adalah pilihan populer untuk aplikasi skala besar dan penyimpanan data.
Database Nosql Terbaik Untuk Penskalaan Cepat Dan Volume Data Tinggi
Basis data NoSQL lainnya dapat diskalakan untuk memenuhi kebutuhan spesifik Anda, sama seperti Anda dengan basis data lainnya. MongoDB, misalnya, adalah bahasa pemrograman yang populer karena dapat menskalakan dengan cepat dan menangani banyak data. Datastore berbasis Redis banyak digunakan karena kemampuan dan kecepatan dalam memorinya.
Penskalaan Vertikal Nosql
Basis data Nosql dapat diskalakan secara horizontal, artinya mereka dapat menangani peningkatan lalu lintas dengan menambahkan lebih banyak node ke sistem. Ini berbeda dengan penskalaan vertikal, di mana sistem diskalakan dengan menambahkan lebih banyak sumber daya ke satu node.
Setiap basis data harus diskalakan untuk menangani volume data yang dihasilkan setiap hari. Istilah "penskalaan" diklasifikasikan menjadi dua jenis: vertikal dan horizontal. Jika Anda ingin menyimpan lebih banyak data, Anda harus berinvestasi di server 2TB. Satu server menjadi semakin mahal dan lebih besar. Proses penambahan mesin ke server menghasilkan penskalaan horizontal. Dalam hal ini, data dibagi menjadi satu set dan didistribusikan ke beberapa server, atau pecahan. Karena mengikuti model de-normalisasi, tidak diperlukan satu titik kebenaran. Pendekatan ini mungkin tidak menghasilkan pembaruan informasi saat master gagal melakukan penulisan karena tidak memperbarui informasi pada replika budak saat master gagal melakukan penulisan.
Apa itu Penskalaan Vertikal di Sql?
Tujuan dari pendekatan penskalaan vertikal adalah untuk meningkatkan kapasitas satu mesin dengan meningkatkan sumber daya dari server logis yang sama. Perangkat lunak yang ada harus dimutakhirkan dengan sumber daya seperti memori, penyimpanan, dan daya pemrosesan agar dapat bekerja sebaik mungkin.
Cara Menskalakan Basis Data Secara Horizontal
Apa itu penskalaan horizontal dan bagaimana cara kerjanya? Metode penskalaan horizontal adalah salah satu yang memerlukan penambahan node tambahan untuk mengakomodasi beban. Ini sangat sulit dengan database relasional karena kesulitan dalam mendistribusikan data terkait di seluruh node.
Selain menambahkan lebih banyak instans untuk berbagi beban, penskalaan secara horizontal (atau penskalaan) memerlukan peningkatan jumlah instans aplikasi atau layanan. Sebaliknya, penskalaan vertikal memerlukan penambahan lebih banyak sumber daya ke instance, seperti daya CPU dan memori. Karena protokol yang mendasari HTTP, sebagian besar aplikasi web, dan API, mereka dapat dengan mudah diskalakan secara independen satu sama lain. Beberapa database sekarang memungkinkan Anda untuk menyinkronkan dan membagikan data tertulis Anda di antara beberapa instance. Jika lalu lintas dialihkan dengan cara ini, lebih banyak sumber daya didedikasikan untuk item yang paling sering diminta. Meskipun proxy terbalik biasanya digunakan untuk menangani permintaan HTTP, database tidak selalu digunakan untuk melakukannya. Sebagian besar database dapat diteruskan dengan perangkat lunak seperti nginx atau HAproxy, keduanya dapat dilakukan pada level TCP.
Jika proxy Anda dapat memahami cara kerja koneksi pada tingkat protokol, proxy dapat menentukan apakah replika baca tidak sinkron atau tidak dapat bereaksi meskipun koneksi jaringan aktif. Rute dapat disesuaikan tergantung beban pada replika serta jumlah koneksi. Ada beberapa server proxy yang dapat melakukan berbagai fungsi. Beberapa kemajuan telah dibuat dalam volume dan klaim yang persisten, tetapi ada juga kesulitan yang melekat jika Anda tidak memilih database yang menilai setiap instans secara setara. Karena penampung sedang dipindahkan di sekitar kluster, memulai ulang salah satu replika baca Anda akan baik-baik saja. Jika ini terjadi pada database utama , Anda tidak akan senang.