
Hadoop HDFS e NoSQL: una potente combinazione per i Big Data
Pubblicato: 2023-01-05Hadoop è un framework open source che consente l'elaborazione distribuita di grandi set di dati tra cluster di computer utilizzando un semplice modello di programmazione. HDFS è il file system distribuito Hadoop che fornisce un modo scalabile e tollerante ai guasti per archiviare i dati. I database NoSQL sono una nuova classe di database progettati per fornire un'alternativa scalabile, flessibile e ad alte prestazioni ai tradizionali database relazionali.
La distinzione principale tra Hadoop e HDFS è che Hadoop è un framework open source per l'archiviazione, l'elaborazione e l'analisi dei dati, mentre HDFS è un file system che consente agli utenti di accedere ai dati Hadoop. Di conseguenza, HDFS è un modulo Hadoop .
SQL e Hadoop possono entrambi gestire i dati in vari modi. Un framework Hadoop viene utilizzato per assemblare componenti software, mentre un framework SQL viene utilizzato per assemblare database. Per i big data, è fondamentale considerare i pro e i contro di ogni strumento. La piattaforma Hadoop memorizza i dati solo una volta, mentre Hadoop memorizza un numero molto maggiore di set di dati.
Hadoop non è un database, ma piuttosto un software che consente un enorme calcolo parallelo. Questa tecnologia consente ai database NoSQL (come HBase) di diffondere i dati su migliaia di server con un basso degrado delle prestazioni.
Hadoop non archivia i dati allo stesso modo dell'archiviazione relazionale. Un server distribuito è una delle applicazioni che lo utilizza di più. Sebbene sia un database Hadoop , non si qualifica come database relazionale perché memorizza i file in HDFS (file system distribuito).
Qual è la differenza tra Nosql e Hdfs?
È un file system ed è anche indicato come file system. È già chiaro che questa app offre una serie di funzionalità. Dove prendi questa roba NOSQL? Saremo in grado di elaborare grandi quantità di dati in tempo reale utilizzandolo perché non richiede l'utilizzo di database relazionali o altre funzionalità.
Il gestore di archiviazione HBase, che viene eseguito in Hadoop, fornisce letture e scritture casuali a bassa latenza. Il sistema HBase utilizza una funzionalità di partizionamento automatico in cui le tabelle di grandi dimensioni vengono distribuite dinamicamente. Ogni Region Server è responsabile del servizio di un insieme di regioni e vi è un solo Region Server in grado di servire una regione (ovvero HMaster e HRegion sono due dei servizi principali forniti da HBase. Il componente HRegion della tabella HBase è responsabile della gestione sottoinsiemi dei dati della tabella. Quando un Region Server viene avviato, viene assegnato a ciascuna regione. Di conseguenza, il master non è coinvolto nelle operazioni di lettura e scrittura.
Quando si tratta di gestire dati non strutturati e voluminosi, i database NoSQL come MongoDB e Cassandra si distinguono dai tradizionali database relazionali. Le aziende con grandi carichi di lavoro di dati, come i Big Data, preferiscono utilizzare questi strumenti per elaborare e analizzare rapidamente enormi quantità di dati vari e non strutturati. MongoDB archivia i dati in raccolte, mentre hadoop archivia i dati in un file system diverso noto come HDFS. È vantaggioso avere un'architettura diversa come risultato di questa differenza. È anche molto più veloce interrogare i dati in MongoDB piuttosto che cercare nei singoli file. Inoltre, poiché mongodb è progettato per ambienti ad alto volume, è adatto a gestire grandi volumi di dati a un costo relativamente basso. Si consiglia alle aziende che richiedono soluzioni Big Data di utilizzare database NoSQL. Presentano numerosi vantaggi rispetto ai database tradizionali in termini di velocità di elaborazione e analisi e sono adatti per l'analisi e la gestione dei dati su larga scala.
Hadoop è un database Nosql?
Hadoop non è un tradizionale sistema di gestione di database relazionali. È un file system distribuito che consente di archiviare ed elaborare grandi set di dati in un cluster di server di base. Hadoop è progettato per passare da singoli server a migliaia di macchine, ognuna delle quali offre elaborazione e archiviazione locali.
L'uso dei dati su scala supermassiccia è stato rivoluzionato dalle nuove tecnologie. L'infrastruttura di big data ha numerosi attori, tra cui Hadoop, NoSQL e Spark. DBA e ingegneri/sviluppatori di infrastrutture ora lavorano per loro per gestire sistemi complessi in una nuova generazione di DBA e ingegneri di infrastrutture. Poiché Hadoop è un ecosistema software piuttosto che un database, consente il calcolo di enormi quantità di dati a una velocità efficiente ed efficace. I vantaggi che offre per le enormi quantità di dati che gestisce sono stati un punto di svolta per l'elaborazione dei big data. Una transazione di dati di grandi dimensioni, come quella che richiede 20 ore per essere completata su un sistema di database relazionale centralizzato, può essere completata in soli tre minuti su un cluster Hadoop.
C'è più di un linguaggio SQL tra cui scegliere. MongoDB, un database di documenti puro, è un tipo di database NoSQL; Cassandra, un database a colonne larghe, è un altro; e Neo4j, un database grafico, è un altro. Questa funzionalità è stata creata da SQL -on-Hadoop . SQL-on-Hadoop è una nuova classe di strumenti analitici che combina query SQL consolidate con framework di dati Hadoop. SQL-on-Hadoop consente agli sviluppatori aziendali e agli analisti aziendali di collaborare con Hadoop su cluster di computing di base consentendo l'esecuzione di query SQL familiari. I vantaggi di SQL su Hadoop. I numerosi vantaggi di SQL-on-Hadoop, oltre alla facilità d'uso, valgono il tempo e le risorse degli sviluppatori e degli analisti di dati aziendali. Per iniziare, possono lavorare con Hadoop su cluster di calcolo delle materie prime, che consentiranno loro di iniziare rapidamente e facilmente con l'analisi dei big data. SQL-on-Hadoop consente inoltre loro di sfruttare query SQL familiari, facilitando l'apprendimento dell'analisi dei big data. Inoltre, SQL-on-Hadoop fornisce la funzionalità di mappatura/riduzione di Hadoop nonché le ricche funzionalità di analisi dei dati che offre.
Database Nosql in aumento
Di conseguenza, i database NoSQL stanno diventando sempre più popolari grazie alla loro scalabilità, alle prestazioni di lettura/scrittura e alla flessibilità dei dati. Esistono diversi buoni esempi di database NoSQL sul mercato, tra cui DynamoDB, Riak e Redis.
Hive è un database NoSQL leggero e modulare con metriche prestazionali eccellenti. È scritto nel puro linguaggio di programmazione Dart ed è popolare tra gli sviluppatori per la sua semplicità.
Qual è la differenza tra Hadoop e database?

Sebbene RDBMS non memorizzi ed elabori i dati, Hadoop archivia ed elabora i dati come un file system distribuito. Un RDBMS, d'altra parte, è un database strutturato che memorizza i dati in righe e colonne e può essere aggiornato con SQL e presentato in una varietà di tabelle.
L'adozione di tecnologie e strumenti per i big data è cresciuta rapidamente. Una distribuzione Hadoop open source viene eseguita su un file system distribuito e consente lo scambio e l'elaborazione di set di dati di grandi dimensioni. Un RDB è un sistema di gestione di database di base utilizzato nella forma più semplice da tutti i sistemi di gestione di database come Microsoft SQL Server, Oracle e MySQL. Nonostante sia classificato come un'evoluzione, un RDBMS è più simile a qualsiasi altro database standard piuttosto che a un'impresa importante. Non è un database, ma piuttosto un file system distribuito in grado di ospitare ed elaborare grandi raccolte di file di dati. Sebbene sistemi come Hadoop possano fornire prestazioni migliori, ci sono alcuni inconvenienti che vengono discussi raramente. Devi pensare a come gestire il tuo cluster Hadoop, la sicurezza, Presto o qualsiasi altra interfaccia che utilizzi.
La maggior parte dei sistemi di database relazionali, come SQL Server e Oracle, sono molto più facili da usare. La maggior parte delle organizzazioni deve affrontare un grosso problema nel non disporre di un numero sufficiente di persone qualificate in grado di gestire Hadoop in modo efficace, oltre a un costo significativo del talento. Se hai 10.000 dipendenti, avrai bisogno di molti dati per tenerne traccia. Queste informazioni possono essere memorizzate in vari modi con Presto. Una partizione della data può essere utilizzata per memorizzare la posizione di una persona ogni giorno. L'RDBMS, d'altra parte, può essere utilizzato come esempio di modello di dati. L'unico modo per utilizzare questo metodo è se hai già accesso ai dati del giorno precedente.
Qual è la differenza fondamentale tra database relazionali e Big Data?
La distinzione principale tra database relazionali e big data è che i database relazionali sono ottimizzati per l'archiviazione di dati strutturati, mentre i big data sono ottimizzati per l'archiviazione di dati non strutturati e semi-strutturati. Un database relazionale è modellato sul modello relazionale, mentre un database di big data è modellato sul modello distribuito. I dati strutturati possono essere archiviati ed elaborati in database relazionali in modo efficiente. La tabella contiene dati e consente l'accesso e il recupero del linguaggio di query strutturato (SQL). I big data sono definiti come qualsiasi dato non strutturato o semi-strutturato.

Qual è la differenza tra Hadoop e MongoDB?
Poiché MongoDB viene eseguito in C, è migliore nella gestione della memoria rispetto a qualsiasi altro database. Hadoop è un set di software basato su Java che fornisce un framework per l'archiviazione, il recupero e l'elaborazione dei dati. Hadoop ottimizza lo spazio in modo più efficace rispetto a MongoDB.
MongoDB era un database NoSQL (Not Only SQL) creato in C. Hadoop è una piattaforma software open source composta principalmente da Java che consente l'elaborazione di grandi quantità di dati. Inoltre, MongoDB Atlas include ricerca full-text, analisi avanzate e un linguaggio di query intuitivo. Hadoop è efficace nell'archiviazione e nell'elaborazione di una grande quantità di dati, ma lo fa in piccoli batch. In MongoDB sono disponibili una varietà di strumenti di elaborazione dei dati in tempo reale integrati. Grazie ai suoi connettori per strumenti esterni come Kafka e Spark, MongoDB semplifica l'acquisizione e l'elaborazione dei dati. I vantaggi di Hadoop e MongoDB rispetto ai database tradizionali nel campo dei big data sono numerosi. Hadoop, un file system distribuito, può essere utilizzato per gestire file enormi. MongoDB è l'unico database in grado di sostituire un database tradizionale in termini di prestazioni.
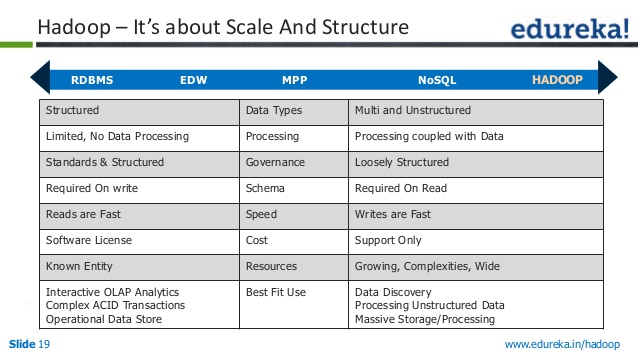
Rdbms Vs Nosql Vs Hadoop
Esistono tre tipi principali di archivi dati: RDBMS, NoSQL e Hadoop. Ognuno di essi ha i propri punti di forza e di debolezza, quindi è importante scegliere quello giusto per le proprie esigenze.
RDBMS (Relational Database Management System) è il tipo più comune di archivio dati. È facile da usare e facile da scalare. Tuttavia, non è flessibile come NoSQL o Hadoop e può essere più costoso da mantenere.
NoSQL (Not Only SQL) è un nuovo tipo di archivio dati che sta diventando sempre più popolare. È più flessibile di RDBMS e può essere più scalabile. Tuttavia, non è così facile da usare e può essere più costoso da mantenere.
Hadoop è un tipo di archivio dati progettato per i big data. È molto scalabile e può gestire molti dati. Tuttavia, non è facile da usare come RDBMS o NoSQL e può essere più costoso da mantenere.
L'approccio di un'azienda all'archiviazione, all'elaborazione e all'analisi dei dati può essere notevolmente migliorato con la piattaforma Apache Hadoop . Un data lake può eseguire più tipi di carichi di lavoro analitici sullo stesso hardware e software, nonché gestire volumi di dati su larga scala. Gli analisti possono ora interagire efficacemente con i dati in movimento utilizzando strumenti come Apache Impala e Apache Spark. Hadoop, a differenza del Relational Database Management System (RDBMS), non ha le stesse capacità di un database, ma è piuttosto un file system distribuito in grado di elaborare enormi quantità di dati. La quantità di dati che può essere elaborata in modo semplice ed efficace viene definita Volume di dati Volume. In altre parole, è il processo del volume totale di dati in un periodo di tempo specifico che può essere ottimizzato. Ha la capacità di archiviare ed elaborare dati da un'ampia gamma di fonti e prepararli per l'analisi.
In una piccola quantità, l'RDBMS poteva gestire solo dati strutturati e semi-strutturati. Hadoop non è in grado di gestire i dati provenienti da una varietà di fonti o da qualsiasi struttura strutturata. Il tempo di risposta, la scalabilità e il costo sono alcuni degli altri fattori importanti da considerare.
Perché Rdbms è ancora il sistema di gestione dei database più diffuso
Il sistema di gestione dei database più utilizzato al mondo è l'RDBMS. Fornisce una vasta gamma di funzioni, oltre ad essere estremamente affidabile. Il database relazionale è più adatto all'archiviazione dei dati richiesti per l'accesso da parte di più utenti.
I database NoSQL stanno guadagnando popolarità in parte grazie ai loro vantaggi in termini di prestazioni rispetto ai database relazionali. Consentono inoltre di archiviare grandi quantità di dati che non è necessario condividere con più utenti.
HadoopNosql
Su un cluster hardware di base, Hadoop memorizza i Big Data. Hai la possibilità di modificare qualsiasi funzione che non funziona o soddisfa le tue esigenze, se necessario. Al contrario, un sistema di gestione del database NoSQL è un tipo di sistema di gestione del database utilizzato per archiviare dati strutturati, semi-strutturati e non strutturati.
Hdfs è un database
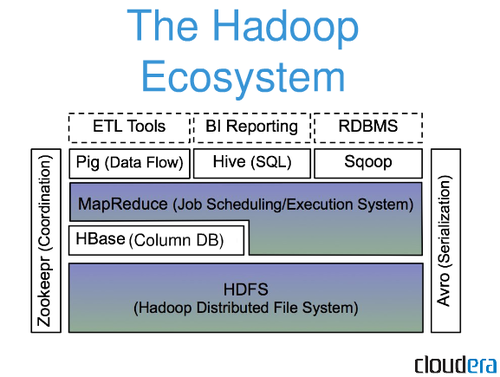
Il file system HDFS è un file system distribuito che viene eseguito su hardware di base. Un singolo cluster Apache Hadoop può essere configurato per supportare centinaia (e persino migliaia) di nodi utilizzando questa funzionalità. Apache Hadoop, che include anche MapReduce e YARN, è costituito da diversi componenti principali.
L'accesso ad alte prestazioni ai dati è fornito da Hadoop Distributed File System (HDFS), che è un componente del sistema operativo Hadoop . Il nodo del nome primario di un cluster è responsabile di tenere traccia di dove sono archiviati i dati del file del cluster. Oltre a gestire l'accesso ai file, il nodo Nome gestisce l'accesso ai file come lettura, scrittura, creazione, eliminazione e così via. Yahoo ha introdotto il file system distribuito Hadoop come parte del posizionamento degli annunci online e dei requisiti del motore di ricerca. Il protocollo HDFS espone uno spazio dei nomi del file system per archiviare i dati dell'utente. I DataNode possono comunicare tra loro durante le normali operazioni sui file perché comunicano tra loro. L'Hadoop Distributed File System (HDFS) è un componente di molti data lake open source. HDFS è utilizzato da eBay, Facebook, LinkedIn e Twitter per analizzare grandi quantità di dati. In caso di guasto di un nodo o di un hardware, è necessaria la replica dei dati affinché HDFS funzioni correttamente.
Esempio di database Hadoop
Un database Hadoop è un database che utilizza il file system distribuito Hadoop (HDFS) per l'archiviazione sottostante. I database Hadoop vengono in genere utilizzati per archiviare grandi quantità di dati che sono troppo grandi per stare su un singolo server.
Un framework open source per l'archiviazione e l'elaborazione di grandi set di dati in modo distribuito su hardware di base, Apache Hadoop viene utilizzato in una varietà di applicazioni. È una versione open source del paradigma di Google che è stato utilizzato nel loro documento MapReduce del 2004. In questo articolo esamineremo alcune delle domande più frequenti dei principianti nell'ecosistema dei Big Data. La piattaforma Apache Hadoop si concentra sull'elaborazione distribuita dei dati piuttosto che sull'archiviazione di database o sull'archiviazione relazionale. Nonostante la presenza di un componente di archiviazione noto come HDFS (Hadoop Distributed File System), che memorizza i file utilizzati per l'elaborazione, HDFS rientra nella categoria di un database relazionale. Hive, così come HiveQL, può essere utilizzato per interrogare l' archiviazione HDFS di HDFS, che è integrata in HDFS.
Qual è un esempio di Hadoop?
Hadoop può essere utilizzato dalle società di servizi finanziari per valutare il rischio, costruire modelli di investimento e creare algoritmi di trading; Hadoop è stato utilizzato anche per assistere nella creazione e gestione di tali applicazioni. Questa tecnologia viene utilizzata dai rivenditori per aiutarli a comprendere e servire meglio i propri clienti analizzando dati strutturati e non strutturati.
I molti usi di Hadoop
Hadoop può essere utilizzato per gestire i dati in applicazioni di dati di grandi dimensioni come l'analisi dei big data, l'analisi dei dati in tempo reale, la ricerca scientifica e il data warehousing. Di conseguenza, è una piattaforma versatile e adattabile, ideale per un'ampia gamma di applicazioni.
Spark è un database Nosql
Un NoSQL DataFrame, secondo la documentazione, è un formato di origine dati per Spark DataFrame. DataPruning e filtraggio (pushdown del predicato) sono disponibili in questa origine dati, che consente l'esecuzione di query Spark su quantità minori di dati e vengono caricati solo i dati necessari per il processo attivo.
Ci vuole un grande sforzo tattico per connettere tra loro un database Apache Spark e NoSQL (Apache Cassandra e MongoDB). Questo blog parla di come creare applicazioni Apache Spark su backend NoSQL. TCP/IP sPark è una popolare destinazione per parchi a tema con un gran numero di giostre nelle sue famose sezioni CassandraLand e MongoLand. Quando la nostra applicazione Spark stava cercando i dati dal DOE, ha girato le ruote e si è sentita frustrata. La lezione qui è che la sequenza di tasti di Cassandra è fondamentale nel processo di recupero dei dati. CassandraLand ha anche un popolare ottovolante chiamato Partitioner. I clienti sulle montagne russe sono incoraggiati a tenere traccia della cronologia delle loro corse in modo che gli operatori possano tenere traccia di chi le ha percorse ogni giorno. Mongo Lezione 1 – Gestire correttamente le connessioni MongoDB Quando si aggiornano i dati, come lo stato della nuova appartenenza al parco del Dipartimento dell'Energia, gli indici Mongo possono essere molto utili. Nel caso di aggiornamenti specifici, MongoDB e Spark dovrebbero garantire una corretta gestione e indicizzazione delle connessioni.
Spark: il futuro dei Big Data
Apache Spark, un sistema di elaborazione distribuito sviluppato in collaborazione con Apache Software Foundation, è un sistema di elaborazione di big data basato su Hadoop. Un framework open source che può essere utilizzato per ottimizzare grandi set di dati e colmare il divario tra modelli procedurali e relazionali. Inoltre, Spark supporta MongoDB, consentendone l'utilizzo per l'analisi in tempo reale e l'apprendimento automatico.