
Berbagai Jenis Cluster Komputer
Diterbitkan: 2023-02-16Dalam komputasi, cluster adalah sekelompok sistem komputer independen yang bekerja sama sehingga, dalam banyak hal, dapat dilihat sebagai satu sistem. Cluster biasanya digunakan untuk meningkatkan kinerja dan ketersediaan dibandingkan komputer tunggal, sementara biasanya jauh lebih hemat biaya daripada komputer tunggal dengan kecepatan atau ketersediaan yang sebanding. Ada berbagai jenis kluster komputer, termasuk kluster komputasi kinerja tinggi, kluster komputer yang digunakan untuk tujuan komersial, dan kluster penyimpanan. Di setiap jenis cluster, sistem komponen bekerja sama untuk melakukan tugas atau tugas bersama. Kluster komputasi kinerja tinggi (HPC) digunakan untuk aplikasi ilmiah dan teknik yang memerlukan banyak daya komputasi dan/atau penyimpanan data. Cluster ini biasanya terdiri dari sekelompok komputer komoditas, yang dihubungkan oleh jaringan area lokal (LAN) yang cepat. Komputer dalam kluster HPC biasanya menjalankan sistem operasi (OS) yang sama atau serupa dan memiliki komponen perangkat keras yang sama atau mirip. Cluster komersial digunakan untuk menjalankan aplikasi bisnis yang memerlukan ketersediaan dan/atau skalabilitas tingkat tinggi. Cluster ini seringkali terdiri dari server yang menjalankan berbagai OS dan memiliki berbagai komponen perangkat keras. Dalam banyak kasus, server di cluster komersial juga terhubung ke jaringan area penyimpanan (SAN) sehingga mereka dapat mengakses penyimpanan data umum. Cluster penyimpanan digunakan untuk menyediakan repositori penyimpanan terpusat yang dapat diakses oleh sekelompok komputer. Cluster penyimpanan biasanya terdiri dari sekelompok server penyimpanan yang terhubung ke SAN. Server di cluster penyimpanan biasanya menjalankan berbagai OS dan memiliki berbagai komponen perangkat keras.
Apa itu klaster mongodb yang dipecah dan apa gunanya menghubungkan ke klaster di MongoDB? Bagaimana cara saya terhubung ke satu atau hanya terhubung ke localhost? Medali emas diberikan dalam lencana Noob 7461. Sepuluh lencana perak dan 23 lencana perunggu diproduksi. Cluster yang direplikasi terdiri dari sepuluh server, dengan satu untuk antarmuka mongos, tiga untuk setiap set replika, dan satu untuk setiap set replika server konfigurasi. Dalam sistem replikasi, komponen digandakan agar selalu ada cadangan jika terjadi kesalahan. Semua pecahan harus merupakan replika agar dapat diproduksi.
Kluster mongodb, misalnya, biasanya digunakan untuk mendeskripsikan klaster yang dipecah di MongoDB. Sebuah sharded mongodb melayani fungsi-fungsi berikut: Menskalakan membaca dan menulis dari beberapa node. Karena setiap node tidak menangani keseluruhan kumpulan data, Anda hanya dapat mempartisi data ke dalam region di shard.
Cluster database , seperti namanya, adalah kumpulan database yang dapat dijalankan oleh satu instance dari server database yang sedang berjalan. Postgres, yang berarti database “default” di PostgreSQL, akan dimasukkan sebagai database default di cluster database setelah dibuat.
Kluster MongoDB juga dapat disebut sebagai "kumpulan replika" atau "kluster pecahan". Dalam kumpulan replika, beberapa server membawa salinan dari data yang sama. Node dalam set replika biasanya tiga. Saat aplikasi klien melakukan operasi apa pun pada sebuah node, semua pembacaan dan penulisan dikirim ke node tersebut; jika terjadi kesalahan, dua node sekunder melindunginya.
Apakah Cluster Dan Database Sama?
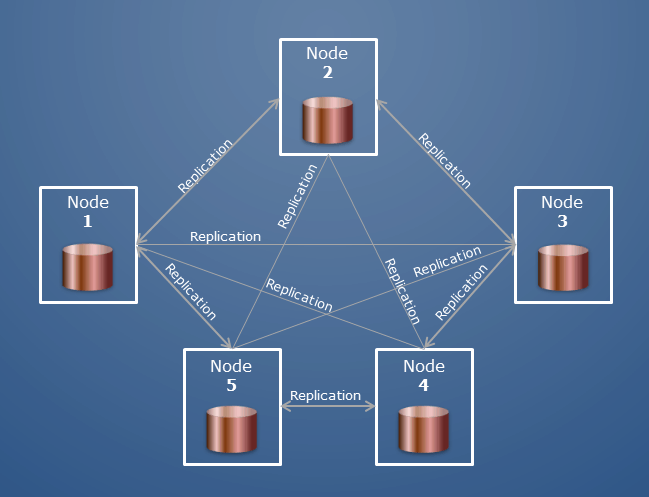
Ada beberapa cluster host yang membentuk sebuah cluster. Host dari klaster yang dipecah diklasifikasikan dalam berbagai peran. Database adalah kumpulan dari koleksi; di Oracle, itu akan setara dengan database dan aschema.
Cluster database adalah kumpulan server atau instance yang menghubungkan satu database ke database lainnya. Pengelompokan basis data digunakan oleh server karena berbagai alasan, yang utama adalah redundansi data, penyeimbangan muatan, ketersediaan tinggi, serta pemantauan dan otomatisasi. Akibatnya, jika komputer gagal, semua data kami akan tersedia untuk orang lain, memberi kami keuntungan redundansi data. Dengan pengelompokan, ada peluang untuk mengotomatiskan banyak proses database sambil membuat aturan untuk mengidentifikasi potensi masalah. Dalam arsitektur cluster, semua permintaan dialihkan ke sejumlah komputer, yang masing-masing mampu menangani permintaan dan memproduksinya untuk pengguna. Kluster failover atau ketersediaan tinggi mereplikasi server dan mengonfigurasi ulang perangkat keras untuk memastikan ketersediaan layanan. Jenis kluster ini menguntungkan bagi pengguna komputer yang bergantung sepenuhnya pada sistem mereka. Tujuan cluster berkinerja tinggi adalah untuk meningkatkan kapasitas jaringan sekaligus meningkatkan kinerja.
Dalam sistem terdistribusi Hadoop, node bertindak sebagai pusat penyimpanan dan pemrosesan data. Perbedaan utama antara cluster dan server adalah bahwa cluster mempekerjakan banyak node yang berkomunikasi satu sama lain untuk melakukan serangkaian operasi. Sebuah cluster berisi sejumlah node yang akan melakukan serangkaian operasi. Sistem terdistribusi Hadoop dapat mendukung hingga 10.000 database. Hasil kueri serupa dapat diperoleh saat data dari beberapa tabel dalam database yang sama digabungkan menjadi kueri dari beberapa database dalam kluster yang sama.
Manfaat Klaster
Menggunakan cluster, Anda dapat dengan mudah mengelola banyak database dengan menyediakan penyimpanan tabel dan kolom yang seragam di semua database tersebut. Ini meningkatkan kinerja dan integritas data, dan dengan demikian membuat sistem lebih efisien.
Di mana Nama Cluster Di Mongodb?
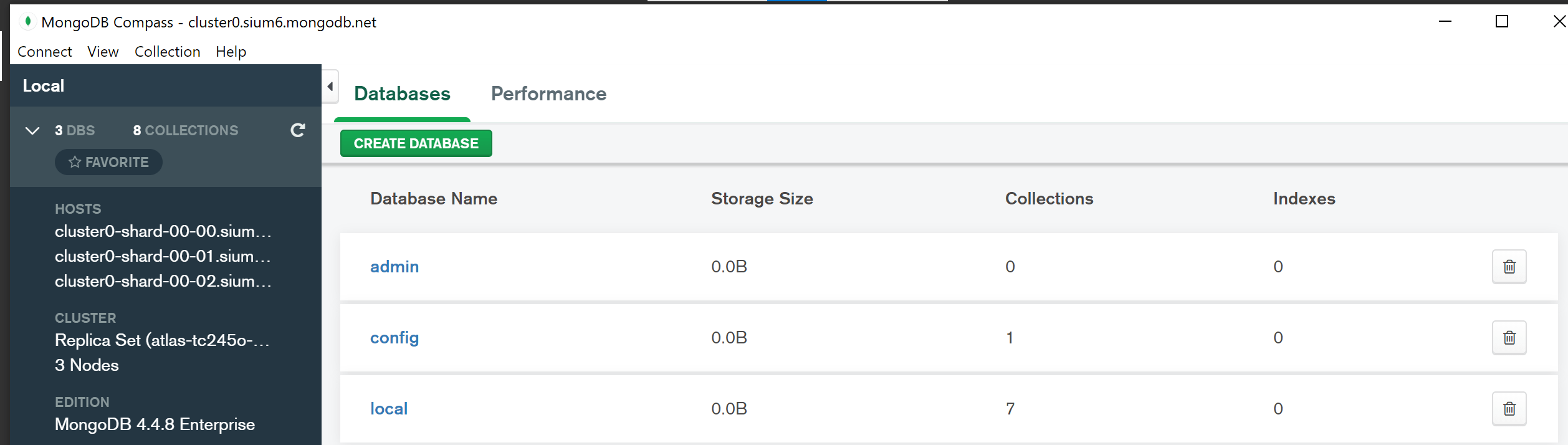
Tidak ada jawaban pasti untuk pertanyaan ini karena nama cluster dapat ditemukan di tempat yang berbeda tergantung pada jenis cluster MongoDB yang digunakan. Misalnya, dalam kumpulan replika, nama klaster biasanya disimpan di koleksi local.system.replset, sedangkan di klaster sharded biasanya ditemukan di koleksi config.shards.
MongoDB Atlas adalah penawaran MongoDB-as-a-Service NoSQL Database-as-a-Service yang tersedia di cloud publik Microsoft Azure, Google Cloud Platform, dan Amazon Web Services. Anda dapat membuat cluster MongoDB yang berfungsi dalam hitungan menit menggunakan browser web favorit Anda dengan mengeklik tautan untuk menyiapkannya. Tidak perlu menginstal perangkat lunak di workstation Anda untuk terhubung ke web melaluinya, dan Anda dapat menggunakan antarmuka web untuk melakukannya. Ketika kumpulan replika MongoDB digunakan bersamaan dengan beberapa server MongoDB, redundansi data dan ketersediaan tinggi terjamin. Cluster MongoDB memiliki kapasitas operasi baca tambahan, yang memungkinkannya untuk mengarahkan klien ke server tambahan. Dalam replikasi, satu atau lebih anggota set replika direplikasi secara asinkron dari oplog node primer ke sekunder, memungkinkan set replika berfungsi meskipun ada potensi kegagalan anggotanya. Di MongoDB, Anda dapat melakukan operasi baca dan tulis tambahan selain perintah input dan output standar.
Dalam kebanyakan kasus, simpul utama adalah sumber dari semua operasi baca, tetapi perutean ke simpul sekunder dapat dikonfigurasi. Risiko data yang berpotensi basi lebih tinggi ketika node terdekat adalah node sekunder. Agar penulisan berhasil disebarkan di seluruh kluster, Anda harus menyertakan opsi untuk menulis data ke set replika MongoDB. Sebagai bagian dari proses ini, properti tulis harus ditambahkan untuk disisipkan. Saat permintaan tulis diterima, klaster diminta untuk mengakui bahwa ia telah berhasil di sebagian besar node pembawa data. Konfigurasi klaster sharded memungkinkannya untuk dikonfigurasi sebagai kumpulan replika juga. Satu set replika berisi proses mongod primer dan sekunder. Jika master gagal, disarankan agar jumlah proses ini ganjil untuk memastikan bahwa mayoritas dilakukan.
Cluster MongoDB , seperti namanya, adalah cluster node yang bekerja sama untuk menyimpan dan mengelola data. Saat membuat klaster MongoDB, Anda menentukan berapa banyak node yang akan disertakan dan untuk apa mereka harus dikonfigurasi. Anda dapat menghubungkan aplikasi Anda ke klaster MongoDB Anda dengan Node setelah dibuat. Kompas MongoDB dapat dianggap sebagai driver untuk perpustakaan MongoDB JS atau driver PyMongo untuk MongoDB. Keuntungan utama menghubungkan aplikasi Anda ke cluster adalah dapat membaca dan menulis data ke cluster. Dengan Kompas MongoDB, Anda dapat menjelajahi, memodifikasi, dan memvisualisasikan data Anda dalam berbagai cara. Contoh bagaimana Anda dapat melihat data Anda dapat ditemukan di kisi, yang memungkinkan Anda untuk mengamati bagaimana data berubah dari waktu ke waktu dan siapa yang mendistribusikan data di klaster Anda.
Dimana Cluster Di Mongodb Atlas?
Tidak ada satu jawaban pasti untuk pertanyaan ini karena lokasi klaster di MongoDB Atlas dapat bervariasi tergantung pada sejumlah faktor, termasuk wilayah geografis tempatnya berada dan kebutuhan khusus aplikasi yang didukungnya. Namun, secara umum, cluster di MongoDB Atlas dapat ditemukan di bagian “Clusters” di konsol MongoDB Atlas.
Sebuah cluster dapat berupa kumpulan replika atau kumpulan pecahan. Jumlah total node setiap proyek dibatasi oleh batasan tertentu berdasarkan rentang fungsinya di seluruh wilayah. Setiap proyek Atlas dapat menerapkan hingga 25 database. Silakan hubungi administrator basis data untuk pertanyaan apa pun tentang batas penerapan basis data. TLS versi 1.2 adalah versi TLS default untuk cluster yang dibuat setelah 1 Juli 2020.

Apa Itu Cluster Di Mongodb
Di MongoDB, cluster adalah sekelompok server database yang menyimpan salinan data yang sama. Setiap server dalam cluster disebut sebagai node. Sebuah cluster dapat memiliki satu atau lebih node.
Untuk apa pengelompokan basis data? Proses menghubungkan beberapa server atau instance ke satu database disebut sebagai koneksi SQL. Di MongoDB, klaster bisa berupa kumpulan replika atau klaster pecahan, bergantung pada jenis MongoDB. Saya akan membahas masing-masing aspek berbeda dari kelompok ini secara lebih mendalam di paragraf berikut. Karena penyeimbangan muatan MongoDB dan jumlah mesin, ia memiliki tingkat ketersediaan yang tinggi. Sebuah cluster dapat digunakan untuk mengotomatiskan banyak proses database sementara juga memungkinkan pembuatan aturan untuk mengingatkan potensi masalah. Database MongoDB dapat dibagi menjadi dua jenis: kumpulan replika dan cluster sharding.
Data disimpan di beberapa mesin dalam Shard. Metode MongoDB dalam menyediakan skalabilitas data didasarkan pada hal ini. Ini mengurangi jumlah waktu yang diperlukan untuk mengelola data dalam jumlah besar. Karena banyaknya data yang disediakan oleh replika, aplikasi terdistribusi juga dapat memanfaatkannya.
Masalah kinerja dan konflik data dapat terjadi jika beberapa proyek Atlas diterapkan di kluster yang sama. Atlas merekomendasikan agar Anda hanya menggunakan satu klaster gratis per proyek Atlas. Alat pengelompokan data yang baik diperlukan dalam berbagai analisis data dan aplikasi penambangan data. Untuk menghindari potensi masalah kinerja dan konflik data dalam proyek Atlas, Atlas menyarankan agar Anda hanya menggunakan satu klaster gratis per proyek.
Arsitektur Cluster Mongodb
Kluster MongoDB adalah sekelompok server MongoDB yang bekerja bersama untuk menyimpan data Anda. Setiap server dalam cluster disebut node. Sebuah cluster dapat memiliki sejumlah node. Sebuah kluster terdiri dari kumpulan replika, yang merupakan grup node yang masing-masing memiliki salinan data Anda. Kumpulan replika memiliki setidaknya tiga node, sehingga jika satu node mati, data Anda masih tersedia.
Arsitektur kumpulan replika merupakan faktor penting dalam kapasitas dan kapabilitas MongoDB. Cluster MongoDB biasanya didistribusikan dalam tiga replika node. Pemulihan basis data setelah bencana harus selalu stabil, terutama setelahnya. Salah satu cara terbaik untuk menerapkan klaster sharded adalah dengan menggunakan strategi replikasi. Data yang terkandung dalam Shard Keys harus didistribusikan dengan cara yang sama. Anda harus menskalakan basis data secara horizontal dan mengurangi jumlah operasi yang dapat dilakukan pada satu instans. Dengan sedikit shard, operasi baca dan tulis dapat menjadi lamban karena fakta bahwa jumlah shard membatasi jumlah operasi.
Setiap bagian data dalam Shard terdiri dari subkumpulan bagian tersebut berdasarkan kumpulan kriteria tertentu. Biasanya jumlah minimum pecahan yang diperlukan untuk mencapai signifikansi pecahan adalah dua. Kueri pencar-pencar sebaiknya hanya digunakan jika dapat digunakan secara bersamaan satu sama lain di semua shard. Saat memilih sebuah klaster, sangat penting untuk memiliki setidaknya tujuh anggota pemungutan suara agar proses pemilihan menjadi sesederhana mungkin. Jika Anda hanya memiliki tujuh atau lebih sedikit anggota pemungutan suara tetapi jumlah anggota yang sama, wasit harus digunakan. Arbiter tidak menyimpan salinan data, menghasilkan lebih sedikit sumber daya yang diperlukan untuk memproses data. Menggunakan nama host DNS logis daripada alamat IP lebih disukai saat mengonfigurasi anggota set replika atau anggota cluster yang dipecah. Karena beberapa koneksi set replika grup driver adalah dengan nama set replika, nama ini harus digunakan secara terpisah untuk set. Distribusi geografis node set replika sangat ideal untuk mengatasi redundansi redundansi dan memastikan toleransi kesalahan jika salah satu pusat data tidak ada.
Nama Cluster Mongodb
Kluster MongoDB adalah sekelompok server MongoDB yang bekerja sama untuk menyediakan ketersediaan dan skalabilitas tinggi. Sebuah cluster biasanya memiliki server utama yang bertindak sebagai server master, dan satu atau lebih server sekunder yang bertindak sebagai budak. Server utama berisi data, dan server sekunder menyalin data dari server utama.
Program database berorientasi dokumen dibuat untuk penyimpanan volume tinggi dengan bantuan MongoDB, sebuah program lintas platform. MongoDB, program database NoSQL, diklasifikasikan demikian karena menggunakan dokumen bergaya JSON dengan skema opsional. Anda dapat meningkatkan performa dengan menginstal database Anda di pusat data yang sama dengan sumber daya DigitalOcean lainnya. Wilayah tersebut memiliki satu atau beberapa pusat data, dan masing-masing memiliki jaringan VPC sendiri. Jenis mesin, jumlah, dan ukuran node database semuanya dapat dipilih. Dengan kata lain, Anda dapat menambahkan hingga dua node siaga ke cluster Anda. Tambahkan nama proyek, lengkapi, dan gunakan tag apa pun yang ingin Anda gunakan saat membuatnya. Sebuah cluster dapat memakan waktu hingga lima menit untuk diselesaikan.
Kekuatan Gugus Atlas Mongodb
MongoDB Atlas Cluster adalah solusi database-as-a-service NoSQL di cloud publik yang berjalan di MongoDB. Ini adalah platform data yang tangguh dan dapat diskalakan yang memungkinkan Anda membuat dan menerapkan aplikasi dengan cepat. Dengan menggunakan MongoDB Atlas Cluster, Anda dapat terhubung dengan aman ke MongoDB dari lokasi mana pun di dunia.
Cara Membuat Cluster Di Mongodb
Gunakan langkah-langkah berikut untuk membuat cluster di MongoDB:
1. Pilih topologi penerapan.
2. Pilih jenis kumpulan replika yang ingin Anda terapkan.
3. Pilih jumlah set replika yang ingin Anda gunakan.
4. Konfigurasikan set replika.
5. Sambungkan ke router mongos.
6. Konfigurasikan kunci beling.
7. Menambahkan pecahan ke kluster.
8. Verifikasi bahwa cluster sudah beroperasi.
MongoDB Atlas adalah tier gratis dari MongoDB, yang merupakan layanan basis data cloud MongoDB yang dikelola sepenuhnya. Layanan ini dirancang untuk beban kerja perusahaan, serta cluster global . Anda tidak perlu membuat akun dengan Amazon Web Services (AWS), Google Cloud Platform, atau Microsoft Azure. Ini akan meminta Anda membuat akun administrator untuk mengakses layanan. Untuk mengakses layanan, cluster harus ditautkan ke alamat IP. Pengaturan keamanan default MongoDB Atlas mencegah semua koneksi eksternal. Kata sandi Anda tidak boleh memiliki karakter khusus dan hanya karakter alfanumerik untuk memudahkan koneksi ke Studio 3T. Saat membuat string koneksi untuk MongoDB, karakter khusus harus dikodekan. Pada Langkah 1, pilih Java dari daftar drop-down DRIVER dan kemudian dari daftar drop-down VERSION. Jika Anda memilih driver dan versinya, layanan akan secara otomatis memperbarui string koneksi pada Langkah 2.
Mongodb Clustering: Opsi Hebat Untuk Throughput Permintaan Tinggi
Dengan menggunakan pengelompokan MongoDB , Anda dapat memenuhi persyaratan throughput, ketersediaan, dan throughput yang tinggi untuk lingkungan yang besar. Kluster MongoDB dapat dikonfigurasi untuk mendukung berbagai jenis kumpulan replika MongoDB, dari penyiapan simpul tunggal sederhana hingga konfigurasi multi simpul yang sangat tersedia.
Tutorial Gugus Mongodb
Kluster MongoDB adalah sekelompok server MongoDB yang bekerja bersama untuk menyimpan data Anda. Cluster MongoDB bisa sekecil satu server atau sebesar ratusan server. Saat Anda membuat klaster MongoDB, Anda menentukan jumlah server (node) yang Anda inginkan di klaster. Setiap node di cluster MongoDB menyimpan subset data Anda. Kluster MongoDB dirancang agar dapat diskalakan dan menyediakan ketersediaan tinggi. Anda dapat menambahkan node ke cluster kapan saja untuk meningkatkan kapasitasnya atau mengganti node yang gagal. Saat Anda menghapus node dari cluster, node lain mendistribusikan ulang data dari node yang dihapus sehingga data masih terdistribusi secara merata di seluruh cluster.
Panduan Mudah Hevo untuk MongoDB Clustering adalah langkah pertama. Ketika database terlalu kecil atau terlalu lambat untuk menjalankan sistem, operasi organisasi akan berlanjut. MongoDB memiliki banyak fitur canggih yang dirancang untuk cloud, seperti sharding dan replikasi. MongoDB memungkinkan untuk menyimpan banyak salinan dari data yang sama, membuatnya sangat mudah diakses. Jika satu server gagal, data dari server lain dapat segera diambil. Anda dapat mengotomatiskan, menyederhanakan, dan memperkaya proses replikasi data dengan menggunakan Hevo Data. Replikasi data sederhana dan tidak merepotkan untuk digunakan saat Anda memiliki akses ke uji coba gratis 14 hari kami.
Untuk mengatur klaster MongoDB, Anda harus menginstal ketiga komponen yang diperlukan terlebih dahulu. Dengan platform otomatis tanpa kode Hevo, Anda dapat melacak semua yang perlu Anda lakukan untuk pengalaman replikasi data yang lancar. Untuk memastikan ketersediaan maksimum, beberapa server atau router konfigurasi harus ada. Saat router menentukan shard tempat data disimpan, router mengirimkan permintaan ke cluster yang sesuai. Dalam proses membangun klaster MongoDB, langkah-langkah berikut diperlukan untuk menambahkan shard ke dalamnya. Dalam konfigurasi berkerumun, port 27018 digunakan sebagai default untuk server shard. Artinya ini adalah server pecahan daripada server konfigurasi.