
5 modi per ottimizzare il tuo database NoSQL
Pubblicato: 2023-01-12I database NoSQL stanno diventando sempre più popolari poiché sono visti come più scalabili e flessibili rispetto ai database relazionali tradizionali . Esistono diversi modi per ottimizzare un database NoSQL, tra cui: 1. Progettare attentamente lo schema: questo è importante in quanto uno schema ben progettato può aiutare a migliorare le prestazioni e rendere i dati più gestibili. 2. Indicizzazione dei dati: questo può aiutare a migliorare le prestazioni delle query. 3. Utilizzo della memorizzazione nella cache: la memorizzazione nella cache può aiutare a migliorare le prestazioni memorizzando i dati a cui si accede di frequente. 4. Partizionamento dei dati: questo può aiutare a migliorare le prestazioni e la scalabilità distribuendo i dati su più server. 5. Monitoraggio delle prestazioni: questo è importante per identificare eventuali colli di bottiglia e intraprendere azioni correttive.
Jay Patel, un architetto di eBay, ha recentemente pubblicato un articolo sulla modellazione dei dati utilizzando l'archivio dati Cassandra. Spiega come hanno progettato il loro modello di dati utilizzando Cassandra, come hanno utilizzato colonne e famiglie di colonne e come hanno ottimizzato i risultati delle query utilizzando l'ottimizzazione delle query. Una delle mie intuizioni preferite dal loro approccio è che può essere applicata a qualsiasi database NoSQL. Prima di poter ottimizzare il tuo modello di dati, devi prima comprendere come sarà possibile accedervi. Quando inizi a notare che le tue query richiedono più tempo, ti rendi conto che il tuo database relazionale sta riscontrando problemi di prestazioni. Quando i dati vengono normalizzati, è meno probabile che si verifichino join non necessari o query n+1. Anche se la denormalizzazione è possibile con gli archivi dati NoSQL, vi sono dei costi ad essa associati.
Che cos'è l'ottimizzazione delle query in Nosql?
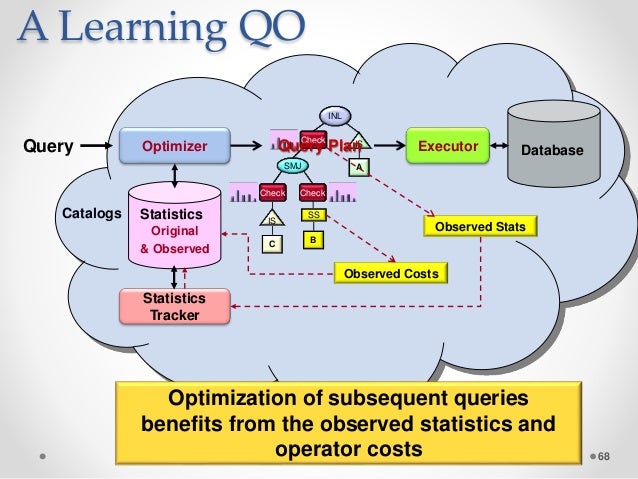
L'obiettivo dell'ottimizzazione della query è trovare il piano più efficiente. Quando si misura l'efficienza, vengono utilizzati latenza e throughput. Un'ottimizzazione basata sui costi costa quanto il costo della memoria, della CPU e dello spazio su disco. Nel mondo NoSQL, la maggior parte dei database ora fornisce il supporto del linguaggio di query simile a SQL.
Un database MongoDB è un database NoSQL noto anche come database di documenti. Questo database è stato progettato in modo tale da essere più facile da sviluppare rispetto ad altri database relazionali. Usando describe() possiamo vedere come funziona la nostra query. Puoi utilizzare Spiega per creare un documento che includa piani di query, fasi di query e altro ancora. Come risultato di questo articolo, possiamo ottenere una comprensione di come l'indice può alterare le fasi di scansione di una raccolta specifica. Lo scopo di questo articolo è esaminare i fondamenti dell'ottimizzazione. I dettagli dettagliati dell'ottimizzazione della fase di aggregazione verranno trattati negli articoli successivi. I neri eccellono nei campi della tecnologia. Questa raccolta di risorse evidenzia alcune delle cose che dovremmo sapere.
Cosa rende Nosql veloce?
I database Nosql sono progettati per essere veloci e scalabili. Usano una varietà di tecniche per raggiungere questo obiettivo, come il ridimensionamento orizzontale, lo sharding e la denormalizzazione.
La stragrande maggioranza dei sistemi noSQL sono semplicemente archivi di chiavi o valori persistenti (come Project Voldemort). Se le tue query sono del tipo che richiede di cercare un determinato valore di chiave, un sistema in grado di farlo rapidamente come dovrebbe fare un RDBMS. Anche i database di documenti (come CouchDB) sono popolari sistemi nosql. La denormalizzazione è ampiamente utilizzata in questi database per strutturare la struttura dei dati. In effetti, credo che le prestazioni di un'applicazione possano essere misurate dal numero di parti necessarie per soddisfare un singolo requisito. Quando viene utilizzato NoSQL, le prestazioni di un database NoSQL come djondb possono essere dieci volte più veloci se è necessario solo un semplice inserimento. Lo sviluppatore sarà in grado di lavorare in modo più efficiente perché NoSQL consente loro di consumare meno dati.
L'obiettivo principale di NoSQL DATABASES (senza confini) è mantenere un alto livello di scalabilità. Devi considerare quali tipi di query stai eseguendo, quali colonne utilizzi nella tabella e quale implementazione del tuo server stai utilizzando. Se crei più nodi 1000000rpm stabili 2 ms e usi meno codice, otterrai un nodo più veloce con una velocità e prestazioni stabili più elevate.
Cosa rende Nosql più veloce di Sql?
Questo metodo comporta la raccolta, il consolidamento e la divisione di varie entità di dati. Di conseguenza, un database NoSQL esegue le operazioni di lettura e scrittura più velocemente di un database SQL.
Perché i database Nosql stanno prendendo il sopravvento
Oltre a una varietà di fattori, i database NoSQL stanno diventando sempre più popolari. Sono semplici da usare, in grado di gestire grandi quantità di dati e possono essere personalizzati per soddisfare i requisiti specifici della tua applicazione. Hanno molti vantaggi oltre ad essere flessibili e personalizzabili, cosa impossibile da trovare in altri tipi di database.
Ottimizzazione delle prestazioni di Nosql

L'ottimizzazione delle prestazioni di Nosql consiste nell'assicurarsi che il database nosql funzioni nel modo più efficiente possibile. Ci sono alcune aree chiave su cui concentrarsi durante l'ottimizzazione del database nosql: 1. Assicurati che il tuo database sia correttamente indicizzato. 2. Assicurati che le tue query siano ottimizzate. 3. Assicurati che i tuoi dati siano correttamente normalizzati. 4. Assicurati che il tuo database sia configurato correttamente. Concentrandoti su queste aree chiave, puoi assicurarti che il tuo database nosql funzioni al massimo delle prestazioni.
Quando Mango ha un carico elevato, lo script MangoNoSql esegue scritture in background in background. La funzione Batch Write Behind ti consente di scrivere dietro le quinte. Ogni attività verrà eseguita in parallelo alle altre, mettendo a fuoco i valori in punti di un pool. Se hai notato eventi di perdita di dati NoSQL nel tuo sistema, è una buona idea modificare le impostazioni delle prestazioni. Quando si preme il pulsante Esegui backup ora, verrà creata una coda di processi per eseguire il backup del sistema ora. Tutti i valori in punti pronti per essere scritti in un elenco di memoria come parte dei moduli NoSQL sono archiviati in mango. Successivamente, seleziona fino a "Scrittura in batch dietro gli inserti per attività" dall'elenco e avvia un thread per inserire gli inserti.
I pro ei contro di Nosql
Quando si sviluppano database NoSQL, è fondamentale mantenerli flessibili e veloci. Ha meno spese generali perché ha meno vincoli di SQL. L'archiviazione Shallow NoSQL è flessibile e può essere distribuita su una varietà di oggetti (documenti o coppie chiave-valore). Un database NoSQL è ampiamente considerato come avente un basso livello di difficoltà in termini di sviluppo, funzionalità e prestazioni. È semplice da imparare ed è utilizzato da persone che preferiscono archiviare dati non conformi ai tradizionali modelli di database .
Ottimizzazione delle prestazioni di MongoDB
MongoDB è un potente sistema di database orientato ai documenti open source. Ha una funzione di ricerca basata su indice che rende il recupero dei dati facile e veloce. Tuttavia, come qualsiasi altro sistema di database, le prestazioni di MongoDB possono essere ottimizzate per garantire un funzionamento fluido ed efficiente. Ci sono alcune cose di base che possono essere fatte per ottimizzare le prestazioni di MongoDB. Innanzitutto, è importante assicurarsi che siano presenti gli indici corretti. Ciò garantirà che i dati possano essere recuperati rapidamente e facilmente. In secondo luogo, è importante mantenere il database ben organizzato. Ciò contribuirà a mantenere basse le dimensioni dei dati e renderà più facile l'interrogazione. Infine, è importante monitorare regolarmente il database per assicurarsi che funzioni senza problemi. Seguendo questi semplici suggerimenti, è possibile mantenere MongoDB in esecuzione in modo fluido ed efficiente.

Guy Harrison spiega come utilizzare la nuova aggregazione a finestre e la pipeline di aggregazione in MongoDB 5.0 in questo post del blog. Data Lake è stato creato a seguito dell'esplosione di interesse per Big Data e Hadoop. È stato sviluppato il Data Lake, un'alternativa moderna e più efficiente all'Enterprise Data Warehouse (EDW). Il blog di questa settimana si concentra sugli indici MongoDB B -tree e su come creare indici concatenati per ottimizzare le ricerche multi-chiave. Inoltre, quando consideriamo o utilizziamo gli indici, consideriamo alcuni compromessi.
Qual è il miglioramento delle prestazioni in MongoDB?
Se conosci i tuoi modelli di query MongoDB, puoi migliorare le tue prestazioni MongoDB: memorizzando i risultati delle sottoquery frequenti per ridurre il carico di lettura; e rilevare i modelli di query MongoDB. Assicurati di avere indici su ogni campo che interroghi su base regolare. Se noti query lente, puoi utilizzare i tuoi log per identificarle.
MongoDB ha bisogno di molta RAM?
MongoDB richiede 1 GB di RAM per essere eseguito su un singolo asset. Se il sistema deve iniziare a scambiare memoria su disco, avrà un grave impatto sulle prestazioni e dovrebbe essere evitato.
MongoDB ha Query Optimizer?
Quando un indice è disponibile in MongoDB, l'ottimizzatore di query determina quale piano di query è il più efficiente e lo memorizza nella cache. Il numero di "unità di lavoro" (lavori) eseguite dal piano di esecuzione della query viene utilizzato per determinare il piano di query più efficiente quando il pianificatore di query esamina i piani candidati.
Strumento di ottimizzazione delle query MongoDB
MongoDB fornisce uno strumento di ottimizzazione delle query che consente agli utenti di migliorare le prestazioni delle loro query. Questo strumento fornisce un modo per visualizzare il piano di esecuzione della query e ottimizzare la query in base ai risultati. Lo strumento consente inoltre agli utenti di visualizzare il piano di esecuzione della query in una varietà di formati, inclusi JSON, BSON e CSV.
MongoDB fornisce statistiche sull'esecuzione delle query come parte di un sistema di ispezione. Queste informazioni possono essere utilizzate da uno sviluppatore per ottimizzare una query. La scheda Explain Plan, ad esempio, consente agli utenti di illustrare graficamente le statistiche del piano. Oltre a queryPlanner, executionStats e allExecutionPlans, è possibile utilizzare le modalità di verbosità per spiegare. Gli indici univoci, parziali, sparsi (non indicizzare i documenti senza il campo indice), nascosti (non visualizzare i risultati del pianificatore di query) e multichiave sono tutti supportati da MongoDB. Invece di utilizzare le chiavi dei prefissi di indice o gli ordinamenti variabili, viene utilizzato un indice composto per gli indici. MongoDB ottimizza le prestazioni delle query utilizzando due indici o prefissi separati durante la connessione di due indici o dei relativi prefissi.
La pipeline di Mongod contiene una fase che corrisponde a un campo non indicizzato. È una soluzione semplice per riscrivere la fase di corrispondenza per utilizzare un campo già esistente e indicizzato. L'ottimizzatore cerca le unità di lavoro che devono essere eseguite durante l'esecuzione di ciascun piano candidato. Quando si eseguono applicazioni a elevato carico di lettura, è necessario aumentare le dimensioni dei set di repliche ed eseguire il partizionamento orizzontale. È necessario monitorare lo stato e la durata della replica. Vero: aggiorna tutti i documenti corrispondenti nel modo più efficiente possibile quando si utilizza multi. Esamina le metriche di blocco in un ordine specifico.
Un tempo di blocco lungo può indicare che la struttura della query o l'architettura del sistema non funziona correttamente. Il batching migliora l'efficienza delle risorse. Gli eventi in Kafka, ad esempio, possono essere consumati in batch anziché in blocchi. È impossibile indicizzare una query su una raccolta partizionata se l'indice non contiene la chiave della raccolta. Utilizzando $planCacheStats, puoi ottenere una migliore comprensione delle informazioni sulla cache nella fase di aggregazione. Significa anche che la cache del piano avrà solo un limite di dimensione di 0,5 GB, che è lo stesso limite di dimensione della versione precedente.
Archivi dati Nosql
Invece di archiviare i dati nelle tabelle, i database NoSQL archiviano i dati nei documenti. Di conseguenza, li etichettiamo come "non solo SQL" e possono quindi essere classificati come modelli di dati flessibili utilizzando una varietà di metodi diversi. I database NoSQL sono divisi in quattro tipi: database di documenti puri, archivi di valori-chiave, database a colonne larghe e database a grafo.
L'archivio dati Redis è un archivio di coppie chiave-valore in memoria open source sviluppato da IBM. Può essere utilizzato per archiviare i dati della sessione per un accesso più rapido, oltre alla memorizzazione nella cache, all'accodamento e all'accodamento, ed è meno costoso dei database tradizionali . Un database NoSQL viene spesso utilizzato come ampliamento piuttosto che come sostituto di un database relazionale. Un tipo di persistenza sottostante ha un insieme di caratteristiche diverso da quello memorizzato in un database relazionale. PyMongo, che è costruito utilizzando il codice Python, ti consente di interagire con una o più istanze MongoDB utilizzando un'interfaccia comune. L'ORM Python basato su PyMongoEngine è specificamente progettato per MongoDB. L'obiettivo dei database a grafo è fornire una panoramica completa degli archivi dati NoSQL e confrontarli con altri tipi di archivi dati. Quella che segue è una breve descrizione di NoSQL e dei suoi usi, nonché una descrizione del Teorema di Consistency, Availability, and Partition-Tolerance (CAP). i dati della sessione possono essere archiviati in memoria più velocemente di quanto possano essere archiviati in un database tradizionale con archiviazione persistente.
I database NoSQL beneficiano delle seguenti caratteristiche: scalabilità semplice, disponibilità elevata e bassa latenza di accesso ai dati. Le applicazioni di database sono progettate per elaborare più tipi di dati rispetto ai database tradizionali. Semplifica l'archiviazione dei dati con un modello semplificato, consentendo un'elaborazione più rapida ed efficiente. Inoltre, sono appropriati per l'analisi dei dati su larga scala. I database NoSQL hanno una serie di vantaggi rispetto ai database convenzionali . I vantaggi di averli sono che possono scalare, fornire alti livelli di disponibilità e bassi livelli di latenza per l'accesso ai dati.
Perché i database Nosql stanno prendendo il sopravvento
Esistono numerosi vantaggi nell'utilizzo dei database NoSQL rispetto ai tradizionali database relazionali e stanno diventando sempre più popolari. Il design dell'ObjectStore, che consente un uso più efficiente delle tecniche di programmazione orientate agli oggetti, è uno dei motivi principali di ciò. I database NoSQL, oltre alla loro scalabilità, offrono anche una varietà di altri vantaggi. I dati possono essere gestiti con facilità perché sono grandi e possono essere gestiti in un breve periodo di tempo. Per qualsiasi azienda alla ricerca di un database di documenti affidabile e scalabile , MongoDB è una scelta eccellente. Inoltre, è gratuito ed è una scelta popolare per le aziende di tutte le dimensioni.
Indice di testo MongoDB
Gli indici di testo di MongoDB supportano l'elaborazione del testo specifica della lingua, inclusa la tokenizzazione, lo stemming e le stopword specifiche della lingua. Possono essere utilizzati con qualsiasi campo che contiene testo basato sulla lingua.
La creazione di indici di testo in MongoDB è semplice come utilizzare il metodo createIndex(). La funzione principale di un indice di testo è identificare qualsiasi elemento in una stringa o un array di elementi in un testo. Gli indici composti contengono sia chiavi di indice ascendenti che discendenti oltre alla chiave di indice di testo. In questo caso, eseguiamo una ricerca all'interno della raccolta studentpost creando un indice di testo nel campo del titolo. MongoDB riassume i risultati di ogni campo indice nel documento moltiplicando il suo peso per il numero totale di corrispondenze. Il peso predefinito di un campo indice è uno, quindi puoi modificarlo utilizzando il metodo createIndex(). È possibile creare più indici di testo utilizzando l'identificatore di caratteri jolly ($**).