
Faktor Pembeda Hadoop: Skalabilitas Sumber Terbuka dan Toleransi Kesalahan
Diterbitkan: 2022-11-18Hadoop adalah kerangka kerja perangkat lunak sumber terbuka untuk penyimpanan terdistribusi dan pemrosesan kumpulan data besar di seluruh kelompok komputer. Ini dirancang untuk meningkatkan dari satu server ke ribuan mesin, masing-masing menawarkan komputasi dan penyimpanan lokal. Alih-alih mengandalkan perangkat keras untuk menghadirkan ketersediaan yang tinggi, kerangka kerja ini dirancang untuk mendeteksi dan menangani kegagalan pada lapisan aplikasi. Hadoop adalah database nosql karena menggunakan arsitektur yang sama sekali berbeda dari database relasional tradisional. Hadoop dirancang untuk menskalakan secara horizontal, yang artinya dapat diskalakan untuk mengakomodasi lebih banyak data dengan menambahkan lebih banyak server komoditas ke kluster. Hadoop juga dirancang untuk toleran terhadap kesalahan, artinya jika server di cluster mati, sistem dapat terus berfungsi tanpa server tersebut.
Hadoop tidak digunakan untuk menyimpan data, juga tidak memerlukan penggunaan penyimpanan relasional; sebaliknya, ini digunakan untuk menyimpan data dalam jumlah besar di server terdistribusi. Basis data Hadoop adalah jenis data daripada sistem perangkat lunak yang memungkinkan komputasi paralel masif. Ini adalah jenis database NoSQL yang mengikat (seperti HBase) yang memungkinkan pengguna untuk meminta dan mencari database dalam variasi terikat. RDBMS, dalam bentuknya saat ini, tidak akan mampu bersaing dengan Hadoop karena mampu mengelola data relatif dan transaksional. Hadoop memiliki kemampuan untuk menangani semua jenis data, baik terstruktur, semi-terstruktur, atau tidak terstruktur, dan mendukung berbagai metode. Analitik data besar memberi bisnis keunggulan kompetitif dunia nyata dengan memberikan wawasan yang lebih dalam. Hadoop, sebagai layanan, mendukung penggunaan pemrosesan analitik online (OLAP) dalam pemrosesan data. Penting untuk diingat bahwa kecepatan proses data ditentukan oleh jumlah permintaan data. Anda dapat menggunakan Hadoop jika Anda tidak menginginkan transaksi ACID atau dukungan OLAP, misalnya.
Basis data Hadoop dan dalam memori adalah dua teknologi yang sama sekali berbeda yang tumpang tindih. Mereka tidak sama, tetapi mereka setuju pada beberapa hal.
Aplikasi analitik yang menggunakan SQL-on-Hadoop mengombinasikan metode kueri bergaya SQL dengan elemen kerangka data Hadoop yang lebih baru . SQL-on-Hadoop memungkinkan pengembang perusahaan dan analis bisnis untuk berkolaborasi pada cluster Hadoop dengan kueri yang familiar dengan SQL.
Ini adalah database NoSQL yang menyediakan sarana untuk menyimpan dan mengambil data. Non-relasional/non-SQL adalah salah satu istilah yang umum digunakan di ruang ini.
Data dikelola dengan berbagai cara oleh Hadoop dan SQL. SQL adalah bahasa pemrograman, sedangkan Hadoop adalah kerangka komponen dalam perangkat lunak. Kedua alat tersebut berguna untuk data besar, tetapi memiliki kekurangan. Platform Hadoop dapat menangani kumpulan data yang jauh lebih besar, tetapi hanya menulis data satu kali.
Apa Perbedaan Antara Hadoop Dan Nosql?
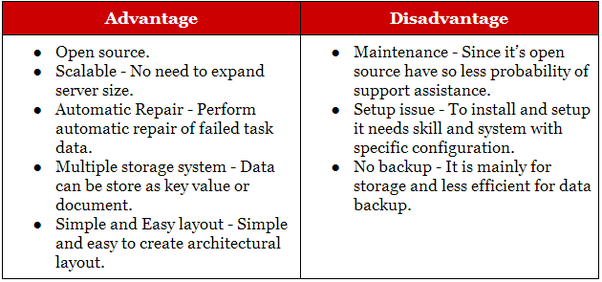
Hadoop cocok untuk aplikasi pengarsipan analitis dan historis, sedangkan NoSQL ideal untuk beban kerja operasional yang melengkapi rekan relasionalnya. Basis data NoSQL dimulai sebagai basis data penyimpanan nilai kunci, tetapi kemudian, basis data dokumen/json dan grafik bergabung dengannya.
Pemrosesan waktu nyata, data besar, dan data tidak terstruktur hanyalah beberapa skenario di mana teknologi NoSQL dapat digunakan. Hasilnya, beberapa tantangan ini, seperti skalabilitas dan ketersediaan, dapat diatasi. Basis data NoSQL memiliki sejumlah keunggulan dibandingkan basis data relasional tradisional. Mereka dapat memproses kumpulan data dengan cara yang jauh lebih cepat dan lebih terukur dari sebelumnya. Sistem administrasi basis data juga menggunakan lebih sedikit pengetahuan dan keahlian daripada basis data tradisional , yang membuatnya lebih mudah digunakan. Database NoSQL memiliki berbagai keunggulan dibandingkan database relasional tradisional. Hal terpenting untuk dipertimbangkan adalah apakah Anda memerlukannya untuk pemrosesan waktu nyata dan kumpulan data besar.
Basis Data Nosql Adalah Pilihan Yang Lebih Baik Untuk Bisnis Dengan Beban Kerja Data Besar
Jika beban kerja data Anda lebih fokus pada analisis dan pemrosesan data dalam jumlah besar yang bervariasi dan tidak terstruktur, seperti Big Data, database NoSQL adalah pilihan yang lebih baik. Berbeda dengan database relasional, database NoSQL tidak bergantung pada model skema tetap. RDBMS lebih fleksibel daripada RDBMS tradisional dalam hal menyimpan, memproses, dan mengelola data, menjadikannya pilihan yang lebih baik untuk bisnis yang memerlukan kemampuan untuk mengakses data dalam jumlah besar dengan cepat dan memiliki kebutuhan untuk menyimpannya tanpa batas.
Apakah Big Data Sql Atau Nosql?

Jika beban kerja data Anda terutama berkaitan dengan pemrosesan cepat dan analisis data beragam dan tidak terstruktur dalam jumlah besar, seperti Big Data, NoSQL adalah taruhan terbaik Anda. Model database NoSQL unik karena tidak bergantung pada struktur skema yang sama dengan database relasional.
Bukan lagi pertanyaan apakah big data akan meningkatkan manufaktur; ini masalah waktu. Dalam data besar, tersedia data terstruktur dan tidak terstruktur yang sangat banyak, beragam, dan kompleks. Sensor, kamera di lantai produksi, dan perangkat konsumen semuanya dapat digunakan untuk mengumpulkan data besar di bidang manufaktur. Karena sebagian besar data manufaktur tidak terstruktur, arsitektur NoSQL tidak dapat bersaing dengan pendekatan kaku seperti SQL. Database NoSQL tidak memerlukan skema untuk menyimpan data dalam tabel database yang sama, memungkinkan pengguna untuk menyimpan data dalam berbagai struktur. Garis pemisahan perusahaan dapat ditentukan oleh seberapa banyak data yang ingin digunakan. Transaksi harus mematuhi empat prinsip operasi dasar agar dianggap sebagai transaksi basis data relasional.
Karena sistem NoSQL dan sistem cloud dapat diintegrasikan, sebaiknya gunakan kerangka komputasi cloud untuk mendukung sistem NoSQL. Optimasi proses manufaktur real-time melalui NoSQL dapat dilakukan melalui integrasi dengan Manufacturing Execution Systems (MES). Keberhasilan ini dimungkinkan dengan menggunakan analitik data besar untuk menghasilkan respons yang lebih cepat terhadap perubahan kondisi. MongoDB adalah basis data NoSQL yang bagus karena mudah disiapkan dan dapat digunakan untuk analitik. Penggunaan arsitektur database dengan respons lebih cepat seperti NoSQL memungkinkan manajemen melakukan simulasi yang lebih baik, memungkinkan mereka membuat keputusan produk yang lebih baik di dunia nyata. Basis data B2B rentan terhadap serangan lintas situs, serta serangan injeksi dan serangan brute force. Serangan injeksi terjadi saat penyerang menambahkan data ke perintah kueri NoSQL atau pernyataan penyimpanan.

Sektor manufaktur sangat memperhatikan keamanan arsitektur NoSQL. Jika penolakan serangan layanan atau serangan injeksi berhasil disampaikan, pabrikan mungkin dapat memodifikasi spesifikasinya. Karena itu, pesaing mungkin dapat memperoleh keuntungan di pasar yang sangat kompetitif.
Proses bisnis yang mengandalkan data real-time menjadi lebih umum karena perusahaan mencari cara untuk meningkatkan efisiensi dan daya tanggap mereka terhadap kebutuhan pelanggan. Database NoSQL berbasis cloud, seperti Cloud Bigtable, memberikan cara yang cepat dan efisien untuk menyimpan dan mengakses kumpulan data besar, menjadikannya solusi yang sangat baik untuk jenis aplikasi ini.
Cloud Bigtable adalah layanan database NoSQL yang dikelola sepenuhnya dan menawarkan waktu aktif 99,999%. Ini sangat ideal untuk beban kerja analitis dan operasional karena memiliki kecepatan pengumpanan data yang tinggi dan mudah untuk menaikkan dan menurunkan skala. Hasilnya, ini adalah pilihan yang sangat baik untuk pemrosesan data waktu nyata dalam aplikasi seperti game seluler dan analitik ritel.
Apakah Nosql Database Terbaik Untuk Data Besar?
MongoDB, misalnya, adalah pilihan yang sangat baik untuk menyimpan data dalam jumlah besar. Mereka memungkinkan berbagai skenario pemrosesan yang gesit dan berkinerja tinggi. Selain itu, data tidak terstruktur disimpan dalam database NoSQL di beberapa node pemrosesan dan di beberapa server. Akibatnya, database NoSQL telah menjadi pilihan default dari beberapa gudang data terbesar di dunia. Database mana yang terbaik untuk data besar? Ketika sampai pada pertanyaan ini, tidak mungkin untuk memprediksi database mana yang terbaik untuk data besar karena kebutuhan organisasi yang berbeda-beda. Amazon Redshift, Azure Synapse Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2, dan banyak database lainnya adalah pilihan paling populer untuk penyimpanan data besar.
Apakah Hadoop Sebuah Basis Data
Hadoop adalah sistem file terdistribusi dan kerangka kerja untuk menjalankan aplikasi pada kelompok besar perangkat keras komoditas. Hadoop bukan database.
Hadoop, kerangka kerja sumber terbuka, memungkinkan penyimpanan dan pemrosesan kumpulan data besar yang efisien. Tabel Hive dan Imperative dapat dibuat menggunakan file teks dalam HDFS. Ini mendukung tiga format file utama: file urutan, file data Avro, dan file Parket. Serangkaian byte diwakili oleh serialisasi data sebagai unit memori. Avro, kerangka serialisasi data yang efisien, didukung secara luas oleh Hadoop dan ekosistemnya.
Penggunaan file teks sebagai format penyimpanan untuk tabel Hive dan Implisit menyederhanakan pengelolaan dan manipulasi data. Akibatnya, ini adalah pilihan yang baik untuk pemrosesan batch atau menyimpan data dalam berbagai format. Selain itu, serialisasi data melalui Avro memungkinkan penyimpanan dan pengambilan data yang efisien dan nyaman. Hasilnya, ini merupakan pilihan yang baik untuk menyimpan data dalam berbagai format atau melakukan pemrosesan paralel.
Hadoop Vs Nosql
Hadoop menangani data besar untuk sekelompok perangkat keras komoditas. Jika fungsionalitas tidak memenuhi kebutuhan Anda atau tidak berfungsi, itu dapat diubah. Ini disebut sebagai NoSQL, dan ini adalah jenis sistem manajemen basis data yang menyimpan data terstruktur, semi-terstruktur, dan tidak terstruktur.
MongoDB, sebagai database NoSQL (Not Only SQL), dibuat pada tahun 2007 sebagai hasil pengembangan C++. Hadoop adalah kumpulan program perangkat lunak sumber terbuka yang terutama ditulis di Java untuk pemrosesan data yang besar. Platform ini juga menyertakan pencarian teks lengkap, alat analitik lanjutan, dan bahasa kueri yang mudah digunakan. Meskipun Hadoop terkenal karena kemampuannya untuk menyimpan dan memproses data dalam jumlah besar, ia juga melakukannya dalam batch kecil. MongoDB menyediakan berbagai alat pemrosesan data real-time. Konektor MongoDB untuk alat eksternal, seperti Kafka dan Spark, mempermudah penyerapan dan pemrosesan data. Dalam hal penanganan data, Hadoop dan MongoDB memberikan berbagai keuntungan dibandingkan database tradisional. Hadoop adalah alat yang sangat baik untuk menangani struktur data besar karena sistem file terdistribusi. MongoDB adalah satu-satunya database yang dapat digunakan sebagai pengganti database tradisional.
Apakah Spark Database Nosql
Dalam dokumentasi disebutkan bahwa NoSQL DataFrame adalah Spark DataFrame berdasarkan format Spark untuk menyimpan data. Berbeda dengan sumber data sebelumnya, yang satu ini mendukung pemangkasan dan pemfilteran data (predikat pushdown), memungkinkan kueri Spark untuk meminta lebih sedikit data dan hanya memuat data yang diperlukan sesuai kebutuhan.
Sangat penting untuk mempertahankan kesadaran taktis saat menggunakan database Apache Spark dan NoSQL ( Apache Cassandra dan MongoDB) bersama-sama dalam sebuah aplikasi. Blog ini berfokus pada cara menggunakan Apache Spark di aplikasi NoSQL. CassandraLand dan MongoLand di TCP/IP sPark adalah dua wahana paling populer, dan merupakan tempat yang tepat untuk dikunjungi jika Anda menyukai taman hiburan. Saat mencari data Departemen Energi, aplikasi Spark kami mulai memutar rodanya. Berikut adalah pelajaran singkat tentang betapa pentingnya urutan kunci Cassandra dalam melakukan kueri. Ada juga roller coaster Partitioner di CassandraLand. Pelanggan yang menikmati roller coaster dapat membagikan informasi mereka dengan operator wahana sehingga mereka dapat melacak siapa yang menaikinya setiap hari.
Pelajaran pertama di MongoDB Pelajaran 1 adalah mengelola koneksi MongoDB dengan benar. Saat Anda perlu memperbarui informasi tentang status keanggotaan taman baru Departemen Energi, indeks Mongo sangat berguna. Sebagai pelanggan MongoDB atau Spark, Anda harus memelihara koneksi dan indeks yang tepat jika terjadi pembaruan sistem.