
3 cose fondamentali da tenere a mente quando si modellano i dati in un database NoSQL
Pubblicato: 2023-02-27Quando si tratta di modellare i dati in un database NoSQL, ci sono alcune cose fondamentali da tenere a mente. Innanzitutto, è importante comprendere la differenza tra database relazionali e non relazionali. I database relazionali, come MySQL, memorizzano i dati in tabelle e righe. I database non relazionali, come MongoDB, memorizzano i dati nei documenti. Ciò significa che quando stai modellando i dati in un database NoSQL, dovrai pensare a come strutturare i tuoi dati in un modo che abbia senso per un database basato su documenti. In secondo luogo, è importante tenere a mente i tipi di query che dovrai eseguire sui tuoi dati. In un database relazionale, in genere si utilizza SQL per interrogare i dati. Tuttavia, in un database NoSQL, dovrai utilizzare un linguaggio di query diverso. Ad esempio, in MongoDB, utilizzerai MongoDB Query Language (MQL). Infine, è importante pensare a come indicizzare i dati. In un database relazionale, in genere indicizzi i dati creando indici su tabelle e colonne. Tuttavia, in un database NoSQL, dovrai indicizzare i dati in modo diverso. Ad esempio, in MongoDB, puoi creare indici su documenti e campi. Tenendo a mente queste tre cose, puoi modellare i dati in un database NoSQL in modo efficiente e scalabile.
I database SQL distribuiti su più computer sono progettati per staccarsi dal modello relazionale. C'è un malinteso comune che i database NoSQL manchino di un modello di dati . Il primo passaggio nella creazione di uno schema consiste nel descrivere come verranno organizzati i dati. Poiché ogni tipo di database NoSQL ha il proprio set di modelli di dati, le differenze tra loro sono naturali. Di conseguenza, la progettazione dello schema sarà iterativa per tutta la vita dell'applicazione. Una delle considerazioni più importanti nel decidere quale database NoSQL utilizzare è il caso d'uso per il quale il modello di dati è più adatto. Ogni documento memorizza più campi e valori oltre a un'ampia gamma di tipi di dati e strutture di dati.
È stata sviluppata una varietà di potenti linguaggi di query per gestire vari tipi di valori di campo e le query possono essere utilizzate per recuperare i valori di campo. Un database NoSQL contiene una chiave e una colonna correlata in ogni riga, che vengono chiamate famiglie di colonne. È la struttura sottostante che memorizza i dati in ciascuno dei quattro principali tipi di database NoSQL. Sebbene i dettagli sull'organizzazione dei dati siano molto flessibili, a volte può essere necessario anche un sistema "senza schema". I database di documenti, i database a colonne larghe e i database a grafo in genere dispongono di un linguaggio di query specifico incorporato.
Esempio di schema di database Nosql
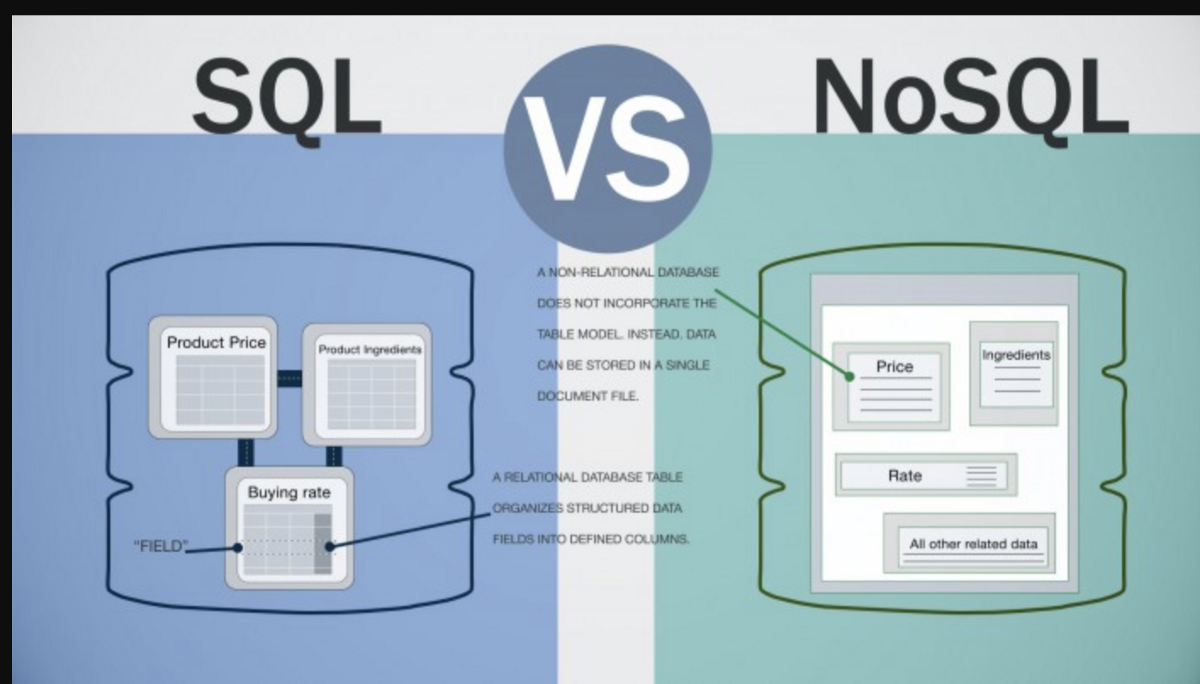
Un database NoSQL è un database non relazionale che non utilizza il tradizionale schema basato su tabelle di un database relazionale. I database NoSQL vengono spesso utilizzati per archiviare grandi quantità di dati non adatti a un database relazionale, ad esempio dati non strutturati, con un numero elevato di relazioni o in continua evoluzione.
Non è necessario utilizzare uno schema fisso per gestire i dati nei database NoSQL perché non hanno una gerarchia. A causa del volume di dati generati e consumati, i database NoSQL vengono utilizzati per archivi dati distribuiti con requisiti di archiviazione elevati. Twitter, Facebook e Google sono tra le aziende che utilizzano NoSQL per archiviare dati e creare app Web in tempo reale. I dati possono essere archiviati in un database chiave-valore e utilizzati come coppia chiave-valore recuperandoli dal database. Gli array associativi e i tipi di database di raccolta sono usi comuni di questo tipo di database NoSQL. Un tipo di documento in genere funge da base per i sistemi di gestione dei contenuti (CMS), piattaforme di blog, analisi in tempo reale e applicazioni di e-commerce. I dati nel database grafico possono essere utilizzati per creare reti sociali, logistica o mappe spaziali.
Le viste CouchDB possono essere definite in MapReduce utilizzando il sistema. Secondo esso, i data store distribuiti non sono in grado di garantire più di due delle tre cose. La coerenza è fondamentale per la coerenza dei dati in generale, anche dopo che un'operazione è stata completata. Se i server non sono in grado di comunicare tra loro, la tolleranza della partizione dovrebbe essere mantenuta.
Database Nosql: la nuova normalità?
La piattaforma di database NoSQL è più flessibile ed efficiente rispetto alla tradizionale piattaforma di database relazionale . Poiché non richiedono uno schema rigido, questi tipi di database sono spesso più semplici da utilizzare. Essi, d'altra parte, non hanno tutte le capacità di un database relazionale.
Modellazione dei dati Nosql
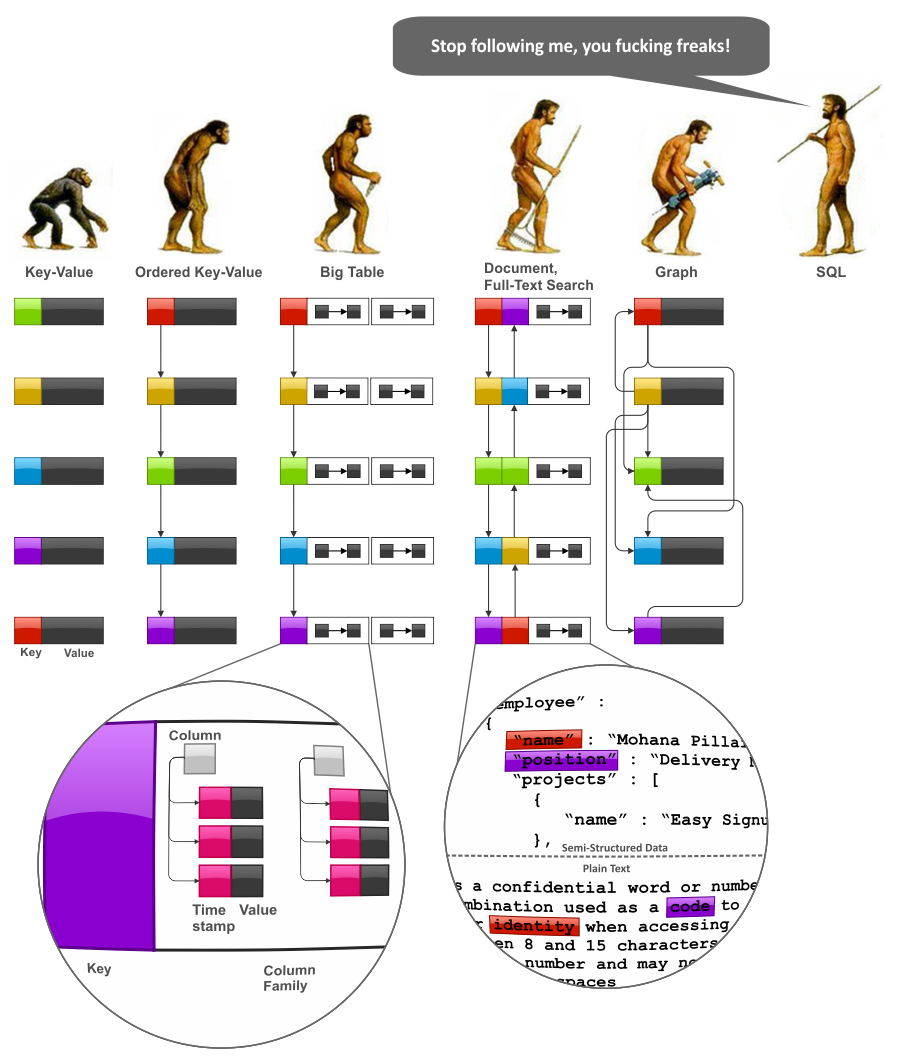
Cos'è un modello di dati NoSQL ? Questo modello non si basa sull'uso di un sistema di gestione di database relazionali (RDBMS). Di conseguenza, il modello è ambiguo su come i dati interagiscono tra loro, su come si collegano tutti insieme.
8 Modelli di modellazione dei dati in Redis è un libro eccellente per imparare la modellazione dei dati in Redis. Discute otto modelli di dati che possono essere utilizzati per creare applicazioni moderne senza le limitazioni di un database relazionale tradizionale, che può essere proibitivo. La piattaforma NoSQL consente l'integrazione di due tabelle o raccolte separate con una tabella. Di conseguenza, saranno in grado di comprendere meglio la loro relazione e trovare più facilmente tutti i dati rilevanti. Ogni tabella è la propria vista nelle applicazioni NoSQL, il che significa che le sue prestazioni sono indipendenti dall'applicazione. Un elenco delimitato (come elenchi di dimensioni note) viene incorporato come elenco illimitato, mentre un elenco illimitato viene incorporato separatamente come elenco illimitato. In questo caso è quello, quindi sono richieste le seguenti variabili: il prodotto, l'autore, la data di pubblicazione, il voto e il commento.
Il primo modello ha relazioni molti-a-molti con lati illimitati. In un database relazionale è necessario tenere traccia di vari tipi di prodotti suddividendoli in tabelle. È possibile distinguere tra i campi di tipo per le raccolte utilizzando Redis Stack. Man mano che avanzi nel modello di bucket, ridurrai il sovraccarico archiviando e gestendo i dati delle serie temporali. Molti casi d'uso possono essere migliorati utilizzando il modello di revisione insieme ai dati in tempo reale. NoSQL consente di utilizzare questi modelli in vari modi per ridurre la complessità delle operazioni JOIN. Operazioni JOIN pesanti, come sistemi HR, CMS, cataloghi di prodotti e social network, richiedono l'uso del Tree and Graph Pattern.
Non si basa sull'uso di un sistema di gestione di database relazionali (RDBMS) per il rafforzamento. I dati possono essere archiviati su un disco, un'unità in memoria o entrambi. L'utilizzo di Redis e NoSQL per creare applicazioni è dimostrato in una serie di esempi su Redis Launchpad.
Database Nosql: il modo migliore per archiviare dati non relazionali
I database Somenosql, invece, possono essere eseguiti su database relazionali. MongoDB e Cassandra, ad esempio, utilizzano l'indice B-Tree, che si trova in un gran numero di database. Il modello grafico utilizzato in Neo4j non è compatibile con i database relazionali. I database NoSQL stanno diventando popolari perché sono più flessibili ed efficienti dei database convenzionali . Non sorprende che un database nosql sia una scelta eccellente se hai bisogno di un modello di dati che non sia basato sul modello relazionale.
Come progettare un database Nosql
Non esiste una risposta definitiva a questa domanda, poiché il modo migliore per progettare un database NoSQL dipende dalle esigenze specifiche dell'applicazione. Tuttavia, ci sono alcuni suggerimenti generali che possono essere seguiti per garantire che il database sia progettato in modo ottimale. Innanzitutto, è importante comprendere i dati che verranno archiviati nel database e le relazioni tra i dati. Ciò contribuirà a determinare lo schema migliore per i dati. Successivamente, è importante scegliere la giusta tecnologia di database NoSQL per l'applicazione. Sono disponibili diverse tecnologie, ognuna con i propri punti di forza e di debolezza. Infine, è importante progettare il database per le prestazioni. Ciò significa considerare cose come l'indicizzazione e lo sharding.
Con RDBMS normalizzato, puoi sfruttare i punti di forza intrinseci del paradigma relazionale. Il vantaggio principale dei database NoSQL è che possono modellare aggregati semi-strutturati ed entità dinamiche. Invece di entità e relazioni, dovresti considerare come modellare NoSql in termini di gerarchia e aggregazioni. la denormalizzazione, come definita in RDBMS, spegne efficacemente il tuo DB in un database NoSQL. Se hai solo bisogno di un sottoinsieme di un aggregato, dovrai unirti al codice, o se hai bisogno di un aggregato di aggregati, dovrai analizzarlo. È fondamentale identificare le tue relazioni il prima possibile.

Progettazione NoSQL
Un modello di dati NoSQL, al contrario di un approccio orientato all'applicazione, si concentra su come l'applicazione interrogherà i dati piuttosto che sulle relazioni all'interno dei dati. Piuttosto che un rigido schema relazionale, i principi di progettazione del database NoSQL enfatizzano la flessibilità dei dati.
Di conseguenza, i database NoSQL dovrebbero essere accompagnati da un corrispondente cambiamento nell'architettura dell'applicazione. La complessità del server viene trasferita dai database basati su SQL come parte dell'approccio NoSQL. In questo articolo esamineremo i vari aspetti della gestione dei dati e raccomanderemo un'architettura che utilizzi il livello di gestione dei dati piuttosto che i database NoSQL. I database NoSQL orientati agli oggetti in genere hanno strutture nidificate per le entità di dati. Quando i figli/le sottostrutture di un documento genitore sono sempre accessibili dall'interno del documento, le strutture di dati nidificate funzionano bene. Le relazioni bidirezionali possono essere evitate in alcuni casi utilizzando strutture nidificate. Le relazioni sono ancora necessarie in alcune applicazioni critiche.
Si sa molto bene come gestire le relazioni con gli RDBMS tradizionali. Come possiamo modellare le relazioni utilizzando i database NoSQL? Potresti provare una delle due strategie. Un modo per ridurre al minimo la duplicazione dei dati è utilizzare strategie di normalizzazione. Un'opzione consiste nella denormalizzazione dei dati, che può migliorare le prestazioni delle query. L'approccio NoSQL alla gestione dei dati rischia di essere frainteso se tenta di minare i pilastri storici della gestione dei dati di Edgar Codd. Di conseguenza, l'accesso al database dovrebbe essere visto come un componente interno dell'implementazione piuttosto che come un'API riutilizzabile.
È fondamentale mantenere la coerenza dei dati tra storage e database NoSQL. I database di documenti chiave-valore sono stati indicizzati utilizzando un'API di indice simile all'API DB di Berkeley. Il W3C ha concluso che i database NoSQL dovrebbero avere un accesso programmatico agli indici piuttosto che un accesso basato su query, secondo i rapporti. Di conseguenza, i vincoli di validità e integrità dei dati dovranno ancora essere applicati. Spostando la convalida fuori dal livello di archiviazione, possiamo centralizzarla nel nostro livello di gestione dei dati. I sistemi di replica basati sulla coerenza, in generale, possono essere implementati su singoli sistemi di archiviazione di database basati su una semantica transazionale più rigorosa. La replica personalizzata e l'imposizione della coerenza sono estremamente utili per le applicazioni che richiedono una maggiore integrità o che richiedono una maggiore scalabilità di coerenza rilassata.
La risoluzione dei conflitti in CouchDB utilizzando la risoluzione dei conflitti in stile MVCC (Multi-Version Concurency Control) a volte è ingenua. In Persevere 2.0 è possibile definire un modello di dati e collegare i prodotti ai relativi produttori. Come risultato dei nostri sforzi, il modello di architettura MVC è stato efficacemente implementato. La ricapitalizzazione di questo tipo di livello dell'interfaccia utente come mVC indica uno spostamento dell'enfasi dalle preoccupazioni relative alla modellazione dei dati nella logica dell'interfaccia utente.
Che cos'è Nosql e l'esempio?
Un database NoSQL (noto anche come SQL) è un tipo di database che memorizza i dati in modo diverso rispetto a un database relazionale. Il termine NoSQL si riferisce a un modello di dati che consente la progettazione di una varietà di database. I tipi di documento, i tipi di valore-chiave, i tipi di colonne larghe e i grafici sono i più comuni.
Qual è l'architettura di Nosql?
Con l' approccio al database NoSQL , i server che eseguono database basati su SQL non sono più tenuti a gestire grandi quantità di dati. La convalida, il controllo degli accessi, la mappatura dei dati, le attività di correlazione, la risoluzione dei conflitti, il mantenimento dei vincoli di integrità e le procedure attivate vengono tutti rimossi dal livello del database.
I vantaggi dei database cloud Nosql
Ci sono diversi vantaggi nell'usare un database cloud nosql rispetto a un database relazionale tradizionale. Sono più flessibili in termini di ridimensionamento. Hanno prestazioni migliori in termini di operazioni di lettura e scrittura rispetto ad altri tipi di software. Il terzo vantaggio è che sono più bravi a gestire le modifiche ai dati.
Quale strumento viene utilizzato per la progettazione di database Nosql?
Hackolade, DbSchema e Cassandra Data Modeler sono alcuni degli strumenti di progettazione dello schema del database NoSQL. Il design dello schema visivo di Hackolade è ideale per database NoSQL di qualsiasi tipo. DbSchema estrae gli schemi dai database NoSQL esistenti e li converte in XML.
Sql o Nosql?
I modelli di dati NoSQL sono cresciuti in popolarità perché sono semplici da usare e mancano di coerenza tra i prodotti. I database SQL semplificano l'esecuzione di query complesse su dati strutturati elaborando le query e unendo i dati tra le tabelle. La mancanza di coerenza tra i database NoSQL, così come la necessità di interrogare i dati più frequentemente, può comportare un aumento dei tempi di query. Se è necessario eseguire rapidamente query sui dati per scopi analitici, un database SQL è la soluzione più probabile. Tuttavia, se hai bisogno di archiviare i dati in un formato più flessibile e meno strutturato, un modello di dati NoSQL potrebbe essere più adatto a te.
Documento Nosql
I database di documenti Nosql stanno diventando sempre più popolari man mano che cresce la necessità di soluzioni di gestione dei dati più veloci e flessibili. Questi database sono progettati per fornire prestazioni elevate, scalabilità e flessibilità, rendendoli ideali per un'ampia gamma di applicazioni.
I database orientati ai documenti sono un approccio moderno che utilizza JSON anziché colonne e righe come archiviazione dei dati. Quando si lavora con dati semistrutturati, è possibile gestire problemi che sono più difficili da comprendere con gli RDBMS. Gli archivi di documenti sono una soluzione naturale e flessibile per gli sviluppatori agili, che possono lavorare più velocemente utilizzandoli. Il linguaggio di query espressivo e l'indicizzazione sfaccettata offrono una varietà di opzioni di query. Puoi comunque beneficiare della garanzia del database relazionale eseguendo transazioni ACID. Puoi saperne di più su come i sistemi distribuiti possono aumentare la scalabilità e la resilienza dei tuoi dati visitando distributedsystems.com. I singoli documenti sono unità indipendenti, che facilitano la distribuzione tra i server senza compromettere la località dei dati.
L'uso di modelli pratici e intuitivi nei database di documenti consente ai modelli di leggere più velocemente rispetto a quelli utilizzati nei database relazionali. La qualità dei dati dovrebbe essere inferiore e vi è il rischio di deterioramento dei dati a causa di tabelle rigide. Non esiste una scalabilità orizzontale nativa nel database relazionale, quindi se vuoi partizionare (shard) il tuo database esistente, dovrai pagare per un costoso sistema di scalabilità verticale. I database orientati ai documenti possono memorizzare vari tipi di documenti e di solito non è necessario inserire alcun campo. Nonostante il fatto che ogni campo sia distinto, esiste una composizione strutturale comune. Ogni documento contiene un ID univoco che può essere utilizzato per aggiungere, modificare, eliminare o richiedere informazioni. L'incapsulamento di dati (o informazioni) incapsulati viene solitamente eseguito in formato o decodifica standard.
I database orientati ai documenti hanno una struttura molto più flessibile rispetto a un database tradizionale . I dati vengono salvati direttamente dal documento anziché dalle colonne all'interno del database quando viene interrogato. Gli unici campi dati che devono essere aggiunti sono quelli rilevanti per il set di dati nell'archivio documenti.
Perché i documenti sono migliori delle tabelle relazionali per l'archiviazione dei file
I documenti vengono spesso utilizzati per archiviare file perché sono più efficienti dei database relazionali per l'archiviazione di file di grandi dimensioni. I documenti di documento hanno anche il vantaggio di essere comodi da cercare e manipolare.