
Format Data HDF5: Opsi Menarik Untuk Menyimpan Dan Mengelola Kumpulan Data Besar
Diterbitkan: 2023-02-13HDF5 adalah format data yang dirancang untuk menyimpan dan mengelola kumpulan data yang besar dan kompleks. Ini sering digunakan dalam aplikasi ilmiah dan teknik, dan popularitasnya meningkat dalam beberapa tahun terakhir. HDF5 bukan database, tetapi dapat digunakan untuk menyimpan data dalam format hierarki yang mirip dengan sistem file. Ini menjadikan HDF5 pilihan yang menarik untuk aplikasi yang perlu menyimpan dan mengelola data dalam jumlah besar.
Anda dapat mengekstrak metadata dan data mentah dari file HDF5 dan netCDF4 dan menggunakan streaming Hadoop untuk menganalisis data Hadoop menggunakan Hadoop Distributed File System (HDFS) HDF5 Connector Virtual File Driver (VFD).
Apakah Hdf5 Sebuah Basis Data?
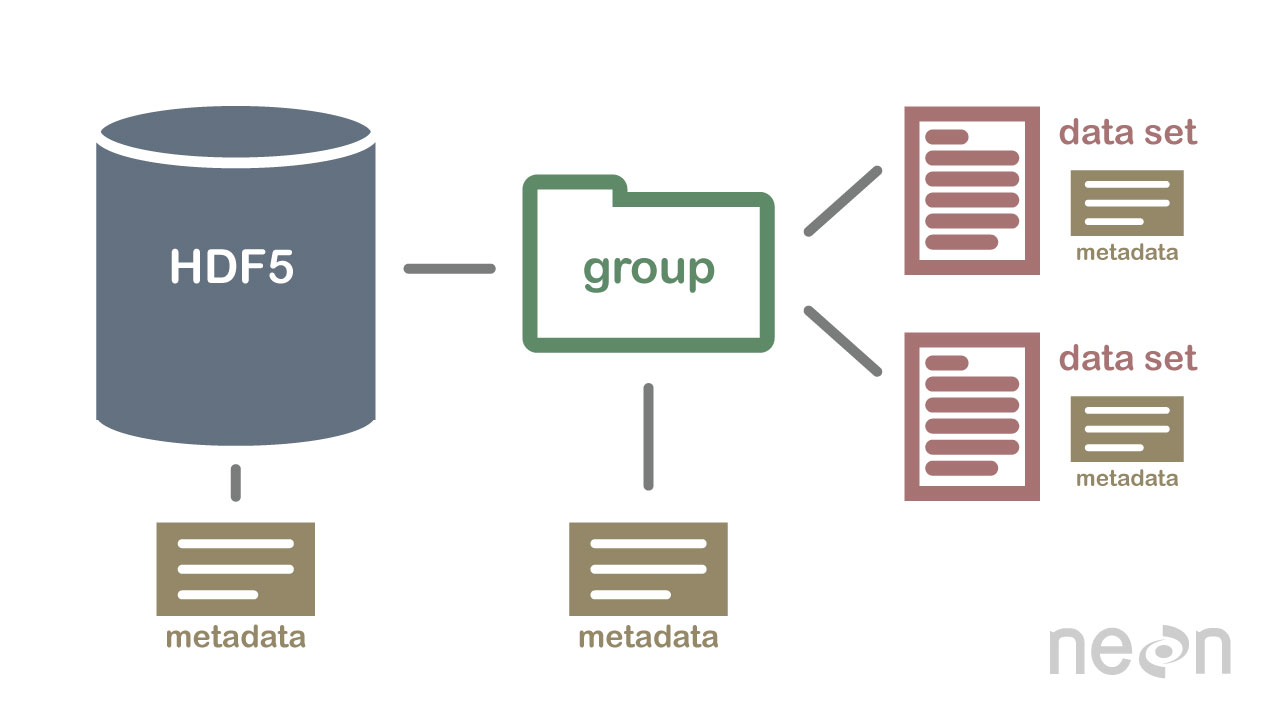
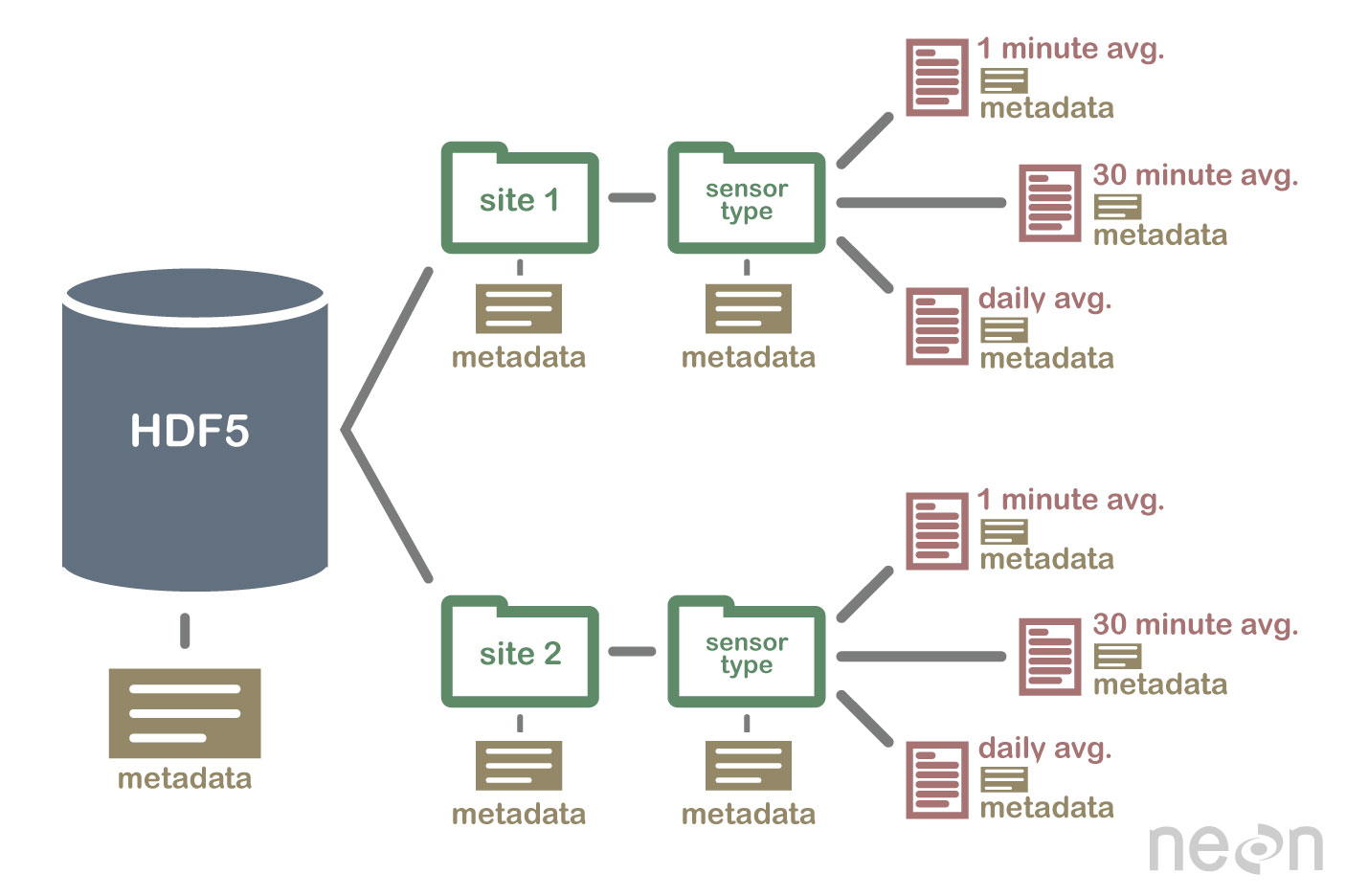
HDF5 bukan database, tetapi dapat digunakan untuk menyimpan data dalam struktur hierarkis, mirip dengan sistem file. HDF5 dapat digunakan untuk menyimpan data dalam berbagai format, termasuk teks, gambar, dan data biner .
Data dalam format hierarkis (HDF5) sangat berguna dalam penelitian ilmiah. Sistem file HDF5, karena mirip dengan sistem file dengan cara yang sangat efisien, adalah format yang sangat baik. Jika menyangkut data yang disandikan dalam format ini, mungkin sulit untuk mengaksesnya. Panduan ini akan memandu Anda tentang bagaimana Apache Drill dapat membantu Anda mengakses dan membuat kueri set data HDf5 dengan mudah. Drill memiliki akses ke file HDF5 individual melalui opsi defaultPath. Ini dilakukan dengan mengeksekusi fungsi table() secara langsung selama waktu kueri atau melalui konfigurasi. Hasil dari kueri ini dapat ditemukan pada tabel di bawah ini. Drill kemudian dapat memilih kolom dan memfilternya satu per satu, memfilter, menggabungkan, atau menggabungkannya dengan data lain yang dapat dikueri.
Spesifikasi HDF5 mendefinisikan format file untuk menyimpan array data. Array data dapat terdiri dari semua jenis data, termasuk data string, float, kompleks, dan integer. Array dapat berisi data dari ukuran apa pun, dan bisa dalam bentuk apa pun. Di HDF5, pertama-tama seseorang harus membuat file header untuk membuat dataset. File header menyertakan informasi tentang kumpulan data serta metadata. File header berisi dua informasi penting: nama kumpulan data dan nomor versi kumpulan data. Array data digunakan untuk menyimpan data set data. Blok terdiri dari data dalam array data. Dalam larik data, setiap blok data berisi kumpulan data yang berdekatan. Jumlah blok dataset ditentukan oleh jumlah byte di dalamnya. Data dapat diakses melalui beberapa metode sesuai dengan spesifikasi HDF5. metode pengindeksan paling umum digunakan untuk mendapatkan data dalam kumpulan data. Dengan menggunakan metode ini, Anda dapat mengakses data dengan memasukkan nama blok dalam larik data yang ingin Anda akses. Metode struktur dapat digunakan untuk mengakses data dalam dataset. Saat Anda menggunakan metode ini, Anda dapat mengakses data dengan menggunakan struktur array data. Dalam contoh berikut, Anda dapat mengakses data dalam larik data dengan menggunakan nilai offset dan panjang dari metode struktur. Cara lain untuk mendapatkan data dari kumpulan data adalah melalui penggunaan metode fungsi. Anda dapat memperoleh data dengan menggunakan salah satu metode dengan memilih fungsi di file header untuk data tersebut. Metode untuk mengakses larik data dapat digunakan dengan mendefinisikan nilai dalam file header sebagai elemen larik data larik. Terakhir, Anda dapat mengakses data dalam kumpulan data menggunakan metode akses. Dengan menggunakan metode ini, Anda dapat mengakses data dengan menggunakan hak akses yang diatur dalam file header. Dengan kata lain, menggunakan hak baca dapat mengakses data dalam larik data melalui metode akses. Data dapat dibuat dan digunakan dengan berbagai cara menggunakan spesifikasi HDF5. Metode create adalah metode paling umum untuk membuat dataset. Dengan menggunakan metode create, Anda dapat membuat dataset dengan memasukkan nama dataset dan nomor versi dataset. Selain spesifikasi HDF5, penggunaan kumpulan data dapat dilakukan dengan berbagai cara. Metode yang paling umum digunakan.

Apakah Hdf5 Database Relasional?
HDF5 bukan database relasional.
Apakah Graphql Nosql Atau Sql?
Tujuan utama GraphQL adalah menggunakan sistem tipe untuk mengembalikan data lebih cepat dan lebih efisien. SQL (bahasa kueri terstruktur) adalah bahasa yang lebih tua dan lebih banyak digunakan untuk menyimpan data dalam sistem basis data tabular atau relasional . Jika Anda ingin API Anda dibangun di atas database NoSQL, sebaiknya bekerja dengan GraphQL.
Type Mismatch adalah database GraphQL dan NoSQL yang dibuat oleh Herman Camarena dan Roger Cochrane. Penggunaan GraphQL dapat menghasilkan pengenalan sistem tipe daripada sistem NoSQL, menghilangkan fleksibilitas yang dibuat oleh sistem NoSQL. Kumpulan GraphQL berisi berbagai macam dokumen yang konsisten dalam struktur dan berisi beberapa pengecualian. Karena GraphQL memiliki kumpulan tipe data bawaan yang cocok dengan tipe backend, pengembang dapat memilih tipe data apa yang akan dibuat. GraphQL harus mengatasi masalah ketidakcocokan tipe untuk menyadari potensinya sepenuhnya. Dalam hal fiturnya, ini memberikan solusi ketidakcocokan tingkat rendah karena banyak keuntungannya. Pekerjaan semakin otomatis dengan alat seperti JSON2SDL StepZen.
Ini adalah alat yang ampuh yang dapat digunakan untuk membuat aplikasi yang lebih tangguh dan efisien, tetapi SQL bukanlah penggantinya. Dalam hal pemeliharaan, hal ini dapat berdampak negatif karena mempersulit beberapa tugas.
Graphql: Bahasa Kueri Untuk Semua Basis Data
Bahasa kueri GraphQL memungkinkan klien dan server untuk berkomunikasi satu sama lain. Instance GraphQL dapat mengambil dan mempertahankan perubahan baik dari sumber data atau status persisten. Resolver adalah sekumpulan fungsi arbitrer yang digunakan untuk mengakses dan memanipulasi data. API tersedia dalam berbagai database, dan GraphQL dapat digunakan dengan siapa saja. Basis data MongoDB adalah basis data sumber data populer yang bersifat agnostik terhadap berbagai jenis data.
Apakah Nosql Menggunakan Pohon B?
Database NOSQL tidak menggunakan pohon B karena tidak didasarkan pada model relasional. Basis data NOSQL sering didasarkan pada pasangan kunci-nilai, penyimpanan dokumen, atau basis data grafik.
B-tree adalah struktur pengindeksan default di MongoDB. Dalam penyimpanan data , B-tree adalah metode yang lebih efisien. Data dapat diatur menggunakan bilangan bulat dan string jika digunakan bersama. Akibatnya, database dengan volume data yang tinggi harus mempertimbangkan untuk menggunakannya. Karena pohon B dapat memakan banyak ruang, mereka adalah model yang efisien. Ini bermanfaat untuk database yang perlu menyimpan data dalam jumlah besar. B-tree juga merupakan pilihan yang baik untuk database yang perlu mengatur data dengan cara tertentu.
Database Mana yang Menggunakan B-tree?
Sudah ada sejak lama dan dapat digunakan di berbagai database. Database NoSQL dapat dibangun di atas mesin B-tree, selain mesin B-tree. MongoDB, misalnya, mengindeks data dalam B-tree. Algoritme untuk DBMS sama dengan database relasional, meskipun ada beberapa pengecualian. String dan integer dapat digunakan untuk mengatur data di B-tree.
Basis data mana yang menggunakan B-tree? Mysql, dalam artikel berikut, menggunakan Btree dan B+tree. SQL Server menyimpan indeks berdasarkan data bertahan berbasis kunci dalam bentuk BTree. Akibatnya, setiap node dalam pohon tersebut muncul sebagai satu halaman.