
Bigtable di Google: il data store orientato alle colonne più utilizzato
Pubblicato: 2022-12-19Bigtable è un data store orientato alle colonne creato da Google. È progettato per gestire grandi quantità di dati con un alto grado di flessibilità. Bigtable è utilizzato da Google da oltre un decennio ed è la base di molti dei suoi servizi, tra cui Gmail, Google Maps e YouTube. Sebbene Bigtable non sia il primo archivio dati orientato alle colonne, è sicuramente il più utilizzato e conosciuto.
In questo articolo esamineremo il modello di archiviazione NoSQL tridimensionale sviluppato da Bigtable. Per verificare che sia strutturato correttamente, esamineremo prima come viene implementato in termini teorici e poi utilizzeremo il client Node.js per farlo. Il modello di archiviazione in Bigtable differisce dal modo in cui potresti trovarlo in un database simile. Più celle in una combinazione riga/colonna possono essere ordinate in base a un timestamp per cella. Invece di salvare le celle in un ordine arbitrario, ogni cella ha il valore e un timestamp per garantire che le celle vengano salvate in un ordine ordinato. Per questo esempio, utilizzeremo Node.js e semplice JavaScript per creare Google Cloud Bigtable. In questo articolo, esamineremo come creare una nuova istanza Bigtable utilizzando il codice.
Iniziamo creando un ambiente pulito, leggendolo e scrivendolo e poi demolendolo. Quando si esegue il codice utilizzando il client Node.js Bigtable, il client Node.js Bigtable potrebbe causare un errore di autorizzazione negata e generare un collegamento per abilitare l'API Cloud Bigtable Admin. Dovresti anche stabilire un account di servizio separato sul tuo progetto GCP per gestire il ruolo di amministratore di Bigtable. Per creare una tabella Bigtable, dobbiamo prima creare un'istanza del database e un cluster di tabelle. Definisci semplicemente un ID tabella e una famiglia di colonne nel client Node.js per farlo e sei a posto. È possibile creare righe semplici utilizzando Bigtable in un database. L'unico modo per interrogare i dati consiste nell'utilizzare la chiave di riga per interrogare una riga specifica o un gruppo di righe.
Sebbene i tempi di acquisizione non influiscano sull'ordine in cui le versioni vengono archiviate, influiscono sul modo in cui vengono archiviate. Non è necessario fornire l'intera chiave di riga; è sufficiente un semplice prefisso. Quando devi interrogare più righe da Bigtable, ti consiglio sempre di utilizzare lo streaming. Quando si utilizza lo streaming, Bigtable non deve eseguire il buffering dei dati sul server prima di inviare le righe, con prestazioni più veloci. I filtri possono essere utilizzati per limitare le versioni delle celle, restituendo solo quelle colonne con nomi di famiglia specifici o colonne con criteri di qualificazione specifici. Questo è particolarmente utile se hai molte versioni da conservare, ma solo la più recente è richiesta per scopi specifici. I filtri vengono utilizzati principalmente per ridurre la quantità di dati sottoposti a query e inviati per migliorare le prestazioni delle query.
In altre parole, Cloud Bigtable è un database NoSQL progettato per i carichi di lavoro di analisi e operazioni. Questo sistema di database è un ibrido multipiattaforma che utilizza Hadoop anziché HBase, che utilizza un database a colonne. Un cloud bigtable può essere utilizzato per alimentare applicazioni con throughput e scalabilità elevati, con una capacità inferiore a 10 MB.
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable e Microsoft Azure CosmosDB sono esempi di archivi a colonne larghe.
Le tabelle non sono la stessa cosa dei database relazionali in termini di archiviazione chiave/valore. Le transazioni possono essere eseguite solo una volta e le unioni non sono supportate.
Google Bigtable è un database Nosql?
Google Bigtable è un database NoSQL progettato per archiviare e gestire grandi quantità di dati. Bigtable è un database orientato alle colonne, il che significa che i dati sono organizzati in colonne anziché in righe. Questo lo rende adatto per l'archiviazione di dati che cambiano costantemente, come i registri web o i dati dei social media. Bigtable è anche altamente scalabile, il che significa che può gestire facilmente grandi quantità di dati.
Questo database NoSQL può memorizzare un'ampia gamma di tipi di dati ed è estremamente stabile. Gestisce inoltre sia lo sharding che la replica, garantendo che il database sia altamente disponibile e affidabile. Molte applicazioni Google lo utilizzano, tra cui Google Analytics, indicizzazione web, MapReduce e Google Maps, Google Libri, La mia cronologia delle ricerche, Google Earth, Blogger.com, Google Code Hosting e Google Per le applicazioni che richiedono un database in grado di gestire un grande numero di elementi di dati, Datastore è un'ottima scelta.
In quale ordine vengono archiviati i dati in Bigtable?
Non esiste un ordine specifico in cui i dati vengono archiviati in bigtable. I dati vengono archiviati in un ordine casuale, il che rende difficile l'accesso a dati specifici.
Bigtable di Google: non solo per l'archiviazione dei dati
I dati non possono essere inseriti in un ordine specifico all'interno di igtable. Poiché Bigtable è un database orientato alle righe, tutti i dati all'interno di una riga sono organizzati in colonne, seguite da una colonna. Poiché i dati vengono archiviati in ordine cronologico inverso, è semplice e veloce richiedere il valore più recente, ma è difficile e richiede tempo richiedere il valore più vecchio.
I tuoi dati vengono conservati su Colossus, il file system interno di lunga durata di Google, ospitato all'interno dei data center di Google, a seguito dell'utilizzo di Colossus da parte di Bigtable. Bigtable è gratuito e non è necessario utilizzare un cluster HDFS o qualsiasi altro file system.
Una query a un'origine dati esterna può essere eseguita senza creare una tabella permanente con il comando combine: Un file di definizione della tabella con una query. Esiste una definizione dello schema inline e una query. Un file di definizione dello schema JSON con una query.
Bigtable Vs Datastore
Ci sono alcune differenze chiave tra Bigtable e Datastore. Innanzitutto, Bigtable è un archivio dati orientato alle colonne, mentre Datastore è orientato alle righe. Ciò significa che in Bigtable i dati sono organizzati in colonne, mentre in Datastore sono organizzati in righe. In secondo luogo, Bigtable non ha un concetto di transazioni, mentre Datastore sì. Ciò significa che in Bigtable non è possibile ripristinare le modifiche a uno stato precedente, mentre in Datastore è possibile. Infine, Bigtable è progettato per un throughput elevato e una bassa latenza, mentre Datastore è progettato per un'elevata disponibilità e scalabilità.
Quale archivio dati cloud può essere utilizzato per creare database cloud di Google? Poiché Bigtable supporta carichi di lavoro di grandi dimensioni con carichi di lavoro di back-end complessi, è destinato a organizzazioni e imprese più grandi. A differenza di SQL, che utilizza un linguaggio di query GQL più restrittivo, i datastore eseguono transazioni ACID su sottoinsiemi di dati noti come gruppi di entità (sebbene il linguaggio di query GQL sia molto più aperto). Google Cloud Datastore e Google Cloud Bigtable sono due servizi distinti che hanno una serie di funzionalità distinte. Inoltre, le informazioni nell'immagine qui sotto possono aiutarti a selezionare il fornitore di servizi appropriato per te. Le risposte di cui sopra, così come quanto discusso nel libro di testo Coursea Google Cloud Platform Big Data and Machine Learning Fundamentals, serviranno da guida per questo articolo.
Qual è la differenza tra Bigtable e Datastore?
Qual è la differenza tra datastore e database? Il bigtable e il datastore sono entrambi progettati rispettivamente per l'elaborazione e l'analisi di dati ad alto volume, mentre il datastore è progettato per dati transazionali di alto valore. Il Datastore è anche noto come database NoSQL perché non aderisce allo standard SQL tradizionale, consentendogli di conservare i dati in modo più flessibile e scalabile. Che tipo di datastore è Google Bigtable? Il modello di archiviazione Bigtable memorizza i dati in tabelle altamente scalabili che vengono ordinate per mappe di chiavi e valori. Una tabella è composta da righe, ciascuna delle quali descrive una singola entità, e da colonne, ciascuna con il proprio valore. Il datastore è obsoleto? Poiché l'API Cloud Datastore v1beta3 è stata rilasciata, non è più disponibile. Tuttavia, il prodotto Cloud Datastore è completamente funzionante e supportato.
Database BigTable
Un Bigtable è un sistema di archiviazione distribuito per la gestione di dati strutturati progettato per scalare a dimensioni molto grandi: petabyte di dati su migliaia di server di prodotti. Bigtable è un database orientato alle colonne, il che significa che i dati vengono archiviati per colonna anziché per riga.
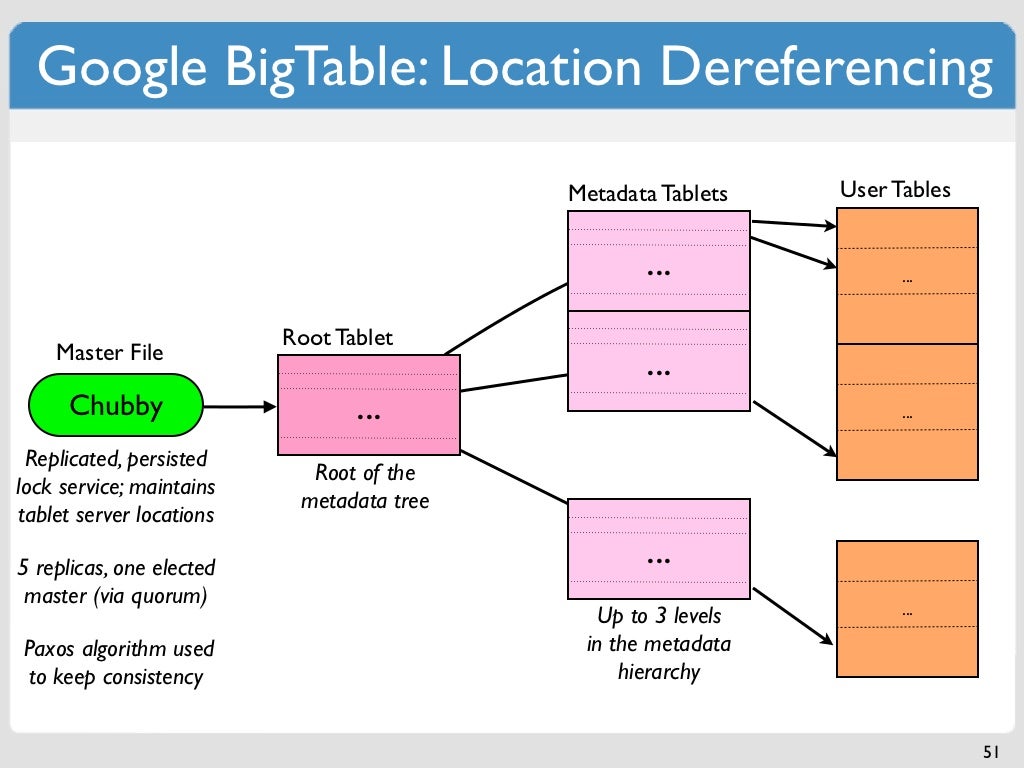
La tabella è una struttura sparsa e densamente popolata con righe e colonne che possono raggiungere miliardi di righe. Un bigtable è una scelta eccellente per archiviare grandi quantità di dati con bassa latenza. Poiché supporta velocità effettiva di lettura e scrittura elevate a bassa latenza, è un'origine dati adatta per le operazioni MapReduce. Quando si utilizza una tabella Bigtable, viene partizionata in blocchi di righe contigue note come tablet per semplificare le query. In un file system chiamato Colossus, utilizzato da Google, i tablet sono archiviati in formato SSTable. Un nodo Bigtable è un sottoinsieme di ogni tablet, che fa parte dell'istanza Bigtable. L'aggiunta di nodi a un cluster può aumentare il numero di richieste simultanee che può gestire.
Una riga contiene una serie di voci di chiave o valore, che sono una combinazione della famiglia di colonne, del timestamp della colonna e della chiave. Bigtable tratta tutti i dati allo stesso modo: come stringhe di byte grezze. Poiché Bigtable archivia le mutazioni in sequenza e le compatta regolarmente, il numero di mutazioni che possono essere archiviate in un determinato momento richiede più spazio di archiviazione. Bigtable comprime i tuoi dati utilizzando un sofisticato algoritmo automatizzato. Poiché le delezioni sono in realtà nuovi tipi di mutazioni, richiedono più spazio di archiviazione a breve termine. I metodi di archiviazione proprietari di Google consentono di ottenere una durabilità dei dati superiore a quella raggiunta dalla replica a tre vie HDFS standard. Oltre a gestire l'accesso alle tabelle Bigtable, puoi gestire l'accesso ad altri servizi Google Cloud assegnando ruoli agli utenti nella sezione Identity and Access Management (IAM) del tuo progetto Google Cloud. In base ai criteri di crittografia predefiniti di Google Cloud, tutti i dati nel cloud vengono crittografati a riposo utilizzando gli stessi sistemi di gestione delle chiavi rafforzati che utilizziamo per i nostri dati crittografati. Utilizzando un backup, puoi salvare una copia dello schema e dei dati di una tabella, quindi ripristinare tale copia dei dati in una nuova tabella in futuro.

Bigtable contro Cassandra
Cassandra e Bigtable utilizzano metodi diversi per determinare quale nodo di elaborazione deve eseguire operazioni di lettura e scrittura. In Cassandra, la chiave di partizione viene definita chiave, mentre in Bigtable la chiave di riga viene definita chiave. La politica di bilanciamento del carico per Cassandra deve essere rivista dal cliente come parte del processo.
Un database distribuito è un database condiviso da più persone. Questa azienda incorpora archivi multidimensionali di valore-chiave nel suo sistema, consentendole di elaborare decine di migliaia di query al secondo (QPS). L'obiettivo di questo documento è confrontare e contrapporre i due sistemi di database. Le caratteristiche principali di Bigtable includono: È stato creato un sistema di archiviazione distribuito per la carta dei dati strutturati. Se Bigtable determina che il ribilanciamento dell'intervallo è necessario per un set di dati, è semplice per un nodo di elaborazione modificare gli intervalli di dati perché il livello di archiviazione è separato dal livello di elaborazione. Bigtable può anche essere utilizzato per supportare la replica asincrona tra cluster distribuiti geograficamente fino a quattro cluster in topologie. La tolleranza agli errori di Cassandra è legata al suo livello di coerenza sintonizzabile.
Configurando una strategia di topologia di replica dei dati, è possibile definire la replica geografica. In generale, viene utilizzata l'impostazione aQUORUM (o LOCAL_QUORUM in alcuni data center). Per essere considerata riuscita, l'impostazione del livello di coerenza di un'operazione deve essere soddisfatta con una maggioranza di nodi di replica che risponda al nodo coordinatore. Utilizzando configurazioni di data center e rack, le repliche di Cassandra sono in grado di sopportare uno stress maggiore rispetto alle repliche tradizionali. Quando si eseguono operazioni di lettura e scrittura, la topologia determina quali nodi sono necessari per garantire la coerenza. Un'istanza Bigtable può contenere un singolo cluster o un gruppo di massimo quattro repliche di grandi dimensioni. Bigtable e Cassandra sono archivi dati NoSQL che sono archivi di colonne larghe.
La chiave di riga di Bigtable viene utilizzata per ordinare i dati globali in una tabella in base all'ordine. I nodi di Bigtable bilanciano automaticamente la responsabilità dei nodi per gli intervalli di chiavi, noti anche come tablet, come parte della funzionalità dei nodi di Bigtable. Il servizio Bigtable di un client non applica i tipi di dati delle colonne che invia. In Bigtable, a ogni colonna di una tabella viene assegnato un nome di famiglia. Nonostante il fatto che le tabelle abbiano spesso più famiglie di colonne (il numero massimo di colonne per tabella è 100), ogni tabella richiede almeno una famiglia di colonne. Un'intersezione di chiavi di riga è costituita da due celle (una famiglia di colonne combinata con un qualificatore di colonna). In Cassandra e Bigtable esiste un metodo per selezionare il nodo di elaborazione per le operazioni di lettura e scrittura.
In Cassandra viene identificata la chiave di partizione, mentre in Bigtable viene utilizzata la chiave di riga. Una policy di bilanciamento del carico che sia a conoscenza dei data center, come una policy multi-cluster, offre il potenziale per il failover. Entrambi i database utilizzano un metodo simile per terminare una scrittura e sono stati ottimizzati per la velocità. I dati vengono archiviati nei due database tramite file SSTable che sono immutabili. In Cassandra, il coordinatore deve notificare al client che la scrittura è stata completata prima che diverse repliche rispondano. Una scrittura riuscita in Bigtable può essere confermata solo da una risposta da un nodo, poiché ogni chiave di riga è assegnata solo a un nodo. Le celle in entrambi i database potrebbero non essere incluse nella SSTable unita.
A causa della clausola WHERE in una query CQL, è impossibile restituire più di una riga in Cassandra. Solo il nodo responsabile dell'intervallo di chiavi deve essere consultato in Bigtable. Nel nodo di elaborazione è possibile limitare la quantità di dati che possono essere letti. Durante una fase di compattazione, le SSTable vengono regolarmente unite e i dati archiviati in Bigtable e Cassandra vengono archiviati in esse. Non ci sono regole che disciplinano il numero di versioni di timestamp per ogni cella, ma potrebbero esserci altri limiti per le dimensioni delle righe. Le garanzie di durabilità dei dati sono fornite dal sistema di replica di Colossus. Bigtable, come Cassandra, ha un'interfaccia a riga di comando e librerie client per molti linguaggi di programmazione comuni.
A ogni nodo viene assegnata una SSTable in Bigtable e i dati in essa archiviati vengono serviti da quel nodo. Quando si dimensiona un cluster Cassandra, non è necessario tenere conto delle repliche di archiviazione come si fa con Bigtable. Le unità a stato solido (SSD) o le unità disco rigido (HDD) sono i tipi di archiviazione più comunemente utilizzati per le istanze Bigtable . Come dimostrato da Cassandra, non vi è alcuna perdita di densità di archiviazione per ottenere la tolleranza ai guasti. È possibile ridimensionare un'istanza Bigtable per soddisfare i requisiti del carico di lavoro con uno sforzo minimo e tempi di inattività minimi. Sebbene siano disponibili solo quattro cluster, ogni cluster può essere creato in qualsiasi regione cloud supportata in tutto il mondo. Google consiglia di testare le prestazioni di Bigtable con dati e query rappresentativi per generare una metrica QPS per nodo.
Cassandra esegue un gran numero di funzioni amministrative utilizzando i componenti gestiti da Bigtable. I backup largetable creano copie ripristinabili della tabella, che vengono archiviate come oggetti nel cluster. I backup consumano meno risorse del nodo e sono meno costosi dell'archiviazione cloud. Un altro metodo per eseguire il backup di Bigtable consiste nell'utilizzare un'esportazione di dati gestita in Cloud Storage. Le attività di manutenzione interna come l'applicazione di patch al sistema operativo, il ripristino dei nodi, la riparazione dei nodi, il monitoraggio della compattazione dello storage e la rotazione dei certificati SSL sono tutte gestite senza problemi dal servizio Bigtable. I dashboard sono disponibili per monitorare la velocità effettiva e le metriche di utilizzo a livello di istanze, cluster e tabella nella pagina della console di Bigtable Google Cloud . È possibile utilizzare il dashboard di monitoraggio per eseguire l'ottimizzazione avanzata delle prestazioni.
Il documento di Bigtable descrive un sistema di archiviazione dei dati che supporta un massiccio ridimensionamento. Ogni tabella nei dati è suddivisa in un numero di partizioni. È possibile eseguire query sulla tabella utilizzando una chiave di riga o utilizzando un intervallo di chiavi di riga. Il documento di Bigtable descrive anche un metodo per distribuire il lavoro del tavolo su un cluster di nodi. Apache Cassandra, un database open source, si basa su alcuni dei concetti del documento Bigtable. I data center utilizzano un'architettura a nodi distribuiti, in cui lo storage è condiviso tra i server che servono i dati. L'accesso al sistema di archiviazione dei dati di Bigtable viene fornito utilizzando l'interfaccia della riga di comando cbt e le librerie client. Bigtable include una serie di linguaggi di programmazione oltre a Python, semplificando l'integrazione con le applicazioni.
Datastax Astra Cassandra As A Service di Google: facile da implementare e scalare
DataStax Astra Cassandra as a Service di Google è una scelta eccellente per conoscere Cassandra. L'interfaccia utente dell'operatore Kubernetes semplifica la configurazione, la gestione e la scalabilità della distribuzione di Cassandra.
Documentazione Bigtable
La documentazione di Bigtable è un'ottima risorsa per conoscere questo potente strumento. Fornisce una panoramica delle caratteristiche e delle capacità di Bigtable, nonché informazioni dettagliate su come utilizzarlo. La documentazione è ben organizzata e facile da seguire, il che la rende una risorsa preziosa per chiunque sia interessato a conoscere questo potente strumento.
Google Cloud Platform è responsabile dell'hosting del database Bigtable di Google. È semplice utilizzare OpenTSDB 2.1 e versioni successive se utilizzato insieme al backend di Google. Tutto quello che devi fare è creare un'istanza Bigtable, configurare le tue tabelle TSDB utilizzando la shell Bigtable HBase e avviare i TSD. I client di Bigtable sono attualmente in versione beta e stanno subendo una serie di modifiche.
Il layout efficiente dei dati di Bigtable
Bigtable è anche adatto per le operazioni MapReduce. Grazie al suo efficiente layout dei dati, MapReduce può gestire grandi volumi di dati in un breve periodo di tempo.