
Come archiviare dati strutturati in un database NoSQL
Pubblicato: 2022-11-17I database NoSQL vengono spesso utilizzati per archiviare dati non strutturati , ma possono anche essere utilizzati per archiviare dati strutturati. Esistono diversi modi per archiviare dati strutturati in un database NoSQL e il metodo più appropriato dipenderà dai dati specifici e dal risultato desiderato. Un modo per archiviare dati strutturati in un database NoSQL consiste nell'utilizzare un approccio orientato ai documenti. Ciò significa che i dati vengono archiviati in documenti, che vengono poi organizzati in raccolte. Un altro modo per archiviare dati strutturati in un database NoSQL consiste nell'utilizzare un approccio chiave-valore. Ciò significa che i dati vengono archiviati in un archivio chiave-valore, in cui ogni chiave corrisponde a un valore. Infine, un approccio orientato ai grafici può essere utilizzato anche per archiviare dati strutturati in un database NoSQL. Ciò significa che i dati sono memorizzati in un grafico, dove i nodi rappresentano i dati e gli spigoli rappresentano le relazioni tra i dati.
Il termine "dati non strutturati" ha una vasta gamma di connotazioni ed è probabile che significhi qualcosa di diverso per persone diverse. RDBMS, poiché si aspetta che tu definisca tutto, si aspetta che tu lo faccia in modo anticipato (ad esempio, sarebbe difficile gestire i dati con un nome e un tipo di colonna (come questo). Quando un utente ha visitato l'ultima volta un paese specifico, vorresti sapere quante volte lo hanno visitato.In un database No. SQL, è possibile modellare la tabella in modo tale che il nome della cella corrisponda al nome della tabella.BLOB può essere archiviati in modo sicuro in qualsiasi RDBMS, incluso Oracle Database e altri database relazionali.Il valore della chiave non può essere specificato nei casi di CLOB e BLOB.Poiché sono semi-strutturati (JSON, XML, non tutti i campi sono noti), sono distinti dalla loro natura non strutturata.
I database NoSQL vengono spesso utilizzati per gestire dati semi-strutturati. I dispositivi IIoT generano dati strutturati, non strutturati e semi-strutturati in tempo reale. È semplice gestire ed elaborare dati strutturati quando la struttura è definita dal venditore.
Hadoop può aiutare una struttura aziendale e dare un senso a modelli e tendenze nascosti all'interno di grandi quantità di dati generati da una varietà di fonti, specialmente nell'era di enormi quantità di dati. È ovvio che le capacità superiori di Hadoop per i dati non strutturati non possono essere sopravvalutate, ma può anche essere utilizzato per risolvere problemi complessi relativi ai dati strutturati.
Per le aziende che elaborano e analizzano grandi quantità di dati vari e non strutturati, come i Big Data, NoSQL è un'opzione migliore. I database NoSQL non hanno gli stessi vincoli dei database relazionali su quali dati possono essere archiviati.
MongoDB può archiviare dati strutturati?

Sì, MongoDB può archiviare dati strutturati. Lo fa utilizzando BSON (Binary JSON) per archiviare i dati in un formato binario. BSON è un superset di JSON, quindi qualsiasi documento JSON può essere archiviato in un database MongoDB .
MongoDB, ad esempio, è cresciuto in popolarità negli ultimi anni a causa di una varietà di fattori. Un'applicazione su larga scala, in cui i dati non possono essere strutturati e devono essere archiviati in modo flessibile, si adatta bene al cloud storage. Poiché MongoDB è classificato come database non strutturato, utilizza un approccio diverso all'archiviazione dei dati . Poiché JSON è un tipo di dati che può essere formattato in vari modi, i file di testo e altri asset non strutturati vengono mantenuti in questo formato. MongoDB è adatto a gestire grandi volumi di dati perché è stato creato per questo scopo. MongoDB può gestire facilmente grandi volumi di dati perché è fisicamente impossibile gestirli.
Che tipo di dati memorizza Nosql?
I database NoSQL vengono utilizzati per archiviare dati non strutturati, il che significa che non si adattano perfettamente a un formato di tabella tradizionale. Ciò potrebbe includere cose come post sui social media, commenti, immagini o qualsiasi altra cosa che non si adatta a una struttura di database tradizionale . Poiché i database NoSQL sono più flessibili, possono essere una buona scelta per le applicazioni che richiedono un accesso rapido e semplice a grandi quantità di dati.
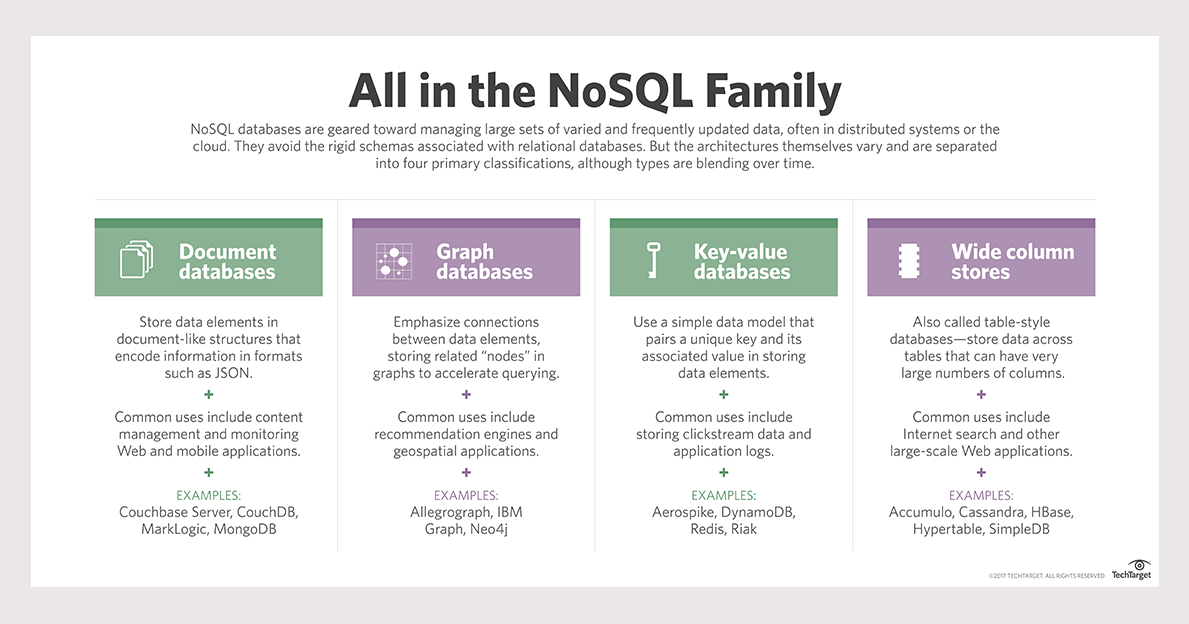
Il termine "database non relazionale" si riferisce a un database che non ha una struttura fissa. L'archivio chiave-valore, i database orientati alle colonne, basati sui documenti, a grafo e a grafo sono i tipi più comuni di database. Nel mondo NoSQL, i database chiave-valore sono tra i tipi più semplici di database da utilizzare. I dati vengono archiviati, raccolti e rimossi utilizzando un semplice insieme di funzioni. Un database archivio chiave-valore non dispone di un linguaggio di query che può essere utilizzato. I tipi di dati sono determinati dai requisiti delle applicazioni che li elaborano. Il caso d'uso più comune dei database chiave-valore è la registrazione di sessioni in applicazioni che richiedono un accesso.
Oltre al caso d'uso più generale, un carrello della spesa consente ai siti di e-commerce di memorizzare i dati sulla sessione di acquisto di ciascun utente. Quando sono attivi i saldi delle festività e le promozioni speciali, la scalabilità dei negozi di valore-chiave è utile. Inoltre, il sistema dispone di ridondanza integrata in modo che nessun articolo di un carrello vada mai perso. I database chiave-valore hanno uno scopo specifico e includono funzionalità che aggiungono valore ad alcuni mentre impongono limitazioni ad altri.
Il linguaggio di programmazione MongoDB non è solo popolare, ma è anche estremamente flessibile. Di conseguenza, è possibile espandere il numero di server per gestire il carico aggiuntivo. Inoltre, la funzionalità di replica di MongoDB garantisce che i dati siano sempre aggiornati e in più posizioni. Di conseguenza, MongoDB è un'opzione molto interessante per le grandi organizzazioni che desiderano mantenere i dati affidabili e coerenti.
Nosql è dati non strutturati o dati semi-strutturati?
I database non relazionali vengono utilizzati per archiviare dati strutturati e non strutturati in NoSQL (piuttosto che solo linguaggi di query strutturati). A causa dell'elevata scalabilità e della facilità di ricerca, NoSQL è ideale per i dati non strutturati.

I dati possono essere archiviati in una varietà di formati, come fogli di calcolo, testo e video o persino file audio. Si tratta di un tipo di dati che viene archiviato nella memoria e dovrebbe avere una struttura predefinita prima di essere archiviato. Un set di dati non strutturati è un set di dati che non può essere archiviato in un database relazionale perché manca di un modello di dati predefinito. Dati non strutturati è un termine che si riferisce a dati non strutturati che non sono strutturati ma contengono una qualche forma di metadati che possono essere utilizzati per trovare la struttura dei dati o la gerarchia dei dati. Ingegneri e scienziati in Machine Learning e Intelligenza Artificiale analizzano questo tipo di dati utilizzando tecniche come l'apprendimento automatico e l'intelligenza artificiale per estrarre il significato (o anche una struttura di alto livello). Include e-mail e altri documenti in un formato simile ma contiene metadati che consentono agli utenti di accedere a informazioni specifiche a un livello specifico, indipendentemente dal formato. In questo articolo abbiamo coperto alcuni esempi reali di ciascuno dei diversi tipi di dati e abbiamo anche esaminato il modo in cui vengono utilizzati nelle organizzazioni moderne.
I dati strutturati vengono generalmente archiviati in database (che vengono successivamente utilizzati per il data warehousing). I dati non strutturati vengono archiviati in database non relazionali o Data Lake perché non esiste uno schema predefinito che deve essere seguito per classificare i dati. Per i dati semi-strutturati e basati sulla gerarchia, MongoDB è una buona opzione.
I sistemi di database NoSQL sono cresciuti in popolarità grazie alla loro scalabilità e flessibilità. Questo metodo di memorizzazione dei dati è ideale per dati non strutturati e semistrutturati, oltre che per dati semistrutturati e non strutturati. Poiché è più facile lavorare con i dati in modo più agile, sono ideali per lo sviluppo iterativo.
Archiviazione di dati non strutturati
Un sistema di archiviazione dati non strutturato è un file system che non impone alcuna struttura ai dati che memorizza. I dati vengono semplicemente archiviati come file flat, senza alcuna struttura imposta dal file system. Questo tipo di sistema di archiviazione viene in genere utilizzato per archiviare testo o dati binari, come le immagini, che non devono essere organizzati in alcun modo particolare.
Questa categoria comprende circa l'80% dei dati non strutturati. Il volume, la varietà e la velocità dei dati non strutturati ne rendono difficile l'archiviazione. I sistemi di archiviazione che sono stati tradizionalmente costruiti per gestire grandi quantità di dati non strutturati potrebbero non essere in grado di farlo in futuro. Di conseguenza, la tua infrastruttura di archiviazione dei dati deve essere in grado di gestire un gran numero di transazioni e di scalare. Quando si sviluppa un progetto Big Data, è fondamentale che le aziende pianifichino in anticipo l'archiviazione dei dati non strutturati. È fondamentale selezionare un'infrastruttura di storage che sia agile, conveniente, scalabile e adattata a un'ampia gamma di casi d'uso. Un database Nosql (Norelational) è un modo eccellente per archiviare queste informazioni.
MongoDB Atlas o altri database cloud , come MongoDB as a Service (DaaS), sono opzioni eccellenti. Un database MongoDB memorizza i dati in un formato BSON (simile a JSON) basato su documenti. Gli attributi di un documento variano a seconda del tipo di dati. Poiché i dati vengono sottoposti a backup e possono essere replicati, gli archivi di documenti sono altamente scalabili e disponibili per la progettazione. La piattaforma MongoDB Atlas database-as-a-service utilizza le principali piattaforme cloud come AWS, Azure e Google Cloud per l'archiviazione dei database. Prima di poter accedere a un data warehouse, è necessario eseguire una fase di estrazione, trasformazione e caricamento (ETL) sui dati non strutturati. I data warehouse elaborano e archiviano i dati da una varietà di fonti per garantire che siano pronti per l'analisi. I data lake memorizzano tutti i dati nel loro formato nativo, che è un mix di dati grezzi ed elaborati.
Grazie alla sua semplicità, leggerezza e facilità di elaborazione, JSON è ideale per l'archiviazione di dati non strutturati. Può essere facilmente convertito in una varietà di formati, inclusi HDFS, Cassandra e MongoDB, tutti supportati da questa applicazione. Poiché non era necessario unire i dati, la nostra soluzione era semplice da implementare. Utilizzando la funzione json_archive, potremmo creare file separati per ogni oggetto JSON. Un database relazionale può archiviare dati non strutturati in vari modi. Per iniziare, i database relazionali sono il modo più efficiente per archiviare ed eseguire query su grandi quantità di dati non strutturati. Consentono una compressione altamente efficiente di grandi quantità di dati e in molti casi sono inclusi linguaggi di query, semantica e altri meccanismi che servono tipi di dati specifici. In secondo luogo, la struttura del database relazionale facilita l'interrogazione dei dati. Ogni record viene archiviato come un singolo oggetto JSON in un database relazionale e tutti i suoi dati vengono archiviati come uno solo. Che tu stia cercando un record specifico o un set completo di record, sarai in grado di trovare le informazioni di cui hai bisogno. Il terzo vantaggio di un database relazionale è che è in grado di gestire grandi quantità di dati. Oltre a poter archiviare decine di milioni di record, sono in grado di gestire query complesse.
Dati non strutturati: cosa, dove e come archiviarli
Nonostante il fatto che i dati non strutturati possano essere archiviati in qualsiasi formato, in genere vengono archiviati in un formato di testo o non di testo. I dati non strutturati, in generale, richiedono una maggiore capacità di archiviazione perché non rientrano in una struttura predefinita. Il cloud storage offre sicurezza e la possibilità di accedere ai dati da qualsiasi luogo, rendendolo un'opzione eccellente per i dati non strutturati. L'utilizzo dell'archiviazione di file è un buon modo per archiviare grandi quantità di dati al fine di organizzarli. Questo software si basa sull'archiviazione basata sul percorso, il che significa che le cartelle e le directory vengono utilizzate per archiviare i dati. È fondamentale sapere dove risiedono i dati in un sistema di archiviazione file se devono essere trovati.