
È Spark per Nosql
Pubblicato: 2023-02-05Spark è un potente strumento per lavorare con i dati, in particolare set di dati di grandi dimensioni. È progettato per essere veloce ed efficiente e supporta una varietà di formati di dati, inclusi i database NoSQL . I database NoSQL stanno diventando sempre più popolari, poiché sono adatti per gestire grandi quantità di dati. Spark può aiutarti a interrogare e manipolare in modo efficiente i dati NoSQL.
Per lavorare in modo efficace, è fondamentale gestire i database della tua applicazione utilizzando Apache Spark e NoSQL ( Apache Cassandra e MongoDB). L'obiettivo di questo blog è fornire suggerimenti per lo sviluppo di applicazioni Apache Spark utilizzando i backend NoSQL. È un parco a tema, e TCP/IP sPark offre giostre sia a CassandraLand che a MongoLand. Quando abbiamo tentato di interrogare i dati DOE, la nostra applicazione Spark ha iniziato a ruotare fuori dal proprio asse. La lezione qui è che quando si interroga Cassandra, le sequenze di tasti sono importanti. CassandraLand offre anche le montagne russe Partitioner, che è una delle sue attrazioni più popolari. Mentre i clienti si godono il loro giro sulle montagne russe, gli operatori possono tenere traccia di chi lo ha percorso ogni giorno conservando le loro informazioni.
Nella lezione uno, esamineremo la gestione delle connessioni MongoDB. Quando devi aggiornare le informazioni su un parco, ad esempio il nuovo stato di appartenenza al parco del Dipartimento dell'Energia, puoi utilizzare gli indici mongo . MongoDB e Spark dovrebbero essere usati per garantire che la tua connessione sia gestita correttamente, così come gli indici in casi specifici.
Apache Spark è un popolare sistema di elaborazione distribuita open source e creato per l'uso in carichi di lavoro di dati di grandi dimensioni. Questa funzionalità, oltre alla memorizzazione nella cache in memoria e all'esecuzione ottimizzata delle query, consente query analitiche rapide su grandi quantità di dati.
Con quasi lo stesso codice, è più efficiente e versatile, consentendogli di elaborare contemporaneamente dati batch e in tempo reale. Di conseguenza, i vecchi strumenti di Big Data stanno diventando sempre più obsoleti a causa della loro mancanza di questa funzionalità.
Che tipo di database è Spark?
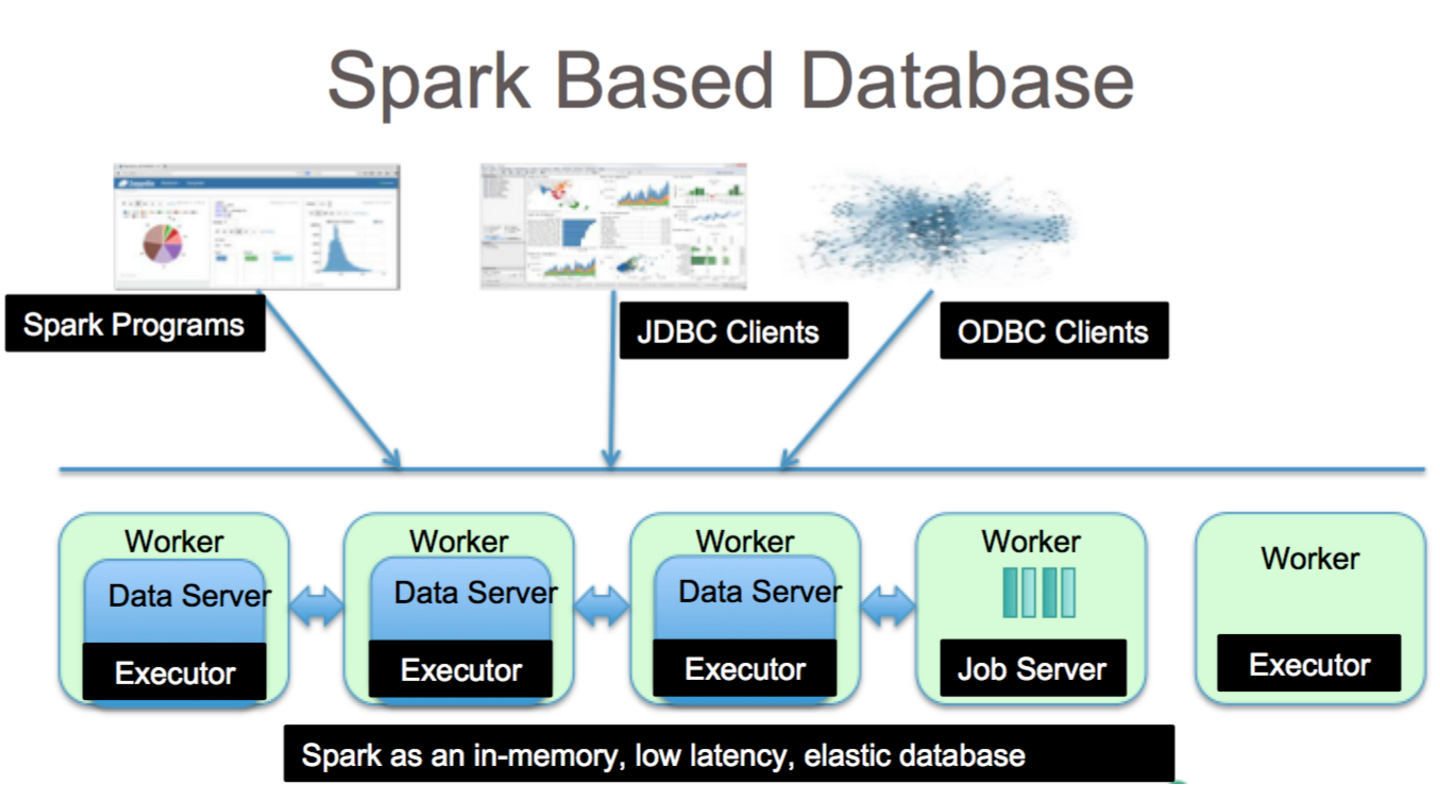
Apache Spark è un framework di elaborazione dei dati in grado di gestire i dati da una varietà di repository di dati, inclusi (HDFS), database NoSQL e database relazionali.
Sebbene ci siano stati numerosi cicli di promozione per i database relazionali, continueranno a essere popolari, indipendentemente dagli ultimi progressi e dall'ascesa dei database NoSQL. Nel corso del tempo, è diventato sempre più difficile archiviare i dati nei database relazionali. In questo articolo, esamineremo alcuni dei progressi significativi nello sfruttare il potere del database relazionale su scala globale. Quando è stato rilasciato per la prima volta, l'interfaccia tra Spark e Big Data Analysis era minima. Molte persone hanno scritto molto codice per eseguire questo programma, che era potente ma relativamente lento. Gli utenti saranno in grado di combinare facilmente questi due modelli nel database Spark SQL . Accetta anche un'ampia gamma di formati di dati da una varietà di fonti.
Il progetto open source Apache Spark è il più attivo, con centinaia di collaboratori che vi contribuiscono. Oltre ad essere un progetto open source gratuito, Spark SQL ha iniziato a guadagnare popolarità nei settori tradizionali. Oltre a Spark SQL, circa due terzi dei clienti di Databricks Cloud (il servizio ospitato che esegue Spark) usano altri linguaggi di programmazione. Dopo la conclusione del nostro primo caso di studio, dimostreremo come applicare databricks al caso in questo caso di studio pratico. Un DataFrame Spark è un insieme di righe (tipi di riga) distribuite con lo stesso schema. Ogni colonna nel set di dati è etichettata con un nome. L'API di DataFrame consente agli sviluppatori di integrare codice procedurale e relazionale.

Spark può anche gestire funzioni avanzate come UDF. Una tabella in un database relazionale è analoga a un dataframe in un dataframe database, ma sono coinvolte più ottimizzazioni. Possono essere manipolati allo stesso modo delle raccolte distribuite native (RDD) di Spark. In generale, la query Spark SQL è più veloce della query Shark ed è più competitiva con Impulsa. Nella query 3a, dove la selettività della query fa sì che una delle tabelle sia molto piccola, c'è una differenza significativa tra Impala e Impala.
È uno strumento fantastico per l'analisi dei dati con Spark SQL. È possibile accedere alla sintassi HiveQL, Hive SerDes e HiveDFs tramite la sintassi HiveQL, nonché Hive SerDes e HiveDFs. Hive metastore , SerDes e UDF sono già stati implementati. Nonostante Spark sia un database, è anche un database NoSQL. Di conseguenza, quando crei una tabella gestita in Spark, sarai in grado di utilizzare una varietà di strumenti conformi a SQL per archiviare i tuoi dati. Le espressioni SQL possono essere utilizzate per accedere alle tabelle in Spark connettendosi a JDBC tramite connettori da jdbc.org. Di conseguenza, puoi anche utilizzare strumenti di terze parti come Tableau, Talend e Power BI. La possibilità di utilizzare Spark è ideale per l'analisi dei dati ed è uno strumento utile per un'ampia gamma di settori.
Spark Sql: il meglio dei due mondi
Colma il divario tra i due modelli menzionati in precedenza, il modello procedurale e quello relazionale, includendo due componenti primari. Di conseguenza, puoi eseguire operazioni relazionali su larga scala su origini dati esterne e raccolte distribuite integrate di Spark utilizzando un'API DataFrame.
Cos'è la scintilla nel database? È un framework open source che utilizza machine learning, elaborazione di query interattive e carichi di lavoro in tempo reale. Questa azienda non dispone di un proprio sistema di archiviazione; piuttosto, utilizza l'analisi su altri sistemi di archiviazione come HDFS, Amazon Redshift, Amazon S3, Couchbase e altri, oltre al proprio. Quando si tratta di elaborazione strutturata dei dati, Spark SQL non è solo un database; è anche un modulo. La stragrande maggioranza è scritta su DataFrames, che sono le astrazioni di programmazione che funzionano insieme alle query SQL.
Qual è il tipo di SQL sql per "sparksql"? Hive SQL supporta la sintassi HiveQL, nonché Hive SerDes e UDF, consentendo di accedere ai warehouse Hive creati in precedenza. L'utilizzo di metastore Hive esistenti, SerDes e UDF in Spark SQL non è difficile.
MongoDB può eseguire Spark?
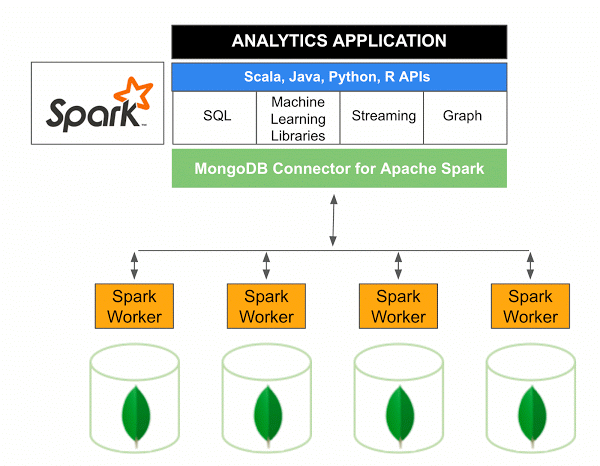
La versione 10.0 del connettore MongoDB per Apache Spark include il supporto per Spark Structured Streaming tramite la nuova Spark Data Sources API V2 e l'implementazione della nuova Spark Data Sources API V2.
Il connettore MongoDB per Spark è un progetto open source che consente di scrivere dati da MongoDB e leggerli da MongoDB utilizzando Scala. Grazie ai metodi di utilità dei connettori, le interazioni tra Spark e MongoDB sono semplificate, rendendolo una potente combinazione per la creazione di sofisticate applicazioni analitiche. Utilizzando le funzionalità di replica e sharding integrate, Spark può essere implementato in una varietà di carichi di lavoro che utilizzano i database MongoDB .
Spark: il modo rapido per creare applicazioni ricche di dati
Con l'aiuto di Spark, uno strumento potente, puoi sviluppare rapidamente applicazioni più funzionali. Incorporando MongoDB, gli sviluppatori possono accelerare il processo di sviluppo utilizzando una singola tecnologia di database. Inoltre, Spark è cloud-native e include il supporto per gli archivi dati NoSQL , rendendolo ideale per le applicazioni a uso intensivo di dati.