
Come mantenere le relazioni tra i dati in un database NoSQL
Pubblicato: 2022-11-23I database NoSQL sono sempre più popolari poiché la quantità di dati generati continua a crescere a un ritmo esponenziale. Tuttavia, c'è ancora molta confusione su come funzionano questi database e su come mantenere le relazioni tra i dati in un ambiente NoSQL. In un database SQL tradizionale, i dati vengono archiviati in tabelle e le relazioni vengono mantenute tramite chiavi esterne. In un database NoSQL, i dati vengono spesso archiviati in documenti, che sono simili agli oggetti in un linguaggio di programmazione orientato agli oggetti. I documenti possono essere nidificati, il che significa che le relazioni possono essere mantenute senza la necessità di chiavi esterne. Esistono diversi modi per mantenere le relazioni tra i dati in un database NoSQL. Il modo più comune è utilizzare i documenti di riferimento. Un documento di riferimento è un documento che contiene un riferimento a un altro documento. Ad esempio, se disponi di una raccolta di post di blog, ogni post potrebbe avere un riferimento al documento dell'autore. Un altro modo per mantenere le relazioni tra i dati in un database NoSQL consiste nell'utilizzare documenti incorporati. Un documento incorporato è un documento memorizzato all'interno di un altro documento. Ad esempio, se disponi di una raccolta di post di blog, ogni post potrebbe avere un documento incorporato che contiene le informazioni sull'autore. Il vantaggio di utilizzare documenti di riferimento o documenti incorporati è che è più facile aggiornare i dati in futuro. Ad esempio, se desideri modificare l'autore di un post sul blog, devi solo aggiornare il documento dell'autore. Non è necessario aggiornare ogni singolo post del blog. Lo svantaggio dell'utilizzo di documenti di riferimento o documenti incorporati è che può rendere i dati più difficili da interrogare. Ad esempio, se desideri trovare tutti i post del blog scritti da un determinato autore, dovrai interrogare il documento dell'autore per ciascun post. Questo può essere inefficiente se si dispone di un gran numero di documenti. Se stai lavorando con un database NoSQL, è importante capire come mantenere le relazioni tra i dati. I documenti di riferimento ei documenti incorporati sono due dei modi più comuni per farlo.
L'implementazione di NoSQL in un database orientato ai documenti è insufficiente o inesistente per lo sviluppo di relazioni tra oggetti. In questo post del blog, ti mostreremo come delegare la gestione di oggetti/relazioni a un database. Le relazioni tra oggetti vengono create utilizzando la chiamata API REST. In questo esempio, utilizzeremo il verbo PUT per collegare un cliente a un problema. Quando una relazione è rappresentata in questo modo, è sempre presente un array di oggetti. Sarai in grado di vedere le modifiche al documento originale dopo ogni riferimento a un oggetto (es. relazione). Poiché il database registra l'uso di ciascuna relazione, possiamo anche vedere dove viene utilizzato un documento specifico in una relazione. Utilizzando le query di esempio mostrate di seguito, è possibile rilevare la presenza di riferimenti impliciti a un documento utilizzando una query speciale: referencedby=true.
Esistono relazioni tra vari documenti in MongoDB, che denota la loro relazione logica. Utilizzando approcci referenziati e incorporati, è possibile modellare le relazioni. Esaminiamo il caso della memorizzazione di indirizzi per utenti con relazioni N:N nell'esempio seguente.
Le relazioni molti-a-molti (N:M) sono più difficili da implementare rispetto alle relazioni uno-a-molti perché non esiste un singolo comando in un database relazionale per farlo. Quando sono implementati in MongoDB, sono allo stesso modo. MongoDB non ti consente di creare alcun tipo di relazione per impostazione predefinita.
I database non relazionali , noti anche come "NoSQL", sono in genere database solo SQL. La loro capacità di conservare le informazioni differisce notevolmente. Un database non relazionale in genere archivia i dati in un formato non tabulare, rendendolo più adattabile alle esigenze delle moderne strutture di dati come i database SQL e NoSQL.
Un database Nosql può essere relazionale?
I database NoSQL non sono database relazionali, il che significa che possono avere strutture diverse rispetto ai database SQL (come righe e colonne) e possono essere adattati per soddisfare più facilmente le esigenze dell'utente.
I sistemi di database come quelli relazionali e NoSQL sono comunemente implementati nelle app native del cloud. La loro architettura e le pratiche di archiviazione dei dati differiscono, così come il loro accesso alle informazioni e ai dati. Un database no-SQL memorizza dati non strutturati o semi-strutturati in coppie o documenti che non hanno formattazione. Gli archivi dati NoSQL sono preferiti quando i servizi a volume elevato richiedono tempi di risposta inferiori al secondo. Se stai cercando un sistema coerente per un elemento che è attualmente in fase di aggiornamento, attendi la risposta finché tutte le repliche non vengono aggiornate correttamente. Anche se la risposta non è la più recente, ogni nodo restituirà una risposta immediata. Se un nodo di dati replicato fallisce, la tolleranza della partizione garantisce che il sistema continui a funzionare.
Il database come servizio (DBaaS) è preferito rispetto ad altri tipi di servizi dati per le applicazioni native del cloud. Questi servizi possono essere utilizzati per fornire sicurezza, scalabilità e monitoraggio. È possibile configurare una macchina virtuale di Azure e installare su di essa un database di propria scelta per ogni servizio. Un microservizio nativo del cloud può sfruttare i database relazionali o NoSQL in base ai requisiti dell'utente. La piattaforma database distribuita come servizio (DBaaS) di Azure include quattro database relazionali gestiti. Non c'è bisogno di tirarsi indietro quando si tratta di modelli just-in-time e pay-as-you-go. Il database di punta di Microsoft, SQL Server, è disponibile insieme a una serie di alternative open source.
Selezionando la quantità di core di elaborazione, memoria e spazio di archiviazione richiesti, puoi eseguire il provisioning di un database di Azure in meno di un minuto. Microsoft si impegna a mantenere Azure una piattaforma aperta, pertanto l'azienda fornisce versioni gestite dei database open source più diffusi. Il livello di elaborazione serverless sospende automaticamente i database durante i periodi di inattività, consentendo di detrarre solo i costi di archiviazione. Oracle ha acquisito Sun Microsystems e la versione gestita di MariaDB è stata creata come fork di MySQL. Il database di Azure per MariaDB è un servizio di database completamente gestito fornito come parte del cloud di Azure. Il servizio è basato sul motore del server MariaDB Community Edition. Può gestire carichi di lavoro mission-critical fornendo prestazioni prevedibili e scalabilità dinamica.
Lo strumento dell'interfaccia della riga di comando o il servizio migrazione dati di Azure sono entrambi modi eccellenti per eseguire la migrazione dei database Postgres. Oltre al supporto per il clustering attivo/attivo a livello globale, CosmosDB supporta sia le scritture che le letture, consentendo di configurare qualsiasi area del database a tale scopo. Il sistema di database CosmosDB può essere usato per eseguire la migrazione di database Mongo, Gremlin o Cassandra esistenti con modifiche minime al codice o ai dati. L'archiviazione tabelle di Azure può essere facilmente trasferita all'API di tabelle CosmosDB per i servizi che la utilizzano. La figura 5-13 contiene cinque modelli di coerenza ben definiti per Azure Cosmos DB. Queste opzioni semplificano la gestione dei compromessi tra coerenza, disponibilità e prestazioni. La tabella seguente illustra i livelli di coerenza per ciascuno.
Jeremy Likness, Program Manager di Microsoft, ha fornito un'eccellente spiegazione dei cinque modelli. Una nuova tecnologia di database nota come NewSQL combina la scalabilità distribuita con le garanzie ACID per creare un database orientato agli oggetti. Quando gli ambienti cloud sono effimeri, ha senso che i nuovi database SQL possano prosperare grazie alla presenza di macchine virtuali sottostanti che possono essere riavviate o riprogrammate in qualsiasi momento. La cifra precedente include i progetti open source creati dalla Cloud Native Computing Foundation. A differenza di altri carichi di lavoro, che utilizzano un costrutto Service, un client può inviare una singola richiesta DNS a un gruppo di processi di database NewSQL identici. Possiamo ridimensionare senza influire sulla disponibilità delle istanze dell'applicazione esistenti se disaccoppiamo le istanze del database dagli indirizzi dei servizi ad esse associati. Una specifica richiesta ad un servizio produrrà sempre lo stesso risultato indipendentemente dal numero di richieste inviate contemporaneamente.
A causa dei loro numerosi vantaggi, i database NoSQL stanno rapidamente diventando sempre più popolari. La capacità di scalare orizzontalmente, gestire più dati, archiviare i dati in modo più flessibile e integrarsi con altri sistemi sono tutti vantaggi del cloud computing. Ci sono una serie di vantaggi per i database NoSQL rispetto ai tradizionali database relazionali .
MongoDB può essere relazionale?
Oltre ad essere un sistema di database non relazionale ben consolidato con una maggiore flessibilità e scalabilità orizzontale, MongoDB presenta alcuni vantaggi rispetto ai database relazionali, come l'integrità referenziale e la concorrenza.
Snowflake è un database relazionale?
Non sorprende che Snowflake sia un potente database relazionale. Puoi usarlo con tutti i principali modelli di dati relazionali, inclusi i tre standard (tabelle, relazione e join) e il più insolito modello a fiocco di neve. Il database supporta anche lo streaming in tempo reale, l'indicizzazione degli oggetti e l'accelerazione delle query, oltre a tutte le moderne funzionalità dei database relazionali presenti nei database moderni . È relazionale o no? Questo database è un database relazionale.
Quale database Nosql non supporta relazioni o join?

Esistono alcuni database nosql che non supportano relazioni o join, inclusi MongoDB, Cassandra e Hbase. Sebbene questi database non siano così popolari come alcuni degli altri, sono ancora utilizzati da molte organizzazioni.
Il database Oracle NoSQL non supporta l'operatore di join generale utilizzato nei database relazionali tradizionali. Tuttavia, fornisce un tipo speciale di join per le tabelle con la stessa gerarchia. Di conseguenza, l'esecuzione dei join è molto semplice perché possono corrispondere solo le righe nella stessa posizione.
Relazione tra entità in Nosql
Una relazione di entità in nosql è una relazione tra due o più entità in un database nosql. Questa relazione può essere uno a uno, uno a molti o molti a molti.
Er diagrammi per database di documenti
Tuttavia, è possibile utilizzare i principi di modellazione ER per costruire un diagramma ER per un database orientato ai documenti in modo simile. Crea un modello di dati che può essere utilizzato per archiviare i tuoi documenti. I tipi di documenti che intendi archiviare, i campi e le proprietà di ciascun documento e il modello nel suo complesso devono essere tutti inclusi in questo modello di dati. Per creare il modello di dati è necessario un diagramma di entità. Il diagramma seguente mostrerà la struttura dei dati nel tuo archivio documenti. Quindi, utilizzando il diagramma delle relazioni, crea un modello di dati. Il diagramma seguente illustra la relazione tra le entità all'interno del modello di dati.
Relazione molti-a-molti in Nosql
Una relazione numero-a-molti è quella in cui due entità possono essere collegate da più istanze della stessa entità. Ci sono alcuni esempi di vita reale: i medici possono curare molti pazienti pur avendo molti medici.
Voglio implementare una struttura tassonomica (termini geografici) per la mia applicazione node.js con un database NoSQL. L'idea alla base dei tag geografici era identificare le persone nate in determinate città o paesi con quei termini, filtrarle in un secondo momento e taggarle. John Doe è nato a Blackburn (Lancashire) nel 1957, Paul Brown a Liverpool nel 1960 e Georgia Doe a Wirral nel 1982. Se ci sono solo pochi elementi strutturali nel paese che seguono quelli moderni, saranno filtrati in modo tale da non sono possibili. Sono un principiante nel mondo NoSQL (non ho progettato alcun database NoSQL, quindi ho una seria sfida di progettazione davanti a me). Credo che ci siano diverse opzioni per risolverlo.

Notazione del piede di corvo: la relazione molti-a-molti
Di solito vedrai Crow's Foot Notation in un database quando rappresenti graficamente un numero da molte relazioni. Le relazioni tra tabelle sono rappresentate da una serie di linee, secondo questa notazione. Le origini di un grafico (angolo in alto a sinistra) di solito iniziano con una linea che scende alla tabella denominata "straniera" (perché è lì che si trova l'origine). Successivamente, le righe andranno alla tabella correlata, seguita dalla tabella figlia.
Documentazione Nosql
La documentazione Nosql è un processo o un insieme di regole utilizzate per scrivere codice nosql . È uno stile di codifica progettato per rendere il codice nosql più leggibile e più facile da capire.
I database NoSQL, a differenza dei database relazionali tradizionali, non memorizzano i dati in un formato fisso. I tipi più comuni sono documenti, valori chiave, colonne larghe e grafici. Alla fine degli anni 2000, una significativa riduzione dei costi di archiviazione ha portato allo sviluppo di database NoSQL. Gli sviluppatori possono utilizzare questi strumenti per archiviare enormi quantità di dati non strutturati, consentendo loro di lavorare su un'ampia gamma di progetti. Database di documenti, database di valori-chiave, archivi a colonne larghe e database a grafo sono alcuni dei database NoSQL più comuni. Poiché non sono richiesti join, le query sono più veloci. I casi d'uso più comuni includono applicazioni critiche (ad es. dati finanziari) e più divertenti (ad es. memorizzazione di letture IoT da una lettiera intelligente per gatti).
In questo tutorial, vedremo come funziona un database NoSQL e perché è vantaggioso per una varietà di applicazioni. Inoltre, esamineremo alcuni malintesi comuni sui database NoSQL e le loro applicazioni. Secondo DB-Engines, MongoDB è il database non relazionale più utilizzato al mondo. Non hai bisogno di alcun software sul tuo computer per interrogare un database MongoDB in questo tutorial. Un cluster è una raccolta di database in cui sono archiviati i database MongoDB . L'archivio dati Atlas è accessibile quando si dispone di un cluster. Esistono tre tipi di database che è possibile creare: manualmente in Atlas Data Explorer, in MongoDB Shell o in MongoDB Compass, a seconda del linguaggio di programmazione preferito.
Questo esempio mostrerà come importare il set di dati di esempio di Atlas. Un database NoSQL può fornire una serie di vantaggi agli sviluppatori, come modelli di dati flessibili, ridimensionamento orizzontale, query velocissime e facilità d'uso. È possibile inserire nuovi documenti, modificare quelli esistenti ed eliminare documenti in Esplora dati. Utilizzando il framework di aggregazione, puoi analizzare i tuoi dati in modo molto potente. È possibile visualizzare facilmente i dati Atlas e Atlas Data Lake sui grafici.
Query Nosql
I database NoSQL vengono spesso utilizzati quando la scalabilità è più importante della coerenza dei dati. I database NoSQL sono talvolta chiamati anche "non solo SQL" per sottolineare che possono supportare linguaggi di query simili a SQL.
In precedenza, i modelli di dati ei sistemi di query erano strettamente integrati. Ora possiamo creare sistemi di database che danno priorità alla produttività degli sviluppatori e iniziare ad astrarre il metodo di query dal modello di dati per dare priorità alla produttività degli sviluppatori. SABRE, il primo database commerciale al mondo, è stato fondato nel 1994 da IBM e American Airlines per migliorare l'efficienza dei biglietti aerei. I database NoSQL sono stati ottimizzati per scalabilità, tempo di attività, ridondanza, flessibilità e flessibilità negli ultimi anni. Oltre ad aggiungere map-reduce come opzione in Riak e MongoDB, l'hanno aggiunto anche a CouchDB e Riak. Ci aspettavamo una semplice query dichiarativa ad hoc da SQL, ma si è rivelato essere più un trucco di scripting. Se stai costruendo un sistema di database facilmente scalabile, la query non è il tuo obiettivo principale.
XQuery e Jsoniq sono tentativi di creare un linguaggio di query standard che può essere utilizzato per recuperare documenti gerarchici nei database di documenti. MarkLogic, un database di documenti XML, utilizza XQuery oltre a XQuery, mentre ArrangoDB utilizza il proprio superset ottimizzato per la modellazione dei dati. Entrambe le lingue hanno una forte connessione con il formato dei dati memorizzati sul disco ed entrambe sono state utilizzate commercialmente. Uno o entrambi i linguaggi di query utilizzati in un database di documenti sono correlati ai linguaggi di query utilizzati nel database. N1QL (o linguaggio di query non in prima forma), al contrario di SQL, è di natura estremamente simile a SQL. Nonostante i rapporti non siano imposti, collaboriamo sui documenti, indipendentemente dal fatto che siano formali o informali. Sia Couchbase che Cassandra hanno dedicato molto tempo e impegno ai loro indici e analisi delle query in modo da poter interrogare i dati in questo modo senza la necessità di una ricerca relazionale.
Puoi eseguire query in Nosql?
Il nome NoSQL non si riferisce a SQL. SQL non è il metodo preferito per la scrittura di query in No SQL. Il software non memorizza i dati in formato relazionale, ma piuttosto in modo organizzato.
Che cos'è l'esempio di Nosql?
I database NoSQL basati su colonne, come Cassandra, HBase e Hypertable, sono comuni.
Nosql è più facile di Sql?
I database SQL hanno il vantaggio di elaborare query e unire i dati tra tabelle, consentendo query più complesse su dati strutturati, come richieste ad hoc. La coerenza di un database NoSQL tra i prodotti, in particolare quando si tratta di grandi quantità di dati, è una caratteristica comune in questo tipo di database.
Modello di dati Nosql
Che cos'è un modello di dati NoSQL? Quali sono i pro e i contro? Non esiste un sistema di gestione di database relazionali (RDBMS) e questo è un modello impossibile da replicare. Di conseguenza, non esiste un modo esplicito per il modello di comprendere come si relazionano i dati, come si combinano tutti.
8 Modelli di modellazione dei dati in Redis copre i fondamenti della modellazione dei dati in NoSQL, nonché le migliori pratiche per iniziare. Il libro esamina otto modelli di dati che gli sviluppatori possono utilizzare per creare applicazioni moderne senza le difficoltà che possono porre i database tradizionali . Utilizzando NoSQL, puoi combinare due tabelle o raccolte separate per creare un'unica tabella o raccolta. Di conseguenza, è più facile trovare tutti i dati rilevanti e comprendere la loro relazione. Ogni tabella in NoSQL può essere visualizzata da sola. Quando si desidera modellare le relazioni uno-a-molti, si incorporano separatamente gli elenchi delimitati (come elenchi con dimensioni note) e gli elenchi illimitati. Il prodotto in questo caso è quello, e le tante recensioni, nomi degli autori, date di pubblicazione, rating e commenti sono le 'molte' variabili.
Il primo modello è una relazione numero-a-molti con lati illimitati. L'obiettivo di un database relazionale è archiviare i prodotti in tabelle separate. Poiché gli schemi sono così flessibili e consentono di separare i campi di tipo in base al tipo di raccolte, tutti gli schemi Redis Stack possono essere configurati con questa funzionalità. Man mano che accumuli e aggreghi dati di serie temporali, il modello di bucket riduce l'overhead. Un modello di revisione può essere utilizzato in una varietà di contesti in cui sono richiesti dati in tempo reale. Questi modelli possono essere utilizzati per eliminare le complicazioni associate alle operazioni JOIN in NoSQL. Il Tree and Graph Pattern è particolarmente utile per una varietà di operazioni pesanti basate su JOIN, come risorse umane, CMS, cataloghi di prodotti e social network.
Questo modello non è supportato da un sistema di gestione di database relazionali (RDBMS) perché è basato su un modello che non è supportato da uno. L'archiviazione dei dati può essere eseguita in vari modi, incluso l'uso del disco, in memoria o entrambi. Redis Launchpad ha una serie di applicazioni scritte utilizzando NoSQL e Redis.
Documento Application Nosql Data
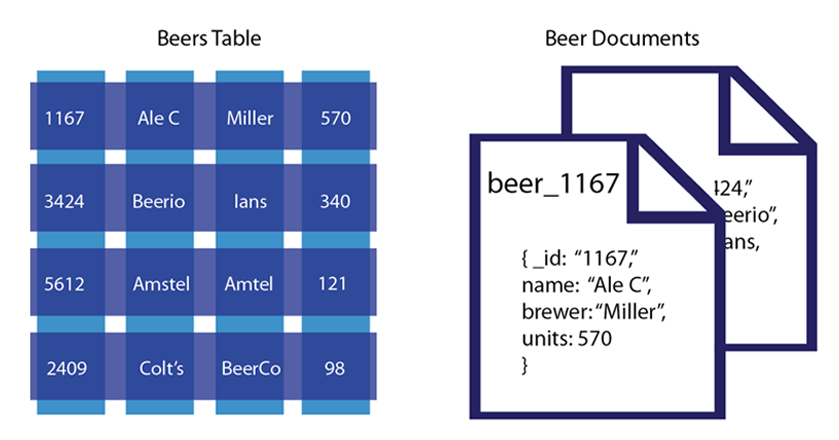
Esistono molti motivi per utilizzare un'applicazione per documenti per archiviare i dati. In primo luogo, i database di documenti sono molto flessibili e possono facilmente memorizzare i dati in una varietà di formati. Ciò significa che puoi archiviare i dati in formato JSON, XML o anche binario, se lo desideri. In secondo luogo, i database di documenti sono spesso più facili da scalare rispetto ai tradizionali database relazionali. Questo perché possono essere frammentati su più server molto facilmente. Infine, i database di documenti spesso forniscono prestazioni migliori rispetto ai database relazionali per determinati tipi di query.
I dati nei database orientati ai documenti sono archiviati in formato JSON anziché in colonne/righe, come in altri database moderni. Questo tipo di dati ti consente di gestire sfide che sono molto più difficili da gestire con gli RDBMS. Gli archivi di documenti consentono agli sviluppatori di collaborare più rapidamente con software agili, rendendoli una soluzione naturale e adattabile. Il linguaggio di query espressivo e la funzione di indice multiforme semplificano le query in vari modi. Utilizzando le transazioni ACID, puoi mantenere tutte le garanzie che sei abituato ad avere in un database relazionale. I tuoi dati possono diventare infinitamente scalabili e resilienti grazie ai sistemi distribuiti. Ogni documento è ospitato separatamente ed è più facilmente distribuito tra i server per garantire che la località dei dati non ne risenta.
I database di documenti, a differenza dei database relazionali, utilizzano modelli pratici e intuitivi che possono essere letti più velocemente. Poiché la qualità dei dati sarà inferiore, ci saranno tabelle meno rigide. Poiché non esiste il ridimensionamento nativo, se desideri partizionare il tuo database relazionale tradizionale , dovrai pagare per costosi sistemi di ridimensionamento. Ogni archivio di documenti in un database orientato ai documenti contiene campi per diversi tipi di documenti e sono facoltativi. Mentre ogni documento ha la stessa composizione strutturale, ci sono campi distinti in ogni documento. Ogni documento ha il proprio ID univoco che può essere utilizzato per aggiungere, modificare, eliminare e richiedere informazioni. Si presume generalmente che la codifica dei documenti includa un formato standard o la compressione di dati (o informazioni) incapsulati.
I database orientati ai documenti differiscono dai database convenzionali in quanto sono molto più flessibili e non richiedono coerenza. Invece di inviare i dati alle colonne all'interno del database, i dati vengono recuperati direttamente dal documento. Non è necessario aggiungere nuovi campi di informazioni a ogni set di dati, solo quelli pertinenti nell'archivio documenti.
La differenza tra MongoDB e Sql
È importante notare che i documenti sono distinti. Non c'è limite al numero di campi che possono essere inclusi in un documento. I tipi di documento possono anche contenere campi ad essi correlati. Un documento, ad esempio, potrebbe rappresentare un cliente in un database. Il documento includerebbe il nome completo, l'indirizzo e il numero di telefono del cliente. Nei campi possono essere inclusi anche lo storico degli ordini e il saldo del conto del cliente.
La differenza tra MongoDB e SQL è che i database non sono tabelle e nemmeno i documenti sono tabelle. MongoDB non ha una raccolta di campi come fa SQL. Le raccolte di documenti, invece, sono costituite da campi correlati.