
InfluxDB: un database di serie temporali
Pubblicato: 2022-11-18InfluxDB è un database di serie temporali scritto in Go e sviluppato da InfluxData. È progettato per essere scalabile, con particolare attenzione a prestazioni di scrittura elevate e query rapide. È anche open source, con una versione community e una versione enterprise. InfluxDB viene spesso utilizzato insieme a Grafana, uno strumento di visualizzazione dei dati open source. InfluxDB è una scelta popolare per i dati delle serie temporali, grazie alle sue elevate prestazioni di scrittura e alle query veloci. È anche open source, il che lo rende attraente per molti sviluppatori.
Per effettuare un confronto, abbiamo utilizzato recensioni di utenti PeerSpot reali per confrontare InfluxDB con Oracle NoSQL . In questo articolo, confronteremo le funzionalità, i prezzi, il servizio e il supporto, la facilità di implementazione e il ROI dei database NoSQL per scoprire quale è più adatto alla tua azienda. Dal 2012, la nostra ricerca è stata utilizzata da 648.701 professionisti. InfluxDB, che è un'offerta basata su cloud, ha la caratteristica migliore, che è il DB serie temporale, le query rapide in blocco e le operazioni di finestra. Ci sono alcuni problemi con l'API in blocco per InfluxDB, che è incompatibile con i dati ad alta cardinalità. Usa il nostro motore di raccomandazione gratuito per determinare quale database NoSQL soddisferà al meglio le tue esigenze. InluxDB è un programma software open source gratuito che consente agli sviluppatori e alle aziende di gestire i dati delle serie temporali.
InfluxDB ti consente di monitorare e analizzare Internet of Things (IoT), applicazioni, sistemi, container e infrastruttura. Un revisore ha citato l'aggregazione e l'integrazione dei dati con Grafana come le caratteristiche più importanti. Il database Oracle NoSQL è concepito per essere un sistema di database molto grande e altamente disponibile. Sono disponibili operazioni complete di creazione, lettura, aggiornamento ed eliminazione (CRUD), oltre a una varietà di garanzie di durabilità e coerenza. Con quattro recensioni, InfluxDB è al quinto posto nel mercato dei database NoSQL, dietro solo a Oracle No SQL, che è al settimo posto con una. Essendo il database più consigliato, ha un'interfaccia molto semplice ed è leggero e potente.
InfluxDB non è un database relazionale perché non include chiavi primarie o esterne, nessun join di misurazioni e così via. tag come soluzione: i tag sono usati come soluzione in teoria, ma sono appropriati solo per dati con cardinalità bassa. Avrai bisogno di una grande quantità di memoria se hai molti record con un tag ID univoco.
Il database influxDB è simile a un database SQL, ma ci sono diverse differenze. Questo database è specificamente progettato per gestire i dati delle serie temporali. Nonostante il fatto che i database relazionali possano gestire i dati delle serie temporali, non sono ottimizzati per i carichi di lavoro delle serie temporali comuni.
InfluxDB Cloud è una piattaforma di dati di serie temporali completamente gestita ed elastica che consente agli utenti di iniziare rapidamente e scalare rapidamente per soddisfare le loro esigenze.
Un database di serie temporali (TSDB) creato da InfluxData è un database open source. I dati delle serie temporali, come le operazioni, le metriche dell'applicazione, i dati dei sensori dell'Internet of Things e l'analisi in tempo reale, possono essere archiviati e recuperati utilizzando questa libreria in Go.
Graphql è uno Sql o Nosql?
In GraphQL, utilizziamo un sistema di tipi per restituire in modo efficiente i dati nelle query dinamiche, che sono un linguaggio di query basato sui tipi. SQL (linguaggio di query strutturato) è uno standard più vecchio e più ampiamente utilizzato per la progettazione, l'implementazione e la gestione di strutture di dati in database tabulari e gerarchici. Se desideri utilizzare un database NoSQL per la tua API, scegli GraphQL.
Entrambi i database Type Mismatch e GraphQL sono stati creati da Cochrane e Herman Camarena. Un sistema di tipi può essere introdotto utilizzando GraphQL piuttosto che un sistema NoSQL perché possiamo ancora sfruttare i vantaggi di NoSQL. La struttura del documento in una raccolta GraphQL varia leggermente da un documento all'altro, con alcune eccezioni. Grazie alle API GraphQL, uno sviluppatore può scegliere quali tipi di dati desidera che corrispondano approssimativamente ai tipi di backend. Per realizzare il pieno potenziale di GraphQL, è necessario affrontare il problema delle discrepanze di tipo. Come lingua, ha molti vantaggi, che rendono meno grave il problema della mancata corrispondenza. Utilizzando strumenti come JSON2SDL di StepZen, sarai in grado di automatizzare ulteriormente il lavoro.
Graphql è indipendente dalle origini dati
Non è indipendente da alcuna origine dati per la quale vengono archiviate o recuperate le modifiche. È possibile accedere ai dati e manipolarli utilizzando funzioni arbitrarie note come risolutori.
Influx Sql o Nosql?
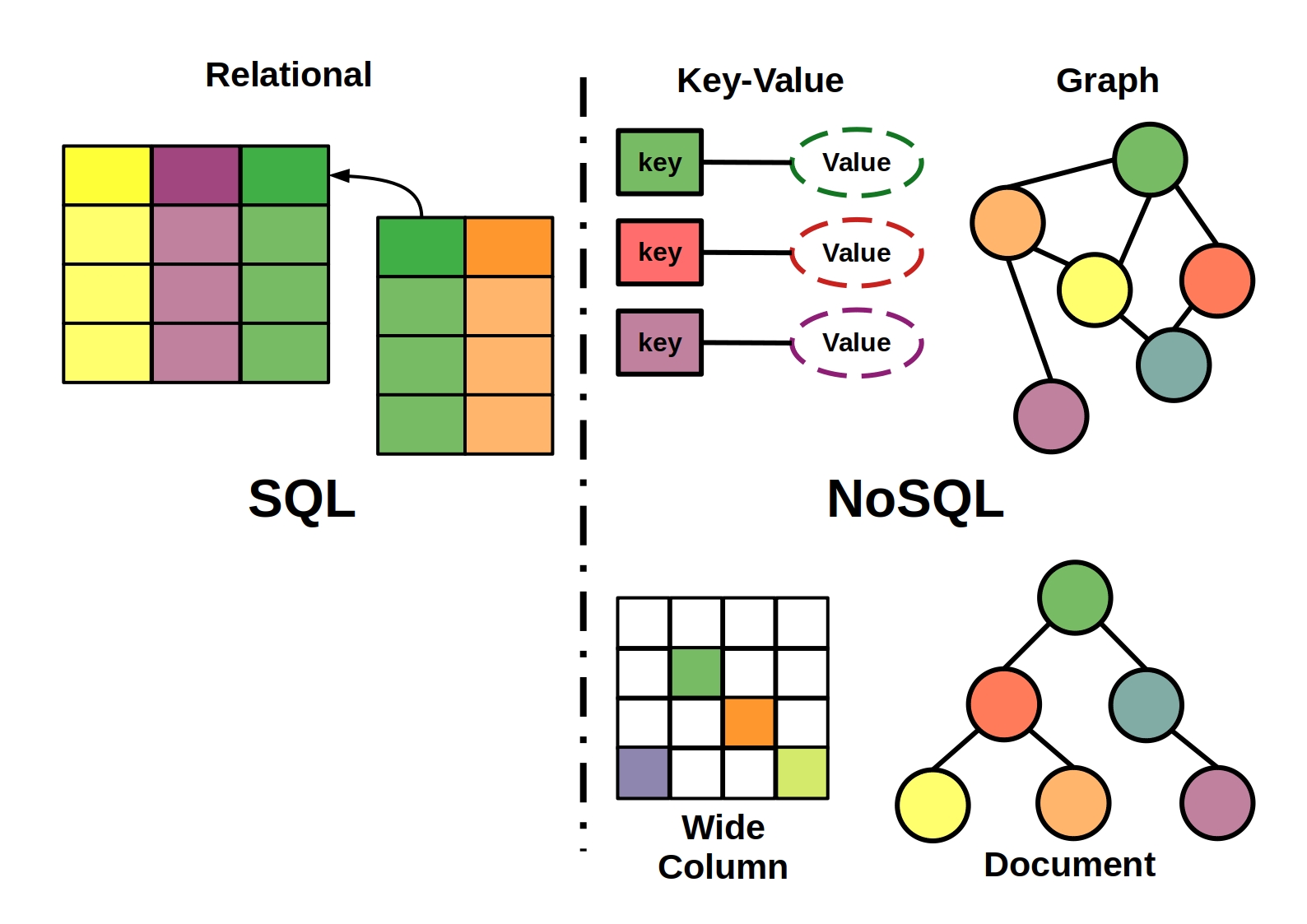
InfluxDB è un database relazionale sviluppato da InfluxData. è un database open source gratuito che combina big data , NoSQL e scalabilità. Ha un'elevata disponibilità, un'elevata velocità di scrittura ed è disponibile su richiesta. InfluxDB, un database NoSQL, memorizza una serie di punti dati nel tempo sulla base di una serie di punti dati di serie temporali.
Il suo scopo è quello di essere utilizzato per i dati delle serie temporali. Ogni serie di dati ha un timestamp che identifica un singolo punto al suo interno. In una tabella di database, la chiave primaria è sempre impostata dal sistema in questo caso, proprio come nei database SQL. Nella maggior parte dei casi, l'aggiunta di un nuovo campo a una misurazione può essere eseguita semplicemente scrivendo un punto per esso. Descrizioni più dettagliate dei termini influxDB menzionati in questa sezione sono disponibili nel nostro Glossario dei termini. Quando usi InfluxDB 1.8 con Flux, puoi acquisire una comprensione di base della sua sintassi e dei suoi concetti. InfluxQL, un linguaggio di query simile a SQL, viene utilizzato per interagire con influxDB.
L'ambiente SQL è stato progettato in modo che coloro che provengono da altri ambienti si trovino a proprio agio con esso. Il programma non supporta operazioni avanzate come UNION, JOIN o HAVING. Il timestamp corrente del server può essere utilizzato con il tempo relativo e now() per calcolare il tempo relativo. Questa query genera un elenco di dati di foodship. Un database CR-ud non è un database CRUD completo, ma piuttosto uno che è più simile ad afluxDB. È progettato per dare la priorità alla generazione e alla lettura dei dati piuttosto che all'aggiornamento e alla distruzione dei dati.
InfluxDB e MySQL sono due dei database di serie temporali più utilizzati. Entrambi gli strumenti open source sono semplici da usare e possono essere personalizzati. InfluxDB è una scelta eccellente per l'analisi dei dati delle serie temporali perché è più semplice di qualsiasi altra. InfluxDB offre una serie di vantaggi rispetto a MySQL. MySQL è più efficiente in termini di memoria e più veloce da sviluppare rispetto a InfluxDB. La seconda ragione per cui InfluxDB è uno strumento migliore di MySQL è che è più stabile. Inoltre, InfluxDB fornisce un supporto migliore per l'analisi delle serie temporali rispetto a MySQL. Per l'analisi delle serie temporali, InfluxDB è una buona scelta perché è semplice da usare, efficiente in termini di memoria e affidabile. Diverse aziende, tra cui Cisco, Power Home Remodeling, AT&T e Windstream Communications, stanno già utilizzando InfluxDB.
I pro ei contro dei database Nosql e Sql
I database SQL forniscono una migliore elaborazione delle transazioni su più righe rispetto ai database NoSQL per dati non strutturati come documenti e JSON. I database SQL vengono utilizzati anche nei sistemi legacy che sono stati scritti in un formato relazionale. I dati di InfluxDB sono archiviati in un gruppo shard. I dati vengono archiviati in un gruppo Shard e archiviati con timestamp definiti nella cronologia come durata dello shard e organizzati in base ai criteri di conservazione (RP). Inoltre, a seconda dell'RP, è possibile regolare la durata del gruppo di frammenti. È possibile modificare la durata del gruppo di partizioni accedendo a Gestione dei criteri di conservazione. InfluxDB presenta molte differenze in termini di struttura e funzionamento rispetto ai database SQL. Lo scopo di InfluxDB è archiviare dati storici. I dati delle serie temporali possono essere archiviati in database relazionali, ma questi database non sono ottimizzati per i carichi di lavoro di serie temporali di routine. Il client InfluxDBQL abilita le query SQL dei dati del database.

Che tipo di database è Influxdb?
InfluxDB è un database di serie temporali open source senza dipendenze esterne. È utile per monitorare metriche, eventi e analizzare analisi.
Il database open source InfluxDB è scritto in un formato di serie temporali ed è gestito da InfluxData. Questa piattaforma, progettata per archiviare e recuperare dati di serie temporali, viene utilizzata per monitorare e registrare metriche e analisi delle prestazioni. L'architettura del database di InfluxDB è composta da due database: un indice delle serie temporali (TSI) per i dati delle serie e un indice invertito per i metadati di misurazione, tag e campo. InfluxDB, un database open source, memorizza i dati in un formato a colonne. Inoltre, le colonne nell'archiviazione dei dati possono supportare query di serie temporali comuni come le scansioni nel tempo. Il Time-Structured Merge Tree (TSM) è la struttura organizzativa utilizzata da InfluxDB. Un FileStore viene utilizzato anche per gestire l'accesso ai file a tutti i file TSM su un computer.
InfluxDB è una soluzione di archiviazione dei dati potente, veloce ed economica che può essere utilizzata per l'analisi e il monitoraggio delle serie temporali. Utilizza la consegna dei dati a colonne in cui tutti i dati vengono consegnati contemporaneamente, eliminando la necessità di leggere intere righe per estrarre valori di dati specifici. Di conseguenza, InfluxDB è uno strumento utile per i dati che sono spesso voluminosi e densi, come i dati dei sensori e del sistema. InfluxDB, come la maggior parte dei database, fornisce un elevato throughput di lettura e scrittura, nonché funzionalità a colonne grazie al suo utilizzo di sharding e indicizzazione. Questa è una funzione utile perché i dati dei sensori o dei registri di sistema, che devono essere conservati e recuperati regolarmente, possono essere archiviati e recuperati. InfluxDB è una soluzione di archiviazione dei dati potente e flessibile, adatta per l'analisi e il monitoraggio delle serie temporali. Il formato include un array a colonne che fornisce i dati una colonna alla volta, throughput di lettura e scrittura due volte più veloci e funzionalità di indicizzazione che consentono una ricerca e una scalabilità più rapide. InfluxDB è una scelta eccellente per un'ampia gamma di requisiti di archiviazione, inclusi voluminosi dati di serie temporali e quelli che richiedono una soluzione di archiviazione dati rapida ed efficiente.
Influxdb Vs Mongodb
I risultati di InfluxDB hanno dimostrato che era di gran lunga superiore a MongoDB quando si trattava di acquisizione di dati e prestazioni di archiviazione su disco. In termini di ingestione di dati, InfluxDB supera MongoDB di un fattore quattro. InfluxDB, a differenza di MongoDB, offriva una compressione 20 volte superiore.
Dopo aver trascorso più di 4 anni utilizzando couchbase, siamo passati a MongoDB e non potremmo essere più felici. Abbiamo ricevuto supporto aziendale, ma l'esperienza è stata terribile, nonostante fossimo elencati come partner di Couchbase. Per eseguirlo correttamente, avrai bisogno di almeno sei server ai loro requisiti minimi. Saranno necessari sei server in produzione. Un'istanza Memcached più piccola viene fornita con l'istanza Couchbase per gestire la cache in memoria. Questo programma ha 8 GB di RAM e può supportare 5000 documenti. Non sto scherzando qui. Su un'istanza Couchbase, c'erano meno di 5000 documenti, meno di 20 indici e più di 8 GB di RAM.
Il database InfluxDB è un'ottima scelta per i dati delle serie temporali. Di conseguenza, è una scelta eccellente per l'archiviazione di dati sensibili perché consente allo sviluppatore il controllo completo sulla sicurezza dei propri dati. Inoltre, il supporto della community di InfluxDB è eccellente, semplificando il contatto con l'organizzazione quando necessario.
Perché Orientdb è il miglior database grafico
OrientDB, al contrario di MongoDB, offre una serie di vantaggi.
Poiché OrientDB è privo di schemi, puoi modellare facilmente il tuo modello di dati.
Poiché OrientDB è conforme ad ACID, i tuoi dati saranno coerenti e durevoli.
Le prestazioni di OrientDB sono superiori a MongoDB, rendendolo una scelta eccellente per l'archiviazione di dati di serie temporali.
OrientDB potrebbe essere l'opzione migliore per te se stai cercando un database grafico. Quando padroneggi il True Graph Engine, non avrai bisogno di gestire altri tipi di dati o implementare altri sistemi.
Influxdb Pro
Ci sono molte ragioni per amare InfluxDB. Eccone solo alcuni: – In primo luogo, InfluxDB è incredibilmente facile da installare e da avviare. In effetti, puoi avere un'istanza attiva e funzionante in pochi minuti con una configurazione minima. – In secondo luogo, InfluxDB ha eccellenti prestazioni di scrittura. Può gestire facilmente milioni di punti dati al secondo senza sudare. – In terzo luogo, InfluxDB ha un modello di dati molto flessibile che può essere facilmente personalizzato per soddisfare le tue esigenze. – In quarto luogo, InfluxDB ha un ricco linguaggio di query che supporta molti diversi tipi di query. – In quinto luogo, InfluxDB si integra bene con molti tipi diversi di origini dati e applicazioni. Nel complesso, InfluxDB è una scelta eccellente per i dati delle serie temporali. È facile da usare, ha grandi prestazioni ed è molto flessibile.
InflluxDB è un database di serie temporali. Per massimizzare le prestazioni per questo caso d'uso, è fondamentale fare dei compromessi, principalmente in termini di funzionalità. I dati con timestamp molto recenti costituiscono la stragrande maggioranza delle scritture e vengono aggiunti in ordine crescente. I dati in questione vengono aggiornati raramente e gli aggiornamenti controversi sono rari. Era difficile per i progettisti aumentare le prestazioni trattando dati effimeri e non consecutivi. Un database con un numero elevato di letture e scritture deve essere sufficientemente grande per gestirlo.
Il database di serie temporali più potente è un servizio che combina InfluxDB Cloud e un database di serie temporali. Questo strumento gratuito è semplice da usare, veloce, serverless ed elastico e supporta strumenti popolari come Docker e Prometheus. A causa della popolarità dell'open source InfluxDB, l'azienda è cresciuta fino a diventare una delle aziende di maggior successo nel settore. L'anno ha visto una notevole espansione della portata di InfluxData, con oltre 450.000 istanze attive di InfluxDB in esecuzione in tutto il mondo. I data scientist e gli ingegneri che richiedono un potente database di serie temporali che sia semplice e veloce da implementare sono i candidati ideali per InfluxDB Cloud.