
Replica master-slave vs replica multi-master nei database NoSQL
Pubblicato: 2023-01-13Esistono molti tipi diversi di replica supportati dai database NoSQL. Il tipo più comune di replica è la replica Master- Slave . In questo tipo di replica è presente un server principale che contiene tutti i dati. I server slave replicano quindi i dati dal server master. Questo tipo di replica è molto semplice e facile da configurare. È anche molto efficiente e offre buone prestazioni. Un altro tipo di replica supportato dai database NoSQL è la replica multimaster. In questo tipo di replica sono presenti più server master. ogni server principale dispone di una copia dei dati. I server slave replicano quindi i dati da tutti i server master. Questo tipo di replica è più complesso da configurare ma offre prestazioni migliori ed è più tollerante ai guasti.
Oltre a NoSQL Data Replication , fornisce una solida funzionalità che consente di copiare e archiviare i dati strutturati, non strutturati e semi-strutturati in caso di arresto anomalo del server. Scopri come utilizzare i database NoSQL in un semplice processo passo dopo passo.
Replica dei dati: poiché i dati vengono replicati da un server all'altro, ogni bit di dati può essere trovato su più server. Un processo di replica è diviso in due fasi: replica master-slave e replica slave-aware. La replica master-slave assegna a un nodo l'autorità per gestire le scritture, mentre la replica con riconoscimento dello slave consente agli slave di leggere e sincronizzarsi con il master.
MySQL include la replica asincrona unidirezionale, in cui un server funge da origine e un altro funge da replica.
Il fattore di replica (RF), come suggerisce il nome, è il numero di nodi in cui vengono replicati i dati (righe e partizioni). Più nodi (RF=N) sono collegati per trasmettere dati. La RF di uno indica che c'è solo una copia di una riga in un cluster e non c'è modo di recuperare i dati se il nodo è bloccato o compromesso.
Che cos'è lo sharding e la replica in Nosql?
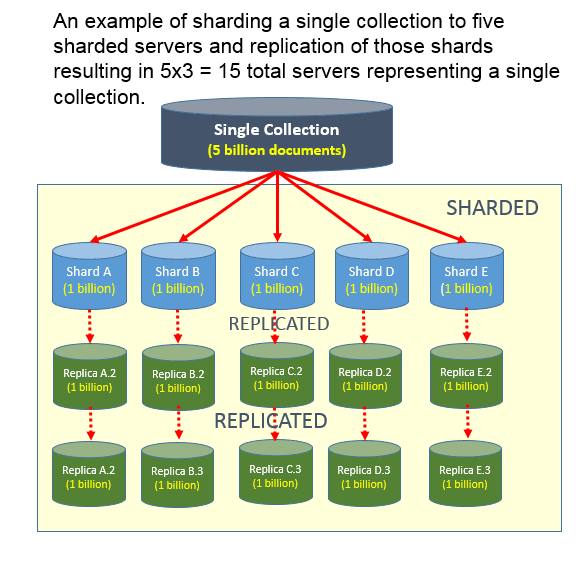
Qual è la differenza tra sharding e replica? La replica dei dati si verifica quando un nodo del server primario e un nodo del server secondario si scambiano dati. Come backup in caso di guasto del server primario, questo può aiutare ad aumentare la disponibilità dei dati. La capacità di scalare orizzontalmente tra i server si basa sull'uso di una chiave di partizione.
I database SQL consentono di dividere un set di dati in tabelle e quindi creare una partizione per ogni tabella. Un database NoSQL , come MongoDB, non ha tabelle ma una raccolta di documenti. Il comando mongo shard viene utilizzato per partizionare le raccolte MongoDB. È possibile distribuire il carico su più server in un unico ambiente di sharding, con conseguente miglioramento delle prestazioni. Quando si tratta di set di dati di grandi dimensioni, questo è particolarmente vero. Inoltre, lo sharding può aiutare a gestire e proteggere set di dati di grandi dimensioni fornendo l'integrità dei dati. Oltre a ridimensionare i tuoi dati, Sharding è uno strumento fantastico per gestirli in modo efficace. Questo modello è ampiamente utilizzato nei database NoSQL grazie alla sua facilità di implementazione e all'ampio supporto.
Perché lo sharding è migliore per le scritture di dati
In generale, la replica consente il ridimensionamento orizzontale delle letture ma non consente il ridimensionamento dei dati su più server con una singola chiave, mentre lo sharding lo fa.
Che tipo di dati è supportato da Nosql?
I database NoSQL sono sempre più popolari perché supportano un'ampia gamma di tipi di dati. Ciò include sia tipi di dati tradizionali come numeri e stringhe, sia tipi di dati più recenti come JSON e XML. I database NoSQL supportano anche un'ampia gamma di linguaggi di programmazione, rendendoli una buona scelta per le aziende che utilizzano più linguaggi.
In un database NoSQL, ci sono quattro tipi: coppie chiave-valore, colonne, grafici e documenti. Ogni categoria ha il proprio insieme di caratteristiche e limitazioni. Il database MongoDB è un popolare database NoSQL . Questo è un database di coppie chiave-valore che memorizza entrambe le coppie. Questa applicazione è semplice da usare, scalabile e veloce. I database orientati ai documenti sono al centro di CouchDB. Questa applicazione è semplice da usare e abbastanza flessibile da ospitare più utenti. Il database CouchBase è orientato alle colonne e si concentra sulle transazioni. Il database di Cassandra si basa su un'architettura fortemente orientata alle colonne. Il sistema di archiviazione HBase è una soluzione di archiviazione scalabile, distribuita e nell'ordine dei petabyte per set di dati di grandi dimensioni. È un database di memoria distribuito che gira su Redis. Utilizzando Riak come archivio dati, puoi creare un sistema open source ad alte prestazioni. Neo4J, come database grafico, è costruito su una piattaforma Java.
Perché Nosql è la scelta migliore per le aziende che devono scalare rapidamente
Per le aziende che devono scalare rapidamente, NoSQL è una buona scelta perché ha un'architettura più flessibile e può essere scalata orizzontalmente. Inoltre, i database NoSQL non sono così sensibili alle modifiche dello schema come i tradizionali database relazionali.
La replica dei dati Nosql è
La replica dei dati Nosql è un processo di copia dei dati da un database nosql a un altro database nosql. Questo viene fatto per mantenere i dati al sicuro e per garantire che siano sempre disponibili in caso di guasto.
Nosql vs. Rdbms: qual è il migliore per le prestazioni?
Esiste un numero crescente di ricerche che dimostrano che i database NoSQL, come MongoDB, superano i tradizionali RDBMS. La tecnologia consente di partizionare e replicare i dati, rendendola ideale per le applicazioni che richiedono un throughput elevato e un rapido accesso ai dati. Anche se a volte i dati possono essere replicati, non è sempre possibile.
Replica master-slave in Nosql
La replica master-slave è un tipo di replica in cui i dati vengono copiati da un server primario ("master") a uno o più server secondari ("slave"). I server slave possono essere utilizzati per le operazioni di lettura, ma tutte le operazioni di scrittura devono essere inviate al master. Questo tipo di replica viene spesso utilizzato nei database Nosql, in quanto può fornire elevata disponibilità e scalabilità. Ad esempio, se il server master non funziona, gli slave possono ancora essere utilizzati per servire le richieste di lettura. E, se è necessaria una maggiore capacità di lettura, è possibile aggiungere ulteriori server slave.
Le sfide della replica master-slave
Può essere difficile mantenere i dati su tutti i nodi slave nel modello di replica master-slave. Se uno dei nodi slave si interrompe, i dati su quel nodo slave andranno persi.
Quale modello di replica supporta le operazioni di lettura e scrittura del database in tutti i nodi?
Il modello di replica che supporta le operazioni di lettura e scrittura del database in tutti i nodi è il modello di replica Master -Master. Questo modello consente a ciascun nodo di agire come master, il che significa che ogni nodo può leggere e scrivere nel database. Ciò è vantaggioso per le organizzazioni che devono disporre di elevata disponibilità e ridondanza, poiché tutti i nodi possono continuare a funzionare anche se un nodo si interrompe.

Quale modello di applicazione supporta le operazioni di lettura e scrittura del database in tutte le note?
Gli RDBMS utilizzano in genere un modello schema-on-write, in cui una struttura dati viene definita in anticipo e tutte le operazioni di lettura e scrittura dipendono da tale struttura.
Le modifiche e gli aggiornamenti del database possono verificarsi in modalità lettura-scrittura
Le modifiche e gli aggiornamenti possono verificarsi in modalità lettura/scrittura quando il database viene aperto in modalità lettura/scrittura, controllata da OpenReadWrite() o OpenWrite. DatabaseReader è una classe che può essere utilizzata per leggere e scrivere dati in un database. I dati possono essere scritti in un database utilizzando l'oggetto DatabaseWriter.
Quale tipo di database supporta i nodi collegati da relazioni?
È possibile archiviare e accedere alle relazioni nei database a grafo utilizzando relazioni strutturate. Le relazioni sono gli aspetti più preziosi dei database a grafo perché sono alcuni dei cittadini più preziosi. I nodi vengono utilizzati nei database a grafo per memorizzare entità di dati e gli spigoli vengono utilizzati per connettere entità.
MongoDB e Node.js: l'abbinamento perfetto per lavorare con i grafici in Javascript
Se vuoi usare i grafici in JavaScript, dovresti usare MongoDB. MongoDB è il database NoSQL più popolare, mentre Node.js è anche un popolare linguaggio di programmazione JavaScript.
Come funziona la replica del database non relazionale?
In un'istanza di replica dei dati NoSQL peer-to-peer, i dati vengono replicati da un database all'altro in base al concetto che ogni copia deve mantenere aggiornata la propria copia. L'unico caso in cui ciò può funzionare è se ogni copia dello schema memorizza lo stesso tipo di dati nello stesso formato. L'altro aspetto critico di questo metodo di replica dei dati è il ripristino del database.
I diversi tipi di replica
*br *Replica di archiviazione *br È un tipo di replica che memorizza le modifiche ai dati in modo coerente. Un server di replica di origine crea uno snapshot del database con le informazioni sullo stato corrente dopo averne creato uno. Quindi, lo snapshot viene inviato al server di replica di destinazione. Dopo lo snapshot, il server di replica di destinazione crea una nuova copia del database. Riferimento alla replica transazionale nei dati Le transazioni vengono archiviate in dati che cambiano frequentemente e possono essere replicati utilizzando la replica transazionale. Una transazione viene raggruppata in batch e replicata in un singolo batch. Le modifiche ai dati vengono replicate da un processo noto come replica. La replica peer-to-peer può essere eseguita tramite l'uso di server. La replica dei dati peer-to-peer è un tipo di replica dei dati che ha lo scopo di replicare i dati che non vengono modificati di frequente. Nella replica dei dati peer-to-peer, un cluster di nodi replica i dati. Ogni nodo in un cluster ha il proprio modello di dati. I nodi del cluster non sono a conoscenza l'uno dell'altro.
Replica del database dei documenti Nosql
I database di documenti Nosql sono progettati per fornire elevata disponibilità e scalabilità replicando i dati su più server. Ciò consente al database di continuare a funzionare anche se uno o più server si guastano.
Grande database Nosql
Non esiste una risposta definitiva a questa domanda in quanto dipende dalle esigenze specifiche dell'utente. Tuttavia, alcuni dei grandi database nosql più popolari includono MongoDB, Cassandra e Hadoop. Questi database sono tutti progettati per fornire scalabilità e prestazioni elevate, rendendoli ideali per l'elaborazione di dati su larga scala.
Un database NoSQL come MongoDB, ad esempio, è ideale per i big data perché può gestire grandi quantità di dati in modo rapido e semplice. Poiché MongoDB è un MongoDB orientato ai documenti, può gestire enormi quantità di dati. In altre parole, MongoDB può gestire i dati in una varietà di formati, inclusi JSON, BSON e JavaScript Object Notation (JSON). Inoltre, semplifica l'accesso e l'archiviazione dei dati. Inoltre, MongoDB è scalabile, il che significa che può elaborare grandi quantità di dati.
Quale database Nosql è il migliore per i Big Data?
Creano i formati che gli strumenti di analisi possono utilizzare per convertire i dati non strutturati e semi-strutturati in formati che possono essere utilizzati nelle loro applicazioni. I requisiti unici per l'archiviazione di big data rendono i database NoSQL (non relazionali) come MongoDB una scelta eccellente.
Perché MongoDB è la scelta migliore per l'archiviazione di Big Data
MongoDB è una scelta eccellente per archiviare e gestire grandi quantità di dati. Le operazioni CRUD (crea, leggi, aggiorna, elimina), il framework di aggregazione, la ricerca di testo e la funzione Map-Reduce semplificano l'accesso, la manipolazione e l'analisi dei dati da parte degli utenti.
I Big Data sono Nosql?
Se i tuoi carichi di lavoro di dati sono più focalizzati sull'elaborazione e l'analisi rapide di grandi volumi di dati vari e non strutturati, come i Big Data, NoSQL è una scelta migliore. I database NoSQL non hanno le stesse restrizioni sui tipi di dati dei database relazionali.
Perché i database Nosql sono il futuro della gestione dei dati
Il database NoSQL sta diventando sempre più popolare grazie ai suoi significativi vantaggi in termini di prestazioni rispetto ai tradizionali database relazionali. È un attivatore di database NoSQL che abilita determinati tipi di database NoSQL, come HBase, consentendo la distribuzione dei dati su migliaia di server senza ridurre le prestazioni. La piattaforma cloud di Google (GCP) fornisce una serie diversificata di servizi di database, unici nella loro capacità di elaborare set di dati dinamici molto grandi senza la necessità di uno schema.
Le grandi aziende usano Nosql?
Tecnologia di database basata su Cloud Computing, Web, Big Data e Big Users. Offrendo NoSQL come alternativa al tradizionale RDBMS, NoSQL è diventato un'opzione praticabile per molte società Internet popolari come LinkedIn, Google, Amazon e Facebook.
Nosql è il futuro per i database di backend di Instagram?
A questo punto, Instagram sembra preferire PostgreSQL come database principale come back-end principale, anche se questo potrebbe cambiare. Cassandra, un popolare database NoSQL, potrebbe o meno essere la soluzione migliore per Instagram. Cassandra è uno strumento eccellente per l'archiviazione di grandi quantità di dati, ma ha uno scarso track record in termini di prestazioni.
Al momento, è difficile prevedere se Instagram utilizzerà o meno i database NoSQL come database di back-end principale. PostgreSQL e Cassandra sono scelte eccellenti, ma non possono competere con SQL in termini di prestazioni.