
MapReduce: un modello di programmazione per set di dati di grandi dimensioni
Pubblicato: 2023-01-08MapReduce è un modello di programmazione e un'implementazione associata per l'elaborazione e la generazione di set di dati di grandi dimensioni con un algoritmo parallelo e distribuito su un cluster.
Stiamo trasformando il modo in cui lavoriamo con enormi quantità di dati utilizzando le nuove tecnologie. I data warehouse, come Hadoop, NoSQL e Spark, sono alcuni degli attori più importanti nel settore. DBA e ingegneri/sviluppatori di infrastrutture fanno parte della nuova generazione di professionisti specializzati nella gestione di sistemi con un alto livello di sofisticazione. Invece di un database, Hadoop è un ecosistema software che consente il calcolo parallelo sotto forma di file di grandi dimensioni. Questa tecnologia ha fornito vantaggi significativi in termini di supporto delle massicce esigenze di elaborazione dei big data. Per una transazione di dati di grandi dimensioni, il cluster Hadoop medio può impiegare solo tre minuti per elaborare una transazione di grandi dimensioni che in genere richiederebbe 20 ore in un sistema di database relazionale centralizzato.
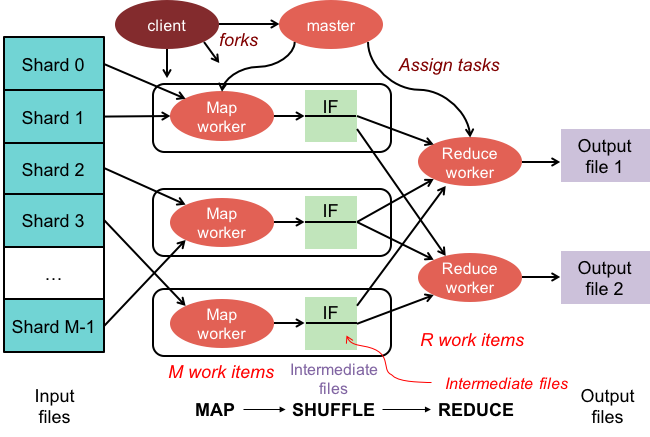
Un cluster mapreduce è un cluster con un algoritmo parallelo e un modello di programmazione che elabora e genera set di dati di grandi dimensioni allo stesso modo di un normale cluster.
L'ecosistema Apache Hadoop è progettato per supportare il calcolo distribuito e fornisce un ambiente affidabile, scalabile e pronto all'uso. Il modulo MapReduce di questo progetto è un modello di programmazione utilizzato per elaborare enormi set di dati che risiedono su Hadoop (un file system distribuito).
Questo modulo è un componente dell'ecosistema open source Apache Hadoop e viene utilizzato per interrogare e selezionare i dati nell'Hadoop Distributed File System (HDFS). I dati possono essere selezionati per una varietà di query utilizzando un algoritmo MapReduce disponibile allo scopo di effettuare tali selezioni.
Utilizzando MapReduce, è possibile eseguire attività di elaborazione dati di grandi dimensioni. Puoi creare programmi MapReduce in qualsiasi linguaggio di programmazione, inclusi C, Ruby, Java, Python e altri. Questi programmi possono essere utilizzati contemporaneamente per eseguire programmi MapReduce, rendendoli molto utili nell'analisi dei dati su larga scala.
A cosa serve Mapreduce in MongoDB?
Le mappe in MongoDB sono un modello di programmazione dell'elaborazione dei dati che consente agli utenti di eseguire set di dati di grandi dimensioni e generare risultati aggregati da essi. MapReduce è il metodo utilizzato da MongoDB per ridurre le mappe. Questa funzione è divisa in due componenti: una funzione map e una funzione reduce.
Utilizzando lo strumento MapReduce di MongoDB, è possibile organizzare e aggregare set di dati di grandi dimensioni. Questo comando, in MongoDB, utilizza i due input principali in MongoDB: la funzione map e la funzione reduce, per elaborare una grande quantità di dati. Per definire gli esempi, seguire i passaggi seguenti. Definiremo la funzione map, la funzione reduce e gli esempi.
MapReduce confronterà le stringhe per ordinare l'output utilizzando il metodo di ordinamento predefinito, indipendentemente dal fatto che tu stia utilizzando o meno il metodo predefinito. Per modificare il modo in cui i dati vengono ordinati, devi prima creare un algoritmo di ordinamento e quindi implementarlo utilizzando la classe mapper.
SpiderMonkey è un motore JavaScript ampiamente utilizzato. Va bene per applicazioni su piccola scala, ma presenta alcune limitazioni. SpiderMonkey non ha un algoritmo di ordinamento, per esempio. Di conseguenza, se desideri utilizzare Mapmapper per ordinare i dati, devi prima creare il tuo algoritmo di ordinamento e implementarlo nella classe Reduce.
Nonostante la sua popolarità, SpiderMonkey non utilizza un algoritmo di ordinamento. Ci sono altre limitazioni a SpiderMonkey, ma questa è notevole. SpiderMonkey, ad esempio, non ha un buon garbage collector, quindi se il tuo programma inizia a rallentare, potresti dover prendere alcune misure per renderlo più veloce.
Perché utilizzare una funzione Mapreduce?
Una funzione MapReduce può essere utile in una varietà di situazioni. Questo metodo può essere utilizzato per l'elaborazione dei dati in batch in alcuni casi. È utile anche se è necessario che una grande quantità di dati venga gestita da una singola applicazione o processo. Una funzione MapReduce può essere utilizzata anche per elaborare dati distribuiti su più nodi in un sistema distribuito. Utilizzando la funzione MapReduce, i dati dei nodi possono essere combinati in un singolo output. Un'applicazione MapReduce viene in genere utilizzata per elaborare grandi quantità di dati, sebbene possa essere necessario gestire quantità molto grandi.
Perché si chiama Mapreduce?
Ci sono alcune teorie là fuori sul motivo per cui si chiama MapReduce. Uno è che è un gioco di parole, poiché gli algoritmi di riduzione della mappa comportano la scomposizione di un problema in pezzi più piccoli (mappatura), quindi la risoluzione di quei pezzi e il loro rimontaggio (riduzione). Un'altra teoria è che si tratti di un riferimento a un documento scritto dai dipendenti di Google nel 2004 intitolato "MapReduce: Simplified Data Processing on Large Clusters". Nel documento, gli autori usano i termini "mappa" e "riduzione" per descrivere le due fasi principali del loro modello di elaborazione proposto.
Tuttavia, è importante notare che il modello MapReduce viene utilizzato solo su base limitata. Non è adatto per set di dati di grandi dimensioni e deve essere parallelizzato per funzionare correttamente. Quando si tratta di affrontare questi problemi, Apache Spark ha una potente alternativa a MapReduce. Il sistema di elaborazione cluster Spark è basato su Hadoop e funziona come una piattaforma informatica generica. Questo strumento può essere utilizzato per velocizzare le tradizionali attività di analisi dei dati come il data mining e l'apprendimento automatico, nonché attività di elaborazione dei dati più complesse come il data warehousing e l'analisi dei big data. Questo software è realizzato utilizzando Erlang, un linguaggio di programmazione scalabile e tollerante ai guasti. Può gestire grandi quantità di dati e può essere eseguito su più macchine contemporaneamente. Inoltre, Spark utilizza il parallelismo, consentendo a più nodi di svolgere la stessa attività contemporaneamente. Nel complesso, ha il potenziale per automatizzare attività di analisi dei dati su larga scala e renderle più scalabili. Se è necessario parallelizzare l'elaborazione e gestire grandi set di dati, è un'ottima alternativa a MapReduce.
Qual è la differenza tra Mapreduce e aggregazione?
Quando si lavora con i Big Data, mapreduce è un metodo importante per estrarre dati da una grande quantità di dati. MongoDB 2.2, fin d'ora, include il nuovo framework di aggregazione. In termini di funzionalità, l'aggregazione è simile a mapreduce, ma sulla carta sembra essere più veloce.
In questo scenario, MongoDB Aggregation e MapReduce vengono eseguiti su container Docker in una configurazione Sharded. Le prestazioni della pipeline dell'aggregatore sono superiori a mapreduce perché consente una navigazione più rapida e semplice. Ecco come funziona il problema: tweet conta i pronomi svedesi come "den", "denne", "denna", "det", "han", "hon" e "hen" (con distinzione tra maiuscole e minuscole) in un hashtag di Twitter. Quanti handle di Twitter ha un utente? Sono stati inviati oltre 4 milioni di tweet. In questo esperimento, creeremo prima un database MongoDB e abiliteremo lo sharding. I flussi di Twitter sono stati importati nel database e sono state eseguite query utilizzando MapReduce e Aggregation Pipeline.
Mapreduce: lo strumento definitivo per l'aggregazione dei dati
Un programma mapReduce legge un elenco di documenti da una raccolta e li elabora utilizzando un insieme di funzioni predefinite. L'operazione mapReduce genera un flusso di documenti pronti per l'elaborazione che verranno elaborati nella fase di riduzione. È possibile combinare mapreduce e aggregazione in una varietà di situazioni. L'operatore di aggregazione $group è uno strumento che può essere utilizzato per raggruppare i documenti in un singolo campo. Quando più documenti vengono uniti utilizzando l'operatore di aggregazione $merge, è possibile creare un nuovo documento. L'operatore di aggregazione $accumulator può essere utilizzato per rappresentare i risultati di più operazioni di riduzione della mappa in un singolo documento.
Mapreduce In Mongodb
MongoDB mapreduce è una tecnologia di elaborazione dati per set di dati di grandi dimensioni. È un potente strumento per l'analisi dei dati e fornisce un modo per elaborare e aggregare i dati in modo parallelo e distribuito. MapReduce è stato ampiamente utilizzato per l'analisi dei dati in una varietà di domini, tra cui l'analisi del traffico web, l'analisi dei log e l'analisi dei social network.

Quando si utilizza il comando mapReduce , è possibile eseguire operazioni di aggregazione map-reduce su una raccolta. La funzione mappa può convertire qualsiasi documento in zero o molti altri. Nelle versioni di MongoDB che vanno dalla 4.2 alla precedente, ogni emit può contenere solo la metà della dimensione massima del documento BSON. Il codice JavaScript obsoleto di tipo BSON utilizzato in MapReduce non è più supportato e il codice non può più essere utilizzato per le sue funzioni. MongoDB 4.4 ora non include più il codice JavaScript di tipo BSON deprecato con ambito (tipo BSON 15). Il parametro scope specifica a quali variabili può accedere la funzione reduce. Per ridurre gli input, MongoDB limita la dimensione del documento BSON alla metà della sua dimensione massima.
I documenti di grandi dimensioni restituiti al server possono essere restituiti e quindi uniti in successive riduzioni, infrangendo potenzialmente il requisito. MongoDB 4.2 è la versione più recente. Questa opzione può essere utilizzata per creare una nuova raccolta partizionata e map-reduce per creare una nuova raccolta con lo stesso nome di raccolta. La funzione finalize riceve come argomenti un valore chiave e il valore ridotto dalla funzione reduce. Sono disponibili tre opzioni per la configurazione del parametro out. Questa opzione, oltre a creare una nuova raccolta, non funziona sui membri secondari dei set di repliche. NonAtomic: l'opzione false può essere fornita solo se la raccolta esiste già da passare ha la specifica esplicita.
L'utilizzo della funzione reduce sia sul documento nuovo che su quello esistente risulta se la chiave sul nuovo documento è la stessa della chiave sul documento esistente. Un map-reduce non funziona quando collectionName è una raccolta esistente non protetta che è stata configurata. In questo caso, a MongoDB viene impedito di bloccare il proprio database se nonAtomic è vero. Solo i membri secondari dei set di repliche che utilizzano questa opzione possono essere esclusi dal set. Non sono necessarie funzioni personalizzate per riscrivere l'operazione di riduzione della mappa. Il cust_id viene utilizzato per calcolare il campo del valore del gruppo della fase a gironi $ con il metodo cust_id. La fase $merge combina i risultati della fase $merge nella raccolta di output utilizzando gli operatori della pipeline di aggregazione disponibili.
Ad esempio, lo stage $out può essere utilizzato per scrivere l'output della raccolta agg_alternative_1. Ogni documento di input può essere elaborato con la funzione mappa. Ogni articolo nell'ordine è associato a un nuovo valore oggetto contenente sia il conteggio di 1 che la quantità dell'articolo nell'ordine. In ReducedVal, il campo count rappresenta la somma dei campi count generati dagli elementi dell'array. Se la funzione finalize modifica l'oggetto reduceVal per includere un campo calcolato denominato avg, l'oggetto modificato viene restituito all'utente. La fase $unwind suddivide il documento in un documento per ogni elemento dell'array utilizzando il campo dell'array items. La fase $project rimodella il documento di output per rispecchiare l'output di mapreduce includendo due campi -id e value.
Sovrascrive il documento esistente se non esiste un documento esistente con la stessa chiave del nuovo risultato. Se specifichi il parametro out, mapReduce restituisce un documento come output nel seguente formato se desideri scrivere i risultati in una raccolta. Se l'output è scritto in linea, viene restituito un array di documenti risultanti. Ogni documento contiene due campi: il nome del documento sorgente e il nome del documento destinatario. Quando il valore della chiave viene immesso nel campo -id, viene creato un campo valore per ridurre o finalizzare i valori per la chiave.
Cos'è Emit in MongoDB?
Come funzione map, la funzione map può chiamare emits (key,value) in qualsiasi momento per generare un documento di output che include la chiave e il valore. Una singola emit in MongoDB 4.2 e versioni precedenti può contenere solo la metà della dimensione massima dei file BSON di MongoDB. A partire dalla versione 4.4 di MongoDB, la restrizione è stata rimossa.
Perché MongoDB è la scelta migliore per dati flessibili e scalabili
A causa della mancanza di uno schema rigido, MongoDB è spesso associato a NoSQL. A causa della mancanza di uno schema rigido, i dati possono essere archiviati in qualsiasi formato conveniente per l'applicazione. La flessibilità del database offre un vantaggio importante quando lo si ridimensiona, in quanto significa che i dati possono essere archiviati in un modo adattato alle esigenze dell'applicazione.
Un diagramma di dati con diagrammi ER può essere utilizzato per visualizzare le relazioni tra vari pezzi di dati. Il diagramma ER rappresenta una serie di nodi che rappresentano una raccolta di dati e le connessioni tra di essi fungono da identificatore.
Le relazioni non vengono applicate in MongoDB perché non è un database relazionale. Il diagramma ER descrive le relazioni che esistono all'interno dei dati e aiuta anche a visualizzarle.
MongoDB è una scelta eccellente per dati flessibili e scalabili. La sua flessibilità gli consente di archiviare i dati in un modo che abbia senso per un'applicazione e la sua scalabilità gli consente di gestire grandi set di dati in modo rapido e semplice.
Esempio MongoDB di riduzione della mappa
In MongoDB, map-reduce è un paradigma di elaborazione dei dati per l'aggregazione dei dati dalle raccolte. È simile alla mappa e riduce le funzioni nella programmazione funzionale.
Le operazioni di riduzione della mappa hanno due fasi:
1. La fase di mappatura applica una funzione di mappatura a ciascun documento della raccolta. La funzione di mappatura emette uno o più oggetti per ogni documento di input.
2. La fase reduce applica una funzione reduce ai documenti emessi dalla fase map. La funzione reduce aggrega gli oggetti e produce un singolo oggetto come output.
Ad esempio, considera una raccolta di articoli. Possiamo usare map-reduce per calcolare il numero di parole in ogni articolo.
Innanzitutto, definiamo una funzione di mappatura che emette una coppia chiave-valore per ogni documento, dove la chiave è l'id dell'articolo e il valore è il numero di parole nell'articolo.
Successivamente, definiamo una funzione di riduzione che somma i valori per ogni chiave.
Infine, eseguiamo l'operazione map-reduce sulla collezione. Il risultato è un documento che contiene i dati aggregati.
In mongosh, c'è un database. Il metodo mapReduce() è un wrapper attorno al comando mapReduce. In questa sezione vengono forniti diversi esempi, ad esempio un'alternativa della pipeline di aggregazione senza un'espressione di aggregazione personalizzata. Le mappe possono essere tradotte con espressioni personalizzate utilizzando Map-Reduce to Aggregation Pipeline Translation Examples. L'operazione di riduzione della mappa può essere modificata senza dover definire funzioni personalizzate utilizzando gli operatori della pipeline di aggregazione disponibili. La funzione map può essere utilizzata per elaborare ogni documento nell'input. Ogni articolo ha il proprio valore oggetto associato a un nuovo valore contenente il numero 1, il numero della quantità per l'ordine e un elenco di articoli.
Se la chiave nel documento corrente è la stessa della chiave nel nuovo documento, l'operazione sovrascrive quel documento. È possibile riscrivere l'operazione di riduzione della mappa utilizzando gli operatori della pipeline di aggregazione anziché definire funzioni personalizzate. La fase $unwind suddivide il documento in base al campo dell'array items, ottenendo un documento per ogni elemento dell'array. Quando la fase $project rimodella il documento di output, viene eseguito il mirroring dell'output di map-reduce. Un'operazione sovrascrive un documento esistente che ha la stessa chiave del nuovo risultato.
Qual è la funzione Mapper in Hadoop?
Come riduttore, devi combinare i dati dei mappatori per generare una risposta unificata. L'output di riduzione viene prodotto quando un insieme di output della mappa viene accettato come input, ognuno dei quali rappresenta un sottoinsieme del risultato generato.
I mappatori vengono utilizzati per dividere i dati in blocchi gestibili, quindi assegnare ciascun blocco a un'attività in base alla sua dimensione. I dati di input vengono ricevuti dalla funzione mapper, dove sono presenti i parametri che indicano l'attività da eseguire.
Una serie di elementi corrisponde ai blocchi di dati che sono stati mappati dal mapper in output. Di conseguenza, l'output della mappa viene inoltrato al riduttore, che lo converte in un output ridotto.
Gli errori sono gestiti anche dalla funzione mapper. Un mapper restituirà un output di errore in questo caso, che non è un output della mappa. Poiché il riduttore non è in grado di elaborare questi dati, il mapper restituirà un messaggio di errore.
Ecosistema Hadoop
L'ecosistema Hadoop è una piattaforma per l'elaborazione e l'archiviazione di big data. È costituito da una serie di componenti, ognuno dei quali ha un ruolo specifico da svolgere nell'elaborazione e nell'archiviazione dei dati. I componenti più importanti dell'ecosistema sono l'Hadoop Distributed File System (HDFS), il framework MapReduce e la libreria Hadoop Common .