
Scalabilità orizzontale con database NoSQL
Pubblicato: 2022-11-20I database NoSQL sono scalabili orizzontalmente, il che significa che possono scalare aggiungendo più nodi a un sistema, al contrario del ridimensionamento verticale che si riferisce all'aggiunta di più risorse a un singolo nodo. Ciò significa che un database NoSQL può essere suddiviso in più parti e ogni parte può essere archiviata su un server separato. Ciò consente il ridimensionamento orizzontale del database, che è molto più efficiente e scalabile del ridimensionamento verticale.
Il ridimensionamento è fondamentale per i database SQL e NoSQL e il concetto di partizionamento del database ne è una parte essenziale. Stiamo suddividendo il database in blocchi (frammenti) come suggerisce il nome.
Inoltre, c'è una mancanza di capacità di operazioni dinamiche in NoSQL. Non vi è alcuna garanzia che il composto abbia proprietà ACIDE. I database SQL sono un'opzione in questi casi. Inoltre, se la tua applicazione richiede flessibilità in fase di esecuzione, evita NoSQL.
Quali sono alcuni svantaggi dei database NoSQL? Uno degli svantaggi dei database NoSQL è che mancano del supporto delle transazioni ACID (atomicità, coerenza, isolamento, durabilità) richiesto per le transazioni ACID su più documenti. Molte applicazioni possono utilizzare l'atomicità a record singolo con la corretta progettazione dello schema.
MongoDB può essere frammentato?
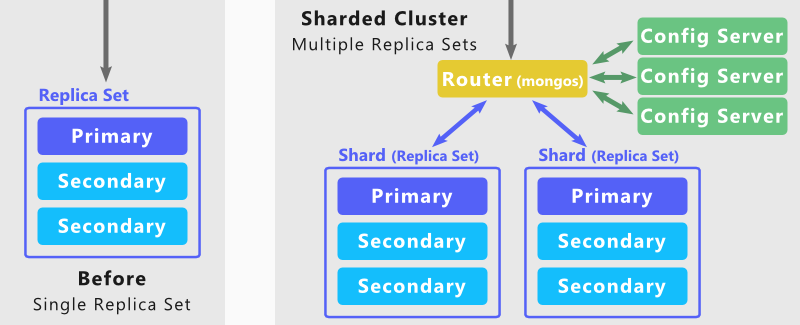
Il backend di MongoDB è costruito su un'architettura di sharding per supportare set di dati estremamente grandi e operazioni ad alto throughput. Database di grandi dimensioni con grandi quantità di dati o che eseguono applicazioni ad alta velocità possono compromettere la capacità del server.
Utilizzando MongoDB Sharding, puoi ridimensionare il tuo database per gestire un numero infinito di utenti simultanei. Ciò si ottiene aumentando il throughput di letture e scritture, nonché la capacità di archiviazione del sistema. Ci sono numerose collezioni tra cui puoi scegliere. Per massimizzare le prestazioni del cluster, scegli attentamente la chiave di partizione. Il database MongoDB NoSQL supporta due tipi di distribuzione dei dati tra cluster con funzionalità di sharding. I dati possono essere suddivisi in intervalli utilizzando il valore della chiave di intervallo di uno shard. Utilizzando l'hash hash, è possibile calcolare il valore di uno Shard con hash.
Alcune chiavi di partizione potrebbero essere chiuse, ma è improbabile che i loro valori con hash si trovino sullo stesso blocco. Configurando e attivando l'impostazione Sharding, sarà possibile accedere al database. Assicurati che i tuoi mongo siano connessi. Anche i tuoi frammenti verranno aggiunti al cluster. Ogni volta che eseguirai questa procedura, avrai completato una transazione per ogni shard. È necessario abilitare un'impostazione di sharding nel database. Quindi, utilizza il metodo sh.shardCollection() per partizionare la tua raccolta. Ora hai creato il tuo primo cluster frammentato. Fino ad ora, i router (istanze mongos) sono stati utilizzati per le interazioni tra le applicazioni.
MongoDB è un eccellente database NoSQL per le piccole e medie imprese che richiedono scalabilità e prestazioni. Inoltre, include funzionalità come lo sharding, che consente la distribuzione di documenti tra frammenti al fine di migliorare le prestazioni. Se il tuo database raggiunge i 200 GB o più, i processi di backup e ripristino potrebbero essere rallentati. Di conseguenza, ogni volta che il tuo database MongoDB cresce oltre una certa dimensione, dovresti sempre consultare il tuo provider MongoDB.
Quali database supportano lo sharding?

I database che supportano lo sharding sono in genere progettati per essere eseguiti su più server, con ogni server che ospita una parte del database. Ciò consente di distribuire il database su più server, il che può migliorare le prestazioni e la scalabilità.
Sharding in Nosql

I modelli di partizionamento basati sulle tecnologie NoSQL includono l'hashing. Il partizionamento comporta il posizionamento di ciascuna partizione in un server potenzialmente separato, possibilmente in tutto il mondo. Gli utenti di tutto il mondo possono beneficiare di questa scalabilità orizzontale, che consente loro di accedere contemporaneamente a diverse parti del set di dati.
Un set di dati viene distribuito memorizzandolo in più database per ottenere il risultato desiderato. Poiché questo approccio consente la divisione di set di dati più grandi in blocchi più piccoli, è possibile utilizzare più nodi di dati per memorizzarli. Poiché i dati sono distribuiti su più macchine, un database partizionato può gestire più richieste di quante ne possa gestire una singola macchina. Usando Sharding per gestire un aumento del carico in misura illimitata, puoi aumentare la velocità effettiva, la capacità di archiviazione e la disponibilità nel tuo database. Quando il tuo carico di lavoro è scritto principalmente per la lettura, la replica dei dati ti fornirà significativi miglioramenti delle prestazioni e potresti non dover utilizzare affatto lo sharding. È necessaria un'architettura diversa per un carico di lavoro basato principalmente sulla scrittura o su uno misto con lettura-scrittura. Esistono molti tipi e architetture diversi di sharding.

L'uso dello sharding basato su intervalli è un metodo semplice e diretto di partizione orizzontale; tuttavia, la sua efficacia sarà determinata dalla disponibilità di chiavi idonee e dalla scelta di gamme adeguate. Un record di sharding con hash o algoritmico viene applicato come input, in cui la funzione hash o l'algoritmo viene utilizzato per generare un output o un valore hash. I dati possono essere conservati in un unico spazio fisico utilizzando lo sharding basato su hash. In un database relazionale , i dati associati a una tabella specifica possono essere distribuiti su altre tabelle. Anche se non è possibile ottenere una chiave adatta, l'hashing degli input consente una distribuzione uniforme dei dati tra i frammenti. Può aiutare con operazioni di trasmissione ridotte, nonché aumentare le prestazioni. Un servizio di sharding basato sulla geografia mantiene anche i dati correlati in un unico posto su un singolo server. Uno shard a distanza è distribuito geograficamente, in cui la chiave per la chiave è una chiave geolocalizzata per gli shard. Esistono numerose altre opzioni che non sono trattate in questo articolo per l'allocazione dei geoshard.
Che cos'è lo sharding in Sql?
Un datastore può essere distribuito su più database tramite il metodo di hashing e quindi archiviato su più macchine. Ciò consente di suddividere set di dati più grandi in blocchi più piccoli e archiviarli in più nodi di dati, aumentando la capacità complessiva del sistema.
Questo algoritmo non garantisce dati partizionati in modo uniforme
Questo algoritmo, secondo questo algoritmo, garantisce che i dati saranno distribuiti uniformemente tra i frammenti, ma non garantisce che saranno distribuiti uniformemente tra i frammenti. Una riga nella colonna della partizione con il nome dati user_id verrà distribuita equamente tra i cinque frammenti; tuttavia, i valori dei dati per i cinque frammenti non saranno equamente divisi.
MongoDB usa lo sharding?
Utilizzando una combinazione di tecniche, più macchine possono condividere i dati attraverso un metodo Sharding. Quando si distribuiscono set di dati di grandi dimensioni e si eseguono operazioni a volume elevato, MongoDB utilizza lo sharding. I sistemi di database con una grande quantità di dati o applicazioni che richiedono un throughput elevato possono richiedere una quantità significativa di capacità di archiviazione.
Il futuro dello sharding: Postgresql
Fai un piano per il futuro. Non solo è possibile distribuire una soluzione di sharding, ma è anche un passaggio obbligatorio. Come parte del processo, la messa a punto e l'ottimizzazione sono richieste su base regolare. Dovresti essere consapevole del fatto che le soluzioni di sharding odierne sono in rapida evoluzione e dovresti tenerti aggiornato. PostgreSQL ha compiuto progressi significativi nello spazio di sharding negli ultimi anni, quindi se desideri una soluzione che possa essere utilizzata su più piattaforme, dovresti seriamente considerare di utilizzarla.
Nosql Sharding vs partizionamento
Il partizionamento e gli algoritmi per ordinare un grande insieme di dati in sezioni più piccole sono analoghi. I dati sono partizionati in modo da poter essere distribuiti su più computer, mentre lo sharding consente di distribuirli su più computer. In generale, i dati partizionati sono divisi in sottoinsiemi basati su una singola istanza di database .
Il partizionamento per sottrazione è un tipo di partizione, oltre al partizionamento orizzontale. Un altro metodo è la partizione verticale, in cui dividi una tabella in blocchi più piccoli. Quando si replica una partizione verticale, si parla di partizionamento verticale. Per dividere i dati, copiare lo schema e quindi utilizzare una chiave di partizione. Ecco alcuni esempi di quando è opportuno dividere un tavolo. Quando i dati sono partizionati, è spesso più semplice eseguire query. Si supponga che un'applicazione contenga una tabella Order contenente un record cronologico degli ordini e che questa tabella venga partizionata ogni settimana. Quando richiedi ordini per una sola settimana, potrai accedere solo a una partizione della tabella Ordini. Una procedura di eliminazione della partizione per questa query potrebbe teoricamente consentirne un'esecuzione 100 volte più veloce.