
Introduzione a Hasura GraphQL Engine per API dinamiche con PostgreSQL
Pubblicato: 2019-11-07In generale, negli ultimi anni, le API REST sono state oggetto di critiche in quanto poco flessibili pur affrontando requisiti tecnologici in rapida evoluzione. In retrospettiva, molti credono che GraphQL sia stato creato per far fronte a questa esigenza di maggiore flessibilità ed efficienza nello sviluppo delle API. Pertanto, mitigando le carenze delle API REST. Come risultato della transizione di Facebook dalle applicazioni HTML5 a configurazioni più solide e native, GraphQL è cresciuto in popolarità e adozione negli ultimi cinque anni con buone ragioni. In questo blog, approfondiremo il fenomeno GraphQL, PostgreSQL e in seguito faremo un'introduzione completa al motore Hasura GraphQL. In uno snippet, la relazione Hasura GraphQL motore-PostgreSQL e l'ecosistema.
GraphQL: una ribellione di Facebook
Mentre molti credono che GraphQL sia stato creato come una ribellione alle API REST, questo potrebbe essere più lontano dalla verità. Ironia della sorte, è stato creato semplicemente per soddisfare un'esigenza interna a Facebook. Originariamente progettato e open source dal team di Facebook, GraphQL è spesso confuso come tecnologia di database. In sostanza, nonostante l'idea sbagliata, GraphQL è tecnicamente un linguaggio di query per API e non database. Di conseguenza, riduce la complessità della creazione di API, astraendo tutte le richieste a un singolo endpoint. A differenza delle tradizionali API REST, GraphQL è dichiarativo, il che significa che tutto ciò che viene richiesto viene restituito. Anche se per ottenere un po' più di contesto, dovremo fare un passo indietro e rivedere le API REST.
L'architettura REST
In genere, le API sono regole, routine o protocolli che specificano come devono interagire i componenti software. Il Representational State Transfer (REST) è fondamentalmente un'architettura di progettazione API normalmente sfruttata nell'implementazione di servizi Web in cui tutto è considerato una "risorsa". Sfortunatamente, la metodologia RESTful è stata costantemente limitata alla gestione di singole risorse. Quindi, se fossero necessari dati provenienti da due o più risorse, ad esempio post e utenti, sarebbero necessari più round trip al server per raccogliere tutto il necessario. Inoltre, REST ha riscontrato problemi con il recupero "over" e "under". Tutto ciò non era l'ideale, soprattutto con l'emergere di più app basate sui dati che gestiscono grandi set di dati combinando risorse correlate. Il che potrebbe spiegare la difficile situazione che Facebook ha dovuto affrontare.
Pertanto, la necessità di un'architettura API che adottasse un approccio più flessibile e progressivo.
La creazione di un'alternativa
In alternativa, GraphQL non considera i dati in termini di URL di risorse, chiavi secondarie o tabelle, ma in termini di un grafico di oggetti e modelli che utilizzano NSObjects o JSON. In particolare, GraphQL non ha bisogno di endpoint dedicati per ogni caso d'uso poiché diverse capacità e casi d'uso possono essere rappresentati in un unico "Grafico". Utilizzando il linguaggio di query GraphQL, puoi descrivere esattamente come dovrebbe apparire la risposta, quindi non sono necessari round trip aggiuntivi del server. In quanto linguaggio di query a livello di applicazione, è progettato per interpretare una stringa da un server/client e restituire i dati in un formato stabile, comprensibile e prevedibile. È semplicemente uno strumento per consolidare meglio i dati.
Semplicità, stabilità ed efficienza.
La verità è che non tutti i progetti richiedono GraphQL nonostante il suo schema ben definito, quindi sappiamo per certo che non supereremo il recupero. Tuttavia, se disponiamo di un prodotto aziendale che si basa su dati provenienti da più origini, ad esempio MySQL, Postgres e altre API, GraphQL è l'opzione migliore. GraphQL è orgoglioso della semplicità, in particolare per quanto riguarda il recupero dei dati poiché i dati vengono raccolti in un endpoint o chiamata comune. In sostanza, poiché i client ottengono esattamente ciò di cui hanno bisogno, ciò riduce efficacemente la dimensione di ogni richiesta effettuata dal client, risultando in applicazioni ad alte prestazioni. Poiché GraphQL unifica i dati che altrimenti richiederebbero più endpoint, facilita i recuperi ripetuti complessi, migliorando così l'efficienza delle query. Di conseguenza, con la sua semplicità derivano più stabilità, pianificazione, costruzione, esecuzione e funzionamento continuato nel tempo del back-end.
Vantaggi di GraphQL
In poche parole, GraphQL consente l'estrazione di dati con query facilmente comprensibili, consente lo sviluppo rapido di applicazioni leggere e veloci perché l'accesso ai dati è più diretto anziché tramite un server. Inoltre, consente il recupero di più risorse con una query senza utilizzare più URL o concatenamento di risorse, utilizzando un endpoint per tutti i dati. Ricorda, i dati sono definiti sul server con uno schema basato su grafici, quindi vengono forniti come un pacchetto anziché tramite più chiamate. Ciò consente una spinta operativa nell'aggregare le risposte dell'API durante lo sviluppo dell'API.
Questo, a sua volta, riduce il carico sui team di sviluppo front-end, facilita il controllo delle versioni delle API, semplifica la manutenzione e fa risparmiare sulle richieste di trasferimento dei dati. Inoltre, consente una maggiore prevedibilità durante la ricezione dei dati, supporta il recupero dichiarativo dei dati e riduce l'over-fetch e l'under-fetch. In sostanza, il recupero eccessivo si verifica quando un client scarica più informazioni di quelle effettivamente richieste nell'app mentre il recupero insufficiente implica che un endpoint specifico non ha fornito informazioni sufficienti, richiedendo quindi al client di effettuare richieste aggiuntive per recuperare ciò di cui ha bisogno.
Tecnicamente, GraphQL è un wrapper che può essere definito, il che significa che non è necessario sostituire completamente un sistema REST. In sostanza, ciò significa che GraphQL è compatibile con i sistemi con cui sono compatibili le API incentrate su REST. Inoltre, GraphQL consente lo sviluppo continuo e indipendente di front e back-end. Questo perché una volta che lo schema è ben definito, i team che lavorano sul front-end e sul back-end sono entrambi consapevoli della struttura definita dei dati. Tutti questi vantaggi sono visti come vantaggiosi da molti ingegneri full-stack. Infine, GraphQL ha una straordinaria capacità di introspezione approfondita e autodocumentazione.

Casi d'uso GraphQL nello sviluppo di API
Considerato estremamente potente, GraphQL è utilizzato dagli sviluppatori Full-stack che cercano una leggibilità stabile con velocità e indicizzazione rapide. In particolare, GraphQL è utile nello sviluppo di API che richiedono un'elevata velocità di trasmissione dei dati. Di fatto, riduce al minimo la quantità di dati richiesta per il trasferimento su una rete. Ciò è estremamente vantaggioso per gli utenti mobili, i dispositivi a bassa potenza e le reti sciatte. Questo è uno dei motivi iniziali per cui Facebook ha progettato GraphQL. Contrariamente a quanto si crede, GraphQL non è applicabile solo in enormi database complessi, ma può creare database relativamente semplici con maggiore efficienza.
Inoltre, può essere applicato su una varietà di framework e piattaforme front-end unici, fornendo un panorama eterogeneo gestito con un'API per soddisfare tutti i requisiti degli utenti. Inoltre, facilita lo sviluppo rapido delle funzionalità poiché aumenta notevolmente la velocità delle funzionalità per i team di sviluppatori full-stack. Lo fa riducendo la comunicazione richiesta tra i team durante lo sviluppo di nuove funzionalità poiché gli sviluppatori front-end possono effettuare richieste API, ad esempio per introdurre nuove funzionalità o modificare quelle esistenti senza dover attendere la consegna degli sviluppatori back-end. Questo breve riepilogo di GraphQL dovrebbe essere sufficiente per ora mentre entriamo nella nostra introduzione al motore Hasura GraphQL. Anche se tocchiamo PostgreSQL per un po' più di contesto.
Che cos'è PostgreSQL?
In quanto sistema di gestione di database relazionale gratuito guidato dalla comunità, PostgreSQL non è di proprietà di nessuna singola azienda. Considerato l'RDBMS più potente e internamente coerente disponibile, Postgres è stato scritto in C e supporta numerosi linguaggi di programmazione, come C/C++, JavaScript, Java, Python, R, Go, Lisp, .Net ecc. sviluppatori full-stack, PostgreSQL è più ricco di funzionalità della sorella MySQL, guadagnando popolarità grazie alle sue funzionalità, scalabilità e prestazioni. PostgreSQL è popolare nei progetti in cui i requisiti ruotano attorno a procedure complesse, progetti complessi, integrazione su misura e integrità dei dati.
Vantaggi di Postgres per gli sviluppatori Full-Stack
In generale, funzionalità come la ricerca full-text, le colonne JSON e la replica logica danno a Postgres il sopravvento su MySQL. Ciò è ottimale per le richieste di prestazioni dei database commerciali tipici, consentendo al contempo il consolidamento di più sistemi di database in uno solo per minori costi e spese generali. Inoltre, le sue caratteristiche più recenti per Key-Value-Storage (tipi di colonna JSON / JSONB) lo rendono un'alternativa adatta ai database NoSQL. Inoltre, supporta il clustering o un'architettura master-slave, il che lo rende adatto per ambienti simili al cloud. Inoltre, la sua popolare estensione per il wrapping di dati esterni consente di eseguire query su fonti esterne direttamente da PostgreSQL quando necessario. In particolare, è più adatto per i sistemi che richiedono l'esecuzione di query complesse, il data warehousing e l'analisi dinamica dei dati.
In effetti, PostgreSQL supporta meglio alcune funzionalità che MySQL non ha. Ad esempio, controlla i vincoli, i tipi di dati avanzati (come array, mappe, JSON), il supporto geospaziale più ricco (PostGIS) e il supporto full-text più completo. Inoltre, supporta la creazione di indici non bloccanti, indici parziali, espressioni di tabelle comuni e funzioni di analisi più dinamiche. Ciononostante, PostgreSQL offre supporto SLL nativo per le connessioni per la crittografia delle comunicazioni client/server, nonché un miglioramento integrato denominato SE-PostgreSQL che fornisce controlli di accesso aggiuntivi basati sulla politica SELinux.

Con molte funzionalità avanzate per prodotti di livello aziendale, PostgreSQL è appropriato per sistemi di grandi dimensioni in cui i dati richiedono l'autenticazione e le velocità di lettura/scrittura sono fondamentali per il successo del progetto. Inoltre, supporta anche molteplici potenziatori delle prestazioni normalmente disponibili nelle soluzioni proprietarie. Tali includono: concorrenza senza blocchi di lettura, server SQL e supporto dati geospaziali per citarne alcuni.
Un altro vantaggio principale dell'architettura Postgres è la sua estensibilità unica. Consente agli utenti di aggiungere funzionalità come tipi di dati, metodi di accesso all'indice, linguaggi di programmazione del server, wrapper di dati esterni (FDW) ed estensioni caricabili senza modificare il codice del sistema principale. Sfrutta una moderna architettura di processore multi-core, quindi consente alle sue prestazioni di crescere in modo quasi lineare all'aumentare del numero di core. Questo è importante In generale, funzionalità come la ricerca full-text, le colonne JSON, la replica logica, danno a Postgres il sopravvento su MySQL. Ciò è ottimale per le richieste di prestazioni dei database commerciali tipici, consentendo al contempo il consolidamento di più sistemi di database in uno solo per minori costi e spese generali. Inoltre, le sue caratteristiche più recenti per Key-Value-Storage (tipi di colonna JSON / JSONB) lo rendono un'alternativa adatta ai database NoSQL. Inoltre, supporta il clustering o un'architettura master-slave, il che lo rende adatto per ambienti simili al cloud. Inoltre, la sua popolare estensione per il wrapping di dati esterni consente di eseguire query su fonti esterne direttamente da PostgreSQL quando necessario. In particolare, è più adatto per i sistemi che richiedono l'esecuzione di query complesse, il data warehousing e l'analisi dinamica dei dati.

Contro di PostgreSQL
In generale, se ti piacciono gli standard ANSI SQL, prendi in considerazione PostgreSQL, anche se se preferisci gli standard ODBC, opta per MySQL. Sfortunatamente, Postgres occasionalmente non è all'altezza delle prestazioni con ambienti di produzione dal vivo "always up". Un ulteriore svantaggio di Postgres è il fatto che la sua replica è implementata a livello di storage engine. Questo lo rende più costoso della replica di MySQL, che è più matura e implementata a "livello di motore di query".
Introduzione al motore Hasura GraphQL
Poiché abbiamo brevemente trattato lo sviluppo dell'API GraphQL e PostgreSQL, dovremmo avere un contesto sufficiente per un'introduzione al motore Hasura GraphQL. Fondamentalmente, Hasura è semplicemente un motore GraphQL per RDBMS PostgreSQL, che fornisce un modo semplificato per eseguire il bootstrap e gestire lo sviluppo dell'API GraphQL. In retrospettiva, Hasura è attualmente l'unica soluzione prontamente disponibile che aggiunge istantaneamente GraphQL-as-a-Service alle applicazioni esistenti basate su PostgreSQL. In sostanza, aggirando il lungo compito di scrivere codice di back-end che elabora GraphQL.
Hasura semplificato
Prendiamoci un minuto per semplificare ulteriormente Hasura. Fondamentalmente, le API sono interfacce che consentono di richiedere informazioni (una query) e quindi rispondere inviando dati JSON o XML. Quel database è normalmente ospitato e recuperato da un server. È qui che entra in gioco Hasura per semplificare le cose. Con il senno di poi, il motore Hasura GraphQL è un server che gestisce le query GraphQL su un database Postgres. Ciò riduce efficacemente il tempo necessario per la produzione dell'app, consentendoti di creare, visualizzare e modificare facilmente le tabelle del database in pochi clic. Di conseguenza, ciò consente agli sviluppatori full-stack di creare applicazioni GraphQL scalabili su PostgreSQL in un tempo più breve. Ciò consente agli sviluppatori di risparmiare settimane di programmazione anticipata e può impedire che bug problematici di perdita di dati arrivino alla produzione.
Quale problema sta risolvendo Hasura nello sviluppo dell'API?
In generale, Hasura semplifica la gestione del ciclo di vita delle API durante l'utilizzo in produzione su larga scala, in particolare per le API complesse. Soprattutto, il motore GraphQL attrae sviluppatori full-stack che sono arretrati con progetti di sviluppo API aziendali che utilizzano database PostgreSQL esistenti. Idealmente, poiché GraphQL consente cicli di sviluppo API fulminei, Hasura fornisce un modo semplificato per le organizzazioni di passare in modo incrementale a GraphQL, senza influire sulle applicazioni, sui database o sugli utenti esistenti. Oltre alle sue prestazioni leggere e elevate, il motore è dotato di un'interfaccia utente di amministrazione, che consente di esplorare le API GraphQL e gestire visivamente lo schema e i dati del database.
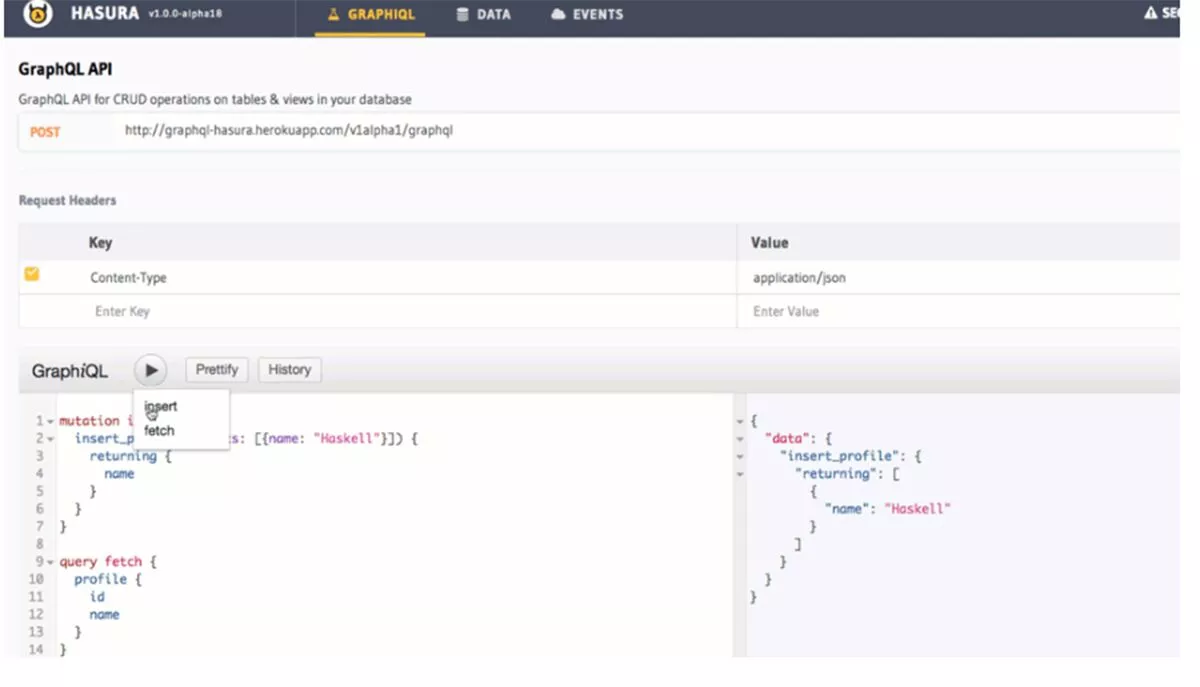
Vantaggi di Hasura
In primo luogo, Hasura dispone di un modello solido e stabile per la gestione delle modifiche o "migrazioni" del database. Questo è vantaggioso poiché la gestione dello schema del database è spesso complicata. Ad esempio, compiti come; tracciamento delle modifiche nel tempo e associazione delle modifiche dello schema ai miglioramenti dell'API (gestione dello schema). Inoltre, lavori di routine come la manutenzione di script che possono distribuire un nuovo database o il rollback delle modifiche possono rivelarsi noiosi e causare bug difficili da diagnosticare o un'interruzione. Come nota a margine positiva, i componenti di migrazione del database Hasura sono semplici SQL, quindi portabili al di fuori del set di strumenti Hasura. Tutto sommato, Hasura ha ottime funzionalità di gestione degli schemi e non è necessario scrivere codice per gestire le connessioni Web socket.
In secondo luogo, il motore Hasura GraphQL semplifica il recupero dei dati richiesti con una singola query. Ciò consente di aggiungere viste come relazioni a tabelle o altre viste. Inoltre, consente la scrittura di risolutori personalizzati con schema-stitching e integrazione di funzioni serverless o API di microservizi che vengono attivate su eventi di database. Questo può tornare utile e facilita la creazione di app 3factor. In effetti, Hasura è un motore estremamente leggero. In retrospettiva, consuma solo fino a 50 MB di RAM anche se serve più di 1000 richieste al secondo. Un brillante ritorno sull'investimento!
In particolare, Hasura facilita ulteriormente l'autorizzazione e l'autenticazione a livello di dati API a grana fine. Consente la connessione a un provider di autenticazione preferito tramite webhook, JWT, Auth0 o implementazioni personalizzate. E quindi, specifica dei ruoli per gli utenti, definendo chi può accedere a dati diversi, ad esempio admin, utenti anonimi, ecc. In genere, il suo sistema di controllo degli accessi granulare si basa sulla struttura della tabella del database simile allo schema GraphQL. Inoltre, le regole di autorizzazione personalizzate sono rigorosamente definite in base alle operazioni e ai valori del database.
Infine, Hasura supporta brillantemente il paging efficiente con un semplice modello offset/limit di tipo SQL. Ad esempio, utilizza il modello di controllo dell'accesso per limitare il numero di righe restituite per una determinata query. Il suo modello consente la regolazione dei limiti per ruolo. Ad esempio, gli utenti che impongono un tasso di richiesta molto più elevato sono limitati a limiti di riga inferiori. Ciò evita di stressare il database e il motore GraphQL. Inoltre, in particolare, Hasura non ti limita solo a GraphQL. Puoi comunque eseguire REST o altri microservizi non GraphQL sulle tabelle Postgres gestite da Hasura. Questo è possibile con lo schema stitching automatico di Hasura. Ciò consente l'unione di un servizio GraphQL non Hasura e di un back-end per un unico schema unificato, combinando nuove API gestite da Hasura con API e dati legacy.
Casi d'uso Hasura
Adatto per ambienti ad alte prestazioni, Hasura Engine offre velocità mentre automatizza l'implementazione di GraphQL-Postgres sui database esistenti. Di conseguenza, ciò fornisce alle aziende che già utilizzano Postgres un modo meno stressante e incrementale di passare a GraphQL collegando le tabelle esistenti in un "grafico". Hasura si occupa in modo efficiente dello schema stitching consentendo di applicare facilmente la logica aziendale personalizzata. Con gli schemi GraphQL remoti, Hasura può essere sfruttato come gateway per la logica aziendale personalizzata consentendo di scrivere sui server GraphQL nella lingua preferita, quindi esporre i dati a un singolo endpoint. Inoltre, Hasura ha un'ottima sintassi per query e mutazioni con query live integrate chiamate abbonamenti in GraphQL.
Le poche limitazioni di Hasura
Sfortunatamente, il modello del sistema di controllo degli accessi di Hasura non funzionerà completamente per ogni applicazione. Ad esempio, non supporta completamente l'autorizzazione di accesso API a livello di singoli parametri di input. Per non parlare del fatto che è limitato al database Postgres che richiede la migrazione nella maggior parte dei casi. Sebbene trascurabili, i messaggi di errore che l'API GraphQL restituisce per richieste non corrette sono piuttosto ostili su Hasura. Altrimenti, c'è poco che Hasura non possa fare come abbiamo visto in questa introduzione a Hasura GraphQL Engine.
Conclusione
In conclusione, con la crescita di GraphQL, semplificherà ulteriormente lo sviluppo di API all'interno delle imprese per creare su scala web. Con la rapida adozione su larga scala di GraphQL in un insieme diversificato di settori, Hasura ha il potenziale per automatizzare ulteriormente la creazione e la gestione delle API con le tecnologie standard del settore a scelta, GraphQL e Postgres. Hasura semplifica la creazione di backend GraphQL CRUD (Create, read, update and delete). Ancora più importante, Hasura è di gran lunga l'unica opzione migliore se stai partendo da zero con un'API incentrata su GraphQL e Postgres, senza scrivere codice di back-end. Per qualsiasi domanda o consulenza sulle possibilità aziendali di GraphQL e Hasura, non esitare a contattarci. Questo è tutto per la nostra introduzione a Hasura GraphQL Engine.